库函数讲解及模拟实现库函数(暂未完成版)
目录
- 库函数
-
- scanf,printf
- rand,srand,time
- assert
- 字符串类库函数
-
- strcpy
- strlen
- strcmp
- strstr
- strcat
- strncpy
- strncat
- strncmp
- strtok
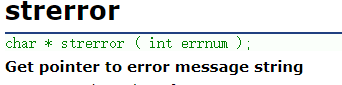
- strerror
- 内存操作函数
-
- memcpy
- memmove
- memcmp
- memset
- qsort
- 模拟实现库函数
-
- 模拟实现strcpy
- 模拟实现strlen
-
- 实现方法1:计数器方法
- 实现方法2:指针方法
- 实现方法3:函数递归方法
- 模拟实现strcmp
- 模拟实现strstr
- 模拟实现strcat
- 模拟实现qsort
- 模拟实现memcpy
- 模拟实现memmove
库函数
scanf,printf
scanf,printf
rand,srand,time
库函数
rand,生成随机数的函数,生成的数字的范围在0~RAND_MAX(32767)之间。该函数无参数,返回类型为int类型,需要的头文件为stdlib.h
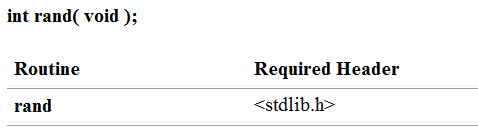
在使用rand函数之前,要调用srand函数作为生成随机数的起点
在使用这个函数之前要调用srand函数作为随机生成的起点。
srand
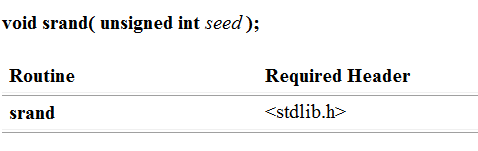
srand函数的参数为无符号的整型,返回类型为空,需要的头文件为
在生成随机数的时候,可以用time函数的返回值作为srand的参数,这样rand函数生成的数就变的非常随机了。
time
函数参数为
time_t*指针类型,返回类型为time_t,需要头文件,参数可以为NULL。

1️⃣ 扫雷项目(里面用到了)
2️⃣三子棋项目(里面用到了)
assert
计算一个表达式,当结果为FALSE时,输出一个诊断消息并中止程序。
需要的头文件为assert.h

字符串类库函数
strcpy
字符串拷贝函数:
![]()

这个是 字符串拷贝函数,里面有 两个参数,第一个参数是
char *类型(char类型的指针), 第二个是const 修饰的char *类型,把源字符串的内容拷贝到目标字符串中,即把strSource所指向的内容拷贝到strDestination中。该函数的返回类型也是char *,返回的是目标字符串的首元素地址。
这个函数所需要用头文件包含string.h。
下面看这个库函数是怎么使用的:
#include 记住源字符串中的 \0 也拷贝进去了。
看它们的内存的储存可以看出:
下面这是没有拷贝之前
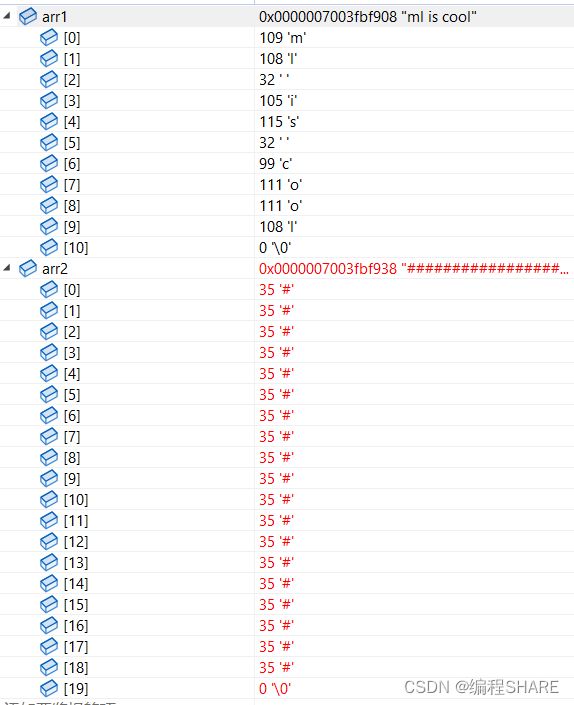
拷贝之后,可以看出来arr1中的 \0也拷贝进去了
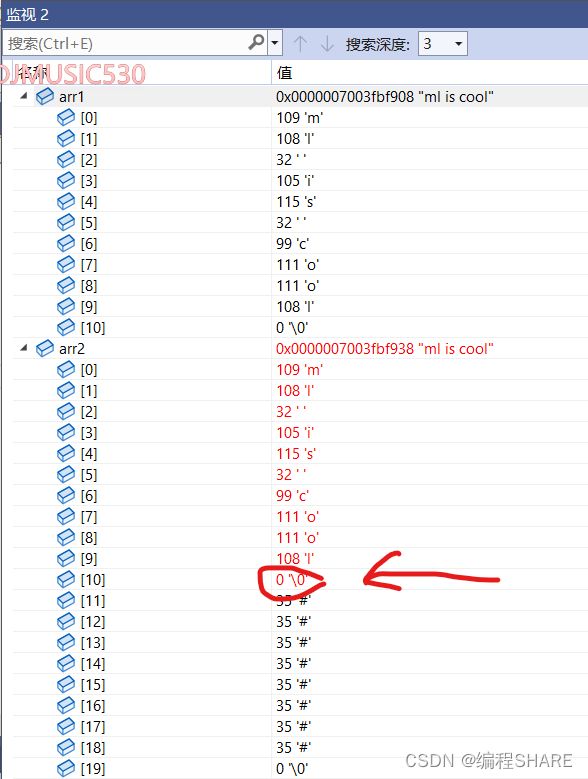
strlen
求字符串长度的函数
![]()
这是求字符串长度的函数,即
\0之前的字符个数。该函数的参数是const修饰的char*类型,函数返回的类型是size_t类型的,即unsigned int类型的(无符号整型),返回的是字符串的长度,需要引包含它的头文件,string.h.见使用方法:
int main()
{
char arr[] = "ml is cool";
int len = strlen(arr);
printf("%d\n", len);
return 0;
}
strcmp
字符串比较函数
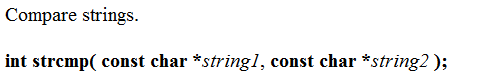


字符串比较函数,依次比较的每个字符的大小,而非字符串的长度。
该库函数的返回类型为int类型,参数有两个都是const修饰的char*类型的指针。该库函数需要引的头文件为
.
对于返回类型Int,如果string1的字符比string2的字符大就返回小于0的数,相等就返回0,大于就返回大于0的数。
比较的过程可以这么来描述,string1指向的第一个字符与string2指向的第一个字符相等的时候,就进行下一对字符的比较,如果不相等就返回大于还是小于值,否则就一直比较到\0。如果还相等就返回0.
下面就用代码来简单的演示它怎么用的:
#include strstr
查找子字符串的函数。


![]()
该函数的参数有两个,都是const修饰的char*类型的指针。需要的头文件为
。返回类型为 char *,如果查找到子串就返回第一次出现子串位置处的地址,如果不含有子串就返回空指针,如果 strCharSet 指向的字符串长度为0,就返回string。
下面就演示一下这个函数怎么用的:
#include 看运行的结果:就是返回的第一次出现该子串的地方开始打印的。
strcat
字符串追加函数



该函数的参数有两个,第一个是被追加字符串的首元素地址,第2 个参数为追加字符串的首元素地址。追加成功返回被追加字符串的首元素地址,否则返回错误。
简单的使用一下:
看代码:
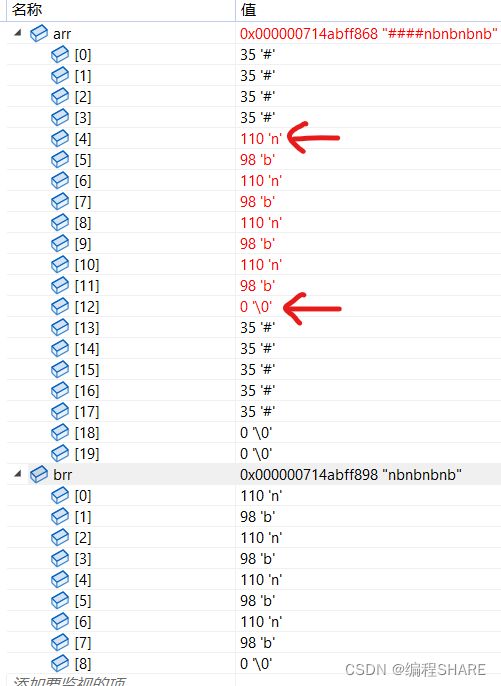
int main()
{
char arr[20] = "####\0#############";
char brr[] = "nbnbnbnb";
printf("%s\n", strcat(arr, brr));
return 0;
}
从下面的调试可以看出来字符串从
\0的地方开始追加,然后把字符串里面的所有东西包括\0全部拷进去.
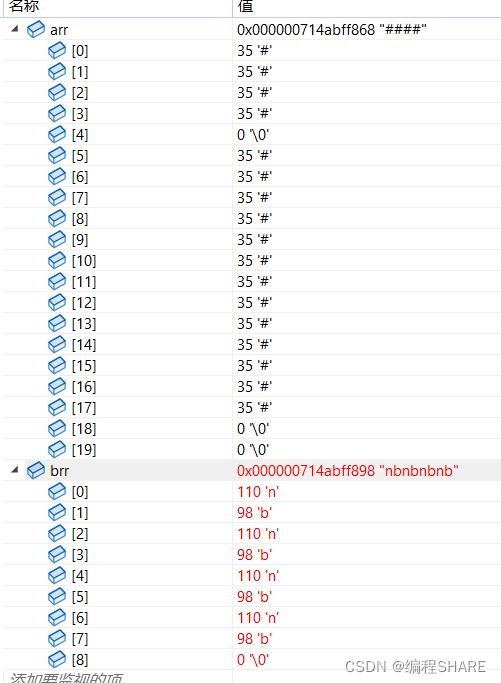
strncpy
和strcpy差不多,只不过可以控制拷贝的字符个数
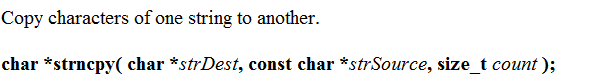
简单的演示一下它怎么使用的,看代码:
#include 如果需要拷贝的个数超过源字符串的长度,那么超过的部分都补上
\0
看下面的代码:
int main()
{
char arr[] = "abcdefabcdef";
char brr[] = "haha";
strncpy(arr, brr,6);
return 0;
}
从下面的监视窗口可以看出:
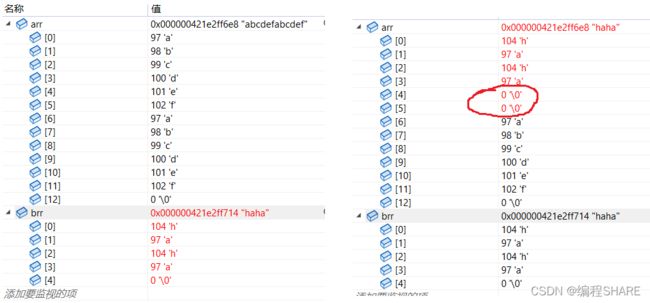
strncat
指定个数追加

简单的使用一下:
int main()
{
char arr[20] = "abcdef\0abcdef";
char brr[] = "haha";
strncat(arr, brr, 6);
return 0;
}
当追加的字符超过源字符串的长度时,如上面这个代码,也只是把源字符串里面所有的字符追加,不会报错。
strncmp
指定字符的个数进行比较:
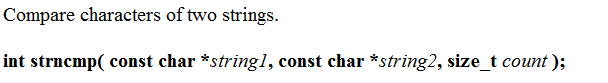
int main()
{
char arr[20] = "abcdefabcdef";
char brr[] = "haha";
printf("%d\n",strncmp(arr, brr, 3));
return 0;
}
strtok
查找字符串中分割符的函数

该函数有两个参数,第一个参数是
char *类型的,用于接收字符串首元素的地址;第二个参数是const 修饰的char *类型的,接收的是分割字符的地址。
如果这个函数找到分割符,就把该字符覆盖成\0,并记住该处的位置。返回刚开始查找字符的地址。如果没有找到就返回空指针,即NULL。
当第一次调用这个函数的时候,第一个参数位接收字符串首元素的地址。
如果继续查找该字符串,则第二次调用该函数的,第一个参数为空指针即NULL。查找到\0之后就停止了。
代码演示:
#include 优化一下
int main()
{
char arr[] = "abcd.eee@eee";
char brr[] = "@.";
char* str = arr;
for (str = strtok(arr, brr); str != NULL; str = strtok(NULL, brr))
{
printf("%s\n", str);
}
return 0;
}
strerror
返回错误码对应的错误信息
#include 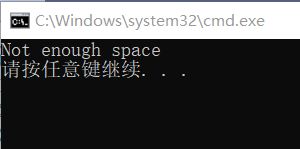
内存操作函数
memcpy

内存拷贝函数:
指定str指向的count个字节的内存拷贝到dest指向的内存。
返回dest指向内存的首地址。
看代码:
#include 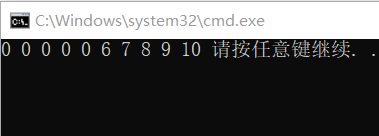
memmove
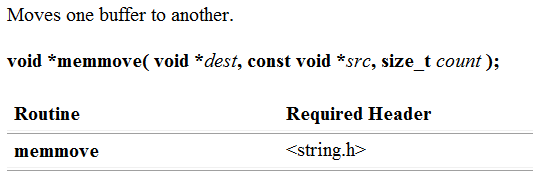
这个也是内存拷贝,它可以解决自己对自己拷贝。弥补了
memcpy不能自己对自己的拷贝的缺陷。
看代码:
#include 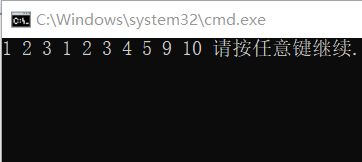
memcmp

内存比较函数,依次比较的是每个字节里面数值的大小。
返回值看下面的图:

#include 
memset

内存设置:
把内存里面的数值,重新设置成指定数,设置的是一个字节的内存,count表示要改变多少个字符的内存,返回改变内存的地址。
#include 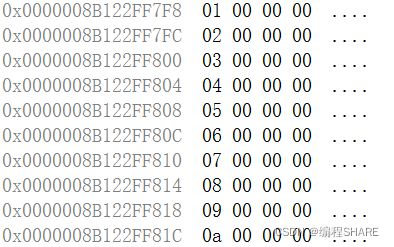
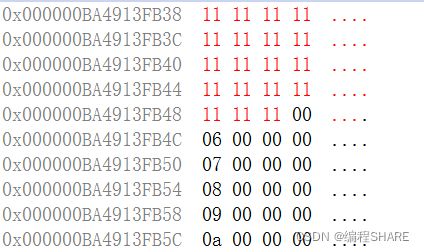
从上面的图片可以看出
qsort

排序函数,可以排序各种类型的,它需要的头文件为stdlib.h它的返回类型为空,参数有4个,
void *ptr,待排序数组的指针
size_t count,元素的个数
size_t size,每个元素的大小
int (*comp)(const void *a, const void *b)
比较函数,这个比较函数的返回类型为int 类型,参数有2个,都是const 修饰的void*类型的指针
如果*a>*b返回大于0的整数,*a<*b返回小于0的整数,相等时返回0。
void* 的类型可以接受各种类型的指针,但不能对void*类型的变量进行解引用操作。
那个比较函数是需要自己写的
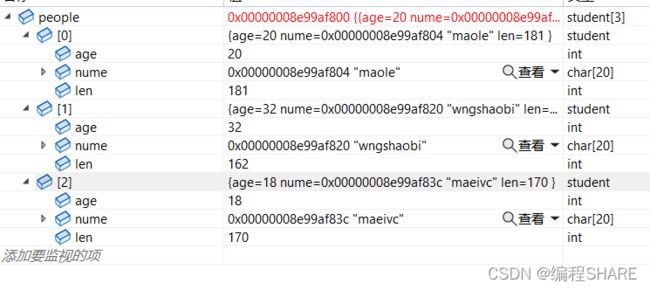
下面就尝试使用一下这个函数:以排序结构体为例
#include 这是按年龄分的
没有排序前:
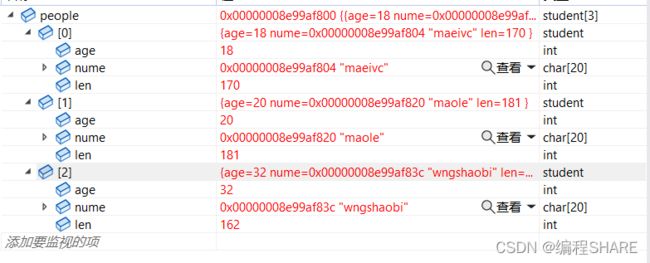
排序后:
模拟实现库函数
模拟实现strcpy
void my_strcpy(char* des,char* sor)
{
while (*sor!='\0')
先遍历源字符串的\0,把\0之前的元素全部拷贝到目标字符串中
{
*des = *sor;
des++;
sor++;
}
最后再把\0拷贝到目标字符串中
*des = *sor;
}
对上面的代码进行超级优化,一些其他的优化就不一 一展示了
char* my_strcpy(char* des, const char* sor)
{
assert(des && sor);
这个库函数上面讲了
char* ret = des;
while (*des++ = *sor++);
return ret;
}
模拟实现strlen
实现方法1:计数器方法
int my_strlen(const char* str)
{
int ret = 0;
while (*str++)
ret++;
return ret;
}
实现方法2:指针方法
size_t my_strlen(const char* str)
{
const char* temp = str;
保证temp的类型和str的类型一致
while (*++str);
为了找到\0
return str - temp;
指针相减得到它们直之间的元素的个数
}
实现方法3:函数递归方法
int my_strlen(const char* str)
{
if (*str)
return 1 + my_strlen(str + 1);
else
return 0;
}
判断是不是\0,不是指针就往后走一步,是就返回0,一步一步进行累加求和.
模拟实现strcmp
库函数的使用过程看上文
看代码:
int my_strcmp(const char* str1, const char* str2)`
{
while (*str1==*str2&&*str1&&*str2)`找到不相同的字符
{
str1++;
str2++;
}
//出来循环之后有两种情况:
//1字符不相等,
//2.至少有一个字符串访问到了\0.
//不管是哪一种情况,直接相减,即可判断谁大谁小还是相等
return *str1 - *str2;
}
模拟实现strstr
char* my_strstr(const char* str1, const char* str2)
{
const char* temp1 = str1;
const char* temp2 = str2;
if (*str2=='\0')//字符串长度为0直接返回str1
return (char*)str1;
while (*str2)
{
while (*str1 != *str2 )
{
str1++;
if (*str1 == '\0')
return NULL;
}
//找到了相同的字符了
temp1 = str1;
while (*str1 == *str2)
{
str1++;
str2++;
if (*str2 == '\0')
return (char*)temp1;
}//没有找到,从新进行标记查找
str2 = temp2;
str1 = temp1 + 1;
}
}
KMP算法解法
模拟实现strcat
char* my_strcat(char* dest, const char* sou)
{
char* ret = dest;
while (*dest)找到\0
{
dest++;
}
while (*dest++ = *sou++)追加
;
return ret;
}
模拟实现qsort
用冒泡排序函数模拟实现qsort
int cmp_stu_age(const void* a,const void* b)
这个是需要自己的定义的
{
int aa = ((stu*)a)->age;
int bb = ((stu*)b)->age;
if (aa > bb)return 1;
if (aa < bb)return -1;
return 0;
}
void swap(char* e1,char* e2,int size)
这里是内存中的数据以一个一个字节的形式进行交换
{
int i = 0;
char temp;
for (i=0;i<size;i++)
{
temp = *(e1 + i);
*(e1 + i) = *(e2 + i);
*(e2 + i) = temp;
}
}
void my_qsort(void* ptr,int n,int size,int(*cmp)(const void*,const void*) )
{
int i, j;
int count = 0;
for (i=0;i<n-1;i++)
{
for (j=0;j<n-1-i;j++)
{
if ((cmp((char*)ptr + j * size , (char*)ptr + (j + 1) * size)) > 0)
{
swap((char*)ptr + j * size, (char*)ptr + (j + 1) * size,size);
count = 1;
}
}
if (count == 0)
break;
}
}
int main()
{
stu people[3] = { {20,"maole",181},{32,"wngshaobi",162},{18,"aeivc",170}};
my_qsort(people, sizeof(people) / sizeof(people[0]), sizeof(people[0]), cmp_stu_age);
return 0;
}
模拟实现memcpy
void* my_memcpy(void* dest, const void* src, int count)
{
void* ret = dest;
while (count--)
{
*(char*)dest = *(char*)src;
dest = (char*)dest + 1;
src = (char*)src + 1;
}
return ret;
}
模拟实现memmove
有两种情况,第一是,
src < dest,另一种是大于等于的情况。每种情况的拷贝方法不一样,前一个是从后往前拷,后一个是从前往后后拷。
void* my_memmove(void* dest, const void* src, int count)
{
void* ret = dest;
if (src < dest)
{
while (count--)
*((char*)dest+count) = *((char*)src + count);
}
else
{
while (count--)
{
*(char*)dest = *(char*)src;
dest = (char*)dest + 1;
src = (char*)src + 1;
}
}
return ret;
}
