CutPaste: Self-Supervised Learning for Anomaly Detection and Localization 全文翻译+详细解读
CutPaste: Self-Supervised Learning for Anomaly Detection and Localization 全文翻译+详细解读
- 文章速览
- 全文翻译及详细解释
-
- 0.摘要Abstract
- 1.介绍Introduction
- 3. Related Work 相关工作
- 4. Experiments 实验
- 5. Ablation Study 消融研究
- 6. Conclusion 总结
- 代码测试-个人实验
- 总结
文章速览

截止2021年7月28日,此方法在MVtec AD异常检测数据集上的表现排第三
橘色字体部分都是个人解读部分,红色字体是我认为非常重要的部分
论文名:基于自监督学习的图像异常检测和定位方法
网址:CutPaste网址链接
作者:Chun-Liang Li*, Kihyuk Sohn*, Jinsung Yoon, Tomas Pfister Google Cloud AI Research
发表刊物:CVPR
发表时间:2021
相关概念:CutPaste One-Class classification Anomaly Detection
提出方法:CutPaste
全文翻译及详细解释
0.摘要Abstract
论文中提出了一种高性能的图像缺陷异常检测模型,可以不依赖于异常数据来检测未知的异常pattern(即异常缺陷)。框架整体属于 two-stage:首先通过自监督学习方法来学习正常图像的表示,然后基于学习到的图像表示来构建单分类器。CutPaste 技术主要是通过图片剪切然后再粘贴至其它位置来构造负样本。实验部分在 MVTec 数据集中验证了模型对图片缺陷检测的有效性,如果不使用预训练那么可以比当前 baselines 的 AUC 提升 3.1 ,如果基于 ImageNet 进行迁移学习那么 AUC 可以达到 96.6。
说白了其实就是一种只有好品的异常检测方法,框架分为两个阶段,第一阶段就是通过自监督学习方法来学习正常图像的表示,第二阶段是基于学习到的图像表示来构建单分类器,其实从这两句话基本啥信息也获取不到,我第一看的时候也是一头雾水,但是别着急,慢慢把文章全部看完后理解的会深一些。另外Cutpaste其实就是就是从一幅图中cutout(cutout你可以理解成扣取)一个patch(一小块图像)然后paste到好品图中,一开始我也很费解到底是从那些图中扣取,看完后才知道原来就是从已知的正常样品图中扣取。最后巴拉巴拉说了一下AUC多棒等等。
1.介绍Introduction
来自不同视觉应用的许多问题都是关于异常检测的。包括制造行业的缺陷检测。医药图像分析,以及视频监控。不像以前的有监督学习任务,异常检测面对着独特的挑战。首先就是异常数据是极难获取的。其次,正常和异常模式之间的差异通常是细粒度的,因为高分辨率图像中的缺陷区域可能很小而且很细微。由于异常数据比较难以获取,构建异常检测器通常是半监督下进行,或者仅使用正常数据进行一类分类设置。由于异常块的分布是事先未知的。我们训练模型来学习好品中的patterns并在这些模型不能很好地表示测试示例时确定异常。例如,训练到的自动编码器(可以理解成模型)当用于在数据重建误差较高时被用于声明是异常。当概率密度值低于某个阈值时,生成模型会声明异常。(有点类似于生成器和判别器了,gan的思想。)然而,被定义为像素级重建误差或概率密度的聚合的异常分数缺乏捕捉高级语义信息。
使用高级学习表示的替代方法已显示出更有效的异常检测。例如,深度一类分类器展示了一种有效的端到端训练的由深度神经网络参数化的一类分类器。Deep one-class classification,这篇文章要看一下,也是用于异常检测。另外deep SVDD的方法,论文中比较了另外两种使用深度学习来解决异常检测的方法:Autoencoder和AnoGAN本文提出了一种新的深度异常检测的方法,灵感来源于基于核的单分类问题以及最小体积估计。我们的方法Deep SVDD,训练一个神经网络,然后最小化包含网络中数据特征的超球体积,提取数据分布变化的共同因素。而论文《Deep one-class classification》则属于One-Class Neural Networks这一类。在One-Class Neural Networks这一类中,作者还介绍了另外一篇论文——《anomaly detection using one-class neural networks》,这些都是使用深度神经网络实现的. 主要是看了看文章的引用部分比单分类的SVM强。另一种就是基于重构的方法,自动编码器法。在自监督表示学习中还有一种方法是,预测图像的几何变换,例如旋转,平移,对比度的学习。可以成功的区分正常值和异常值。这些方法大多是都是专注于检测语义异常值,不能检测细粒度异常缺陷。说白了他就是说以前的方法的一些局限性和弊端,对于更精细的缺陷检测的不够好。
在我们这次的工作中,重点是处理一类缺陷检测问题(所谓的一类检测问题就是异常检测,啥意思呢,就是只有好品,一个类别。而常规的缺陷检测都是二分类或者多分类的,训练集中至少有两个类别。此后不再赘述这个一分类检测问题概念),图像异常检测的一个特例。在高分辨率图像中局部存在各种形式的未知异常模式。我们遵循两阶段框架。我们首先通过解决代理任务就是paste这种事情,来学习自监督表示。然后在学到的表示中构建一个生成的 一类分类器,以将具有异常模式的数据与正常模式区分开来。我们的创新在于为自监督设计一个新颖的代理任务。具体来说,我们在正常训练数据和通过 CutPaste 增强的数据之间制定了代理分类任务,提出的数据增强策略可以剪切图像块并粘贴到图像的随机位置。CutPaste数据增强致力于产生空间不规则性以作为实际缺陷的粗略近似,这些数据是我们之前无法获取到的训练集。(缺陷训练集)。不同尺寸、横纵比,旋转角度的矩形贴片,从而形成各式各样的增强方式。尽管 CutPaste 增强样本(图 2(e))很容易与真实缺陷区分开来,因此可能是真实异常分布的粗略近似,但我们表明通过检测 CutPaste 增强引入的不规则性学习的表示可以很好地概括检测真实缺陷。我们评估了在MVTECAD上的数据集,一个真实的工业质检标准。通过从scratch(依然不是很理解这个scratch的含义,暂且理解成划痕缺陷吧)学习深度表征。图像级的异常检测AUC达到了95.2。比现有的高出3.1。(这里说的是两个,一个是Inverse-transform autoencoder for anomaly detection. arXiv preprint arXiv:1911.10676, 2019。另一个是Patch svdd: Patch-level svdd for anomaly detection and segmentation. arXiv preprint arXiv:2006.16067, 2020 Patch-SVDD)另外,此外,我们通过 ImageNet 预训练模型的迁移学习报告了最先进的 96.6 图像级 AUC。此外,我们解释了如何使用学习的表示来定位高分辨率图像中的缺陷区域。在不使用任何异常数据的情况下 ,一个简单的补丁模型扩展可以实现 96.0 像素级的定位 AUC,这改进了之前的最新技术 [61](95.7 AUC)。 我们使用不同类型的增强和代理任务进行了广泛的研究,以展示 CutPaste 增强对未知缺陷检测的自监督表示学习的有效性。
下面我们研究一下图1:

这里研究一下Figure1,也就是cutpaste过程。我们的异常检测和定位方法概述。(a)CNN通过 CutPaste(橙色虚线框)这一过程将正常好品图(蓝色)和增强(绿色)数据分布区分开来。这个增强图它从正常数据中切割出一个小的矩形区域(黄色虚线框)并将其粘贴在随机位置。表示是从整个图像或局部pathches中训练的。(b top)图像级表示为异常检测做出整体决策,并用于通过 GradCAM 神经网络输出进行可视化定位缺陷。这是像素级的。Patch级别表示从局部补丁中提取密集特征以生成异常分数图,然后将其最大池化以进行检测或上采样以进行定位。
## 2.A Framework for Anomaly Detection 异常检测整体框架
在本节中,我们展示了我们的局部区域有缺陷的高分辨率图像的异常检测框架,我们采用了一个两阶段框架用于异常检测。在第一阶段,我们从正常数据中学习深度表示,然后使用学习到的表示构建一个类分类器。随后,在下面的2.1节中,我们提出了一种通过预测 CutPaste 增强来学习自监督表征的新方法,并扩展到从局部patch中学习和提取表征。
2.1使用 CutPaste 进行自监督学习
定义好的代理任务(pretext tasks “前置任务”或“代理任务”。pretext task 通常是指这样一类任务,该任务不是目标任务,但是通过执行该任务可以有助于模型更好的执行目标任务。其本质可以是一种迁移学习:让网络先在其他任务上训练,使模型学到一定的语义知识,再用模型执行目标任务。这里提到的其他任务就是pretext task。)对于自监督表示学习至关重要。流行的方法包括旋转预测通过预测图像旋转实现无监督表示学习—2018,无监督的语义特征学习)和对比任务学习(通过正负样品来学习表征)这些方法已经被语义一类分类所研究。而我们的研究4.1,表明纯粹的使用这种方式,例如旋转预测和对比学习对于局部缺陷来说是次优的。
我们推测几何变换,例如旋转和平移,在学习语义概念的表示方面是有效的。但缺乏规律性(例如,连续性、重复性)。在图2b中,缺陷检测的异常模式通常包括不规则性,例如裂缝(瓶子、木头)或扭曲(牙刷,网格)。我们的目标是设计一种创建局部不规则模式的增强策略。 然后我们训练模型来识别这些局部不规则性,希望它可以在测试时推广到看不见的(无形的,无法预知的)真实缺陷。
一种可以在图像中产生局部不规则性的流行增强方法是 Cutout,擦除了随机选择的一小块矩形区域。Cutout被发现是一种有效的数据增强方式强制执行不变形。提高多类分类任务的准确性。相比之下,我们首先将 Cutout 图像与正常图像区分开来。乍一看,这个任务似乎很容易通过精心设计的低级图像过滤器来解决。令人惊讶的是,正如我们将在第4节中展示的那样,如果事后不知道这一点,深度卷积网络不会学习这些捷径(shortcut,这里怎么解释?shortpath,中文“直连”或“捷径”)是CNN模型发展中出现的一种非常有效的结构)。在缺陷检测的算法设计中使用 Cutout 的相关论文有:XX。我们可以通过随机选择颜色和比例来使任务更难,如图 2(d) 所示,以避免幼稚的捷径解决方案。这就是为什么用scar而不用cutout。为了进一步防止学习用于区分增强图像的幼稚决策规则并鼓励模型学习检测不规则性,我们提出了如下的 CutPaste 增强:
1.从正常的训练图像中切割出一个大小和纵横比可变的小矩形区域
2.可选项:我们在补丁中旋转或修改像素值。
3.将patch粘贴回随机位置的图像。
我们在图 1 的橙色虚线框和图 2(e) 中的更多示例中展示了 CutPaste 增强过程。 遵循旋转预测 [19] 的思想,我们将所提出的自监督表示学习的训练目标函数定义如下:
![]()
其中 X 是正常数据集,CP(·) 是一个 CutPaste 增强,g 是一个由深度网络参数化的二元分类器。CE(·,·)是指交叉熵损失。实际上,在将 x 输入 g 或 CP 之前应用数据增强,例如平移或颜色抖动

上图不用我翻译了,比较简单,自己看就行。
2.2Cutpaste的变形
CutPaste-划伤。 在[16]中提出了一种称为“疤痕”的特殊情况,使用随机颜色的细长矩形框,如图2(d)所示,用于缺陷检测。 类似地,除了使用大矩形补丁的原始 CutPaste 之外,我们还提出了使用填充有图像补丁的划伤状(细长)矩形框的 CutPaste-Scar(图 2(f))。
多类分类。 虽然 CutPaste(大块)和 CutPaste-Scar 有相似之处,但两个增强的图像块的形状却大不相同。 从经验上看,它们在不同类型的缺陷上都有自己的优势。 为了在训练中利用两个尺度的优势,我们通过将 CutPaste 变体视为两个单独的类,在 normal、CutPaste 和 CutPaste-Scar 之间制定了更细粒度的 3 向分类任务。 详细研究将在第 5.2 节中介绍。
CutPaste 和真实缺陷之间的相似性。 CutPaste 的成功可以从离群值曝光 [23] 中理解,我们在训练期间生成伪异常(CutPaste)。 除了使用 [23] 中的自然图像外,CutPaste 创建的示例保留了正常示例的更多局部结构(即粘贴的补丁来着同一块区域。)这对模型学习发现这种不规则性更具挑战性。
另一方面,CutPaste 看起来确实与一些真正的缺陷相似。 一个自然的问题是,CutPaste 的成功是否源于对真实缺陷的良好模仿。 在图 3 中,我们展示了来自训练模型的表征的 t-SNE 图。 显然,CutPaste 示例几乎与真实缺陷示例(异常)不重叠,但是学习到的表示能够区分正常示例、不同的 CutPaste 增强样本和真实缺陷。 它表明 (1) CutPaste 仍然不是对真实缺陷的完美模拟,并且 (2) 从中学习以发现不规则性可以很好地概括不可见的异常。

2.3Computing Anomaly Score 计算异常分
有多种方法可以通过一类分类器计算异常分数。 在这项工作中,我们在表示 f 上构建了生成分类器,如核密度估计器 [52] 或高斯密度估计器 [43]。 下面,我们解释如何计算异常分数和如何权衡的。
尽管非参数 KDE(核密度估计,一句话概括,核密度估计Kernel Density Estimation(KDE)是在概率论中用来估计未知的密度函数,属于非参数检验方法之一) 不受分布假设的影响,但它需要许多示例才能进行准确估计 [58],并且计算成本可能很高。 由于缺陷检测的正常训练示例有限,我们考虑了一个简单的参数高斯密度估计器(GDE)主要就是用的GDE,这里再给大家两个链接用于学习GDE:GDE1GDE2,简单的说就是缺陷被当成缺陷的概率,,其对数密度计算如下。(我们注意到,作为 KDE 和 GDE 之间的中间地带的高斯混合也可用于更具表现力的密度建模。 我们没有从经验上观察到显着的性能提升。
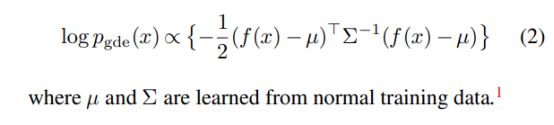
这里μ和∑都是从正常训练数据学习得到的。
Embedding 和 One Hot 编码,上面说了,Embedding 是一个将离散变量转为连续向量表示的一个方式。在神经网络中,embedding 是非常有用的,因为它不光可以减少离散变量的空间维数,同时还可以有意义的表示该变量。我们可以总结一下,embedding 有以下 3 个主要目的:在 embedding 空间中查找最近邻,这可以很好的用于根据用户的兴趣来进行推荐。作为监督性学习任务的输入。用于可视化不同离散变量之间的关系。
2.4Localization with Patch Representation 使用patch表示的定位
虽然我们提出了一种学习图像整体表示的方法,但如果除了图像级检测之外,我们还想定位有缺陷的区域 [38, 6, 61],那么学习图像块的表示将是首选。通过从图像patch中学习和提取表示。我们可以构建一个异常检测器,它能够计算图像块的分数,然后可以用来定位有缺陷的区域。
CutPaste 预测很容易应用于学习patch表示——我们在训练中需要做的就是在应用 CutPaste 增强之前裁剪patch。 类似于等式(1),训练目标可以写成:

其中 c(x) 在 x 的随机位置裁剪一个补丁。 测试时,我们从给定的所有补丁中提取embeddings (字面理解是 “嵌入”,实质是一种映射,从语义空间到向量空间的映射,同时尽可能在向量空间保持原样本在语义空间的关系,如语义接近的两个词汇在向量空间中的位置也比较接近。)。对于每个patch,我们评估其异常分数并使用高斯平滑将分数传播到每个像素 [32]。 在第 4.2 节中,我们使用补丁级检测器进行缺陷定位可视化热图,以及使用 GradCAM 等视觉解释技术的图像级检测器的热图 [51]。
3. Related Work 相关工作
假设在训练期间只给出正常数据的一类分类设置下的异常检测,已被广泛研究。自监督学习在计算机视觉中的最新成功。也已被证明对一类分类和异常检测有效。一个主要的家族是通过预测几何变换(Deep anomaly detection using geometric transformations. In NIPS, 2018|| Using self-supervised learning can improve model robustness and uncertainty. In NIPS, 2019|| Classification-based anomaly detection for general data. In ICLR, 2020)例如旋转平移和翻转。另一个系列包括具有几何增强的对比学习的变体。然而,成功仅限于语义异常检测标准上。例如 CIFAR-10 [28] 或 ImageNet [17],以及我们在4.1节中显示。依赖几何变换的方法在缺陷检测基准上表现不佳。(这篇文章没有引用padim)
由于实际应用,如工业检测或医疗诊断、缺陷检测被广泛关注。已经采取了包括自动编码在内的方法的初始步骤,GAN生成对抗网络,在 ImageNet 上使用预训练模型和通过增强解决不同代理任务的自我监督学习。提出的 CutPaste 预测任务不仅显示出在缺陷检测方面的强大性能。而且可以与现有方法相结合,例如从预训练模型进行迁移学习以获得更好的性能或基于patch的模型进行更准确的定位,我们在第四节中中展示。
3.1.Relation to Other Augmentations 与其他增强的关系 这里我觉得就是 作者避坑,怕重复,所以阐述自己论文和以前论文的不同点
尽管 Cutout [18] 和 RandomErasing [65] 类似于 CutPaste,但它们通过填充零或均匀采样像素值的小矩形区域而不是像 CutPaste 那样的结构图像块来创建不规则性。 此外,与典型的用于学习不变性表示的增强使用不同,我们学习了一种对这些增强有区别的表示。
cutout和随机擦除都是把图像的那个位置补0,而cutpaste是用图像来创建不规则性。另一个就是他们学习到了一种对这种增强有所区分的表示方式,说白了就是学到了这种不规则性。
划痕增强 [16](图 2(d))是 Cutout 的一个特例,它使用带有随机颜色的细长矩形。 虽然它展示了强大的性能,但我们展示了具有相同比例(图 2(f))的 CutPaste,它用来自同一图像的补丁填充细长矩形,改进了通过预测 Cutout 训练的表示。
说白了就是把自己的cutpaste进行了改进,怎么改呢,就和划痕增强一样,变成细长条的。
CutMix [62] 从一张图像中提取矩形图像块并粘贴到另一张图像的随机位置,在粘贴操作方面与 CutPaste 相关。 一个主要区别是 CutMix 在目标中利用现有图像标签和 MixUp [64],而 CutPaste 预测是一种不需要图像标签的自我监督学习。 另一个区别是 CutMix 研究标准监督任务(二分类或者多分类),而我们的目标是一类分类。
CutMix 是从其他缺陷图中进行cut,但是他们是从原图中搞,所以他们就是异常检测,一类分类问题,高级了。
提出了一种具有patch-swap增强作为噪声过程的去噪自编码器。 [26] 建议通过使用 GAN 预测局部增强来学习表征。 我们的方法更简单(例如,不需要训练解码器或 GAN)同时高性能,因此更实用。这里他指的是什么?是那个GDE还是最开始的目标函数?他指的这个自编码器具体是什么意思?有知道的评论区请留言,谢谢。
4. Experiments 实验
我们在 MVTec 异常检测数据集 [5] 上进行了大多数实验,该数据集包含 10 个对象和 5 个纹理类别,用于异常检测。该数据集由用于训练的正常图像和用于测试的具有各种类型缺陷的正常和异常图像组成。 它还为有缺陷的测试图像提供像素级注释。 该数据集的图像数量规模相对较小,训练图像的数量从 60 到 391 不等,这对学习深度表示提出了独特的挑战。我们遵循一类分类协议,也称为半监督异常检测 [10],2,我们在其各自的正常训练示例上为每个类别训练一类分类器。之后,我们使用 ResNet-18 [22] 从头开始通过增强预测学习表示,加上平均池化层顶部的 MLP 投影头,然后是最后一个线性层。我们基于顶部池化特征为异常检测器构建高斯密度估计(GDE)作为等式(2)
我们在 256×256 图像上训练模型。 我们注意到相同的训练策略,例如超参数的选择或数据增强,适用于所有类别。 训练的详细设置可以在附录 A 中找到。
4.1. Main Results 主要结果
我们在表 1 中报告了异常检测性能。我们用不同的随机种子运行了 5 次实验,并报告了每个类别的平均 AUC 和标准误差。 我们还报告了纹理、对象和所有类别的平均误差和标准误差的平均值。
MVTec AD 数据集上的异常检测性能 [5]。 我们报告了经过训练以对 CutPaste、CutPaste(疤痕)、两者(3 向)和基线增强(例如旋转、切除或疤痕)进行分类的表示的 AUC。 为了进行比较,我们移植了深度一类分类器 [45]、不知情学生 [6] 和补丁 SVDD [61] 的那些分类器。 我们报告了用 5 个随机种子测试的平均值和标准误差。 最后,我们使用 5 个 CutPaste(3 路)模型的集合来报告 AUC。 表现最好的模型和标准误差范围内的模型是粗体的。
旋转预测在语义异常检测中被证明是强大的 [52]。 然而,与 Cutout 变体 Scar 预测 (85.0) 相比,它导致缺陷检测的 AUC 不令人满意,为 73.1。 旋转预测的一些失败是由于未对齐的对象,例如图 2 中所示的螺丝。对于对齐的对象,虽然它在牙刷上表现良好,但在胶囊上却不是最佳的。 (可以这么理解,图像是对称的时候,旋转比较好用,图像非对称时旋转不好用)Cutout 变体的详细消融研究可在第 5 节中找到。
CutPaste 和 CutPaste-Scar 通过避免潜在的理想化的解决方案来改进 Cutout 和 Scar 预测,分别以 90.9 和 93.5 的 AUC 优于其他增强预测。 通过更细粒度的 3 向分类来利用不同规模的 CutPaste,我们实现了最佳的 95.2 AUC,这超过了从头开始学习的现有工作,例如 P-SVDD [61] (92.1 AUC)。 通过 CutPaste 提出的数据驱动方法也优于利用预训练网络的现有作品,包括带有预训练 VGG16 的 DOCC [45] (87.9 AUC) 和带有预训练 ResNet18 的 Uninformed Student [6] (92.5 AUC)。 最后,我们通过集成来自 5 个 CutPaste(3 路)模型的异常分数,进一步将 AUC 提高到 96.1。

4.2. Defect Localization 缺陷定位
我们使用我们通过 3 向分类任务训练的表示进行异常定位实验。 准确定位缺陷的一个挑战是,由于我们的模型学习图像的整体表示,因此很难使用热图式方法进行定位。 相反,我们使用视觉解释技术 GradCAM [51] 来突出影响异常检测器决策的区域。 我们在图 4 的第二行显示了定性结果,这些结果在视觉上令人愉悦。 我们进一步评估了逐像素定位 AUC,达到 88.3。
相反,我们使用 CutPaste 预测来学习图像块的表示,如第 2.4 节所述。 我们从 256×256 图像训练 64×64 块的模型。 在测试时,我们以 4 的步长密集提取异常分数,并通过使用高斯平滑的感受野上采样来传播异常分数 [32]。 我们在表 2 中报告了本地化 AUC。我们基于补丁的模型达到了 96.0 AUC。 具体来说,我们的模型在纹理类别上表现出优于之前最先进技术(96.3 AUC 与 93.7 相比)的强大性能。 我们还优于 DistAug 对比学习 [52],后者仅产生 90.4 的定位 AUC。 最后,我们在图 4 中可视化用于定位的代表性样本,即使缺陷很小也能显示准确的定位。 更全面的缺陷定位结果在附录 B 中给出。
4.3. Transfer Learning with Pretrained Models 使用预训练模型进行迁移学习
MVTec 数据集上的逐像素定位 AUC。 标准误差内的最佳和模型是粗体的。

表 3:使用在 ImageNet [17] 上预训练并通过 CutPaste(3 路)finetune的 EfficientNet (B4) [55] 的表示在 MVTec 数据集上的检测性能。 当它比相同特征下的预训练或finetune对应物(pool vs level-7)更好时,这个数字是粗体的。

在第 4.1 节中,我们已经展示了所提出的数据驱动方法比利用预训练网络更好,例如 DOCC [45] 和 Uninformed Student.这与之前关于语义异常检测的研究一致 [52]。另一方面,预训练的 EfficientNet [55] 被发现对缺陷检测有用 [43]。 如表 3 所示,未经微调,来自预训练 EfficientNet (B4) 的表示结果为 94.5 AUC,与提议的 CutPaste 预测(表 1 中的 95.2)相比具有竞争力。
在这里,我们证明了通过 CutPaste 提出的自监督学习是通用的,它还可以用于改进预训练网络以更好地适应数据。 我们使用预训练的 EfficientNet (B4) 作为主干,并按照标准的微调步骤使用相同的 CutPaste 预测(3 向)任务进行训练。 详细设置可在附录 A 中找到。我们在表 3 中显示了结果。通过 CutPaste 微调后,我们达到了新的最先进的 96.6 AUC。 此外,CutPaste 预测是一种通用且有用的策略,可以适应大多数情况下的数据。 例如,CutPaste 在类药丸上有很大的改进(81.9 →91.3)。 对于很多近乎完美的情况,比如瓶子,CutPaste 仍然能够小幅提升。 最后,正如 [30, 43] 所建议的,我们研究了各种深度特征的性能。 我们发现 level-7 feature 表现出最好的性能,我们使用 CutPaste 进一步将 EfficientNet 的 level-7 feature 从 96.8(预训练)提高到 97.1±0.0。

说白了就是cutout你怎么玩 效果都不如cutpaste
5. Ablation Study 消融研究
我们进行了各种额外的研究,以提供对提出的 CutPaste 的更深入的了解。 除了第 4.1 节中报告的标准变体之外,我们首先将 CutPaste 与不同的 Cutout 变体进行比较。 其次,我们展示了通过预测 CutPaste 学习到的表示可以很好地推广到更精心设计的看不见的缺陷。 最后,我们与语义异常检测进行比较。
5.1. From Cutout to CutPaste
我们评估了经过训练的表示的性能,以预测 Cutout 增强的变体,其区域由灰色(标准)、平均像素值、随机颜色或来自不同位置的图像补丁(即 CutPaste)填充。 我们还测试了 Confetti 噪声 [32],它会抖动局部补丁的颜色。 我们在图 5 中显示了来自考虑的增强的样本,并在表 4 中报告了检测 AUC。虽然实现 71.3 AUC 已经明显优于随机猜测,但预测标准 Cutout 增强仍然是一项简单的任务,网络可能已经从简单的代理任务中学到了一个简单的解决方案,如第 2 节所述。通过逐渐增加代理的难度 为了避免对补丁具有随机颜色的已知琐碎解决方案,或具有与正常数据的局部模式(五彩纸屑噪声,CutPaste)相似的结构,网络学习发现不规则性并更好地泛化以检测真正的缺陷。

5.2. Binary v.s. Finer-Grained Classification 2类方法合并 vs. 细粒度分类
在表 1 中,虽然 CutPaste-scar 平均表现出比 CutPaste 更好的性能,但没有明确的赢家对所有人都效果最好。 由于实践中存在多种类型的缺陷,我们利用两种增强的优势进行表征学习。 在第 2.2 节中,我们通过解决正常、CutPaste 和 CutPaste-scar 之间的 3 向分类任务来训练模型。 或者,我们训练通过区分正常示例和两个增强的并集来解决二元分类任务。
结果以及使用 CutPaste 和 CutPaste-scar 训练的表示的结果在表 5 中。很明显,使用这两种增强都可以提高性能。 在具有增强并集的二进制和 3 路之间,我们观察到通过 3 路分类任务训练的表示具有更好的检测性能。 在我们的案例中,关于 3 向公式优越性的一个合理假设是,单独对 CutPaste 和 CutPastescar 增强建模比一起建模更自然,因为它们之间在补丁的大小、形状和旋转角度方面存在系统差异。
5.3. CutPaste on Synthetic Anomaly Detection CutPaste 合成异常检测
我们进一步研究了我们的模型对看不见的异常的泛化。 具体来说,我们对通过将不同形状掩码修补到正常数据(例如数字 [29]、正方形、椭圆形或心形 [35])而创建的合成异常数据集进行测试,这些数据填充有随机颜色或自然图像。 合成异常的样本如图 6 所示,检测结果在表 6 中。我们首先注意到这些数据集并非微不足道——通过预测 Cutout 增强训练的模型仅达到 81.5。 我们提出的 CutPaste(3 路)模型在合成数据集上表现良好,平均达到 98.3 AUC。 我们强调在训练中看不到补丁中的某些形状(例如椭圆、心形)或统计数据(例如,恒定颜色、自然图像),但我们仍然可以推广到这些看不见的情况。
 说白了就是自己又做了一些缺陷,看看模型的性能,结果还不错
说白了就是自己又做了一些缺陷,看看模型的性能,结果还不错
5.4. Application to Semantic Outlier Detection 在语义异常值检测中的应用
我们还按照 [20, 52] 中的协议在 CIFAR-10 [28] 上进行语义异常检测实验,其中单个类被视为正常,其余 9 个类是异常。 我们对 Cutout、CutPaste 和旋转预测进行了比较 [52]。 Cutout 的 AUC 为 60.2,CutPaste 的 AUC 为 69.4,明显优于 Cutout (60.2)。 然而,这些仍然远远落后于 CIFAR-10 语义异常检测的旋转预测(91.3 AUC)。 另一方面,在 4.1 节中,我们已经讨论了旋转预测比 3-way CutPaste 预测差很多的相反情况。 结果表明语义异常检测和缺陷检测之间存在差异,需要不同的算法和增强设计
6. Conclusion 总结
我们提出了一种数据驱动的缺陷检测和定位方法。 我们成功的关键是使用 CutPaste 对表征进行自我监督学习,这是一种简单而有效的增强方法,可以鼓励模型找到局部不规则性。 我们在真实世界数据集上展示了卓越的图像级异常检测性能。 此外,通过学习和提取补丁级表示,我们展示了最先进的像素级异常定位性能。 我们设想 CutPaste 增强可能是构建用于半监督和无监督缺陷检测的强大模型的基石。
论文致谢。 我们感谢杨峰分享了 uninformed student 的实施和 Sercan Arik 对我们手稿的校对。
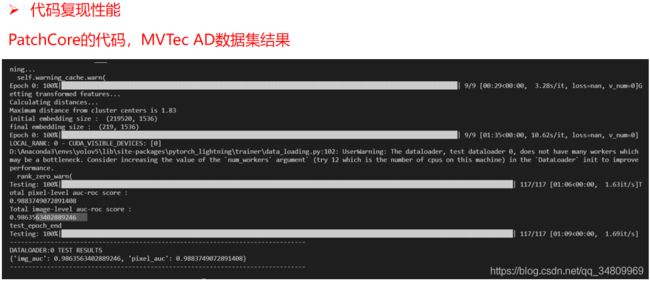
代码测试-个人实验
非官方代码地址:https://github.com/Runinho/pytorch-cutpaste
有几个重要的超参这里说明一下:
–freeze_resnet 冻结resnet的时期数,其实程序中在训练前对resnet18网络进行全部冻结,除了最后的fc层,前面所有层无法更新参数。训练时在第20轮的时候进行解冻。但是这里的epoch和传统epoch不是一个意思,对于每一epoch他们定义了256个参数更新步骤。
![]()
![]()
–head_layer 是投影头层数。论文中没有看到相关介绍,还需要研究。创建一个MLP head。其中代码作者让我们看的代码也看了,https://github.com/uoguelph-mlrg/Cutout/blob/master/util/cutout.py
这里贴的代码就是cutout的代码 ,随机找一个区域,随机长宽,扣掉,灰度值变成0,仅此而已。
–variant 就是几种不同的方法,论文中有介绍。 choices=[‘normal’, ‘scar’, ‘3way’, ‘union’],几种cutpaste的方法。
代码部分分析:
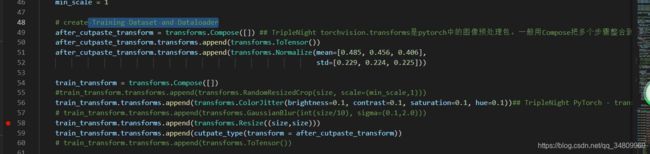
这里是创建一个Dataloader,用于搞训练的数据,先进行了归一化,然后做了一些hsv亮度上的变化,然后resize尺寸到(256,256),然后再做的cutpaste。共三个步骤:


紧接着这里做的repeat是数据均衡化:

当head_layer =1 时,head_layers = [512]*head_layer+[128] 即
head_layers 为[512, 128]一维数组。
num_classes 这个很有歧义,当cutpaste类型是3-way时就是3.否则是2。
nn.Identity()
这个函数建立一个输入模块,什么都不做,通常用在神经网络的输入层。用法如下:
mlp = nn.Identity()
print(mlp:forward(torch.ones(5, 2)))
model = ProjectionNet(pretrained=pretrained, head_layers=head_layers, num_classes=num_classes)

这里的3 是3-way的。
loss_fn用的交叉熵损失函数。
CosineAnnealingWarmRestarts 调整学习率。
num_batches 375
训练时:

xc是一个cat后的数据。

embeds 是resnet18 后的。24, 512 维的。
tmp 是 24,128维的。
logits 是 24,3维的。这是最后的logits:

loss = 1.1265

论文中也没有提到马氏距离,但是代码预测阶段最后还是通过马氏距离。代码部分的马氏距离算出来每张图的距离值,只能作为好坏品的分类使用,但是没有做出像素级的缺陷定位和热力图等。代码部分较为简单。
最终训练后的测试结果和代码作者所贴出来的基本吻合,不再赘述。
总结
CutPaste方法




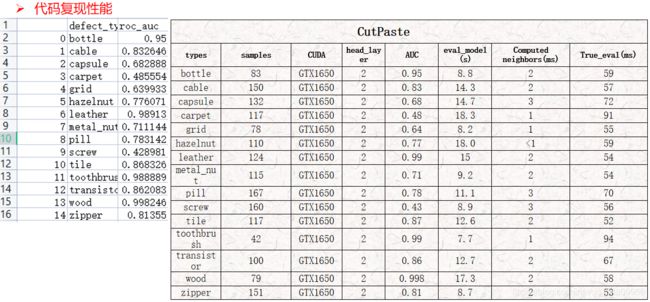
另外测试了排第一的PatchCore代码