业务场景
- 使用elasticsearch作为全文搜索引擎,对标题、内容等,实现智能搜索、输入提示、拼音搜索等
- elasticsearch索引与数据库数据不一致,导致搜索到不应被搜到的结果,或者搜不到已有数据
- 索引相关业务,影响其他业务操作,如索引删除失败导致数据库删除失败
- 为了减少对现有业务的侵入,基于数据库层面,对信息表进行监控,但需要索引的字段变动时,更新索引
- 由于使用的是mysql数据库,故决定采用alibaba的canal中间件
- 主要是监控信息基表base,监控这一张表的数据变动,mq消息消费时,重新从数据库查询数据更新或删除索引(数据无法直接使用,要数据清洗,需要关联查询拼接处理等)
- 大致逻辑
数据库变动 -> 产生binlog -> canal监控读取binlog -> 发送mq -> 索引服务消费mq -> 查询数据库 -> 更新索引 -> 消息ack
安装
下载安装
wget 地址解压即可修改配置即可启动使用wget 下载太慢了,可以自己下载下来再传到centos服务器里github1.1.5地址:https://github.com/alibaba/canal/releases/tag/canal-1.1.5
数据库启用row binlog
- 修改mysql数据库 my.cnf
- 开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式
log-bin=mysql-bin # 开启 binlog binlog-format=ROW # 选择 ROW 模式 server_id=1 # 配置 replaction 不要和 canal 的 slaveId 重复
建立canal授权账号
CREATE USER canal IDENTIFIED BY 'canal'; GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%'; FLUSH PRIVILEGES;
使用
修改配置文件canal.properties
- 主配置文件
canal.properties - 配置你的连接
canal.destinations = example,默认了个example - 启用rabbitMQ
canal.serverMode = rabbitMQ
################################################## ######### RabbitMQ ############# # 提前建好 用户、vhost、exchange ################################################## rabbitmq.host = 192.168.1.171:5672 rabbitmq.virtual.host = sql rabbitmq.exchange = sqlBinLogExchange rabbitmq.username = admin rabbitmq.password = admin rabbitmq.deliveryMode = Direct
配置单个连接
canal/conf/下- 修改
instance.properties - 需要配置数据库连接
canal.instance.master.address - 配置表过滤规则,
canal.instance.filter.regex,注意.和\\ - 配置路由规则
canal.mq.topic
示例如下
################################################# ## mysql serverId , v1.0.26+ will autoGen # canal.instance.mysql.slaveId=0 # enable gtid use true/false canal.instance.gtidon=false # position info 写连接即可,其他省略,会自动获取 canal.instance.master.address=192.168.1.175:3306 canal.instance.master.journal.name= canal.instance.master.position= canal.instance.master.timestamp= canal.instance.master.gtid= # rds oss binlog canal.instance.rds.accesskey= canal.instance.rds.secretkey= canal.instance.rds.instanceId= # table meta tsdb info canal.instance.tsdb.enable=true #canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb #canal.instance.tsdb.dbUsername=canal #canal.instance.tsdb.dbPassword=canal #canal.instance.standby.address = #canal.instance.standby.journal.name = #canal.instance.standby.position = #canal.instance.standby.timestamp = #canal.instance.standby.gtid= # username/password 先前建好的数据库用户名密码 canal.instance.dbUsername=canal canal.instance.dbPassword=canal canal.instance.connectionCharset = UTF-8 # enable druid Decrypt database password canal.instance.enableDruid=false #canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ== # table regex 只监控部分表 canal.instance.filter.regex=.*\\.cms_base_content # table black regex canal.instance.filter.black.regex=mysql\\.slave_.* # table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2) #canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch # table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2) #canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch # mq config 这个是routerkey,要配置 canal.mq.topic=anhui_szf # dynamic topic route by schema or table regex #canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..* canal.mq.partition=0 # hash partition config #canal.mq.partitionsNum=3 #canal.mq.partitionHash=test.table:id^name,.*\\..* #canal.mq.dynamicTopicPartitionNum=test.*:4,mycanal:6
配置多个连接
- 在
conf下新建文件夹,复制一份instance.properties - 在
canal.destinations里添加上面的文件夹名称 - 可以使用不同的
canal.mq.topic,路由到不同队列
配置rabbitMQ
- 登入你的rabbitMQ管理界面
http://192.168.1.***:15672/ - 确保用户存在,且有权限
- 确保vhost存在,没使用默认的
/,则创建

新建你的exchange
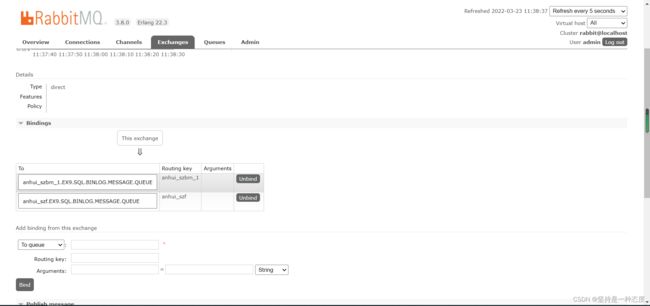
新建你的queue

根据前面配置的topic,作为routerkey将exchange与queue起来
程序改动
canal源码
- 修改
CanalRabbitMQProducer.java - 实现只监控部分字段
- 处理mq消息体,去除不需要的东西,减少数据传输
- 主要修改了
send(MQDestination canalDestination, String topicName, Message messageSub)
package com.alibaba.otter.canal.connector.rabbitmq.producer;
... ... 省略
@SPI("rabbitmq")
public class CanalRabbitMQProducer extends AbstractMQProducer implements CanalMQProducer {
// 需要监控的操作类型
private static final String OPERATE_TYPE = "UPDATE,INSERT,DELETE";
// 更新时,需要触发发送mq的字段
private static final String[] KEY_FIELDS = new String[]{"COLUMN_ID","TITLE","REDIRECT_LINK","IMAGE_LINK",
"IS_PUBLISH","PUBLISH_DATE","RECORD_STATUS","IS_TOP","AUTHOR","REMARKS","TO_FILEID","UPDATE_USER_ID"};
// 数据处理时,需要保留的字段(需把标题等传值过去,已删除数据这些查不到了)
private static final String[] HOLD_FIELDS = new String[]{"ID", "SITE_ID", "COLUMN_ID", "RECORD_STATUS", "TITLE"};
... ... 省略
private void send(MQDestination canalDestination, String topicName, Message messageSub) {
if (!mqProperties.isFlatMessage()) {
byte[] message = CanalMessageSerializerUtil.serializer(messageSub, mqProperties.isFilterTransactionEntry());
if (logger.isDebugEnabled()) {
logger.debug("send message:{} to destination:{}", message, canalDestination.getCanalDestination());
}
sendMessage(topicName, message);
} else {
// 并发构造
MQMessageUtils.EntryRowData[] datas = MQMessageUtils.buildMessageData(messageSub, buildExecutor);
// 串行分区
List flatMessages = MQMessageUtils.messageConverter(datas, messageSub.getId());
for (FlatMessage flatMessage : flatMessages) {
if (!OPERATE_TYPE.contains(flatMessage.getType())) {
continue;
}
// 只有设置的关键字段更新,才会触发消息发送
if ("UPDATE".equals(flatMessage.getType())) {
List> olds = flatMessage.getOld();
if (olds.size() > 0) {
Map param = olds.get(0);
// 判断更新字段是否包含重要字段,不包含则跳过
boolean isSkip = true;
for (String keyField : KEY_FIELDS) {
if (param.containsKey(keyField) || param.containsKey(keyField.toLowerCase())) {
isSkip = false;
break;
}
}
if (isSkip) {
continue;
}
// 取出data里面的ID和RECORD_STATUS,只保留这个字段的值,其余的舍弃
if (null != flatMessage.getData()) {
List> data = flatMessage.getData();
if (!data.isEmpty()) {
List> newData = new ArrayList<>();
for(Map map : data) {
Map newMap = new HashMap<>(8);
for (String field : HOLD_FIELDS) {
if (map.containsKey(field) || map.containsKey(field.toLowerCase())) {
newMap.put(field, map.get(field));
}
newData.add(newMap);
flatMessage.setData(newData);
// 不需要的字段注释掉,较少网络传输消耗
flatMessage.setMysqlType(null);
flatMessage.setSqlType(null);
flatMessage.setOld(null);
flatMessage.setIsDdl(null);
logger.info("====================================");
logger.info(JSON.toJSONString(flatMessage));
byte[] message = JSON.toJSONBytes(flatMessage, SerializerFeature.WriteMapNullValue);
if (logger.isDebugEnabled()) {
logger.debug("send message:{} to destination:{}", message, canalDestination.getCanalDestination());
sendMessage(topicName, message);
}
}
... ... 省略
}
微服务消费mq
- 根据前面的mq配置,建立rabbitMQ连接
- 根据前面设置好的
exchange与queue,消费mq即可 - 更新或删除索引
- ack确认索引更新失败的,根据情况,nack或者存入失败表
- 由于使用的Springboot版本较低,无法使用批量消费接口,只好使用拉模式,主动消费了
- 部分代码
package cn.lonsun.core.middleware.rabbitmq;
import cn.lonsun.core.util.SpringContextHolder;
import cn.lonsun.es.internal.service.IIndexService;
import cn.lonsun.es.internal.service.impl.IndexServiceImpl;
import cn.lonsun.es.vo.MessageVO;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.GetResponse;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.core.ChannelAwareMessageListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* @author yanyulin
* @ClassName: MessageListenerBean
* @Description: RabbitMQ消息接收者
* @date 2022-3-14 15:25
* @version: 1.0
*/
@Component
public class MessageListenerBean implements ChannelAwareMessageListener {
private static Logger log = LoggerFactory.getLogger(MessageListenerBean.class);
@Autowired
private RedisTemplate redisTemplate;
// 一次处理多少条消息,考虑es写入性能(文本较大时,单个索引可能很大),一次处理200条,模拟剩余多少条,使用2
private static final int BATCH_DEAL_COUNT = 2;
// mq里待消费线程缓存KEY
public static final String WAIT_DEAL = "wait_deal";
// 集合编码
private String code;
@Override
public void onMessage(Message message, Channel channel) throws IOException {
Thread thread=Thread.currentThread();
long maxDeliveryTag = 0;
String queuName = message.getMessageProperties().getConsumerQueue();
// 消费前,更新剩余待消费消息数量
redisTemplate.opsForValue().set(code + "_" + WAIT_DEAL, channel.messageCount(queuName) + 1);
System.out.println("==============>" + code + "=" + redisTemplate.opsForValue().get(code + "_" + WAIT_DEAL));
List messageVOList = new ArrayList<>();
List responseList = new ArrayList<>();
while (responseList.size() < BATCH_DEAL_COUNT) {
// 需要设置false,手动ack
GetResponse getResponse = channel.basicGet(queuName, false);
if (getResponse == null) {
byte[] body = message.getBody();
String str = new String(body);
log.info(code + " deliveryTag:{} message:{} ThreadId is:{} ConsumerTag:{} Queue:{} channel:{}"
,maxDeliveryTag,str,thread.getId(),message.getMessageProperties().getConsumerTag()
,message.getMessageProperties().getConsumerQueue(),channel.getChannelNumber());
// 开始消费
MessageVO messageVO = JSONObject.parseObject(str,MessageVO.class);
log.debug("监听数据库cms_base_content表变更记录消息,消息内容: {} ", JSON.toJSONString(messageVO));
messageVOList.add(messageVO);
break;
}
responseList.add(getResponse);
maxDeliveryTag = getResponse.getEnvelope().getDeliveryTag();
}
try{
if (!responseList.isEmpty()) {
for (GetResponse response : responseList) {
byte[] body = response.getBody();
String str = new String(body);
log.info(code + " deliveryTag:{} message:{} ThreadId is:{} ConsumerTag:{} Queue:{} channel:{}"
,maxDeliveryTag,str,thread.getId(),message.getMessageProperties().getConsumerTag()
,message.getMessageProperties().getConsumerQueue(),channel.getChannelNumber());
// 开始消费
MessageVO messageVO = JSONObject.parseObject(str,MessageVO.class);
log.debug("监听数据库cms_base_content表变更记录消息,消息内容: {} ", JSON.toJSONString(messageVO));
messageVOList.add(messageVO);
}
IIndexService indexService = SpringContextHolder.getBean(IndexServiceImpl.class);
indexService.batchDealIndex(messageVOList, code);
channel.basicAck(maxDeliveryTag, true);
// Ack后,更新剩余待消费消息数量
redisTemplate.opsForValue().set(code + "_" + WAIT_DEAL, channel.messageCount(queuName));
System.out.println("==============>" + code + "=" + redisTemplate.opsForValue().get(code + "_" + WAIT_DEAL));
}catch(Throwable e){
log.error("监听前台访问记录消息,deliveryTag: {} ",maxDeliveryTag,e);
//成功收到消息
try {
channel.basicNack(maxDeliveryTag,true,true);
} catch (IOException e1) {
log.error("ack 异常, 消息队列可能出现无法消费情况, 请及时处理",e1);
}
public MessageListenerBean() {
public MessageListenerBean(String code) {
this.code = code;
}
到此这篇关于使用canal监控mysql数据库实现elasticsearch索引实时更新的文章就介绍到这了,更多相关canal监控mysql数据库内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!