大数据学习——Hadoop集群完全分布式的搭建(超详细)
 Hadoop集群完全分布式的搭建
Hadoop集群完全分布式的搭建
JunLeon——go big or go home
目录
Hadoop集群完全分布式的搭建
1、分布式集群的网络和节点规划
(1)网络规划
(2)节点规划
2、分布式集群的环境准备
(1)克隆虚拟机
(2)网络配置、修改主机名、配置网络映射
3、设置SSH无密码登录节点
4、安装配置Hadoop集群
(配置文件时均在hadoop的主目录下操作)
(2)配置分布式集群环境(6个配置文件)
(3)分发Hadoop集群安装目录及文件
(4)启动和停止Hadoop集群
(6)Web端访问
5、时间同步
(1)安装NTP服务器
(2)配置其他机器的时间同步
说明:此模式是在伪分布模式的基础上搭建,hadoop的主目录为/opt/hadoop2.7.3,所有的操作都是在root用户执行的。也没有做ssh安装、Java JDK、Hadoop的解压安装的步骤,详情请查看前面的博客。
1、分布式集群的网络和节点规划
(1)网络规划
主机名 IP地址 节点类型 BigData01 192.168.182.10 master BigData02 192.168.182.20 slave1 BigData03 192.168.182.30 slave2
(2)节点规划
服务 BigData01 BigDate02 BigData03 NameNode √ Secondary NameNode √ DataNode √ √ √ ResourceManager √ NodeManager √ √ √ JobHistoryServer √
2、分布式集群的环境准备
(1)克隆虚拟机
在伪分布模式的基础上,前面已经将创建好用户、安装ssh服务、安装配置Java环境等,所以把Bigdata01作为Master节点,克隆两台虚拟机作为slave节点(分别是BigData02、BigData03)。
1 进入BigData01主机,将
/etc/udev/rules.d/70-persistent-net.rules文件进行删除rm -rf /etc/udev/rules.d/70-persistent-net.rules注:该文件是Linux系统开机启动配置网卡的配置文件,重启开机后会自动生成。
2 拍摄快照
关闭虚拟机 --> 右键单击虚拟机 --> 选择
快照-->拍摄快照--> 设置快照名称和描述
注:拍摄快照是保留虚拟机此刻的状态,方便返回到相同的状态,也可以根据快照克隆相同状态的虚拟机。
3 克隆虚拟机
右键单击虚拟机-->选择
管理-->克隆-->选择克隆源(现有快照)-->选择克隆类型-->修改虚拟机名称及位置
注意:本集群用作学习使用,故选的是链接克隆,完整克隆和链接克隆的区别在于,链接克隆,如果母机宕机,克隆后的虚拟机也不可用。
(2)网络配置、修改主机名、配置网络映射
根据集群网络IP规划,分别将IP,主机名,网络映射配置好。
| IP地址 | 主机名 |
|---|---|
| 192.168.182.10 | BigData01 |
| 192.168.182.20 | BigData02 |
| 192.168.182.30 | BigData03 |
注意:在配置是需要将主机名和IP地址要一致。
网络配置文件 /etc/sysconfig/network-scripts/ifcfg-eth0
vi /etc/sysconfig/network-scripts/ifcfg-eth0注意:CentOS7和8里面,网络配置文件为:/etc/sysconfig/network-scripts/ifcfg-ens33
主机名配置文件 /etc/sysconfig/network,修改HOSTNAME=主机名
vi /etc/sysconfig/network将HOSTNAME=localhost.localdomain修改为HOSTNAME=BigData01
注意:CentOS7或8,主机名配置文件为:/etc/hostname,直接删除以前的,添加主机名
配置网络映射 /etc/hosts
vi /etc/hosts在文件最后添加 ip地址 主机名(每一台虚拟机上都要配置,如下三行都要添加)
192.168.182.10 BigData01
192.168.182.20 BigData02
192.168.182.30 BigData02
重启网络服务:
service network restart注意:如果重启网络服务失败,出现下图所示:
请查看Linux学习——那些我们网络配置遇到过的问题?ping不通百度?XShell连接不上?(超详细)_JunLeon的博客-CSDN博客 重启网络服务失败-->解决办法二

3、设置SSH无密码登录节点
执行命令在本机生成公钥、私钥和验证文件
ssh-keygen -t rsa执行命令将登录信息复制到验证文件
ssh-copy-id BigData01 # BigData01为主机名 ssh-copy-id BigData02 # BigData01为主机名 ssh-copy-id BigData03 # BigData01为主机名注:这里免密登录配置和上面一样,虚拟机相互之间都要执行
ssh-copy-id这个命令。
4、安装配置Hadoop集群
(配置文件时均在hadoop的主目录下操作)
进入Hadoop主目录:cd /opt/hadoop-2.7.3
(1)配置Java、Hadoop的环境变量
由于是在伪分布模式的基础上搭建的,故跳过jdk、hadoop的安装,但是需要保证java、hadoop的环境变量在
/etc/profile文件中已经配置好,如图所示

(2)配置分布式集群环境(6个配置文件)
对于Hadoop分布式集群模式的部署,常常需要配置的三个文件:
环境变量配置文件:hadoop-env.sh、yarn-env.sh、mapred-env.sh
全局核心配置文件:core-site.xml
HDFS配置文件:hdfs-site.xml
YARN配置文件:yarn-site.xml
MapReduce配置文件:mapred-site.xml、slaves
1 vi etc/hadoop/hadoop-env.sh 定位25行,配置自己的jdk路径即可
注意:
yarn-env.sh、mapred-env.sh两个文件可以不用配置,如果要配置,可以在首次出现“export JAVA_HOME=……”处配置为“export JAVA_HOME=/opt/jdk1.8.0_161”
2 vi etc/hadoop/core-site.xml
fs.defaultFS hdfs://BigData01:9000 hadoop.tmp.dir /opt/hadoopTmp/ 参数说明:
fs.defaultFS:该参数是配置指定HDFS的通信地址。其值为hdfs://BigData01:9000,9000为端口号。
hadoop.tmp.dir:该参数配置的是Hadoop临时目录,即指定Hadoop运行时产生文件的存储路径,其值可以自行设置,不能设置为/tmp(/tmp是Linux的临时目录)。
注意:如果在普通用户配置临时目录
/opt/hadoopTmp/,需要手动创建及修改权限。
3 vi etc/hadoop/hdfs-site.xml
dfs.namenode.http-address BigData01:50070 dfs.namenode.secondary.http-address BigData02:50090 dfs.replication 3 dfs.namenode.name.dir /opt/hadoopTmp/dfs/name dfs.datanode.data.dir /opt/hadoopTmp/dfs/data 参数说明:
dfs.namenode.http-address:该参数是配置NameNode的http访问地址和端口号。因为在集群规划中指定BigData01设为NameNode的服务器,故设置为BigData01:50070。
dfs.namenode.secondary.http-address:该参数是配置SecondaryNameNode的http访问地址和端口号。在集群规划中指定BigData02设为SecondaryNameNode的服务器,故设置为BigData02:50090。
dfs.replication:该参数是配置HDFS副本数量。
dfs.namenode.name.dir:该参数是设置NameNode存放的路径。
dfs.datanode.data.dir:该参数是设置DataNode存放的路径。
4 vi etc/hadoop/yarn-site.xml
yarn.resourcemanager.hostsname BigData01 yarn.resourcemanager.webapp.address BigData01:8088 yarn.nodemanager.aux-services mapreduce_shuffle yarn.nodemanager.aux-services.mapreduce.shuffle.class org.apache.hadoop.mapred.ShuffleHandler yarn.log-aggregation-enable true yarn.log-aggregation.retain-seconds 106800 yarn.nodemanager.remote-app-log-dir /user/container/logs 参数说明:
yarn.resourcemanager.hostsname:该参数是指定ResourceManager运行在那个节点上。
yarn.resourcemanager.webapp.address:该参数是指定ResourceManager服务器的web地址和端口。
yarn.nodemanager,aux-services:该参数是指定NodeManager启动时加载server的方式。
yarn.nodemanager.aux-services.mapreduce.shuffle.class:该参数是指定使用mapreduce_shuffle中的类。
yarn.log-aggregation-enable:该参数是配置是否启用日志聚集功能。
yarn.log-aggregation.retain-seconds:该参数是配置聚集的日志在HDFS上保存的最长时间。
yarn.nodemanager.remote-app-log-dir:该参数是指定日志聚合目录。
5 vi etc/hadoop/mapred-site.xml
mapred-site.xml文件默认不存在,可以使用模板文件mapred-site.xml.template复制一份为mapred-site.xml
复制命令:
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml文件里配置:
mapreduce.framework.name yarn mapreduce.jobhistory.address Bigdata03:10020 mapreduce.jobhistory.webapp.address BigData03:19888 mapreduce.jobhistory.intermediate-done-dir ${hadoop.tmp.dir}/mr-history/tmp mapreduce.jobhistory.done-dir ${hadoop.tmp.dir}/mr-history/done 参数说明:
mapreduce.framework.name:该参数是指定MapReduce框架运行在YARN上。
mapreduce.jobhistory.address:该参数是设置MapReduce的历史服务器安装的位置及端口号。
mapreduce.jobhistory.webapp.address:该参数是设置历史服务器的web页面地址和端口。
mapreduce.jobhistory.intermediate-done-dir:该参数是设置存放日志文件的临时目录。
mapreduce.jobhistory.done-dir:该参数是设置存放运行日志文件的最终目录。
6 vi etc/hadoop/slaves
添加你的所有节点主机名即可
BigData01 BigData02 BigData03
(3)分发Hadoop集群安装目录及文件
在Master节点上安装及配置好hadoop系统,其他slave节点完成ssh、jdk等的安装、免密登录等,既可以将在BigData01上配置好的Hadoop分发给其他节点:
分发命令:
[root@BigData01 opt]# scp -r /opt/hadoop-2.7.3 root@BigData02:/opt/ [root@BigData01 opt]# scp -r /opt/hadoop-2.7.3 root@BigData03:/opt/
(4)启动和停止Hadoop集群
在启动hadoop集群前,需要先格式化NameNode,在Master主机下操作:
格式化命令:
hdfs namenode -format也可以使用:hadoop namenode -format命令
格式化后即可启动集群的节点,可以分别启动HDFS和YARN,也可以一起启动:
全部启动命令:start-all.sh
启动和停止HDFS:
start-dfs.sh #启动HDFS stop-dfs.sh #停止HDFS启动和停止YARN:
start-yarn.sh #启动YARN stop-yarn.sh #停止YARN全部启动和停止:
start-all.sh #启动HDFS和YARN stop-all.sh #停止HDFS和YARN启动和停止历史(日志)服务器:
mr-jobhistory-daemon.sh start historyserver #启动historyserver mr-jobhistory-daemon.sh start historyserver #停止historyserver
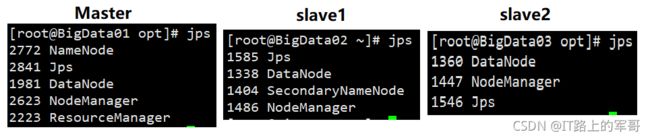
(5)验证(查看是否启动成功)
命令:jps
成功开启后,会看到下图所示的节点显示:
Master: NameNode、DataNode、ResourceManager、NodeManager
slave1: SecondaryNameNode、DataNode、NodeManager
slave2: DataNode、NodeManager
(6)Web端访问
关闭防火墙:
service iptables stop访问HDFS:50070
192.168.182.10:50070 #访问HDFS,50070是端口访问YARN:8088
192.168.182.10:8088 #访问YARN,8088是端口注意:根据自己配置的IP地址查看,必须关闭虚拟机里的防火墙,不然访问不了。
5、时间同步
Hadoop集群对时间要求非常高,主节点与各从节点的时间都必须同步。NTP使用来使计算机时间同步的一种协议。配置时间同步服务器(NTP服务器)主要就是为了进行集群的时间同步。
这里主要以BigData01作为NTP服务器,从节点BigData02和BigData03每10分钟跟BigData01同步一次。
(1)安装NTP服务器
1 安装配置NTP服务器
查看是否安装NTP服务,如果出现
ntp-x.x.x和ntpdate-x.x.x则不需要再安装rpm -qa | grep ntp安装命令:
yum install -y ntp # 使用yum在线安装
2 修改配置文件
ntp.confvi /etc/ntp.conf
① 启用restrice,修改网段
打开restrice的注释(删除前面的#号),修改为自己的网段
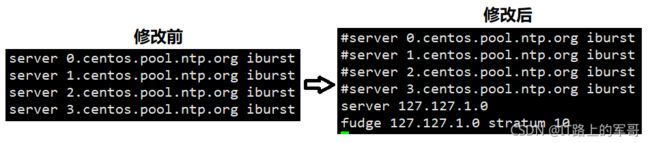
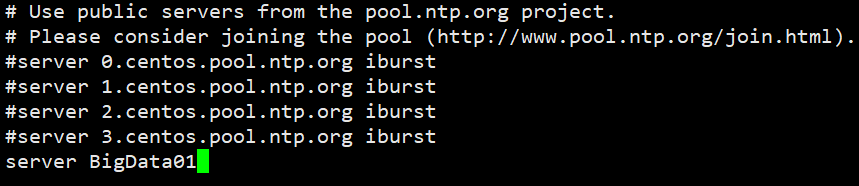
② 注释掉四行server域名,再添加两行,如图所示:
③ 修改配置文件ntpd
命令:
vi /etc/sysconfig/ntpd在此文件内,第二行添加一行
SYNC_HWCLOCK=yes,将同步后的时间写入CMOS里。
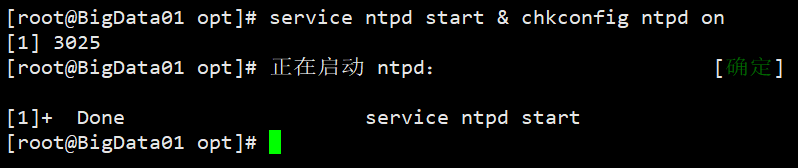
④ 启动NTP服务
service ntpd start # 启动NTP服务 chkconfig ntpd on # 开机自启动,永久启动两个命令可以连用:

(2)配置其他机器的时间同步
首先要保证从节点(其他机器)安装有NTP,然后开始配置从节点跟主节点同步时间。以下操作是在BigData02和BigData03机器上配置(剩下的这两台都要配置):
① 注释掉四行server域名配置,其后添加一行:
server BigData01② 修改配置文件ntpd,此操作和前面的NTP服务器中配置一样
③ 启动时间同步
启动NTP服务:
service ntpd start & chkconfig ntpd on也可以执行命令:
ntpdate BigData01完成同步注意:在客户机里也可以不用配置NTP,而是使用Linux定时任务来执行与NTP服务器同步时间,具体操作如下:
输入命令:
crontab -e打开vi编辑器后,添加一行:
*/10 * * * * /usr/sbin/ntpdate BigData01; /sbin/hwclock -w表示每10分钟与NTP服务器(BigData01)进行一次时间同步,并写入本机BIOS。

(3)测试集群间的时间同步
通过命令查看集群简的时间是否同步
date '+%Y-%m-%d %H:%M:%S'以“年-月-日 时:分:秒”的格式显示,如果三台时间一致,完成时间同步。然后重启虚拟机再次查看时间是否同步。
以上Hadoop分布式集群(完全分布式)就已经搭建成功了,并对其做好时间同步,方便后面去搭建高可用的环境。
下一篇:搭建Hadoop基于Zookeeper的高可用环境(超详细)
如果喜欢、对你有帮助,反手点赞+收藏,跟着军哥学习知识……