Python之机器学习日记02——朴素贝叶斯02
机器学习日记02——朴素贝叶斯02
自然语言处理与词向量
(参考资料:liukn教授机器学习教程,网络课程)
1. 自然语言处理的几个常见应用:
1、机器翻译
2、打击文本类垃圾,如微信、邮件
3、信息提取
4、文本情感分析
5、自动问答
6、个性化推荐
自然语言处理的目标是弥补人类交流(自然语言)与计算机理解(机器学习)之间的差距,最终实现计算机在理解自然语言上像人类一样智能。未来,自然语言处理的发展将使人工智能可以逐渐面对更加复杂的情况、解决更多问题,也将为我们带来一个更加智能化的时代。




2. 什么是词向量?
词向量技术是将词转化成为稠密向量,并且对于相似的词,其对应的 词向量也相近。
• 它一般是一个布尔类型的集合,该集合中每个元素都表示其对应的单 词是否在文档中出现。这种模型通常称为词集模型,
![]()
• 词的表示
• 在自然语言处理任务中,首先需要考虑词如何在计算机中表示。通常, 有两种表示方式:
• 离散表示(one-hot representation)
• 传统的基于规则或基于统计的自然语义处理方法将单词看作一个原子符号被称作one-hot representation。one-hot representation把每个词表示为一个长向量。这个向量的维度是词表大小,向量中只有一个维度的值为1,其余维度为0,这个维度就代表了当前的词。
• 分布式表示(distribution representation)
• word embedding指的是将词转化成一种分布式表示,又称词向量。分布式表示将词表示成一个定长的连续的稠密向量。
读入写出然后应用?
共现矩阵
(1)通过统计一个事先指定大小的窗口内的word共现次数,以word周边的共现词的次数做为当前word的vector。具体来说,我们通过从大量的语料文本中构建一个共现矩阵来定义word representation。
(2)有语料如下:I like deep learning. I like NLP. I enjoy flying.

矩阵定义的词向量在一定程度上缓解了one-hot向量相似度为0的问题,但没有解决数据稀疏性和维度灾难的问题。
(3)文本看成单词向量或者词条向量,也就是说将句子转换为向量。
(4)考虑出现所有文档中的单词,再决定将哪些单词纳入词汇表或者说所要的词汇集合,然后必须要将每一篇文档转换为词汇表上的向量。
• 简单起见,先假设已经将本文切分完毕,存放到列表中,并对词汇向量进行分类标注。
• 将postingList是存放词条列表中,classVec是存放每个词条的所属类别,1代表侮辱类 ,0代表非侮辱类。
• 创建一个词汇表,并将切分好的词条转换为词条向量
• postingList是原始的词条列表
• myVocabList是词汇表。myVocabList是所有单词出现的集合,没有重复的元素。
3. 怎么做词向量?


词向量的训练
(1)P(wt|wt-k,wt-(k-1)…,wt-1,wt+1,wt+2…,wt+k)= P(wt|context)
(2)词向量效果的影响因
• 增加词向量的维度能够增加词向量效果。
• 在同一领域语料下,语料越多越好,增加不相关领域语料将会降低词向量效果。 • 大的上下文窗口学到的词向量更反映主题信息,而小的上下文窗口学到的词向量更反映词的功能和上下文语义信息。
• 语料的纯度越高(杂质少),词向量效果越好。因此,在利用语料训练词向量时,进行预处理能够提高词向量的效果。

P(wt|wt-k,wt-(k-1)…,wt-1,wt+1,wt+2…,wt+k)= P(wt|context)
P(A|B)==P(B|A)P(A)/P(B)
P(属于某类别|具有某特征) =P(具有某特征|属于某类别)P(属于某类别)/P(具有某特征)
P(属于某类别|具有某特征) =P(具有某特征|属于某类别)P(属于某类别)/P(具有某特征)
类别: 好评0 差评 1
特征:词向量

Bayes.py
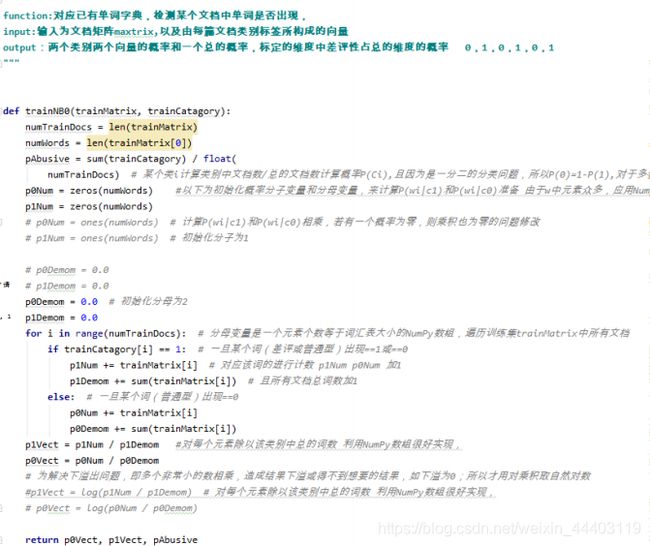

(1)p0V存放的是每个单词属于类别0,也就是差评类词汇的概率。比如p0V的第2个概率,就是worthless这 个单词属于好评类的概率为0。第4个概率,就是“有” 这个单词属于好评类的概率为0.41667,
(2) p1V的第2个概率,就是worthless这个单词属于差评类的概率为0.10526,第4个概率,就是“有” 这个单词属于差评类的概率为0,
(3)p0V存放的就是P(有 | 好评类) = 0. 417,这些单词的条件概率。
(4) p1V存放的就是各个单词属于好评类的条件概率。pAb就是先验概率。
实际例子
现有一篇被预测文档:出现了影院,支付宝,云计算,计算属于科技、娱乐的类别概率?


训练集统计结果(指定统计词频):

两个问题:
问题一:p(wn|ci) 中有一个为0,导致整个累乘结果也为0。这是错误的结论。
解决方法:将所有词的出现次数初始化为1,并将分母初始化为2。
问题二:即使 p(wn|ci) 不为0了,可是它的值也许会很小,这样会导致浮点数值类型的下溢出等精度问题错误。
解决方法:用 p(wn|ci) 的对数进行计算。具体实现请参考下面代码。针对这两个问题,它对上一步的函数做了一点修改
4.朴素贝叶斯改进之拉普拉斯平滑
拉普拉斯平滑:
(1) 拉普拉斯平滑(Laplace Smoothing)又被称为加1平滑,是比较常用的平滑方法,它就是为了解决0概率问题。
(2) 假定训练样本很大时,每个分量x的计数加1造成的估计概率变化可以忽略不计,但可以方便有效的避免零概率问题
(3) P(F1│C)=(Ni+α)/(N+αm)
(4)α为指定的系数一般为1,m为训练文档中统计出的特征词个数
平滑系数
平滑的目的也是正则化的目的之一,它是针对参数w而言,本质上就是要使得w的变化不要那么剧烈,有如下数学模型(假设最小化J):

上侧是一个典型的线性回归模型
(1)(xi,yi)就是实际的观测值,w就是估计的参数,右侧就是一个正则化项。可以直观的感受到,正则化项实际上起到了限制参数w的“变化程度或变化幅值”的作用,拉普拉斯惩罚。
(2) 可以令w的任何一个分量相比较于剩余分量变化程度保持一致,不至于出现变化特别明显的分量。直接的作用就是防止模型“过拟合”,提高了模型的泛化性能。
(3) 定义:假设f是定义在d维子空间中的一个实函数,该子空间上的拉普拉斯算子和拉普拉斯代价函数分别为:

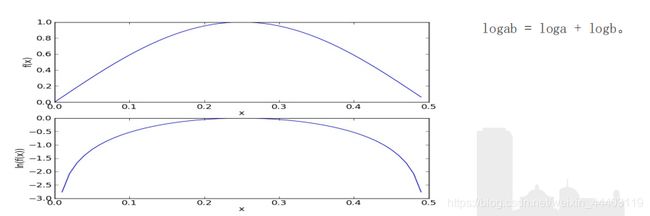
下溢出
1.太多很小的数相乘造成的。
2.两个小数相乘,越乘越小,这样就造成了下溢出。
3.在相应小数位置进行四舍五入,计算结果可能就变成0了。为了解决这个问题,对乘积结果取自然对数。通过求对数可以避免下溢出或者浮点数舍入导致的错误。
4.采用自然对数进行处理不会有任何损失。下图给出函数f(x)和ln(f(x))的曲线。
朴素贝叶斯词向量分类

朴素贝叶斯之过滤垃圾邮件
1.收集数据:提供文本文件。
2.准备数据:将文本文件解析成词条向量。
3.分析数据:检查词条确保解析的正确性。
4.训练算法:使用我们之前建立的trainNB0()函数。
5.测试算法:使用classifyNB(),并构建一个新的测试函数来计算文档集的错误率。
6.使用算法:构建一个完整的程序对一组文档进行分类,将错分的文档输出到屏幕上。
收集数据后,可建立两个文件夹ham和spam,spam文件下的txt文件为垃圾邮件,再准备数据,使用split函数对于英文文本,可以以非字母、非数字作为符号进行切分。
词袋模型(Bag Of Words, BOW)





朴素贝叶斯之新浪新闻分类(Sklearn)
首先进行数据预处理后得到数据:


得到如下结果:
![]()
文本特征选择
all_words_list就是将所有训练集的切分结果通过词频降序排列构成的单词合集。


文本特征选择
all_words_list就是将所有训练集的切分结果通过词频降序排列构成的单词合集。
结果如下:(大家可以找到其他数据试试,结果形式如下即可)

all_words_list就是将所有训练集的切分结果通过词频降序排列构成的单词合集。
1.首先去掉高频词,至于去掉多少个高频词,通过观察去掉高频词个数和最终检测准确率的关系来确定。
2.去除数字,不把数字作为分类特征。
3.去除一些特定的词语,比如:“的”,“一”,“在”,“不”,“当然”,"怎么"这类的对新闻分类无影响的介词、代词、连词。
4.使用已经整理好的stopwords_cn.txt文本。
使用Sklearn构建朴素贝叶斯分类器

1.朴素贝叶斯是一类比较简单的算法,scikit-learn中朴素贝叶斯类库的使用也比较简单。
2.在scikit-learn中,一共有3个朴素贝叶斯的分类算法类。
3.分别是GaussianNB,MultinomialNB和BernoulliNB。
4.其中GaussianNB就是先验为高斯分布的朴素贝叶斯, 5.MultinomialNB就是先验为多项式分布的朴素贝叶斯,
6.而BernoulliNB就是先验为伯努利分布的朴素贝叶斯。
7.先验概率模型就是先验概率为多项式分布的朴素贝叶斯
8.对于新闻分类,属于多分类问题。可以使用MultinamialNB()完成我们的新闻分类问题
![]()
参数说明如下:
1.alpha:浮点型可选参数,默认为1.0,其实就是添加拉普拉斯平滑,即为上述公式中的λ ,如果这个参数设置为0,就是不添加平滑;
2.fit_prior:布尔型可选参数,默认为True。布尔参数fit_prior表示是否要考虑先验概率,如果是false,则所有的样本类别输出都有相同的类别先验概率。否则可以自己用第三个参数class_prior输入先验概率,或者不输入第三个参数class_prior让MultinomialNB自己从训练集样本来计算先验概率,此时的先验概率为P(Y=Ck)=mk/m。其中m为训练集样本总数量,mk为输出为第k类别的训练集样本数。
3.class_prior:可选参数,默认为None。


优缺点:
优点:
• 朴素贝叶斯算法假设了数据集属性之间是相互独立的,因此算法的逻辑性十分简单,并且算法较为稳定,当数据呈现不同的特点时,朴素贝叶斯的分类性能不会有太大的差异。换句话说就是朴素贝叶斯算法的健壮性比较好,对于不同类型的数据集不会呈现出太大的差异性。当数据集属性之间的关系相对比较独立时,朴素贝叶斯分类算法会有较好的效果。
缺点:
• 属性独立性的条件同时也是朴素贝叶斯分类器的不足之处。数据集属性的独立性在很多情况下是很难满足的,因为数据集的属性之间往往都存在着相互关联,如果在分类过程中出现这种问题,会导致分类的效果大大降低。
感谢聆听指导!