计算机是如何工作的,Java多线程编程
一、冯诺依曼体系
现代的计算机,大多遵守 冯诺依曼体系结构 (Von Neumann Architecture)

CPU 中央处理器: 进行算术运算和逻辑判断.
![]()
AMD Ryzen 7 580OU with Radeon Graphics
GHz 叫做 CPU 的主频
这个数字越大,CPU 就算的越快,表示 1s 执行 32 亿条指令
存储器: 分为外存和内存, 用于存储数据(使用二进制方式存储)
输入设备: 用户给计算机发号施令的设备.
输出设备:计算机个用户汇报结果的设备
针对存储空间
- 硬盘 > 内存 >> CPU
针对数据访问速度
- CPU >> 内存 > 硬盘
认识计算机的祖师爷 – 冯诺依曼
冯·诺依曼(John von Neumann,1903年12月28日-1957年2月8日), 美籍匈牙利数学家、计算机科学家、物理学家,是20世纪最重要的数学家之一。冯·诺依曼是布达佩斯大学数学博士,在现代计算机、博弈论、核武器和生化武器等领域内的科学全才之一,被后人称为 “现代计算机之父”, “博弈论之父”.
二、CPU 基本工作流程
1、逻辑门
1.1、电磁继电器
电子开关 —— 机械继电器 (Mechanical Relay):
电磁继电器:通过通电 / 不通电来切换开关状态,得到 1 或者 0 这样的数据

1.2、门电路 (Gate Circuit)
基于上述的 “电子开关” 就能构造出基本的门电路,可以实现 1 位(bit) 的基本逻辑运算
最基础的门电路,有三种:
非门:可以对一个 0/1 进行取反. 0-> 1
与门:可以针对两个 0/1 进行与运算. 1 0 -> 0
或门:可以针对两个 0/1 进行或运算. 1 0 -> 1
针对二进制数据来进行的.不是"逻辑与”,此处是按位与
借助上述的基础门电路,能构造出一个更复杂的门电路:异或门
相同为0,相异为1。1 0 -> 1
1.3、运算器
基于上述的门电路,还可以搭建出一些运算器
半加器:是针对两个比特位,进行加法运算

全加器:是针对三个比特位,进行加法运算
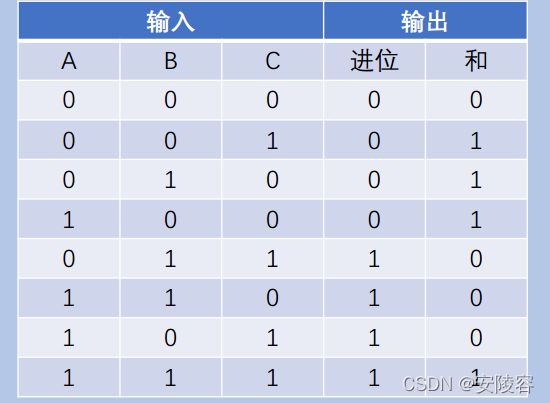
1.4、加法器
基于上述的半加器和全加器,就可以构造出一个针对多个 bit 位的数据进行加法运算的加法器了
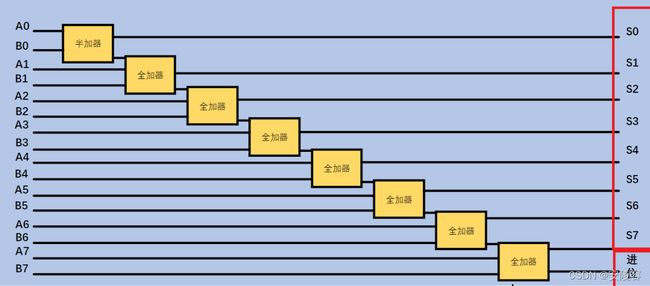
A和B是两个8 bit的数字
A0这个数字的第0位(最右)A1
A2
A3
…
电子开关=>基础的门电路=>异或门电路=>半加器=>全加器=>8位加法器
有了加法器之后,就可以计算不只是加法,还能计算减法、乘法、除法都是通过这个加法器来进行
2、寄存器,控制单元(CU)
CPU里面除了运算器之外,还有控制单元和寄存器(Register)
门电路 (电子开关)
CPU芯片来说,上面就集成了非常非常多的这些电子开关,一个CPU上面的电子开关越多,就认为是计算能力就越强
CPU里面除了运算器之外,还有控制单元和寄存器
-
寄存器是CPU内部用来存储数据的组件
访问速度:寄存器是内存的3-4个数量级
存储空间:比内存小很多很多,现在的x64的cpu (64位的cpu),大概有几十个寄存器,每个寄存器是8个字节,几百个字节,
成本:CPU上面的这个寄存器,还是非常贵
持久化:掉电之后数据丢失 -
控制单元 CU(Control Unit):
协调CPU来去进行工作
控制单元最主要的工作,能够去执行指令
后面进行详细的论述
3、指令(Instruction)
指令和编程密切相关。
编程语言,大概分成三类:
1、机器语言
通过二进制的数字,来表示的不同的操作
不同的CPU (哪怕是同一个厂商,但是不同型号的CPU),所支持的机器语言(指令)也可能存在差别
2、汇编语言
一个CPU到底支持哪些指令,生产厂商,会提供一个**"芯片手册”** 详细介绍CPU都支持哪些指令,每个指令都是干啥的
汇编语言和机器语言是一对一的关系 (完全等价)
不同的CPU支持的机器指令不一样,不同的CPU上面跑的汇编也不一样
学校的大部分的汇编语言都是针对一款上古神 U,Intel 8086 CPU
3、高级语言
(C,Java,JS)
指令是如何执行的?
自己构造出一个最简单的芯片手册:

假设CPU上有两个寄存器
A 00
B 01
0010 1010
这个操作的意思,就是把1010 内存地址上的数据给读取到A寄存器中
0001 1111
这个操作的意思,就是把 1111内存地址上的数据读到寄存器 B 中
0100 1000
这个操作的意思,就是把 A寄存器的值,存到 1000这个内存地址中
1000 0100
这个操作的意思,就是把 00寄存器和01寄存器的数值进行相加,结果放到 00 寄存器里
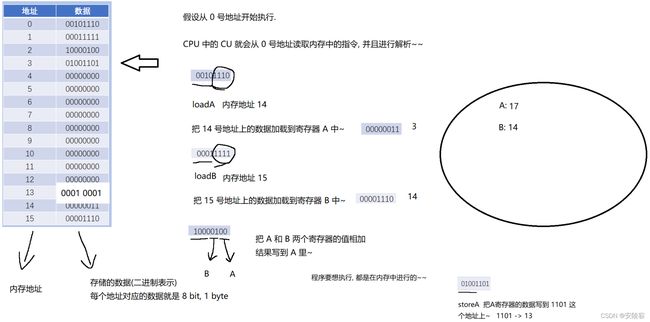
CPU的工作流程:(通过CU控制单元来实现的)
- 从内存中读取指令
- 解析指令
- 执行指令
咱们编写的程序,最终都会被编译器给翻译成 CPU 所能识别的机器语言指令,在运行程序的时候,操作系统把这样的可执行程序加载到内存中,cpu 就一条一条指令的去进行读取,解析,和执行,如果再搭配上条件跳转,此时,就能实现条件语句和循环语句
三、操作系统(Operating System)
操作系统是一组做计算机资源管理的软件的统称。目前常见的操作系统有:Windows系列、Unix系列、
Linux系列、OSX系列、Android系列、iOS系列、鸿蒙等
操作系统是一个搞 "管理的软件"
- 对下,要管理好各种硬件设备
- 对上,要给各种软件提供稳定的运行环境
1、进程/任务(Process/Task)
exe 可执行文件,都是静静的躺在硬盘上的,在你双击之前,这些文件不会对你的系统有任何影响
但是,一旦你双击执行这些 exe 文件,操作系统就会把这个 exe 给加载到内存中,并且让 CPU 开始执行exe内部的一些指令 (exe里面就存了很多这个程序对应的二进制指令)
这个时候,就已经把 exe给执行起来,开始进行了一些具体的工作
这些运行起来的可执行文件,称为 "进程"
这些都是机器上运行的进程:

- 线程:
线程是进程内部的一个部分, 进程包含线程,如果把进程想象成是一个工厂,那么线程就是工厂里的生产线,一个工厂里面可以有一个生产线或者也可以有多个生产线
咱们写的代码,最终的目的都是要跑起来,最终都是要成为一些进程
对于 java 代码来说,最终都是通过 java 进程来跑起来的 (此处的这个 java 进程就是咱们平时常说的jvm)
进程 (process) 还有另一个名字任务 (task)
2、操作系统是如何管理进程的?
- 先描述一个进程 (明确出一个进程上面的一些相关属性)
- 再组织若干个进程 (使用一些数据结构,把很多描述进程的信息给放到一起,方便进行增删改查)
描述进程:操作系统里面主要都是通过 C/C++来实现的,此处的描述其实就是用的C语言中的 “结构体” (也就和Java的类差不多)
**操作系统中描述进程的这个结构体, "PCB" (process control block),进程控制块,这个东西不是硬件中的那个PCB板
组织进程:典型的实现,就是使用双向链表来把每个进程的PCB给串起来
操作系统的种类是很多的,内部的实现也是各有不同,咱们此处所讨论的情况,是以Linux这个系统为例,由于windows, mac 这样的系统,不是开源的,里面的情况我们并不知道
3、PCB中的一些属性:
1、pid (进程id)
进程的身份标识,进程的身份证号

2、内存指针
指明了这个进程要执行的代码 / 指令在内存的哪里,以及这个进程执行中依赖的数据都在哪里
当运行一个exe,此时操作系统就会把这个 exe 加载到内存中,变成进程
进程要执行的二进制指令 (通过编译器生成的), 除了指令之外还有一些重要的数据
3、文件描述符表:
程序运行过程中,经常要和文件打交道 (文件是在硬盘上的)
文件操作:打开文件,读/写文件,关闭文件
进程每次打开一个文件,就会在文件描述符表上多增加一项,(个文件描述符表就可以视为是一个数组,里面的每个元素,又是一个结构体,就对应一个文件的相关信息)
一个进程只要一启动,不管你代码中是否写了打开 / 操作文件的代码,都会默认的打开三个文件 (系统自动打开的),标准输入(System.in),准输出(System.out) 标准错误(System.err)
要想能让一个进程正常工作,就需要给这个进程分配一些系统资源:内存,硬盘,CPU
这个文件描述符表的下标,就称为文件描述符
4、进程调度:
- 上面的属性是一些基础的属性,下面的一组属性,主要是为了能够实现进程调度
进程调度:是理解进程管理的重要话题,现在的操作系统,一般都是 “多任务操作系统”(前身就是 “单任务操作系统”,同一时间只能运行一个进程),一个系统同一时间,执行了很多的任务
5、并行和并发:
- 并行:微观上,两个CPU核心,同时执行两个任务的代码
- 并发:微观上, 一个CPU核心,先执行一会任务1, 再执行一会任务,再执行一会任务…再执行一会任务
只要切换的足够快, 宏观上看起来, 就好像这么多任务在同时执行一样
并行和并发这两件事, 只是在微观上有区分
宏观上咱们区分不了,微观上这里的区分都是操作系统自行调度的结果
例如6个核心,同时跑20个任务
这20个任务, 有些是并行的关系, 有些是并发的关系。可能任务A和任务B,一会是并行, 一会是并发….都是微观上操作系统在控制的,在宏观上感知不到
正因为在宏观上区分不了并行并发, 我们在写代码的时候也就不去具体区分这两个词实际上通常使用 “并发” 这个词, 来代指并行+并发
咱们只是在研究操作系统进程调度这个话题上的时候, 稍作区分但是其他场景上基本都是使用并发作为一个统称来代替的,并发编程
4、CPU 分配 —— 进程调度(Process Scheduling)
6、调度
所谓的调度就是 “时间管理”,
并发就是规划时间表的过程,也就是“调度"的过程
7、状态
状态就描述了当前这个进程接下来应该怎么调度
- 就绪状态:随时可以去 CPU 上执行
- 阻塞状态 / 睡眠状态:暂时不可以去CPU上执行
Linux中的进程状态还有很多其他的…
8、优先级
先给谁分配时间,后给谁分配时间,以及给谁分的多,给谁分的少…
9、记账信息
统计了每个进程,都分别被执行了多久,分别都执行了哪些指令,分别都排队等了多久了…
给进程调度提供指导依据的
10、上下文
就表示了上次进程被调度出 CPU 的时候,当时程序的执行状态。下次进程上CPU的时候,就可以恢复之前的状态,然后继续往下执行
进程被调度出CPU之前,要先把CPU中的所有的寄存器中的数据都给保存到内存中 (PCB的上下文字段中) ,相当于存档了
下次进程再被调度上CPU的时候,就可以从刚才的内存中恢复这些数据到寄存器中,相当于读档了
存档+读档,存档存储的游戏信息,就称为 “上下文”
5、内存分配 —— 内存管理(Memory Manage)
进程的调度,其实就是操作系统在考虑CPU资源如何给各个进程分配
那内存资源又是如何分配的呢?
11、虚拟地址空间:
由于操作系统上,同时运行着很多个进程,如果某个进程,出现了bug 进程崩溃了,是否会影响到其他进程呢?
现代的操作系统 (windows, linux, mac… ) ,能够做到这一点,就是 “进程的独立性” 来保证的,就依仗了"虚拟地址空间"
例:如果某个居民核酸变成阳性了,是否会影响到其他的居民呢?
一旦发现有人阳性了,就需要立刻封楼封小区,否则就会导致其他人也被传染,
这个情况就类似于早期的操作系统,早期的操作系统,里面的进程都是访问同一个内存的地址空间。如果某个进程出现 bug,把某个内存的数据给写错了,就可能引起其他进程的崩溃
解决方案,就是把这个院子,给划分出很多的道路
这些道路之间彼此隔离开,每个人走各自的道理,这个时候就没事了,此时即使有人确诊,也影响不到别人了,
如果把进程按照虚拟地址空间的方式给划分出了很多份,这个时候不是每一份就只剩一点了嘛?? 虽然你的系统有百八十个进程,但是实际上从微观上看,同时执行的进程,就6个!!
每个进程能够捞着的内存还是挺多的,而且另一方面,也不是所有的进程都用那么多的内存,有的进程 (一个3A游戏,吃几个G),大多数的进程也就只占几M即可
6、进程间通信(Inter Process Communication)
12、进程间通信
进程之间现在通过虚拟地址空间,已经各自隔离开了,但是在实际工作中,进程之间有的时候还是需要相互交互的。
例:某业主A问:兄弟们,谁家有土豆,借我两个
业主B回答:我有土豆,我给你
设定一个公共空间,这个空间是任何居民都可以来访问的,
让B先把土豆放到公共空间中,进行消毒,再让A来把这个公共空间的土豆给取走,彼此就不容易发生传染
类似的,咱们的两个进程之间,也是隔离开的,也是不能直接交互的,操作系统也是提供了类似的 "公共空间”,
进程 A 就可以把数据见放到公共空间上,进程B再取走
进程间通信:
操作系统中,提供的 “公共空间” 有很多种,并且各有特点,有的存储空间大,有的小,有的速度快,有的慢.….
操作系统中提供了多种这样的进程间通信机制,(有些机制是属于历史遗留的,已经不适合于现代的程序开发)
现在最主要使用的进程间通信方式两种:
1.文件操作
2.网络操作 (socket)
总结:
四、多线程
1、线程(Thread)
为啥要有进程?因为我们的系统支持多任务了,程序猿也就需要 “并发编程”
通过多进程,是完全可以实现并发编程的,但是有点小问题:
如果需要频繁的创建而 / 销毁进程,这个事情成本是比较高的,如果需要频繁的调度进程,这个事情成本也是比较高的:
对于资源的申请和放,本身就是一个比较低效的操作,
创建进程就得分配资源:
1)内存
2)文件
销毁进程也得释放资源
1)内存
2)文件
如何解决这个问题?思路有两个:
- 进程池: (如数据库连接池,字符串常量池)
进程池虽然能解决上述问题,提高效率。同时也有问题:池子里的闲置进程,不使用的时候也在消耗系统资源,消耗的系统资源太多了 - 使用线程来实现并发编程:
线程比进程更轻量,每个进程可以执行一个任务,每个线程也能执行一个任务 (执行一段代码),也能够并发编程,
创建线程的成本比创建进程要低很多。销毁线程,的成本也比销毁进程低很多。调度线程,的成本也比调度进程低很多。
在Linux上也把线程称为轻量级进程(LWP light weight process)
2、为什么线程比进程更轻量?
- 进程重量是重在哪里:重在资源申请释放 (在仓库里找东西…)
- 线程是包含在进程中的,一个进程中的多个线程,共用同一份资源 (同一份内存+文件)
只是创建进程的第一个线程的时候 (由于要分配资源)成本是相对高的,后续这个进程中再创建其他线程,这个时候成本都是要更低一些,所以为什么更轻量?少了申请释放资源的过程
可以把进程比作一个工厂,假设这个工厂有一些生产任务,例如要生产 1w 部手机
要想提高生产效率:
1). 搞两个工厂,一个生产 5k (多创建了一个进程)
2). 还是一个工厂,在一个工厂里多加一个生产线,两个生产线并行生产,一个生产线生产5k,(多创建了一个线程)
最终生产1w个手机,花的时间差不多,但是这里的成本就不一样了
多加一些线程,是不是效率就会进一步提高呢?一般来说是会,但是也不一定
如果线程多了,这些线程可能要竞争同一个资源,这个时候,整体的速度就收到了限制,整体硬件资源是有限的
总结进程与线程的区别:
- 进程包含线程,一个进程里可以有一个线程,也可以有多个线程
- 进程和线程都是为了处理
并发编程这样的场景
但是进程有问题,频繁创建和释放的时候效率低,相比之下,线程更轻量,创建和释放效率更高。为啥更轻量?少了申请释放资源的过程 - 操作系统创建进程,要给进程分配资源,进程是操作系统分配资源的基本单位
操作系统创建的线程,是要在CPU上调度执行,线程是操作系统调度执行的基本单位,(前面讲的时间管理,当时咱们是调度的进程,但是更准确的说,其实是调度的线程)- 调度的进程:前面的例子相当于是每个进程里,只有一个线程了,可以视为是在调度进程,但是如果进程里有多个线程,更严谨的说法,还是以线程为单位进行调度
- 进程具有独立性,每个进程有各自的虚拟地址空间,一个进程挂了,不会影响到其他进程。
同一个进程中的多个线程,共用同一个内存空间,一个线程挂了,可能影响到其他线程的,甚至导致整个进程崩溃
Java这个生态中更常使用的并发编程方式,是多线程
其他的语言,主打的并发变成又不一样:
go,主要是通过多协程的方式实现并发.
erlang,这个是通过 actor 模型实现并发.
JS,是通过定时器+事件回调的方式实现并发.……
多线程仍然是最主流最常见的一种并发编程的方式
五、Java 多线程编程
Java 的线程 和 操作系统线程 的关系:
- 线程是操作系统中的概念,操作系统内核实现了线程这样的机制,并且对用户层提供了一些 API 供用户使用 (例如 Linux 的 pthread 库),
在 Java 标准库 中,就提供了一个Thread类,来表示 / 操作线程,Thread 类可以视为 Java 标准库提供的 API, 对操作系统提供的 API 进行了进一步的抽象和封装 - 创建好的
Thread实例,其实和操作系统中的线程是一 一对应的关系,操作系统提供了一组关于线程的API(C语言风格),Java对于这组API进一步封装了,就成了Thread类
1、第一个多线程程序
Thread类的基本用法
通过 Thread 类创建线程,写法有很多种
其中最简单的做法,创建子类,继承自Thread,并且重写 run 方法
package thread;
class MyThread extends Thread {
@Override
public void run() {
System.out.println("hello thread!");;
}
}
public class demo1 {
public static void main(String[] args) {
Thread t = new MyThread();
t.start();
}
}
run 方法描述了,这个线程内部要执行哪些代码,每个线程都是并发执行的 (各自执行各自的代码),因此就需要告知这个线程,你执行的代码是什么,
run 方法中的逻辑,是在新创建出来的线程中,被执行的代码
并不是我一定义这个类,一写run方法,线程就创建出来,相当于我把活安排出来了,但是同学们还没开始干呢
需要调用这里的 start 方法,才是真正的在系统中创建了线程,才是真正开始执行上面的 run 操作,在调用 start 之前,系统中是没有创建出线程的
2、线程之间是并发执行的
如果在一个循环中不加任何限制,这个循环转的速度非常非常快,导致打印的东西太多了,根本看不过来了,就可以加上一个 sleep 操作,来强制让这个线程休眠一段时间
这个休眠操作,就是强制地让线程进入阻塞状态,单位是 ms,就是1s 之内这个线程不会到 cpu 上执行
public void run() {
while (true) {
System.out.println("hello thread!");
Thread.sleep(1000);
}
}
这是多线程编程中最常见的一个异常,线程被强制的中断了,用 try catch 处理
在一个进程中,至少会有一个线程,
在一个 java进程中,也是至少会有一个调用 main 方法的线程 (这个线程不是你手动搞出来的)
自己创建的 t 线程 和 自动创建的 main 线程,就是并发执行的关系 (宏观上看起来是同时执行)
此处的并发 = 并行 + 并发
宏观上是区分不了并行和并发的,都取决于系统内部的调度
package thread;
// Thread是在java.lang 里的,java.lang 里的类都不需要手动导入,类似的还有String
class MyThread2 extends Thread {
@Override
public void run() {
while (true) {
System.out.println("hello thread!");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class demo2 {
public static void main(String[] args) {
Thread t = new MyThread2();
t.start();
while (true) {
System.out.println("hello main");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
运行打印:
/* hello main
hello thread!
hello thread!
hello main
hello main
hello thread!
hello thread!
hello main */
现在两个线程,都是打印一条,就休眠 1s
当1s 时间到了之后,系统先唤醒谁呢?
看起来这个顺序不是完全确定 (随机的)
每一轮,1s 时间到了之后,到底是先唤醒 main 还是 thread,这是不确定的 (随机的)
操作系统来说,内部对于线程之间的调度顺序,在宏观上可以认为是随机的 (抢占式执行)
这个随机性,会给多线程编程带来很多其他的麻烦
3、Thread 类创建线程的写法
写法一: 创建子类,继承自 Thread
写法二: 创建一个类,实现 Runnable 接口,再创建 Runnable实例传给Thread 实例
通过 Runnable 来描述任务的内容
进—步的再把描述好的任务交给Thread 实例
package thread;
// Runnable 就是在描述一个任务
class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println("hello");
}
}
public class demo3 {
public static void main(String[] args) {
Thread t = new Thread(new MyRunnable());
}
}
写法三 / 写法四: 就是上面两个写法的翻版,使用了匿名内部类
创建了一个匿名内部类,继承自 Thread 类,同时重写run方法,同时再new出这个匿名内部类的实例
package thread;
public class demo4 {
public static void main(String[] args) {
Thread t = new Thread() {
@Override
public void run() {
System.out.println("hello thread!");
}
};
t.start();
}
}
new 的是Runnable,针对这个创建的匿名内部类,同时new 出的 Runnable` 实例传给 Thread 的构造方法
package thread;
public class demo5 {
public static void main(String[] args) {
Thread t = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("hello thread!");
}
});
t.start();
}
}
通常认为Runnable 这种写法更好一点,能够做到让线程和线程执行的任务,更好的进行解耦
写代码一般希望,高内聚,低耦合
Runnable 单纯的只是描述了一个任务,至于这个任务是要通过一个进程来执行,还是线程来执行,还是线程池来执行,还是协程来执行,Runnable 本身并不关心,Runnable 里面的代码也不关心
第五种写法: 相当于是第四种写法的延伸,使用 lambda 表达式,是使用lambda 代替了 Runnable 而已
package thread;
public class demo6 {
public static void main(String[] args) {
Thread t = new Thread(() -> {
System.out.println("hello thread!");
});
t.start();
}
}
多线程能够提高任务完成的效率
测试:有两个整数变量,分别要对这俩变量自增10亿次,分别使用一个线程,和两个线程
此处不能直接这么记录结束时间,别忘了,现 在这个求时间戳的代码是在 main 线程中
main 和t1 ,t2 之间是并发执行的关系,此处t1和t2 还没执行完呢,这里就开始记录结束时间了,这显然是不准确的
正确做法应该是让main线程等待 t1和 t2 跑完了,再来记录结束时间
join 效果就是等待线程结束,t1.join就是让main 线程等待t1 结束,t2.join让 main 线程等待 t2结束
package thread;
public class demo7 {
private static final long count = 10_0000_0000;
public static void serial() {
long begin = System.currentTimeMillis();
long a = 0;
for (int i = 0; i < count; i++) {
a++;
}
long b = 0;
for (int i = 0; i < count; i++) {
b++;
}
long end = System.currentTimeMillis();
System.out.println("消耗时间: " + (end- begin) + "ms");
}
public static void concurrency() throws InterruptedException {
long begin = System.currentTimeMillis();
Thread t1 = new Thread(() -> {
long a = 0;
for (int i = 0; i < count; i++) {
a++;
}
});
t1.start();
Thread t2 = new Thread(() -> {
long b = 0;
for (int i = 0; i < count; i++) {
b++;
}
});
t2.start();
t1.join(); // 让 main 线程等待 t1 结束
t2.join(); // 让 main 线程等待 t2 结束
long end = System.currentTimeMillis();
System.out.println("消耗时间: " + (end- begin) + "ms");
}
public static void main(String[] args) throws InterruptedException {
// serial();
concurrency();
}
}
串行执行的时候,时间大概是600多ms (平均650左右)
两个线程并发执行,时间大概是400多ms (平均450左右)
提升了接近50%
并不是说,一个线程600多ms,两个线程就是300多ms
这俩线程在底层到底是并行执行,还是并发执行,不确定,真正并行执行的时候,效率才会有显著提升
多线程特别适合于那种CPU密集型的程序,程序要进行大量的计算,使用多线程就可以更充分的利用CPU的多核资源
六、Thread类的其他的属性和方法
1、Thread 的常见构造方法
| 方法 | 说明 |
|---|---|
| Thread() | 创建线程对象 |
| Thread(Runnable target) | 使用 Runnable 对象创建线程对象 |
| Thread(String name) | 创建线程对象,并命名 |
| Thread(Runnable target, String name) | 使用 Runnable 对象创建线程对象,并命名 |
| 【了解】Thread(ThreadGroup group, Runnable target) | 线程可以被用来分组管理,分好的组即为线程组,这 个目前我们了解即可 |
Thread(String name):这个东西是给线程 (thread对象) 起一个名字,起一个啥样的名字,不影响线程本身的执行
仅仅只是影响到程序猿调试,可以借助一些工具看到每个线程以及名字,很容易在调试中对线程做出区分
可以使用 jconsole 来观察线程的名字,jconsole是jdk自带的一个调试工具

jconsole 这里能够罗列出你系统上的java进程(其他进程不行)



2、Thread 的几个常见属性
| 属性 | 获取方法 |
|---|---|
| ID | getId() |
| 名称 | getName() |
| 状态 | getState() |
| 优先级 | getPriority() |
| 是否后台线程 | isDaemon() |
| 是否存活 | isAlive() |
| 是否被中断 | isInterrupted( |
是否后台线程:isDaemon()
如果线程是后台线程,不影响进程退出
如果线程不是后台线程 (前台线程),就会影响到进程退出
创建的 t1 和 t2 默认都是前台的线程
即使 main 方法执行完毕,进程也不能退出,得等 t1 和 t2 都执行完,整个进程才能退出!
如果 t1 和 t2 是后台线程,此时如果 main 执行完毕,整个进程就直接退出,t1 和 t2 就被强行终止了
是否存活: isAlive()
操作系统中对应的线程是否正在运行
Thread t 对象的生命周期和内核中对应的线程,生命周期并不完全一致
创建出t对象之后,在调用 start 之前,系统中是没有对应线程的
在run方法执行完了之后,系统中的线程就销毁了,但是t这个对象可能还存在,通过 isAlive就能判定当前系统的线程的运行情况
如果调用 start之后,run执行完之前,isAlive 就是返回true 。如果调用start 之前,run执行完之后,isAlive 就返回 false
ID是线程的唯一标识,不同线程不会重复
名称是各种调试工具用到
优先级高的线程理论上来说更容易被调度到
关于后台线程,需要记住一点:JVM会在一个进程的所有非后台线程结束后,才会结束运行。
是否存活,即简单的理解,为 run 方法是否运行结束了
public class ThreadDemo {
public static void main(String[] args) {
Thread thread = new Thread(() -> {
for (int i = 0; i < 10; i++) {
try {
System.out.println(Thread.currentThread().getName() + ": 我还活着");
Thread.sleep(1 * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println(Thread.currentThread().getName() + ": 我即将死去");
});
System.out.println(Thread.currentThread().getName()
+ ": ID: " + thread.getId());
System.out.println(Thread.currentThread().getName()
+ ": 名称: " + thread.getName());
System.out.println(Thread.currentThread().getName()
+ ": 状态: " + thread.getState());
System.out.println(Thread.currentThread().getName()
+ ": 优先级: " + thread.getPriority());
System.out.println(Thread.currentThread().getName()
+ ": 后台线程: " + thread.isDaemon());
System.out.println(Thread.currentThread().getName()
+ ": 活着: " + thread.isAlive());
System.out.println(Thread.currentThread().getName()
+ ": 被中断: " + thread.isInterrupted());
thread.start();
while (thread.isAlive()) {}
System.out.println(Thread.currentThread().getName()
+ ": 状态: " + thread.getState());
}
}
3、Thread中的一些重要方法
3.1、启动一个线程-start()
start() 决定了系统中是不是真的创建出线程
start 和 run 的区别:
run()单纯的只是一个普通的方法,描述了任务的内容start()则是一个特殊的方法,内部会在系统中创建线程
package thread;
public class demo1 {
public static void main(String[] args) {
Thread t = new Thread(() -> {
while (true) {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
// t.run();
while (true) {
System.out.println("hello main");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
用 start() 是并发执行,而 run()循环打印 hello thread
run方法只是一个普通的方法,你在main线程里调用run,其实并没有创建新的线程,这个循环仍然是在 main 线程中执行的
既然是在一个线程中执行,代码就得从前到后的按顺序运行,运行第一个循环,再运行第二个循环
for (int i = 0; i < 5; i++) {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
如果改成循环五次,打印五个 hello thread,让后打印 hello main
3.2、中断一个线程
中断线程:让一个线程停下来
线程停下来的关键,是要让线程对应的 run方法执行完
还有一个特殊的是 main 这个线程,对于main 来说,得是main方法执行完,线程就完了)
如何中断线程:
1、标志位
可以手动的设置一个标志位 (自己创建的变量,boolean),来控制线程是否要执行结束
package thread;
public class demo2 {
private static boolean isQuit = false;
public static void main(String[] args) {
Thread t = new Thread(() -> {
while (!isQuit) {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
// 只要把这个 isQuit 设为true,这个循环就退出了,进一步的 run 就执行完了,再进一步就是线程执行结束了
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
isQuit = true;
System.out.println("终止 t 线程!");
}
}
运行输出:
hello thread
hello thread
hello thread
hello thread
hello thread
终止 t 线程!
在其他线程中控制这个标志位,就能影响到这个线程的结束
此处因为,多个线程共用同一个虚拟地址空间,因此,main 线程修改的 isQuit 和 t 线程判定的 isQuit,是同一个值
2、interrupted()
但是,isQuit 并不严谨,更好的做法,使用 Thread 中内置的一个标志位来进行判定
Thread.interrupted() 这是一个静态的方法
Thread.currentThread().isInterrupted() 这是实例方法,其中 currentThread 能够获取到当前线程的实例
package thread;
public class demo3 {
public static void main(String[] args) {
Thread t = new Thread(() -> {
while (!Thread.currentThread().isInterrupted()) {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 在主线程中,调用 interrupt 方法,中断这个线程
// 让 t 线程被中断
t.interrupt();
}
}
运行此代码,打印五次 hello thread 后,出现异常,然后继续打印 hello thread
调用 t.interrupt() 这个方法,可能产生两种情况:
1). 如果 t 线程是处在就绪状态,就是设置线程的标志位为 true
2). 如果 t 线程处在阻塞状态 (sleep 休眠了),就会触发一个 InterruptException
这个代码绝大部分情况,都是在休眠状态阻塞
此处的中断,是希望能够立即产生效果的
如果线程已经是阻塞状态下,此时设置标志位就不能起到及时唤醒的效果
调用这个 interrupt 方法,就会让 sleep 触发一个异常,从而导致线程从阻塞状态被唤醒
当下的代码,一旦触发了异常之后,就进入了catch 语句,在catch 中,就单纯的只是打了一个日志
printStackTrace 是打印当前出现异常位置的代码调用栈,打完日志之后,就直接继续运行
解决方法:
package thread;
public class demo3 {
public static void main(String[] args) {
Thread t = new Thread(() -> {
while (!Thread.currentThread().isInterrupted()) {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
// 当前触发异常后,立即退出循环
System.out.println("这个是收尾工作");
break;
}
}
});
t.start();
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 在主线程中,调用 interrupt 方法,中断这个线程
// 让 t 线程被中断
t.interrupt();
}
}
运行结果:
hello thread
hello thread
hello thread
hello thread
hello thread
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at thread.demo3.lambda$main$0(demo3.java:9)
at java.lang.Thread.run(Thread.java:748)
这个是收尾工作
推荐的做法:
咱们一个代码中的线程有很多个,随时哪个线程都可能会终止
Thread.interrupted() 这个方法判定的标志位是Thread的static成员,一个程序中只有一个标志位
Thread.currentThread().isInterrupted()这个方法判定的标志位是 Thread的普通成员,每个示例都有自己的标志位,一般就无脑使用这个方法即可
| 方法 | 说明 |
|---|---|
| public void interrupt() | 中断对象关联的线程,如果线程正在阻塞,则以异常方式通知, 否则设置标志位 |
| public static boolean interrupted() | 判断当前线程的中断标志位是否设置,调用后清除标志位 |
| public boolean isInterrupted() | 判断对象关联的线程的标志位是否设置,调用后不清除标志位 |
3.3、线程等待-join()
多个线程之间,调度顺序是不确定的,线程之间的执行是按照调度器来安排的,这个过程可以视为是 “无序,随机”,这样不太好,有些时候,我们需要能够控制线程之间的顺序
线程等待,就是其中一种控制线程执行顺序的手段
此处的线程等待,主要是控制线程结束的先后顺序
join():调用 join 的时候,哪个线程调用的 join ,哪个线程就会阻塞等待,要等到对应的线程执行完毕为止 (对应线程的 run 执行完)
package thread;
public class demo4 {
public static void main(String[] args) {
Thread t = new Thread(() -> {
for (int i = 0; i < 5; i++) {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
// 在主线程中,使用等待操作,等 t 线程执行结束
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
首先,调用这个方法的线程是 main 线程,针对t这个线程对象调用的,此时就是让 main 等待t
调用 join 之后,main 线程就会进入阻塞状态 (暂时无法在cpu上执行)
代码执行到 join` 这一行,就暂时停下了,不继续往下执行了
那么join什么时候能继续往下走,恢复成就绪状态呢?
就是等到 t 线程执行完毕 ( t 的 run方法跑完了)
通过线程等待,就是在**控制让** t先结束,main 后结束,一定程度上的干预了这两个线程的执行顺序
这是代码中控制的先后顺序,就像刚才写的自增 100 亿次这个代码,计时操作就是要在计算线程执行完之后再执行
但是 join 操作默认情况下,是死等,不见不散,这不合理
join 提供了另外一个版本,就是可以设置等待时间,最长等待多久,如果等不到,就不等了
try {
t.join(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
进入 join 也会产生阻塞,这个阻塞不会一直持续下去,如果 10s 之内,t线程结束了,此时 join直接返回
如果10s之后,t 仍然不结束, 此时join 也就直接返回
日常开发中涉及到的一些 "等待” 相关的操作,一般都不会是死等,而是会有这样的 "超时时间"
3.4、获取当前线程的引用
Thread.currentThread() 就能够获取到当前线程的引用 (Thread 实例的引用),哪个线程调用的这个currentThread,就获取到的是哪个线程的实例
package thread;
public class demo5 {
public static void main(String[] args) {
Thread t = new Thread(){
@Override
public void run() {
System.out.println(Thread.currentThread().getName()); // Thread-0
}
};
t.start();
// 在 main 线程中调用的,拿到的就是 main 这个线程的实例
System.out.println(Thread.currentThread().getName()); // main
}
}
this.getName() :对于这个代码来,是通过继承 Thread 的方式来创建线程
此时在 run 方法中,直接通过 this,拿到的就是当前 Thread 的实例
Thread t = new Thread(){
@Override
public void run() {
System.out.println(this.getName());
}
};
t.start();
此处的 this 不是指向 Thread 类型了,而是指向 Runnable,而 Runnable 只是一个单纯的任务,没有 name 属性的
Thread t = new Thread(new Runnable() {
@Override
public void run() {
System.out.println(this.getName()); // err
}
});
t.start();
要想拿到线程的名字,只能通过 Thread.currentThread()
lambda 表达式效果同 Runnable
Thread t = new Thread(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName());
}
});
t.start();
3.5、休眠当前线程
sleep 所谓的休眠到底是在干啥?
进程:PCB+双向链表,这个说法是针对只有一个线程的进程是如此的
如果是一个进程有多个线程,此时每个线程都有一个PCB,一个进程对应的就是一组PCB了
PCB 上有一个字段tgroupld,这个id其实就相当于进程的id,同一个进程中的若干个线程的 tgroupld 是相同的
process control block
进程控制块 和 线程有啥关系?其实 Linux内核不区分进程和线程
进程线程是程序猿写应用程序代码,搞出来的词,实际上 Linux内核只认PCB !
在内核里 Linux 把线程称为轻量级进程

如果某个线程调用了sleep 方法,这个 PCB 就会进入到阻塞队列
操作系统调度线程的时候,就只是从就绪队列中挑选合适的 PCB 到 CPU 上运行,阻塞队列里的 PCB 就只能干等着,当睡眠时间到了,系统就会把刚才这个 PCB 从阻塞队列挪回到就绪队列,以上情况都是在 Linux 系统
内核中的很多工作都依赖大量的数据结构,但凡是需要管理很多数据的程序,都大量的依赖数据结构
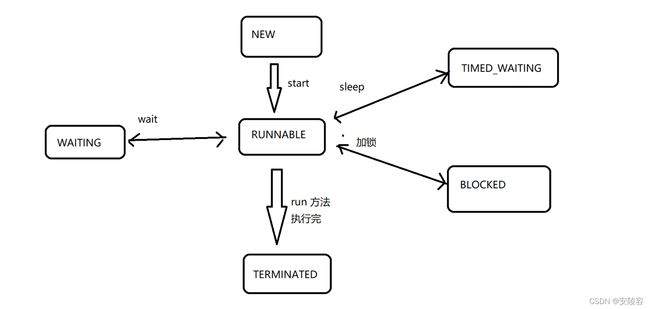
4、线程的状态
进程有状态:就绪,阻塞
这里的状态就决定了系统按照啥样的态度来调度这个进程,这里相当于是针对一个进程中只有一个线程的情况
更常见的情况下,一个进程中包含了多个线程,所谓的状态,其实是绑定在线程上
Linux 中,PCB 其实是和线程对应的,一个进程对应着一组 PCB
上面说的 “就绪" 和 “阻塞” 都是针对系统层面上的线程的状态 (PCB)
在 Java 中Thread 类中,对于线程的状态,又进—步的细化了
1、 NEW:安排了工作, 还未开始行动
把 Thread 对象创建好了,但是还没有调用 start
public class demo6 {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(() -> {
});
System.out.println(t.getState()); // NEW
t.start();
}
}
2、 TERMINATED:工作完成了
操作系统中的线程已经执行完毕,销毁了但是 Thread 对象还在,获取到的状态
public class demo6 {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(() -> {
});
t.start();
Thread.sleep(1000);
System.out.println(t.getState()); // TERMINATED
}
}
以上两个状态是 Java 内部搞出来的状态,就和操作系统中的 PCB 里的状态就没啥关系
3、 RUNNABLE:可工作的,又可以分成正在工作中和即将开始工作
就绪状态,处于这个状态的线程,就是在就绪队列中,随时可以被调度到 CPU 上
如果代码中没有进行 sleep,也没有进行其他的可能导致阻塞的操作,代码大概率是处在 Runnable 状态的
public class demo7 {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(() -> {
while (true) {
// 这里什么都不能有
}
});
t.start();
Thread.sleep(1000);
System.out.println(t.getState()); // RUNNABLE
}
}
一直持续不断的执行这里的循环,随时系统想调度它上cpu都是随时可以的
4、TIMED_WAITING:这几个都表示排队等着其他事情
代码中调用了sleep,就会进入到 TIMED_WAITIN,意思就是当前的线程在一定时间之内,是阻塞的状态
public class demo7 {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(() -> {
while (true) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
Thread.sleep(1000);
System.out.println(t.getState()); // TIMED_WAITING
}
}
一定时间到了之后,阻塞状态解除这种情况就是 TIMED_WAITING,也是属于阻塞的状态之一
5、BLOCKED:这几个都表示排队等着其他事情
当前线程在等待锁,导致了阻塞(阻塞状态之一) --synchronized
6、WAITING:这几个都表示排队等着其他事情
当前线程在等待唤醒,导致了阻塞(阻塞状态之一) --wait
为啥要这么细分?这是非常有好处的:
开发过程中经常会遇到一种情况,程序 "卡死” 了
一些关键的线程,阻塞了
在分析卡死原因的时候,第一步就可以先来看看当前程序里的各种关键线程所处的状态
5、线程状态转换简图