Linux性能调优 —— CPU性能
一、到底应该怎么理解“平均负载”?
1、uptime 查询平均负载
$ uptime
02:34:03 up 2 days, 20:14, 1 user, load average: 0.63, 0.83, 0.88
02:34:03 // 当前时间
up 2 days, 20:14 // 系统运行时间
1 user // 正在登录用户数
最后三个数字呢,依次则是过去 1 分钟、5 分钟、15 分钟的平均负载
# -d 参数表示高亮显示变化的区域
$ watch -d uptime
..., load average: 1.00, 0.75, 0.39
2、查询系统有几个 CPU
# 关于 grep 和 wc 的用法请查询它们的手册或者网络搜索
$ grep 'model name' /proc/cpuinfo | wc -l
# 更直观的命令
$ lscpu
3、用 iostat、mpstat、pidstat 等工具
需要预先安装 stress 和 sysstat 包
yum install -y stress sysstat
stress
系统压力测试工具
模拟一个 CPU 使用率 100% 的场景
$ stress --cpu 1 --timeout 600
模拟 I/O 压力,即不停地执行 sync
$ stress -i 1 --timeout 600
模拟大量进程的场景,模拟的是 8 个进程
$ stress -c 8 --timeout 600
mpstat
多核 CPU 性能分析工具,用来实时查看每个 CPU 的性能指标
# -P ALL 表示监控所有 CPU,后面数字 5 表示间隔 5 秒后输出一组数据
$ mpstat -P ALL 5
pidstat
进程性能分析工具,用来实时查看进程的 CPU、内存、I/O 以及上下文切换等性能指标
用法:http://einverne.github.io/post/2019/05/pidstat-usage.html
# 间隔 5 秒后输出一组数据
$ pidstat -u 5 1
4、拓展工具
lsof 系统工具
https://www.cnblogs.com/sparkbj/p/7161669.html
htop
https://www.cnblogs.com/programmer-tlh/p/11726016.html
# 需要安装
$ yum install -y htop
# 跟top一样使用
$ htop
atop
https://www.cnblogs.com/DataArt/p/10344438.html
# 需要安装
$ yum install -y atop
# 跟top一样使用
$ atop
二、CPU上下文切换
1、CPU 上下文
CPU 寄存器,是 CPU 内置的容量小、但速度极快的内存。而程序计数器,则是用来存储 CPU 正在执行的指令位置、或者即将执行的下一条指令位置。它们都是 CPU 在运行任何任务前,必须的依赖环境,因此也被叫做 CPU 上下文
2、CPU 上下文切换
CPU 上下文切换,就是先把前一个任务的 CPU 上下文(也就是 CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
而这些保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加载进来。这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行。
根据任务的不同,CPU 的上下文切换就可以分为几个不同的场景,也就是进程上下文切换、线程上下文切换以及中断上下文切换
3、怎么查看系统的上下文切换情况
vmstat
是一个常用的系统性能分析工具,主要用来分析系统的内存使用情况,也常用来分析 CPU 上下文切换和中断的次数
# 每隔 5 秒输出 1 组数据
[root@myhost-001 ~]# vmstat 5
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 283544 2108 416380 0 0 73 29 131 99 0 0 99 0 0
0 0 0 283520 2108 416380 0 0 0 0 22 47 0 0 100 0 0
0 0 0 283520 2108 416380 0 0 0 0 19 44 0 0 100 0 0
0 0 0 283520 2108 416380 0 0 0 0 23 51 0 0 100 0 0
cs(context switch)是每秒上下文切换的次数。
in(interrupt)则是每秒中断的次数。
r(Running or Runnable)是就绪队列的长度,也就是正在运行和等待 CPU 的进程数。
b(Blocked)则是处于不可中断睡眠状态的进程数。
pidstat
查看每个进程的详细情况
# 每隔 5 秒输出 1 组数据
[root@myhost-001 ~]# pidstat -w 5
Linux 3.10.0-957.21.3.el7.x86_64 (myhost-001) 2020年08月20日 _x86_64_ (1 CPU)
11时44分36秒 UID PID cswch/s nvcswch/s Command
11时44分41秒 0 3 0.60 0.00 ksoftirqd/0
11时44分41秒 0 9 0.80 0.00 rcu_sched
11时44分41秒 0 11 0.20 0.00 watchdog/0
一个是 cswch ,表示每秒自愿上下文切换(voluntary context switches)的次数,
另一个则是 nvcswch ,表示每秒非自愿上下文切换(non voluntary context switches)的次数
- 所谓自愿上下文切换,是指进程无法获取所需资源,导致的上下文切换。比如说, I/O、内存等系统资源不足时,就会发生自愿上下文切换。
- 而非自愿上下文切换,则是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如说,大量进程都在争抢 CPU 时,就容易发生非自愿上下文切换。
# 每隔 1 秒输出 1 组数据(需要 Ctrl+C 才结束)
# -w 参数表示输出《进程》切换指标,而 -u 参数则表示输出 CPU 使用指标
$ pidstat -w -u 1
# 每隔 1 秒输出一组数据(需要 Ctrl+C 才结束)
# -wt 参数表示输出《线程》的上下文切换指标
$ pidstat -wt 1
sysbench
模拟系统多线程调度 预先安装 sysbench 和 sysstat 包,如 apt install sysbench sysstat
# 以 10 个线程运行 5 分钟的基准测试,模拟多线程切换的问题
$ sysbench --threads=10 --max-time=300 threads run
/proc/interrupts
怎样才能知道中断发生的类型呢?
就是从 /proc/interrupts 这个只读文件中读取。/proc 实际上是 Linux 的一个虚拟文件系统,用于内核空间与用户空间之间的通信。/proc/interrupts 就是这种通信机制的一部分,提供了一个只读的中断使用情况
# -d 参数表示高亮显示变化的区域
$ watch -d cat /proc/interrupts
重调度中断(RES),这个中断类型表示,唤醒空闲状态的 CPU 来调度新的任务运行。这是多处理器系统(SMP)中,调度器用来分散任务到不同 CPU 的机制,通常也被称为处理器间中断(Inter-Processor Interrupts,IPI)
4、总结
- 自愿上下文切换变多了,说明进程都在等待资源,有可能发生了 I/O 等其他问题;
- 非自愿上下文切换变多了,说明进程都在被强制调度,也就是都在争抢 CPU,说明 CPU 的确成了瓶颈;
- 中断次数变多了,说明 CPU 被中断处理程序占用,还需要通过查看 /proc/interrupts 文件来分析具体的中断类型。
三、CPU使用率居然达到100%,我该怎么办?
1、CPU 使用率
节拍率
节拍率 HZ 是内核的可配选项,可以设置为 100、250、1000 等。不同的系统可能设置不同数值,你可以通过查询 /boot/config 内核选项来查看它的配置值。比如在我的系统中,节拍率设置成了 250,也就是每秒钟触发 250 次时间中断
$ grep 'CONFIG_HZ=' /boot/config-$(uname -r)
CONFIG_HZ=250
/proc/stat
Linux 通过 /proc 虚拟文件系统,向用户空间提供了系统内部状态的信息,而 /proc/stat 提供的就是系统的 CPU 和任务统计信息
# 只保留各个 CPU 的数据
$ cat /proc/stat | grep ^cpu
cpu 280580 7407 286084 172900810 83602 0 583 0 0 0
cpu0 144745 4181 176701 86423902 52076 0 301 0 0 0
cpu1 135834 3226 109383 86476907 31525 0 282 0 0 0
同时,正因为节拍率 HZ 是内核选项,所以用户空间程序并不能直接访问。为了方便用户空间程序,内核还提供了一个用户空间节拍率 USER_HZ,它总是固定为 100,也就是 1/100 秒。这样,用户空间程序并不需要关心内核中 HZ 被设置成了多少,因为它看到的总是固定值 USER_HZ
第一列表示的是 CPU 编号,如 cpu0、cpu1 ,而第一行没有编号的 cpu ,表示的是所有 CPU 的累加。其他列则表示不同场景下 CPU 的累加节拍数,它的单位是 USER_HZ,也就是 10 ms(1/100 秒),所以这其实就是不同场景下的 CPU 时间
2、怎么查看 CPU 使用率

定义:CPU 使用率,就是除了空闲时间外的其他时间占总 CPU 时间的百分比
性能分析工具给出的都是间隔一段时间的平均 CPU 使用率,所以要注意间隔时间的设置,特别是用多个工具对比分析时,你一定要保证它们用的是相同的间隔时间
对比一下 top 和 ps 这两个工具报告的 CPU 使用率,默认的结果很可能不一样,因为 top 默认使用 3 秒时间间隔,而 ps 使用的却是进程的整个生命周期
top
显示了系统总体的 CPU 和内存使用情况,以及各个进程的资源使用情况。
# 默认每 3 秒刷新一次,top 默认显示的是所有 CPU 的平均值,这个时候你只需要按下数字 1 ,就可以切换到每个 CPU 的使用率了。
[root@myhost-001 ~]# top
top - 11:59:40 up 1:26, 2 users, load average: 0.02, 0.15, 0.20
Tasks: 100 total, 1 running, 99 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 995892 total, 274024 free, 298100 used, 423768 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 503220 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 1358 root 20 0 161880 2232 1580 R 0.3 0.2 0:00.13 top 1 root 20 0 127988 6528 4124 S 0.0 0.7 0:01.13 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd 3 root 20 0 0 0 0 S 0.0 0.0 0:00.15 ksoftirqd/0 5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H 6 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kworker/u256:0 7 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0 8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh 9 root 20 0 0 0 0 S 0.0 0.0 0:00.31 rcu_sched 10 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 lru-add-drain
.....
第三行 %Cpu 就是系统的 CPU 使用率
- user(通常缩写为 us),代表用户态 CPU 时间。注意,它不包括下面的 nice 时间,但包括了 guest 时间。
- nice(通常缩写为 ni),代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整为 1-19 之间时的 CPU 时间。这里注意,nice 可取值范围是 -20 到 19,数值越大,优先级反而越低。
- system(通常缩写为 sys),代表内核态 CPU 时间。
- idle(通常缩写为 id),代表空闲时间。注意,它不包括等待 I/O 的时间(iowait)。
- iowait(通常缩写为 wa),代表等待 I/O 的 CPU 时间。
- irq(通常缩写为 hi),代表处理硬中断的 CPU 时间。
- softirq(通常缩写为 si),代表处理软中断的 CPU 时间。
- steal(通常缩写为 st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的 CPU 时间。
- guest(通常缩写为 guest),代表通过虚拟化运行其他操作系统的时间,也就是运行虚拟机的 CPU 时间。
- guest_nice(通常缩写为 gnice),代表以低优先级运行虚拟机的时间。
top 并没有细分进程的用户态 CPU 和内核态 CPU。
# 每隔 1 秒输出一组数据,共输出 5 组
[root@myhost-001 ~]# pidstat 1 5
Linux 3.10.0-957.21.3.el7.x86_64 (myhost-001) 2020年08月20日 _x86_64_ (1 CPU)
12时04分32秒 UID PID %usr %system %guest %CPU CPU Command
12时04分33秒 UID PID %usr %system %guest %CPU CPU Command
12时04分34秒 UID PID %usr %system %guest %CPU CPU Command
12时04分35秒 0 1380 0.00 1.00 0.00 1.00 0 pidstat
12时04分35秒 UID PID %usr %system %guest %CPU CPU Command
12时04分36秒 0 1380 0.00 1.00 0.00 1.00 0 pidstat
12时04分36秒 UID PID %usr %system %guest %CPU CPU Command
12时04分37秒 0 1380 1.01 1.01 0.00 2.02 0 pidstat
平均时间: UID PID %usr %system %guest %CPU CPU Command
平均时间: 0 1380 0.20 0.60 0.00 0.80 - pidstat
- 用户态 CPU 使用率 (%usr);
- 内核态 CPU 使用率(%system);
- 运行虚拟机 CPU 使用率(%guest);
- 等待 CPU 使用率(%wait);
- 以及总的 CPU 使用率(%CPU)。
ps
则只显示了每个进程的资源使用情况
# 从所有进程中查找 PID 是 24344 的进程
$ ps aux | grep 24344
root 9628 0.0 0.0 14856 1096 pts/0 S+ 16:15 0:00 grep --color=auto 24344
3、CPU 使用率过高怎么办?
通过 top、ps、pidstat 等工具,你能够轻松找到 CPU 使用率较高(比如 100% )的进程。但是你可能又想知道,占用 CPU 的到底是代码里的哪个函数呢?
GDB
因为 GDB 调试程序的过程会中断程序运行,这在线上环境往往是不允许的。所以,GDB 只适合用在性能分析的后期,当你找到了出问题的大致函数后,线下再借助它来进一步调试函数内部的问题
ab(apache bench)
一个常用的 HTTP 服务性能测试工具
# 安装
$ yum install -y httpd-tools
# 并发 10 个请求测试 Nginx 性能,总共测试 100 个请求
$ ab -c 10 -n 1000 http://192.168.0.10:10000/
# 并发请求数改成 5,同时把请求时长设置为 10 分钟(-t 600)
$ ab -c 5 -t 600 http://192.168.0.10:10000/
perf top
它能够实时显示占用 CPU 时钟最多的函数或者指令,因此可以用来查找热点函数
$ perf top

第一行包含三个数据,分别是采样数(Samples)、事件类型(event)和事件总数量(Event count)
- 第一列 Overhead ,是该符号的性能事件在所有采样中的比例,用百分比来表示。
- 第二列 Shared ,是该函数或指令所在的动态共享对象(Dynamic Shared Object),如内核、进程名、动态链接库名、内核模块名等。
- 第三列 Object ,是动态共享对象的类型。比如 [.] 表示用户空间的可执行程序、或者动态链接库,而 [k] 则表示内核空间。
- 最后一列 Symbol 是符号名,也就是函数名。当函数名未知时,用十六进制的地址来表示
perf record
$ perf record # 按 Ctrl+C 终止采样
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.452 MB perf.data (6093 samples) ]
perf report
$ perf report # 展示类似于 perf top 的报告
我们还经常为 perf top 和 perf record 加上 -g 参数,开启调用关系的采样,方便我们根据调用链来分析性能问题
# -g 开启调用关系分析,-p 指定 php-fpm 的进程号 21515
$ perf top -g -p 21515
# 按方向键切换到 php-fpm进程,再按下回车键展开 php-fpm 的调用关系
4、小结
CPU 使用率是最直观和最常用的系统性能指标,更是我们在排查性能问题时,通常会关注的第一个指标。所以我们更要熟悉它的含义,尤其要弄清楚用户(%user)、Nice(%nice)、系统(%system) 、等待 I/O(%iowait) 、中断(%irq)以及软中断(%softirq)这几种不同 CPU 的使用率。比如说:
- 用户 CPU 和 Nice CPU 高,说明用户态进程占用了较多的 CPU,所以应该着重排查进程的性能问题。
- 系统 CPU 高,说明内核态占用了较多的 CPU,所以应该着重排查内核线程或者系统调用的性能问题。
- I/O 等待 CPU 高,说明等待 I/O 的时间比较长,所以应该着重排查系统存储是不是出现了 I/O 问题。
- 软中断和硬中断高,说明软中断或硬中断的处理程序占用了较多的 CPU,所以应该着重排查内核中的中断服务程序。
碰到 CPU 使用率升高的问题,你可以借助 top、pidstat 等工具,确认引发 CPU 性能问题的来源;再使用 perf 等工具,排查出引起性能问题的具体函数。
四、系统的CPU使用率很高,但为啥却找不到高CPU的应用?
1、命令
pstree
可以用树状形式显示所有进程之间的关系
$ pstree | grep stress
|-docker-containe-+-php-fpm-+-php-fpm---sh---stress
| |-3*[php-fpm---sh---stress---stress]
execsnoop
一个专为短时进程设计的工具。它通过 ftrace 实时监控进程的 exec() 行为,并输出短时进程的基本信息,包括进程 PID、父进程 PID、命令行参数以及执行的结果
# 安装 execsnoop
https://www.codeleading.com/article/56251061422/
$ git clone https://github.com/brendangregg/perf-tools.git
# 使用
$ ./execsnoop
$ ./iolatency -Q
$ ./tpoint -s block:block_rq_insert 'rwbs ~ "*R*"'
$ ./funccount -i 1 'bio_*'
2、小结
碰到常规问题无法解释的 CPU 使用率情况时,首先要想到有可能是短时应用导致的问题,比如有可能是下面这两种情况。
- 第一,应用里直接调用了其他二进制程序,这些程序通常运行时间比较短,通过 top 等工具也不容易发现。
- 第二,应用本身在不停地崩溃重启,而启动过程的资源初始化,很可能会占用相当多的 CPU。
对于这类进程,我们可以用 pstree 或者 execsnoop 找到它们的父进程,再从父进程所在的应用入手,排查问题的根源
五、系统中出现大量不可中断进程和僵尸进程怎么办?
1、进程状态
- R 是 Running 或 Runnable 的缩写,表示进程在 CPU 的就绪队列中,正在运行或者正在等待运行。
- D 是 Disk Sleep 的缩写,也就是不可中断状态睡眠(Uninterruptible Sleep),一般表示进程正在跟硬件交互,并且交互过程不允许被其他进程或中断打断。
- Z 是 Zombie 的缩写,如果你玩过“植物大战僵尸”这款游戏,应该知道它的意思。它表示僵尸进程,也就是进程实际上已经结束了,但是父进程还没有回收它的资源(比如进程的描述符、PID 等)。
- S 是 Interruptible Sleep 的缩写,也就是可中断状态睡眠,表示进程因为等待某个事件而被系统挂起。当进程等待的事件发生时,它会被唤醒并进入 R 状态。
- I 是 Idle 的缩写,也就是空闲状态,用在不可中断睡眠的内核线程上。前面说了,硬件交互导致的不可中断进程用 D 表示,但对某些内核线程来说,它们有可能实际上并没有任何负载,用 Idle 正是为了区分这种情况。要注意,D 状态的进程会导致平均负载升高, I 状态的进程却不会。
- T 或者 t,也就是 Stopped 或 Traced 的缩写,表示进程处于暂停或者跟踪状态。
- X,也就是 Dead 的缩写,表示进程已经消亡,所以你不会在 top 或者 ps 命令中看到它。
2、iowait 分析
dstat
可以同时查看 CPU 和 I/O 这两种资源的使用情况,便于对比分析
# 间隔 1 秒输出 10 组数据
$ dstat 1 10
You did not select any stats, using -cdngy by default.
--total-cpu-usage-- -dsk/total- -net/total- ---paging-- ---system--
usr sys idl wai stl| read writ| recv send| in out | int csw
0 0 96 4 0|1219k 408k| 0 0 | 0 0 | 42 885
0 0 2 98 0| 34M 0 | 198B 790B| 0 0 | 42 138
0 0 0 100 0| 34M 0 | 66B 342B| 0 0 | 42 135
0 0 84 16 0|5633k 0 | 66B 342B| 0 0 | 52 177
0 3 39 58 0| 22M 0 | 66B 342B| 0 0 | 43 144
0 0 0 100 0| 34M 0 | 200B 450B| 0 0 | 46 147
0 0 2 98 0| 34M 0 | 66B 342B| 0 0 | 45 134
0 0 0 100 0| 34M 0 | 66B 342B| 0 0 | 39 131
0 0 83 17 0|5633k 0 | 66B 342B| 0 0 | 46 168
0 3 39 59 0| 22M 0 | 66B 342B| 0 0 | 37 134
从 dstat 的输出,我们可以看到,每当 iowait 升高(wai)时,磁盘的读请求(read)都会很大。这说明 iowait 的升高跟磁盘的读请求有关,很可能就是磁盘读导致的。
# -d 展示 I/O 统计数据,-p 指定进程号,间隔 1 秒输出 3 组数据
$ pidstat -d -p 4344 1 3
06:38:50 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
06:38:51 0 4344 0.00 0.00 0.00 0 app
06:38:52 0 4344 0.00 0.00 0.00 0 app
06:38:53 0 4344 0.00 0.00 0.00 0 app
# 不指定进程号,观察所有进程的 I/O 使用情况。间隔 1 秒输出多组数据 (这里是 20 组)
$ pidstat -d 1 20
...
06:48:46 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
06:48:47 0 4615 0.00 0.00 0.00 1 kworker/u4:1
06:48:47 0 6080 32768.00 0.00 0.00 170 app
06:48:47 0 6081 32768.00 0.00 0.00 184 app
....
strace
是最常用的跟踪进程系统调用的工具
$ strace -p 6082
strace: attach: ptrace(PTRACE_SEIZE, 6082): Operation not permitted
一般遇到这种问题时,我会先检查一下进程的状态是否正常。比如,继续在终端中运行 ps 命令,并使用 grep 找出刚才的 6082 号进程
$ ps aux | grep 6082
root 6082 0.0 0.0 0 0 pts/0 Z+ 13:43 0:00 [app] <defunct>
进程 6082 已经变成了 Z 状态,也就是僵尸进程。僵尸进程都是已经退出的进程,所以就没法儿继续分析它的系统调用。
# 我们用了 perf 工具,来分析系统的 CPU 时钟事件
$ perf record -g
$ perf report
3、僵尸进程
僵尸进程是因为父进程没有回收子进程的资源而出现的,那么,要解决掉它们,就要找到它们的根儿,也就是找出父进程,然后在父进程里解决。
pstree
父进程的找法
# -a 表示输出命令行选项
# p 表 PID
# s 表示指定进程的父进程
$ pstree -aps 3084
systemd,1
└─dockerd,15006 -H fd://
└─docker-containe,15024 --config /var/run/docker/containerd/containerd.toml
└─docker-containe,3991 -namespace moby -workdir...
└─app,4009
└─(app,3084)
会发现 3084 号进程的父进程是 4009
火焰图
https://blog.csdn.net/pwl999/article/details/106786495/
https://blog.csdn.net/gatieme/article/details/78885908
systemtab
https://blog.csdn.net/wangzuxi/article/details/44901285
perf-tools
https://zhoubofsy.github.io/2018/12/14/linux/perf-tools/
https://www.cnblogs.com/GODYCA/archive/2013/05/28/3104281.html
六、怎么理解Linux软中断?
1、软中断
Linux 将中断处理过程分成了两个阶段,也就是上半部和下半部:
- 上半部用来快速处理中断,它在中断禁止模式下运行,主要处理跟硬件紧密相关的或时间敏感的工作。
- 下半部用来延迟处理上半部未完成的工作,通常以内核线程的方式运行
实际上,上半部会打断 CPU 正在执行的任务,然后立即执行中断处理程序。而下半部以内核线程的方式执行,并且每个 CPU 都对应一个软中断内核线程,名字为 “ksoftirqd/CPU 编号”,比如说, 0 号 CPU 对应的软中断内核线程的名字就是 ksoftirqd/0。
2、查看软中断和内核线程
proc 文件系统。它是一种内核空间和用户空间进行通信的机制,可以用来查看内核的数据结构,或者用来动态修改内核的配置。其中:
- /proc/softirqs 提供了软中断的运行情况;
- /proc/interrupts 提供了硬中断的运行情况。
# 查看 /proc/softirqs 文件的内容,你就可以看到各种类型软中断在不同 CPU 上的累积运行次数
$ cat /proc/softirqs
CPU0 CPU1
HI: 0 0
TIMER: 811613 1972736
NET_TX: 49 7
NET_RX: 1136736 1506885
BLOCK: 0 0
IRQ_POLL: 0 0
TASKLET: 304787 3691
SCHED: 689718 1897539
HRTIMER: 0 0
RCU: 1330771 1354737
第一,要注意软中断的类型,也就是这个界面中第一列的内容。从第一列你可以看到,软中断包括了 10 个类别,分别对应不同的工作类型。比如 NET_RX 表示网络接收中断,而 NET_TX 表示网络发送中断。
第二,要注意同一种软中断在不同 CPU 上的分布情况,也就是同一行的内容。正常情况下,同一种中断在不同 CPU 上的累积次数应该差不多。比如这个界面中,NET_RX 在 CPU0 和 CPU1 上的中断次数基本是同一个数量级,相差不大。
软中断实际上是以内核线程的方式运行的,每个 CPU 都对应一个软中断内核线程,这个软中断内核线程就叫做 ksoftirqd/CPU 编号。那要怎么查看这些线程的运行状况呢?
$ ps aux | grep softirq
root 7 0.0 0.0 0 0 ? S Oct10 0:01 [ksoftirqd/0]
root 16 0.0 0.0 0 0 ? S Oct10 0:01 [ksoftirqd/1]
七、系统的软中断CPU使用率升高,我该怎么办?
hping3
是一个可以构造 TCP/IP 协议数据包的工具,可以对系统进行安全审计、防火墙测试等
运行 hping3 命令,来模拟 Nginx 的客户端请求
# -S 参数表示设置 TCP 协议的 SYN(同步序列号),-p 表示目的端口为 80
# -i u100 表示每隔 100 微秒发送一个网络帧
# 注:如果你在实践过程中现象不明显,可以尝试把 100 调小,比如调成 10 甚至 1
$ hping3 -S -p 80 -i u100 192.168.0.30
watch
可以定期运行一个命令来查看输出;如果再加上 -d 参数,还可以高亮出变化的部分,从高亮部分我们就可以直观看出,哪些内容变化得更快
$ watch -d cat /proc/softirqs
CPU0 CPU1
HI: 0 0
TIMER: 1083906 2368646
NET_TX: 53 9
NET_RX: 1550643 1916776
BLOCK: 0 0
IRQ_POLL: 0 0
TASKLET: 333637 3930
SCHED: 963675 2293171
HRTIMER: 0 0
RCU: 1542111 1590625
sar
sar 可以用来查看系统的网络收发情况,还有一个好处是,不仅可以观察网络收发的吞吐量(BPS,每秒收发的字节数),还可以观察网络收发的 PPS,即每秒收发的网络帧数
# -n DEV 表示显示网络收发的报告,间隔 1 秒输出一组数据
$ sar -n DEV 1
15:03:46 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
15:03:47 eth0 12607.00 6304.00 664.86 358.11 0.00 0.00 0.00 0.01
15:03:47 docker0 6302.00 12604.00 270.79 664.66 0.00 0.00 0.00 0.00
15:03:47 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
15:03:47 veth9f6bbcd 6302.00 12604.00 356.95 664.66 0.00 0.00 0.00 0.05
对于 sar 的输出界面,我先来简单介绍一下,从左往右依次是:
- 第一列:表示报告的时间。
- 第二列:IFACE 表示网卡。
- 第三、四列:rxpck/s 和 txpck/s 分别表示每秒接收、发送的网络帧数,也就是 PPS。
- 第五、六列:rxkB/s 和 txkB/s 分别表示每秒接收、发送的千字节数,也就是 BPS。
- 后面的其他参数基本接近 0,显然跟今天的问题没有直接关系,你可以先忽略掉。
tcpdump
是一个常用的网络抓包工具,常用来分析各种网络问题
# -i eth0 只抓取 eth0 网卡,-n 不解析协议名和主机名
# tcp port 80 表示只抓取 tcp 协议并且端口号为 80 的网络帧
$ tcpdump -i eth0 -n tcp port 80
15:11:32.678966 IP 192.168.0.2.18238 > 192.168.0.30.80: Flags [S], seq 458303614, win 512, length 0
...
八、总结:如何迅速分析出系统CPU的瓶颈在哪里?
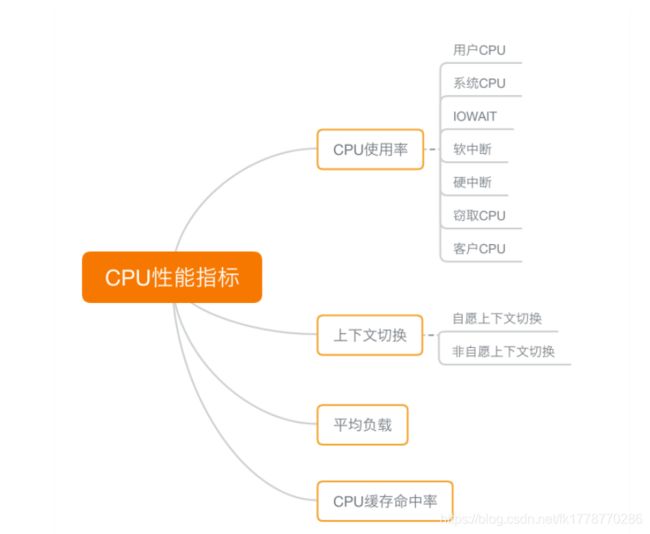
1、CPU 性能指标
CPU 使用率
CPU 使用率描述了非空闲时间占总 CPU 时间的百分比,根据 CPU 上运行任务的不同,又被分为用户 CPU、系统 CPU、等待 I/O CPU、软中断和硬中断等。
- 用户 CPU 使用率,包括用户态 CPU 使用率(user)和低优先级用户态 CPU 使用率(nice),表示 CPU 在用户态运行的时间百分比。用户 CPU 使用率高,通常说明有应用程序比较繁忙。
- 系统 CPU 使用率,表示 CPU 在内核态运行的时间百分比(不包括中断)。系统 CPU 使用率高,说明内核比较繁忙。
- 等待 I/O 的 CPU 使用率,通常也称为 iowait,表示等待 I/O 的时间百分比。iowait 高,通常说明系统与硬件设备的 I/O 交互时间比较长。
- 软中断和硬中断的 CPU 使用率,分别表示内核调用软中断处理程序、硬中断处理程序的时间百分比。它们的使用率高,通常说明系统发生了大量的中断。
- 除了上面这些,还有在虚拟化环境中会用到的窃取 CPU 使用率(steal)和客户 CPU 使用率(guest),分别表示被其他虚拟机占用的 CPU 时间百分比,和运行客户虚拟机的 CPU 时间百分比。
平均负载(Load Average)
也就是系统的平均活跃进程数。它反应了系统的整体负载情况,主要包括三个数值,分别指过去 1 分钟、过去 5 分钟和过去 15 分钟的平均负载。
理想情况下,平均负载等于逻辑 CPU 个数,这表示每个 CPU 都恰好被充分利用。如果平均负载大于逻辑 CPU 个数,就表示负载比较重了
进程上下文切换
- 无法获取资源而导致的自愿上下文切换;
- 被系统强制调度导致的非自愿上下文切换。
上下文切换,本身是保证 Linux 正常运行的一项核心功能。但过多的上下文切换,会将原本运行进程的 CPU 时间,消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,缩短进程真正运行的时间,成为性能瓶颈
CPU 缓存的命中率

CPU 缓存的速度介于 CPU 和内存之间,缓存的是热点的内存数据。根据不断增长的热点数据,这些缓存按照大小不同分为 L1、L2、L3 等三级缓存,其中 L1 和 L2 常用在单核中, L3 则用在多核中。
从 L1 到 L3,三级缓存的大小依次增大,相应的,性能依次降低(当然比内存还是好得多)。而它们的命中率,衡量的是 CPU 缓存的复用情况,命中率越高,则表示性能越好。
2、性能工具
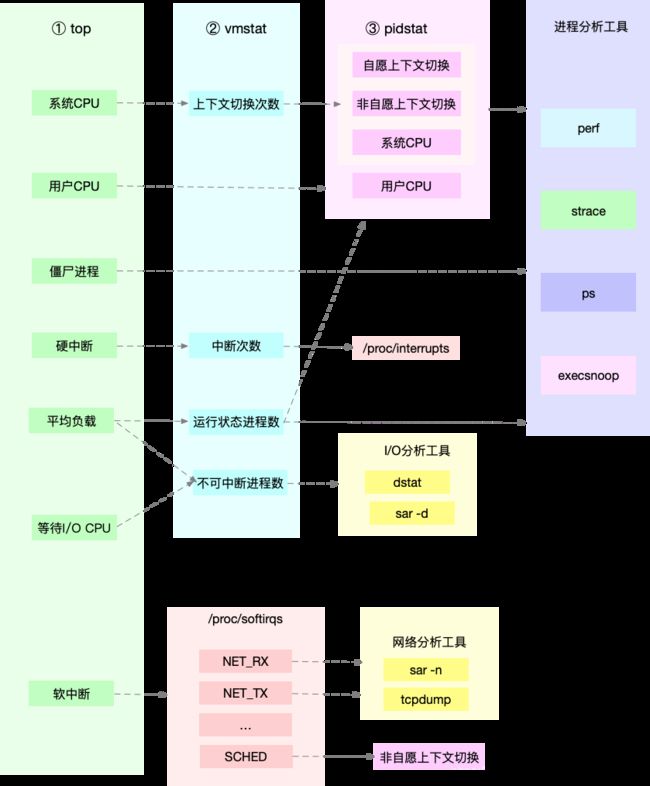
第一个,平均负载的案例。我们先用 uptime, 查看了系统的平均负载;而在平均负载升高后,又用 mpstat 和 pidstat ,分别观察了每个 CPU 和每个进程 CPU 的使用情况,进而找出了导致平均负载升高的进程,也就是我们的压测工具 stress。
第二个,上下文切换的案例。我们先用 vmstat ,查看了系统的上下文切换次数和中断次数;然后通过 pidstat ,观察了进程的自愿上下文切换和非自愿上下文切换情况;最后通过 pidstat ,观察了线程的上下文切换情况,找出了上下文切换次数增多的根源,也就是我们的基准测试工具 sysbench。
第三个,进程 CPU 使用率升高的案例。我们先用 top ,查看了系统和进程的 CPU 使用情况,发现 CPU 使用率升高的进程是 php-fpm;再用 perf top ,观察 php-fpm 的调用链,最终找出 CPU 升高的根源,也就是库函数 sqrt() 。
第四个,系统的 CPU 使用率升高的案例。我们先用 top 观察到了系统 CPU 升高,但通过 top 和 pidstat ,却找不出高 CPU 使用率的进程。于是,我们重新审视 top 的输出,又从 CPU 使用率不高但处于 Running 状态的进程入手,找出了可疑之处,最终通过 perf record 和 perf report ,发现原来是短时进程在捣鬼。
另外,对于短时进程,我还介绍了一个专门的工具 execsnoop,它可以实时监控进程调用的外部命令。
第五个,不可中断进程和僵尸进程的案例。我们先用 top 观察到了 iowait 升高的问题,并发现了大量的不可中断进程和僵尸进程;接着我们用 dstat 发现是这是由磁盘读导致的,于是又通过 pidstat 找出了相关的进程。但我们用 strace 查看进程系统调用却失败了,最终还是用 perf 分析进程调用链,才发现根源在于磁盘直接 I/O 。
最后一个,软中断的案例。我们通过 top 观察到,系统的软中断 CPU 使用率升高;接着查看 /proc/softirqs, 找到了几种变化速率较快的软中断;然后通过 sar 命令,发现是网络小包的问题,最后再用 tcpdump ,找出网络帧的类型和来源,确定是一个 SYN FLOOD 攻击导致的。
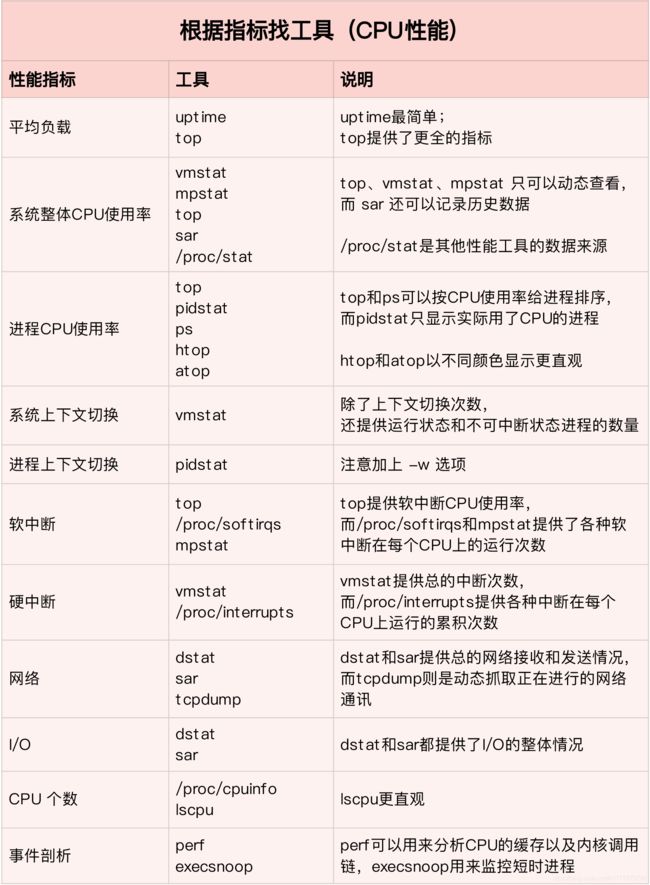

为了缩小排查范围,我通常会先运行几个支持指标较多的工具,如 top、vmstat 和 pidstat 。为什么是这三个工具呢?