窗口函数形如:
表达式 OVER (PARTITION BY 分组字段 ORDER BY 排序字段)
有两个能力:
- 当表达式为 rank() dense_rank() row_number() 时,拥有分组排序能力。
- 当表达式为 sum() 等聚合函数时,拥有累计聚合能力。
无论何种能力,窗口函数都不会影响数据行数,而是将计算平摊在每一行。
这两种能力需要区分理解。
底表
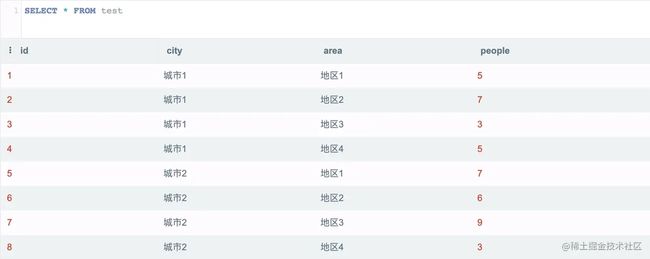
以上是示例底表,共有 8 条数据,城市1、城市2 两个城市,下面各有地区1~4,每条数据都有该数据的人口数。
分组排序
如果按照人口排序,ORDER BY people 就行了,但如果我们想在城市内排序怎么办?
此时就要用到窗口函数的分组排序能力:
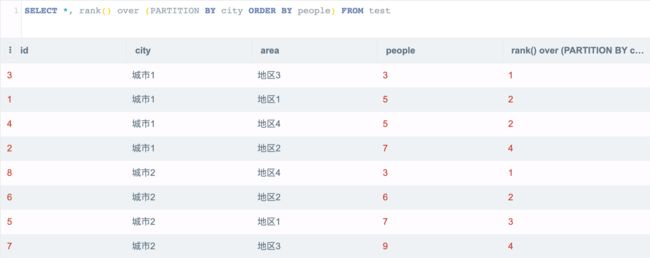
SELECT *, rank() over (PARTITION BY city ORDER BY people) FROM test
该 SQL 表示在 city 组内按照 people 进行排序。
其实 PARTITION BY 也是可选的,如果我们忽略它:
SELECT *, rank() over (ORDER BY people) FROM test
也是生效的,但该语句与普通 ORDER BY 等价,因此利用窗口函数进行分组排序时,一般都会使用 PARTITION BY。
各分组排序函数的差异
我们将 rank() dense_rank() row_number() 的结果都打印出来:
SELECT *, rank() over (PARTITION BY city ORDER BY people), dense_rank() over (PARTITION BY city ORDER BY people), row_number() over (PARTITION BY city ORDER BY people) FROM test

其实从结果就可以猜到,这三个函数在处理排序遇到相同值时,对排名统计逻辑有如下差异:
rank(): 值相同时排名相同,但占用排名数字。dense_rank(): 值相同时排名相同,但不占用排名数字,整体排名更加紧凑。row_number(): 无论值是否相同,都强制按照行号展示排名。
上面的例子可以优化一下,因为所有窗口逻辑都是相同的,我们可以利用 WINDOW AS 提取为一个变量:
SELECT *, rank() over wd, dense_rank() over wd, row_number() over wd FROM test WINDOW wd as (PARTITION BY city ORDER BY people)
累计聚合
我们之前说过,凡事使用了聚合函数,都会让查询变成聚合模式。如果不用 GROUP BY,聚合后返回行数会压缩为一行,即使用了 GROUP BY,返回的行数一般也会大大减少,因为分组聚合了。
然而使用窗口函数的聚合却不会导致返回行数减少,那么这种聚合是怎么计算的呢?我们不如直接看下面的例子:
SELECT *, sum(people) over (PARTITION BY city ORDER BY people) FROM test

可以看到,在每个 city 分组内,按照 people 排序后进行了 累加(相同的值会合并在一起),这就是 BI 工具一般说的 RUNNGIN_SUM 的实现思路,当然一般我们排序规则使用绝对不会重复的日期,所以不会遇到第一个红框中合并计算的问题。
累计函数还有 avg() min() 等等,这些都一样可以作用于窗口函数,其逻辑可以按照下图理解:

你可能有疑问,直接 sum(上一行结果,下一行) 不是更方便吗?为了验证猜想,我们试试 avg() 的结果:

可见,如果直接利用上一行结果的缓存,那么 avg 结果必然是不准确的,所以窗口累计聚合是每行重新计算的。当然也不排除对于 sum、max、min 做额外性能优化的可能性,但 avg 只能每行重头计算。
与 GROUP BY 组合使用
窗口函数是可以与 GROUP BY 组合使用的,遵循的规则是,窗口范围对后面的查询结果生效,所以其实并不关心是否进行了 GROUP BY。我们看下面的例子:

按照地区分组后进行累加聚合,是对 GROUP BY 后的数据行粒度进行的,而不是之前的明细行。
总结
窗口函数在计算组内排序或累计 GVM 等场景非常有用,我们只要牢记两个知识点就行了:
- 分组排序要结合 PARTITION BY 才有意义。
- 累计聚合作用于查询结果行粒度,支持所有聚合函数。
讨论地址是:精读《SQL 窗口函数》· Issue #405 · ascoders/weekly
到此这篇关于SQL窗口函数的文章就介绍到这了,更多相关SQL窗口函数内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!