写在前面
排序是算法的必修课
也是基础的第一课
其实就排序本身而言没有什么值得学习的
很多编程语言自带排序函数,例如Java语言的Arrays.sort()函数,基本上可以直接用
所以我们在刷算法题的时候很少自己写排序代码
但是排序仍然值得大家去学习
因为排序并没有大家想的这么简单,只是将乱序变为有序,其实不同的排序算法里包含着不同的思想
例如冒泡排序就是暴力算法的思想,归并排序就是分治算法的思想
在本页博客里大家更多的是体会排序算法所包含的各种思想,在后续的学习中还会继续深入地和大家讨论
冒泡排序
冒泡排序(Bubble Sort)是基于交换的排序,每次遍历需要排序的元素,依次比较相邻的两个元素的大小,如果前一个元素大于后一个元素则两者交换,保证最后一个数字一定是最大的(假设按照从小到大排序),即最后一个元素已经排好序,下一轮只需要保证前面 n-1 个元素的顺序即可。
之所以称为冒泡,是因为最大/最小的数,每一次都往后面冒,就像是水里面的气泡一样。
排序(假设从小到大)的步骤如下:
- 从头开始,比较相邻的两个数,如果第一个数比第二个数大,那么就交换它们位置。
- 从开始到最后一对比较完成,一轮结束后,最后一个元素的位置已经确定。
- 除了最后一个元素以外,前面的所有未排好序的元素重复前面两个步骤。
- 重复前面 1 ~ 3 步骤,直到所有元素都已经排好序。
例如,我们需要对数组 [98,90,34,56,21] 进行从小到大排序,每一次都需要将数组最大的移动到数组尾部。那么排序的过程如下动图所示:
交换具体逻辑如下图所示:
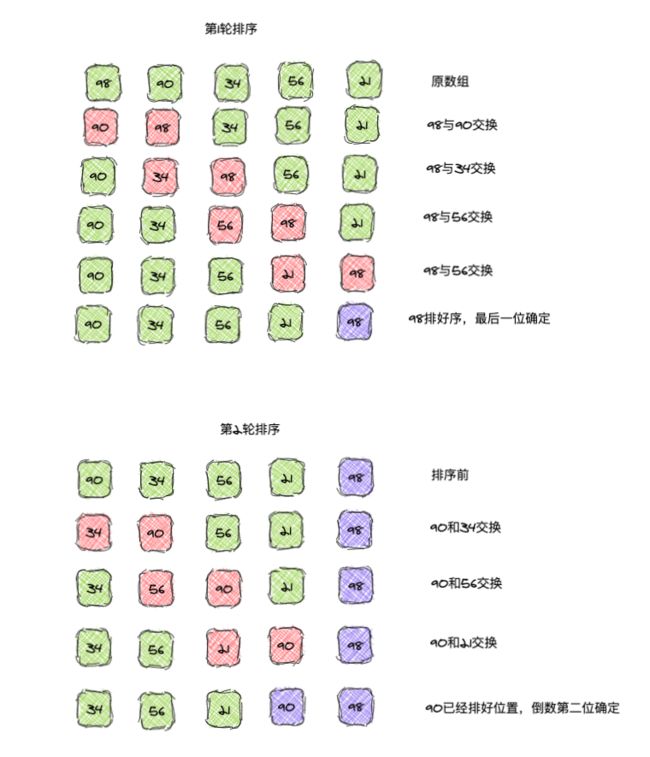
接下来两轮排序确定好了第二个和第三个的位置,其实这个数组已经完成排序了,一共 5 个数,冒泡 4 次即可。

紫色表示已经排好的元素,橙红色表示正在比较/交换的元素,可以看出前面两次排序之后,已经确定好了最大两个数的位置。
冒泡排序Java代码
public class BubbleSort {
public static void bubbleSort(int[] nums) {
int size=nums.length;
for(int i=0;inums[j+1]) {
int temp=nums[j+1];
nums[j+1]=nums[j];
nums[j]=temp;
}
printf(nums);
}
}
}
public static void printf(int[] nums) {
for (int num : nums) {
System.out.print(num + " ");
}
System.out.println("");
}
public static void main(String[] args) {
// TODO Auto-generated method stub
int[]nums = new int[]{98,90,34,56,21};
printf(nums);
bubbleSort(nums);
}
} 冒泡排序Java代码运行结果

选择排序
前面说的冒泡排序是每一轮比较确定最后一个元素,中间过程不断地交换。而选择排序就是每次选择剩下的元素中最小的那个元素,与当前索引位置的元素交换,直到所有的索引位置都选择完成。
排序的步骤如下:
- 从第一个元素开始,遍历其后面的元素,找出其后面比它更小的且最小的元素,若有,则两者交换,保证第一个元素最小。
- 对第二个元素一样,遍历其后面的元素,找出其后面比它更小的且最小的元素,若存在,则两者交换,保证第二个元素在未排序的数中(除了第一个元素)最小。
- 依次类推,直到最后一个元素,那么数组就已经排好序了。
比如,现在我们需要对 [98,90,34,56,21] 进行排序,动态排序过程如下:
静态排序过程如下:
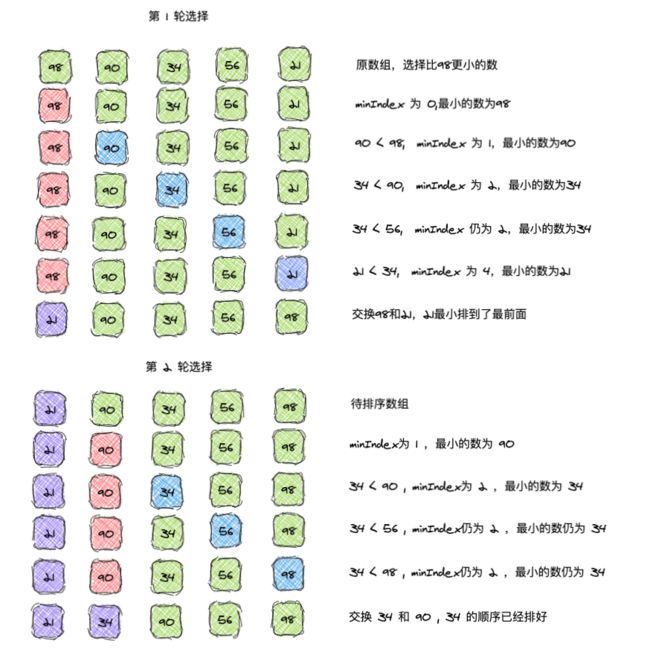
前面两轮选择排序已经分别将 21 和 34 选择出来,放到最前面的位置。
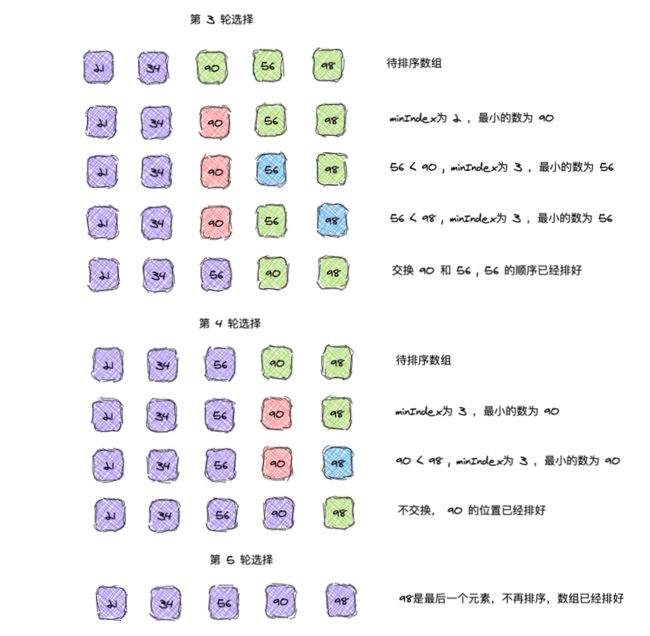
剩下的排序是确定 56 和 90 的位置,最后一个 98 自然就是最大的数,不需要再排序。
选择排序Java代码
public class SelectionSort {
public static void printf(int[] nums) {
for (int num : nums) {
System.out.print(num + " ");
}
System.out.println("");
}
public static void selectionSort(int []nums) {
int times=0;
int size=nums.length;
int minIndex,temp;
for(int i=0;i选择排序Java代码运行结果

插入排序
选择排序是每次选择出最小的放到已经排好的数组后面,而插入排序是依次选择一个元素,插入到前面已经排好序的数组中间,确保它处于正确的位置,当然,这是需要已经排好的顺序数组不断移动。步骤描述如下:
- 从第一个元素开始,可以认为第一个元素已经排好顺序。
- 取出后面一个元素
n,在前面已经排好顺序的数组里从尾部往头部遍历,假设正在遍历的元素为nums[i],如果num[i]>n,那么将nums[i]移动到后面一个位置,直到找到已经排序的元素小于或者等于新元素的位置,将n放到新腾空出来的位置上。如果没有找到,那么nums[i]就是最小的元素,放在第一个位置。 - 重复上面的步骤 2,直到所有元素都插入到正确的位置。
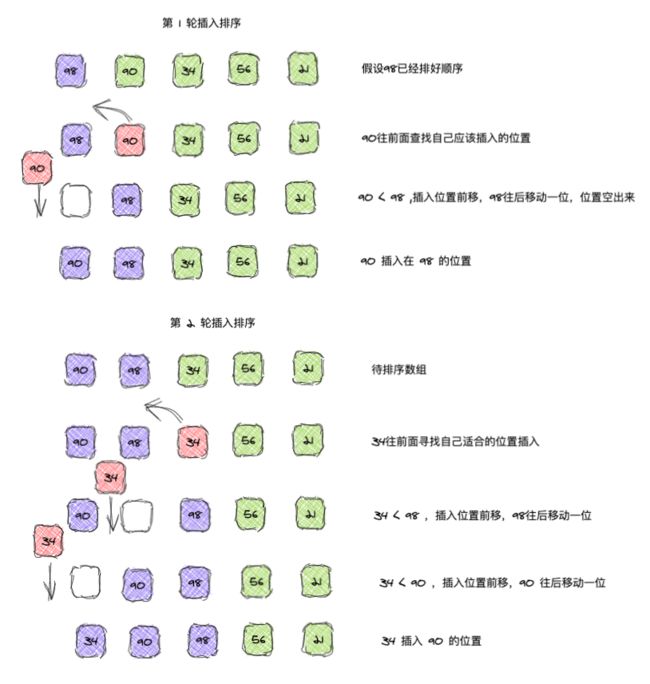
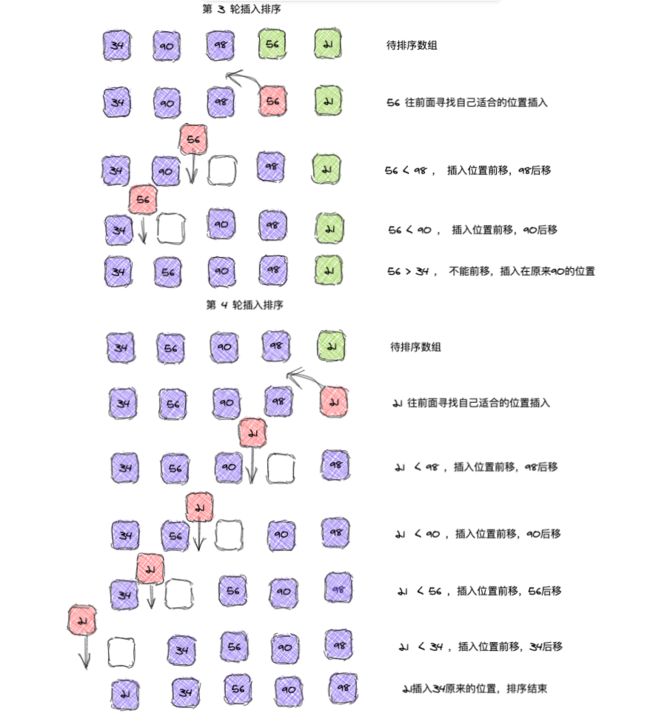
以数组 [98,90,34,56,21] 为例,动态排序过程如下:
具体的排序过程如下:
第一次假设第一个元素已经排好,第二个元素 90 往前面查找插入位置,正好查找到 98 的位置插入,第二轮是 34 选择插入位置,选择了第一个元素 90 的位置插入,其后面的元素后移。
第三轮排序则是 56 选择适合自己的位置插入,第四轮是最后一个元素 21 往前查找适合的位置插入:
插入排序Java代码
public class InsertionSort {
public static void printf(int[] nums) {
for (int num : nums) {
System.out.print(num + " ");
}
System.out.println("");
}
public static void insertionSort(int[] nums) {
if(nums==null) {
return;
}
int size=nums.length;
int index,temp;
for(int i=1;i=0&&nums[index]>temp) {
nums[index+1]=nums[index];
index--;
}
// 插入空出来的位置
nums[index+1]=temp;
System.out.print("第" + (i) + "轮插入结果:");
printf(nums);
}
}
public static void main(String[] args) {
// TODO Auto-generated method stub
int[]nums = new int[]{98,90,34,56,21};
printf(nums);
insertionSort(nums);
}
} 插入排序Java代码运行结果

希尔排序
希尔排序(Shell's Sort)又称“缩小增量排序”(Diminishing Increment Sort),是插入排序的一种更高效的改进版本,同时该算法是首次冲破 O(n^2n2) 的算法之一。
插入排序的痛点在于不管是否是大部分有序,都会对元素进行比较,如果最小数在数组末尾,想要把它移动到数组的头部是比较费劲的。希尔排序是在数组中采用跳跃式分组,按照某个增量 gap 进行分组,分为若干组,每一组分别进行插入排序。再逐步将增量 gap 缩小,再每一组进行插入排序,循环这个过程,直到增量为 1。
希尔排序基本步骤如下:
- 选择一个增量
gap,一般开始是数组的一半,将数组元素按照间隔为gap分为若干个小组。 - 对每一个小组进行插入排序。
- 将
gap缩小为一半,重新分组,重复步骤 2(直到gap为 1 的时候基本有序,稍微调整一下即可)。
以数组 [98,90,34,56,21,11,43,61] 为例子,排序的动图如下:
同样以数组 [98,90,34,56,21,11,43,61] 为例子,元素个数为 8,首次 gap 为 4,元素分为 4 组,同颜色视为一组,对相同颜色进行插入排序,这样保证了大致位置上大的元素在后面,小的元素在前面。

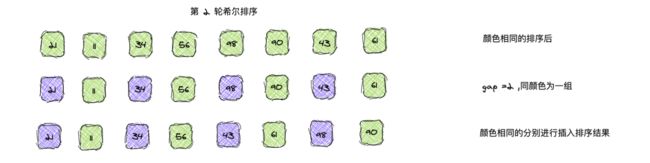
第二轮希尔排序,gap = 4/2 = 2,则元素可以分为两组,同颜色视为一组,仍是对同组的进行插入排序:
最后一轮,gap= 2/2 =1,则所有元素视为一组,相当于对所有元素进行插入排序,这时候元素已经基本有序,只需要做小范围的调整即可。
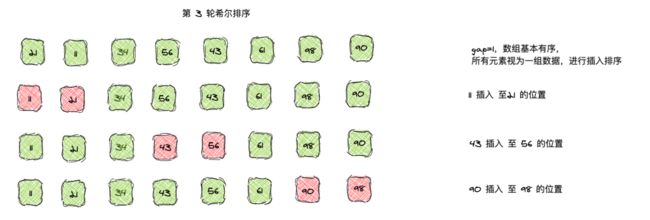
希尔排序是非稳定排序算法,每一组的排序,都确保了这一组的数据基本有序,整体上也是基本有序。
希尔排序Java代码
public class ShellSort {
public static void printf(int[] nums) {
for (int num : nums) {
System.out.print(num + " ");
}
System.out.println("");
}
public static void shellSort(int[] nums) {
int times=1;
for(int gap=nums.length/2;gap>0;gap/=2) {
System.out.print("第" + (times++) + "轮希尔排序, gap= " + gap + " ,结果:");
for(int i = gap;i=0&&temp 希尔排序Java代码运行结果

快速排序
快速排序比较有趣,选择数组的一个数作为基准数,一趟排序,将数组分割成为两部分,一部分均小于/等于基准数,另外一部分大于/等于基准数。然后分别对基准数的左右两部分继续排序,直到数组有序。这体现了分而治之的思想,其中还应用到挖坑填数的策略。
算法的步骤如下:
- 从数组中挑一个元素作为基准数,一般情况下我们选择第一个
nums[i],保存为standardNum,可以理解为nums[i]坑位的数被拎出来了,留下空的坑位。 - 取数组的左边界索引指针
i,右边界索引指针j,j从右边往左边,寻找到比standardNum小的数,停下来,写到nums[i]的坑位,nums[j]的坑位空出来。 索引指针i从左边往右边找,寻找比standardNum大的数,停下来,写到nums[j]的坑位,这个时候,num[i]的坑位空出来(前提是i和j不相撞)。 - 上面的
i和j循环步骤 2,直到两个索引指针i和j相撞,将基准值standardNum写到坑位nums[i]中,这时候,standardNum左边的数都小于等于它本身,右边的数都大于等于它本身。 - 分别对
standardNum左边的子数组和右边的子数组,循环执行前面的 1,2,3,直到不可再分,并且有序。
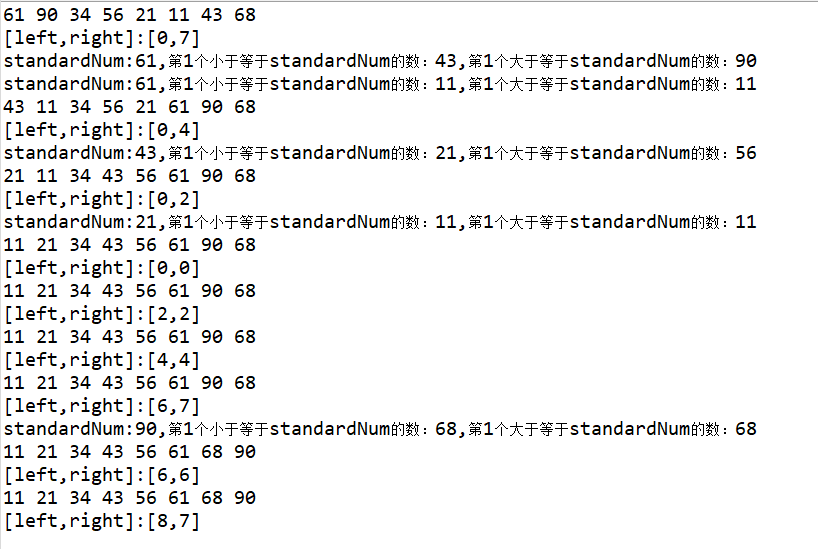
以数组 [61,90,34,56,21,11,43,68] 为例,动态排序过程如下:
具体的排序过程如下:
第一轮排序是所有元素,以第一个数 61 为基准值,排序完成则左边的数都小于等于 61,右边的数都大于等于 61。

分别对 61 左边的数 [ 43,11,34,56,21 ] 和右边的数 [ 90,68 ] 分别进行快速排序,这里体现了分治的思想。首先我们来看左边 [ 43,11,34,56,21 ] 的排序。

左边又确定了以 43 为分割的数组 [ 21,11,34 ] 以及 [ 64 ],由于递归的原因,再次先对左边 [ 21,11,34 ] 进行排序:

左边 [ 21,11,34 ] 排序后,以 21 为分割线,左右各自只有一个数,自然已经停止,上面 43 的右边也只有一个元素,所以也已经是有序的。

至此,61 以及左边都是有序的,再对 61 右边的 [ 90,68 ] 进行快速排序:

快速排序Java代码
public class QuickSort {
public static void printf(int[] nums) {
for (int num : nums) {
System.out.print(num + " ");
}
System.out.println("");
}
public static void quickSort(int[] nums) {
quickSort(nums,0,nums.length-1);
}
public static void quickSort(int nums[],int left,int right) {
System.out.println("[left,right]:["+left+","+right+"]");
if(left=standardNum) {
j--;
}
System.out.print("standardNum:"+standardNum+",第1个小于等于standardNum的数:"+nums[j]);
if(i 快速排序Java代码运行结果
计数排序
计数排序,不是基于比较,而是基于计数,比较适合元素数值相近且为整数的情况。
计数排序步骤如下:
- 遍历数组,找出最大值和最小值。
- 根据最大值和最小值,初始化对应的统计元素数量的数组。
- 遍历元素,统计元素个数到新的数组。
- 遍历统计的数组,按照顺序输出排序的数组元素。
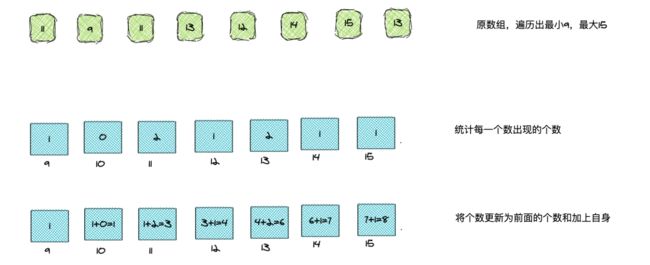
假设有几个青少年,他们年龄很靠近,分别是 11、9、11、 13、12、14、15、13,现在需要给他们按照年龄排序。首先先遍历一遍,找出最小的 min 和最大的元素 max,创建一个大小为 max - min + 1 的数组,再遍历一次,统计数字个数,写到数组中。
然后再遍历一次统计数组,将每个元素置为前面一个元素加上自身,为什么这样做呢?
这是为了让统计数组存储的元素值等于相应整数的最终排序位置,这样我们就可以做到稳定排序,比如下面的 15 对应的是 8,也就是 15 在数组中出现是第 8 个元素,从后面开始遍历,我们就可以保持稳定性。
比如原数组从后往前遍历到 13 的时候, 13 对应的位置是 6,那么此时从后往前遍历到的第一个 13 就是在第 6 个元素位置。后面再遇到 13,就放到第 5 个元素位置,不会打乱它们的相对位置。
具体过程如下:
计数排序Java代码
public class CountSort {
public static void countSort(int[] nums) {
int max = nums[0];
int min = nums[0];
for (int i = 1; i < nums.length; i++) {
if (nums[i] > max) {
max = nums[i];
}
if (nums[i] < min) {
min = nums[i];
}
}
System.out.println("min:" + min + ",max:" + max);
int count = max - min;
int[] countNums = new int[count + 1];
for (int i = 0; i < nums.length; i++) {
countNums[nums[i] - min]++;
}
System.out.print("countNums: ");
printf(countNums);
int sum = 0;
// 后面的元素等于前面元素加上自身
for (int i = 0; i < count + 1; i++) {
sum += countNums[i];
countNums[i] = sum;
}
System.out.print("countNums: ");
printf(countNums);
int[] newNums = new int[nums.length];
for (int i = nums.length - 1; i >= 0; i--) {
/**
* nums[i] - min 表示原数组 nums 里面第i位置对应的数在统计数组里面的位置索引
*/
newNums[countNums[nums[i] - min] - 1] = nums[i];
countNums[nums[i] - min]--;
}
printf(newNums);
}
public static void printf(int[] nums) {
for (int num : nums) {
System.out.print(num + " ");
}
System.out.println("");
}
public static void main(String[] args) {
int[] nums = new int[]{11, 9, 11, 13, 19, 14, 16, 14, 8, 17};
printf(nums);
countSort(nums);
}
}计数排序Java代码运行结果

桶排序
桶排序,是指用多个桶存储元素,每个桶有一个存储范围,先将元素按照范围放到各个桶中,每个桶中是一个子数组,然后再对每个子数组进行排序,最后合并子数组,成为最终有序的数组。这其实和计数排序很相似,只不过计数排序每个桶只有一个元素,而且桶存储的值为该元素出现的次数。
桶排序的具体步骤:
- 遍历数组,查找数组的最大最小值,设置桶的区间(非必需),初始化一定数量的桶,每个桶对应一定的数值区间。
- 遍历数组,将每一个数,放到对应的桶中。
- 对每一个非空的桶进行分别排序(桶内部的排序可以选择 JDK 自带排序)。
- 将桶中的子数组拼接成为最终的排序数组。
以数组 [98,90,34,56,21,11,43,61] 为例,桶排序的动态过程:
先遍历查找出 max 为 98, min 为 11,数组大小为 8,( 98 - 11 )/8 + 1 = 11,桶的个数为 11。先把元素按照区间放进去,对每一个桶分别排序,然后再把桶的元素连起来放在数组中,排序就完成了。
桶排序Java代码
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class BucketSort {
public static void bucketSort(int[] nums) {
// 遍历数组获取最大最小值
int max = Integer.MIN_VALUE;
int min = Integer.MAX_VALUE;
for (int i = 0; i < nums.length; i++) {
max = Math.max(max, nums[i]);
min = Math.min(min, nums[i]);
}
// 计算桶的数量
int bucketNum = (max - min) / nums.length + 1;
System.out.println(
"最小:" + min + ",最大:" + max + ",桶的数量:" + bucketNum
);
List> buckets = new ArrayList>(bucketNum);
for (int i = 0; i < bucketNum; i++) {
buckets.add(new ArrayList());
}
// 将每个元素放入桶
for (int i = 0; i < nums.length; i++) {
int num = (nums[i] - min) / (nums.length);
buckets.get(num).add(nums[i]);
}
// 对每个桶内部进行排序
for (int i = 0; i < buckets.size(); i++) {
Collections.sort(buckets.get(i));
}
// 将桶的元素复制到数组中
int index = 0;
for (int i = 0; i < buckets.size(); i++) {
for (int j = 0; j < buckets.get(i).size(); j++) {
nums[index++] = buckets.get(i).get(j);
}
}
}
public static void main(String[] args) {
int[] nums = new int[]{98, 90, 34, 56, 21, 11, 43, 61};
printf(nums);
bucketSort(nums);
printf(nums);
}
public static void printf(int[] nums) {
for (int num : nums) {
System.out.print(num + " ");
}
System.out.println("");
}
} 桶排序Java代码运行结果

堆排序
堆排序,就是利用大顶堆或者小顶堆来设计的排序算法,是一种选择排序。堆是一种完全二叉树:
- 大顶堆:每个节点的数值都大于或者等于其左右孩子节点的数值。
- 小顶堆:每个节点的数值都小于或者等于其左右孩子节点的数值。
我们一般使用数组来对堆结构进行存储,下面我们只说大顶堆(元素按照从小到大排序),假设数组为 nums[],则第 i 个数满足:num[i] >= nums[2i+1] 且 num[i] >= nums[2i+2],第 i 个数在堆上的左节点就是数组中下标索引 2i+1 的元素,其右节点就是数组中下标索引 2i+2 的元素。
排序的思路为:
- 将无序的数组构建出一个大顶堆,也就是上面的元素比下面的元素大。
- 将堆顶的元素和堆的最末尾的元素交换,将最大元素下沉到数组的最后面(末端)。
- 重新调整前面的顺序,继续交换堆顶的元素和当前末尾的元素,直到所有元素全部下沉。
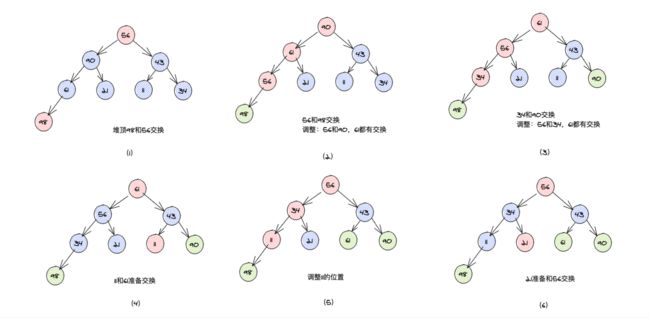
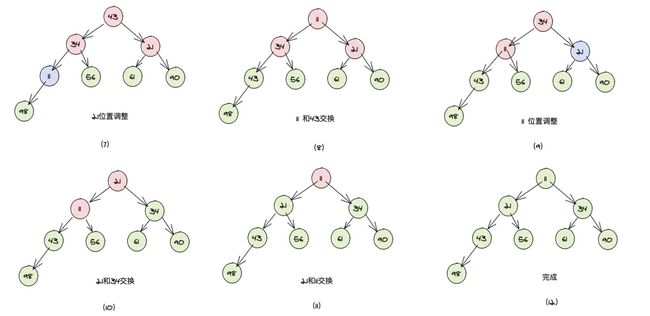
倘若一个数组为 [11,21,34,43,56,61,90,98],动态的过程如下:
树结构形象的结构如下:

首先需要先初始化堆,也叫堆化过程,就是用父节点和子节点对比,我们采取的是大的数往上冒,小的元素往下沉,执行该操作的是每一个非叶子节点与其左右子节点分别对比,从下到上,从右到左。其中我们上面发现交换的有 43 和 34,61 和 56。
经过上面的调整,已经是一个最大堆,我们每次取最大的那个元素(堆顶的元素)和最后的元素交换,然后调整:
堆排序Java代码
public class HeapSort {
public static void heapSort(int[] nums) {
// 首先需要构建最大堆
for (int i = nums.length / 2 - 1; i >= 0; i--) {
// 从第一个非叶子结点调整结构,大的往上走
adjustHeap(nums, i, nums.length);
}
printf(nums);
System.out.println("-----------------------------");
// 交换元素和调整
for (int j = nums.length - 1; j > 0; j--) {
// 将堆顶元素与末尾元素交换
swap(nums, 0, j);
// 重新调整,大的元素往上交换
adjustHeap(nums, 0, j);
printf(nums);
System.out.println("-----------------------------");
}
}
/**
* 调整大顶堆
*/
public static void adjustHeap(int[] nums, int i, int length) {
// 取出当前元素
int temp = nums[i];
//从左节点开始
for (int k = i * 2 + 1; k < length; k = k * 2 + 1) {
// 如果右节点更大,那么指向右节点
if (k + 1 < length && nums[k] < nums[k + 1]) {
k++;
}
// 子节点的值直接给父节点
if (nums[k] > temp) {
nums[i] = nums[k];
i = k;
} else {
break;
}
printf(nums);
}
// 最后将最上面的节点置,放到当前的节点
nums[i] = temp;
}
/**
* 交换元素
*/
public static void swap(int[] nums, int a, int b) {
int temp = nums[a];
nums[a] = nums[b];
nums[b] = temp;
}
public static void printf(int[] nums) {
for (int num : nums) {
System.out.print(num + " ");
}
System.out.println("");
}
public static void main(String[] args) {
int[] nums = new int[]{98, 90, 34, 56, 21, 11, 43, 61};
printf(nums);
heapSort(nums);
printf(nums);
}
}
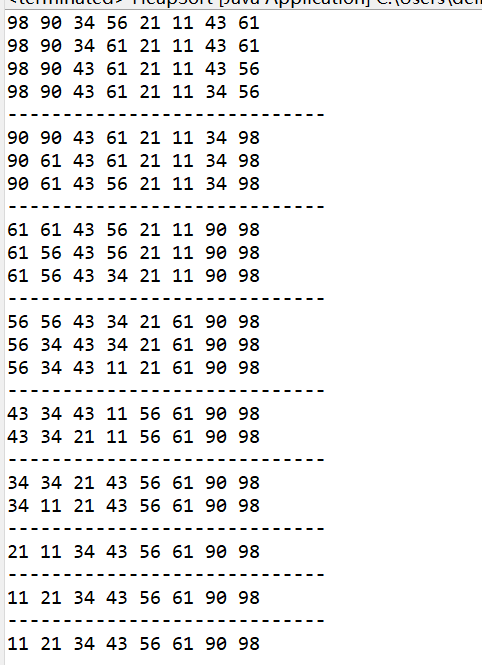
堆排序Java代码结果显示
基数排序
基数排序比较特殊,特殊在它只能用在整数(自然数)排序,而且不是基于比较的,其原理是将整数按照位分成不同的数字,按照每个数各位值逐步排序。何为高位,比如 81,1 就是低位, 8 就是高位。 分为高位优先和低位优先,先比较高位就是高位优先,先比较低位就是低位优先。下面我们讲高位优先。
主要的步骤如下:
- 将所有元素统一称为统一数位长度,前面补 0。
- 从最高位开始,依次排序,从最高位到最低位遍历完,数组就是有序的。
以数组 [98,90,34,56,21,11,43,61,39] 为例,动态的排序过程如下:
具体的流程,初始化桶:
先按照个位排序,然后从后面往前面取出数值,这里很想前面的计数排序,也很像桶排序。个位排序完之后,除了个位不同而其他位置不同的数已经保持了相对位置的排序。
再按照十位排序,也是如个位般,放到各个桶里面去,再取出,这样把所有位数都遍历完之后,取出的数组就是有序的。

基数排序Java代码
public class RadixSort {
private static void radixSort(int[] nums) {
int max = nums[0];
// 指数,从个位到十位到百位...
int exp;
// 遍历得到最大值
for (int num : nums) {
if (num > max) {
max = num;
}
}
// 从个位开始,对数组每一位进行排序
for (exp = 1; max / exp > 0; exp = exp * 10) {
// 临时数组
int[] tempNums = new int[nums.length];
// 数值 0-9,桶的个数固定为 10
int[] buckets = new int[10];
// buckets 中存储的其实是数据出现的次数
for (int value : nums) {
buckets[(value / exp) % 10]++;
}
// 每一个值等于前面的元素次数加上自身(类似计数排序)
for (int i = 1; i < 10; i++) {
buckets[i] += buckets[i - 1];
}
// 从后往前遍历,将元素写会临时数组
for (int i = nums.length - 1; i >= 0; i--) {
tempNums[buckets[(nums[i] / exp) % 10] - 1] = nums[i];
buckets[(nums[i] / exp) % 10]--;
}
// 将有序元素 tempNums 赋给 nums
System.arraycopy(tempNums, 0, nums, 0, nums.length);
printf(nums);
}
}
public static void printf(int[] nums) {
for (int num : nums) {
System.out.print(num + " ");
}
System.out.println("");
}
public static void main(String[] args) {
int[] nums = new int[]{98, 90, 34, 56, 21, 11, 43, 61, 39};
printf(nums);
radixSort(nums);
}
}
基数排序Java代码结果显示

实验总结
- 冒泡排序:基本最慢,时间复杂度最好为 O(n),最坏为 O(n2),平均时间复杂度为 O(n2),空间复杂度为 O(1),稳定排序算法。
- 选择排序:时间复杂度很稳定,最好最坏或者平均都是 O(n2),空间复杂度为 O(1),可以做到稳定排序。
- 插入排序:时间复杂度最好为 O(n),最坏为 O(n2),平均时间复杂度为 O(n2),空间复杂度为 O(1),稳定排序算法。
- 希尔排序:希尔增量下最坏的情况时间复杂度是 O(n2),最好的时间复杂度是 O(n) (也就是数组已经有序),平均时间复杂度是 O(n3/2),属于不稳定排序。
- 快速排序:时间复杂度最差的情况是 O(n2),平均时间复杂度为 O(nlogn),空间复杂度,虽然快排本身没有申请额外的空间,但是递归需要使用栈空间,递归数的深度是 log2n,空间复杂度也就是 O( log2n),属于不稳定排序。
- 归并排序:排序复杂度为 O(nlog2n),不存在好坏的情况,但是代价就是需要申请额外的空间,申请空间的大小最大为 n,所以空间复杂度为 O(n),属于稳定排序。
- 计数排序:时间复杂度为 O(n+k),申请了一个统计数组和一个新数组,空间复杂度为 O(n+k),没有所谓最好最坏,都是一个复杂度,一般适用于小范围整数排序,属于稳定排序。
- 桶排序:最好情况时间复杂度 O(n),最坏情况时间复杂度为 O(n2),平均的时间复杂度为 O(n+k)。由于在中间过程中会申请桶的数量
m,所以空间复杂度为 O(n+m),稳定性决定于桶内部排序。 - 堆排序:时间复杂度为 O(nlogn),没有申请额外的空间,空间复杂度为 O(1),属于不稳定排序。
- 基数排序:时间复杂度为 O(d(2n))。一般只使用于整数排序,不适合小数或者文字排序。由于需要申请桶的空间,假设有 k 个桶(上面是 10 个桶),则空间复杂度为 O(n+k),一般 k 较小,所以近似为 O(n),属于稳定排序。
每一种排序,都有其优缺点,我们应该根据场景选择合适的排序算法。
关于时间复杂度,我们一般使用大 O 表示法,它是一种体现算法时间复杂度的计法,通俗来讲,就是随着问题规模的增长,算法执行的指令数也在增长,时间复杂度越高,则执行时间增长越快。常见的算法时间复杂度由好到坏依次为: Ο(1) < Ο(log2n) < Ο(n) < Ο(nlog2n) < Ο(n^2n2) < Ο(n^3n3) < … < Ο(2^n2n) < Ο(n!) ,一个优秀的算法,自然少不了对低时间复杂度的追求。
但是我们也不能自然也不能忽略空间复杂度,也就是随着问题规模的增长,计算过程中所需要的存储空间增长的速度(增长率),其计算方式与时间复杂度类似。时间复杂度和空间复杂度是息息相关的两个概念,随着计算机空间越拉越大,不少的算法倾向于以空间换时间,这也是取舍的策略。
讲完这么多种排序,我们平时并非都能去实践,重要的是算法演变的过程以及设计思路。