EMNLP2020文档级关系抽取模型GLRE 论文Global-to-Local Neural Networks for Document-Level Relation Extraction
文章目录
- 前言
- 1.摘要
- 2.模型
-
- 2.1编码层
- 2.2全局表示层
- 2.3局部表示层
- 2.4分类层
- 3.实验
前言
这是EMNLP2020一篇文档级关系抽取的论文,代码链接 https://github.com/nju-websoft/GLRE,这篇论文主要有三个亮点:
- 构建了异质图并使用了R-GCN进行特征传播,相较之前一些构建同质图然后做特征传播的模型,使用异质图可以融合更复杂的特征;
- 有一个本地表示层,通过自注意力的计算方式得到一个local entity representation,消融实验证明了这种方式可以提升关系推理的性能;
- 在关系分类时使用文档主题信息,计算关系向量对文档主题信息的注意力。
1.摘要
文档级关系抽取的目标是识别有多个句子的一篇文档中两个命名实体之间的语义关系,这需要复杂的实体关系推理。本文提出了一种新的文档级RE模型,通过对文档信息进行整体和局部两方面的信息表示进行编码,然后将实体的局部语义和全局语义表示拼接在一起得到实体对的表示,在和文档主题求注意力后进行关系分类。
2.模型
首先用BERT对输入文档以句子为单位编码,然后采用和19年EMNLP中的EoG模型一样的方式构建一个异质图,在异质图上使用R-GCN进行特征传播,接着使用一个本地表示层,最终拼接多个向量(局部表示和全局表示)得到实体对的表示,在对文档主体信息求注意力后进行关系分类。
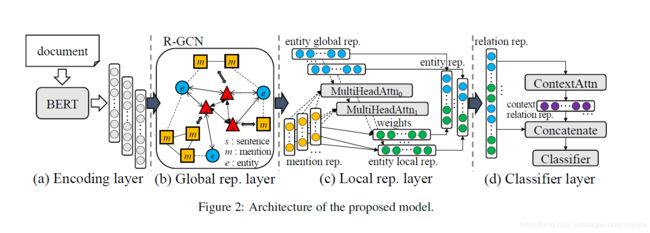
2.1编码层
D = [ w 1 , w 2 , . . . w k ] D=[w_1,w_2,... w_k] D=[w1,w2,...wk] 是输入文档,其中 w j ( 1 ≤ j ≤ k ) wj(1≤j≤k) wj(1≤j≤k) 是其中的第 j j j 个字。使用BERT对文档D进行编码:

其中 h j ∈ R d w h_j∈R^{d_w} hj∈Rdw 是在BERT最后一层输出的一系列隐藏状态。受BERT输入长度的限制,GLRE将一个长文档以短段落的形式顺序编码。
2.2全局表示层
这个模块构建了一个和EoG中相同的具有不同类型节点和边的全局异构图,以获取不同的依赖关系信息。在这个异质图中,有三种类型的节点:
- 提及节点(M节点),该节点对文档D中实体的不同提及进行建模。提及节点 m i m_i mi 的表示通过对所包含单词的表示进行平均来定义。为了区分节点类型,拼接了一个节点类型表示 t m ∈ R t d t_m∈R^d_t tm∈Rtd。因此, m i m_i mi 的表示是 n m i = [ a v g w j ∈ m i ( h j ) ; t m ] n_{m_i}=[avg_{w_j∈m_i}(h_j);t_m] nmi=[avgwj∈mi(hj);tm] ,其中 [ ; ] [ ;] [;] 是串联运算符。
- 实体节点(E节点),表示文档D中的实体。实体节点 e i e_i ei 的表示是通过其所有提及的平均(将实体对应的所有提及向量做一个平均池化)和节点类型表示 t e ∈ R t d t_e∈R^d_t te∈Rtd 来定义的。因此, e i e_i ei的表示为 n e i = [ a v g m j ∈ e i ( n m j ) ; t e ] n_{e_i}=[avg_{m_j∈e_i}(n_{m_j});t_e] nei=[avgmj∈ei(nmj);te] 。
- 句子节点(S节点),用D来编码句子。与提及节点类似,句子节点si的表示形式化为 n s i = [ a v g w j ∈ s i ( h j ) ; t s ] n_{s_i}=[avg_{w_j∈s_i}(h_j);t_s] nsi=[avgwj∈si(hj);ts],其中 t s ∈ R t d t_s∈R^d_t ts∈Rtd。
三种类型的节点两两相连共有六种类型的边,六种边有五种是可以直接表达出来的,EE边是不能直接表达,需要通过计算来进行推理然后得到的。GLRE定义了五种类型的边来建模节点之间的交互:
- 提及边(M-M):为同一句话中的任意两个提及节点添加一个边。
- 提及实体边(M-E):在提及节点和其对应的实体节点之间添加一条边。
- 提及句子边(M-S):如果提及出现在句子中,在提及节点和句子节点之间添加一个边。
- 实体句子边(E-S):如果句子中至少出现一个实体的提及,在实体节点和句子节点之间创建一条边。
- 句子边(S-S):连接所有的句子节点来对非序列信息进行建模(即打破句子顺序,建立文档级的联系)。
最后,使用L层堆叠R-GCN在全局异构图上进行特征传播。与GCN不同,R-GCN考虑了不同类型的边,能够更好地对多关系图进行建模。具体而言,其第 ( l + 1 ) (l+1) (l+1) 层的节点前向传递更新定义如下:

其中 σ ( ⋅ ) σ(·) σ(⋅) 是激活函数。 N i x N^x_i Nix 表示与边 x x x 连接的节点 i i i 的邻域集, X X X 表示边的类型集。 W x l , W 0 l ∈ R d n × d n W^l_x,W^l_0∈R^{d_n×d_n} Wxl,W0l∈Rdn×dn是可训练的参数矩阵( d n d_n dn是节点表示的维数)。将图卷积后的实体节点表示称为实体全局表示,它在整个文档范围内编码实体的语义信息。用 e i g l o e^{glo}_i eiglo表示一个实体的全局表示。
2.3局部表示层
通过将实体相关的提及表示与多头注意力结合,来学习实体针对特定实体对的局部表示。“局部”可以从两个角度来理解:
- 从编码层聚合原始提及信息。
- 对于不同的实体对,每个实体将具有与该实体对对应的一个局部表示。即假设一个实体 e 1 e_1 e1,它能够和其他三个实体组成三个实体对,那么实体 e 1 e_1 e1将针对这三个实体对各有一个局部表示。
多头注意力机制能够使模型结合多个不同表示子空间的实体信息。它的计算包括查询集Q和键值对(K,V):
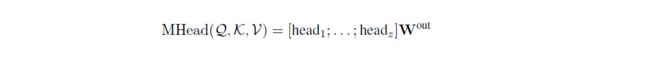
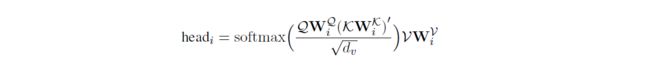
在GLRE中,Q是实体全局表示,K是图卷积前的初始句子节点表示(即R-GCN中句子节点的输入特征),V是初始提及节点表示。具体地说,给定一个实体对 ( e a , e b ) (e_a,e_b) (ea,eb),GLRE定义它的local representations如下:
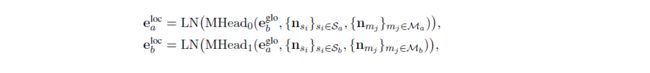
式中, L N ( ⋅ ) LN(·) LN(⋅)表示层标准化。 M a M_a Ma是 e a e_a ea对应的提及节点的集合, S a S_a Sa是 M a M_a Ma中每个提及节点所在的句子节点的集合。 M b M_b Mb和 S b S_b Sb对 e b e_b eb的定义类似。 M H e a d 0 MHead_0 MHead0和 M H e a d 1 MHead_1 MHead1是用来学习实体局部表示的独立模型参数。
关于本地表示部分注意力机制的使用,论文里有解释为什么要这样使用注意力:如果一个句子包含两个分别对应于实体 e a 、 e b e_a、e_b ea、eb的提及节点 m a 、 m b m_a、m_b ma、mb,那么提及节点表示 n m a 、 n m b n_{m_a}、n_{m_b} nma、nmb对预测 ( e a , e b ) (e_a,e_b) (ea,eb)关系的贡献更大,在得到 e a l o c , e a l o c e^{loc}_a,e^{loc}_a ealoc,ealoc时注意力权重应该更大。更一般地说,含有 m a m_a ma的句子的节点表示和 e b g l o e^{glo}_b ebglo之间的语义相似度越高,说明这个句子和 m b m_b mb在语义上更相关,所以 n m a n_{m_a} nma应该对 e a l o c e^{loc}_a ealoc给予更高的注意力权重。
2.4分类层
为了对实体对 ( e a , e b ) (e_a,e_b) (ea,eb)的目标关系 r r r进行分类,GLRE首先将实体的全局表示、实体的局部表示和相对距离表示拼接起来,作为实体的最终表示:
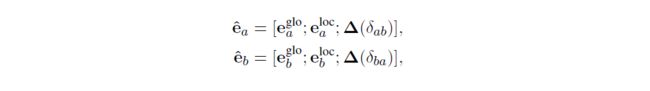
式中 δ a b δ_{ab} δab表示文件中实体 e a e_a ea的第一个提及到实体 e b e_b eb的第一个提及的相对距离。 δ b a δ_{ba} δba的定义类似。
然后,将 e a , e b e_a,e_b ea,eb的最终表示拼接起来,作为目标关系表示 o r = [ ˆ e a ; ˆ e b ] o_r=[ˆe_a;ˆe_b] or=[ˆea;ˆeb]。
此外,文档中的所有关系都隐含着文档的主题信息,例如电影中经常出现的“导演”和“角色”。反过来,主题信息暗示了可能的关系。相似主题下的一些关系可能同时发生,而不同主题下的其他关系则不可能同时发生。因此,GLRE使用自我注意来捕捉语境关系表征,融合文档的主题信息:

其中 W ∈ R d r × d r W∈R^{d_r×d_r} W∈Rdr×dr是一个可训练的参数矩阵。 d r d_r dr是目标关系表示的维度。 o i ( o j ) o_i(o_j) oi(oj)是第i个(第j个)实体对的关系表示。 θ i θ_i θi是 o i o_i oi的注意力权重。 p p p是实体对的数目。
最后,使用前向神经网络(FFNN)对目标关系表示或上下文关系表示 o c o_c oc进行预测。此外,考虑到一个实体对可能包含多个关系,GLRE将多分类问题转化为多个二元分类问题。 r r r在所有关系集合 R R R上的预测概率分布定义如下:

损失函数为:
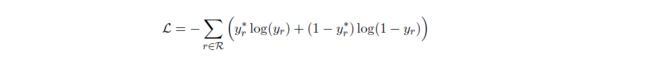
3.实验
用DocRED和CDR两个数据集做了对比实验