秒杀项目(前后端分离)
1P/11P项目开篇
技术点总结
1、安装开发工具
2P/11p 项目架构介绍
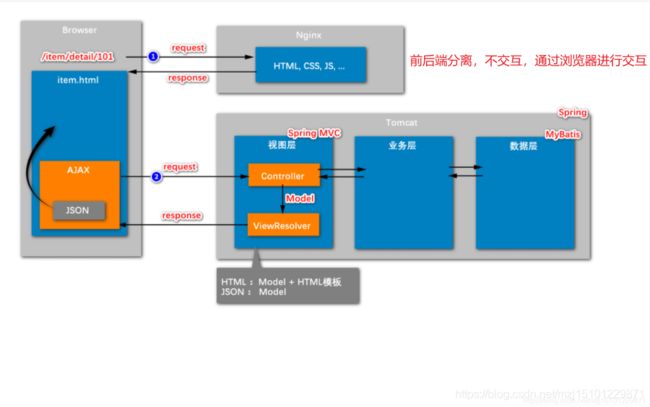
- 常见的请求:返回前端页面HTML:Model+HTML模板
- ajax异步请求:返回json数据【返回特定格式的字符串只返回Model】
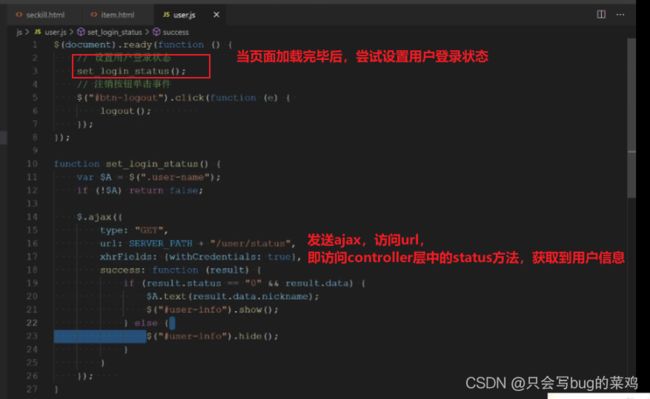
- 本项目采用前后端分离架构,从视图层返回的数据是json
- 浏览器先发送请求到静态资源服务器(niginx服务器中部署静态资源文件)或静态页面,然后再页面渲染结束时;发送一个异步的ajax请求,ajax程序从controller层中得到响应的json数据,执行
- 回调函数。将数据渲染到静态页面上去。浏览器先后发送两次请求。
- 45:00:讲解项目代码目录结构【后端】
- 48:00: 前端代码结构
- mysql数据库表一共5张表
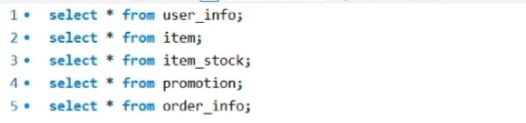
- 1、用户表
- 2、商品表
- 3、商品库存表【商品表和库存表为什么要分开,是因为要考虑到下单时扣减库存,如果不分开的话,就要在商品列表中对商品加行锁,会影响并发效率】
- 4、商品活动
- 5、订单表
- 面试题:为什么要拆分那么多层?降低耦合度。比如说dao层和业务层对数据的要求不一样,从dao层查询得到一个完整的用户数据,肯定是包含用户的密码的,但是不能将用户密码直接返回给前端页面,有风险。所以要通过有任务层去进行处理。
2p/11p 项目架构与运行
- 使用华为云服务器
- 开放端口号,在控制台,安全组中配置

- 27:00之前,部署服务器,mysql
- 安装JDK1.8
- 安装maven,修改maven的镜像地址为阿里云仓库。
- 安装idea开发工具
- 安装VSVCode
- 安装workbench【也可以在idea中进行查看】
- 打开idea,配置maven,打开项目,将项目部署。
- 修改配置文件
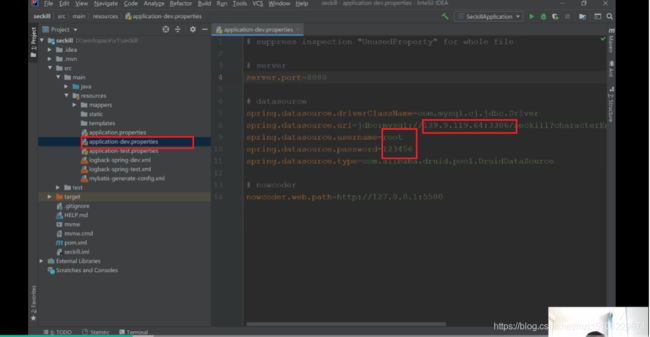
- 启动服务进行测试。
- 配置前端,打开vscode
- 安装插件
- 打开项目,配置后台路径
- open inlive server
- 成功。
- 再次总结流程

热点问题1:00开始

- 演示springboot快速构建项目
Spring
- Ioc的好处? 自动注入@Autowird。管理bean。
- Ioc的字面意思是控制反转,程序员自己创建对象并管理对象之间的关系叫正转。而控制反转的意思就是将创建对象管理对象的任务交给容器。就是把bean的管理的权力交给spring。好处就是降低我们程序中bean之间的耦合度,bean可以实现可插拔,如果在程序中想要置换某一个bean,非常方便。通常来说像实体类这种频繁发生变化的对象就不去用ioc去管理,而像service和dao这种单例的东西、可以复用的东西会采用ioc去管理。
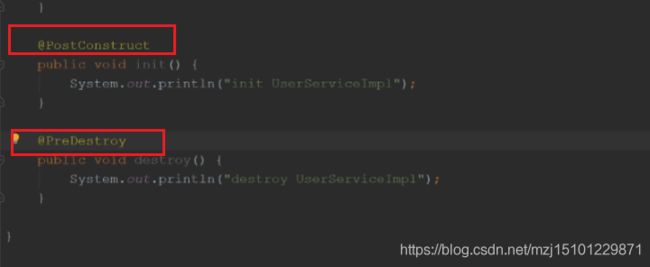
- Ioc还能管理bean的作用域和生命周期!
- 自定义方法,添加以下注解即可。
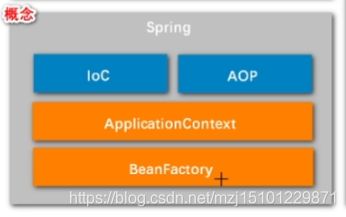
- BeanFactory和applicationContext的区别?
beanfactory就是一个bean的工厂,Ioc通过它来管理bean,applicationContext继承于beanfactory,beanfactory是给内部人士用的,applicationContext是一个子接口,功能更强,给开发者使用的。
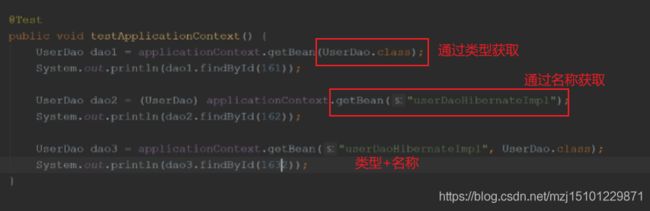
- getBean方法,applicationContext的核心功能?
springboot
- springboot如何实现自动装配?
答案
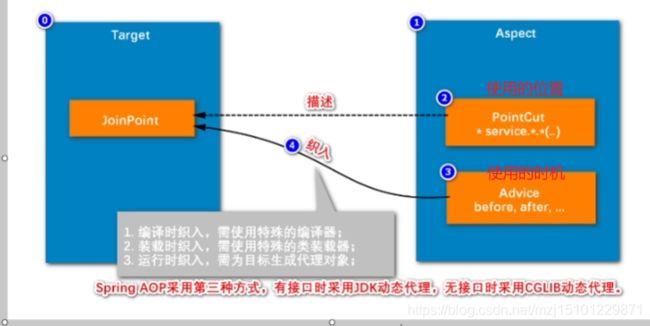
AOP的一些理解
一些注解的使用理解

SpringMvc
- SpringMvc的一些操作流程?
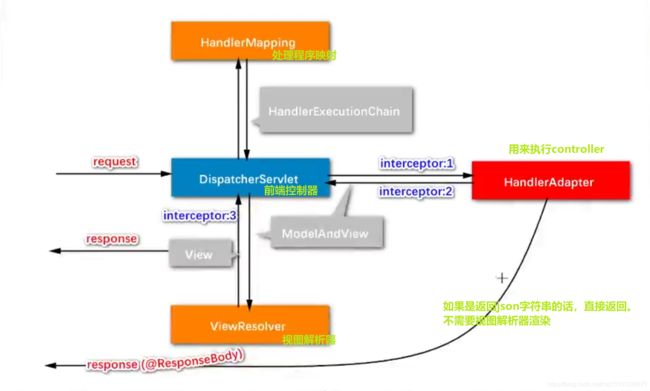
- 最好是看一下源码,现在看了一遍,不太理解。下次再看。
- 把这个流程背下来,跟着源码走一下断点。
Mybatis1:00,再看一次,整理一下。
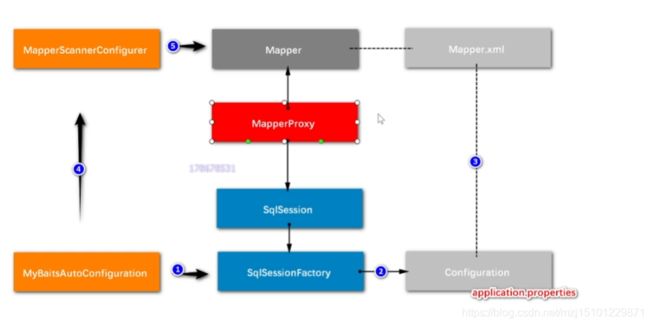
- 查看mybatis源码【下次再看】
开始登录注册功能的开发【1:24开始】
3p/11p 用户登录与注册
介绍公共代码部分
后端部分
-
统一异常处理, -所有的异常抛出,在controller层统一处理。
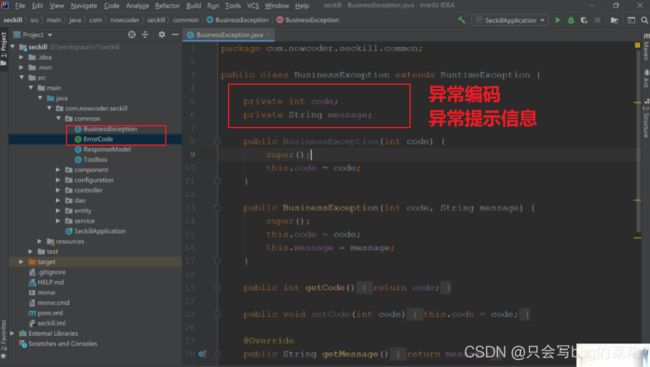
-
统一定义返回前端json数据的格式
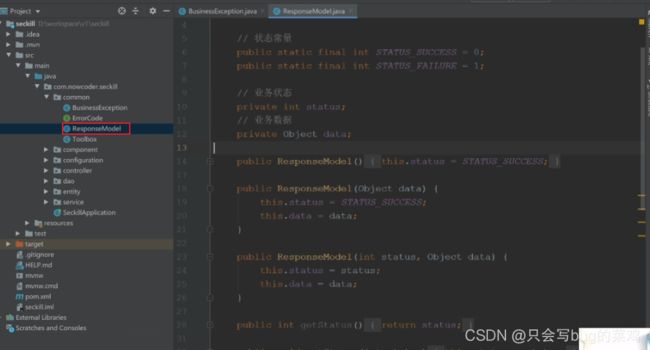
-
工具箱中新建方法:md5加密方法
-
还有一个日期的格式化方法
-
在controller中使用统一异常处理
-
springmvc提供一个机制,类似于aop,只针对springmvc这一层。当任何一个controller报异常时,就会调用此方法处理。
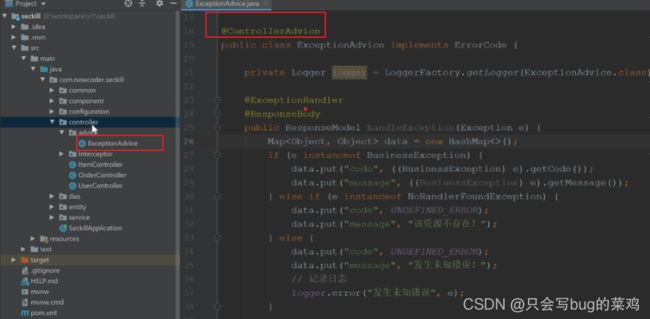
-
修改logback-spring-dev.xml中的日志文件保存位置

前端部分,使用bootstrap+jquery,轻量级的。
用户注册功能
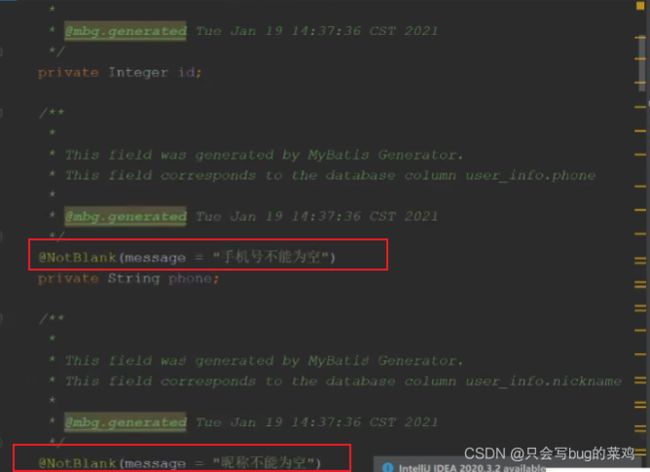
- 先看user_info表,再看user实体类,user实体类中有非空校验,虽然在前台也有校验,但是有个别请求如果不走前台逻辑,直接通过地址栏访问,很容易就出问题,所以在后台也要做校验。
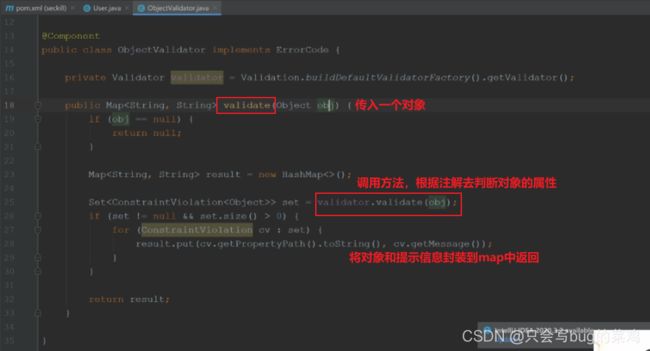
- 校验工具如下:按照工具要求对实体类进行注解。

- 上面的注解是由objectValidator使用,具体如下:
- 查看dao层。
- 查看userMapper,补充一个根据手机号查询用户的方法

- 查看service层,userservice接口
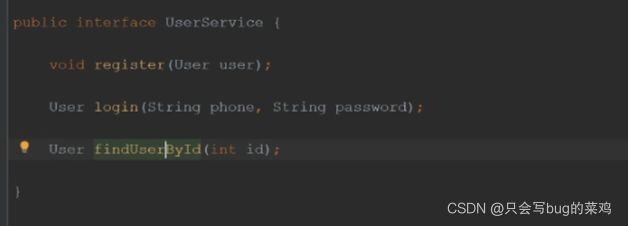
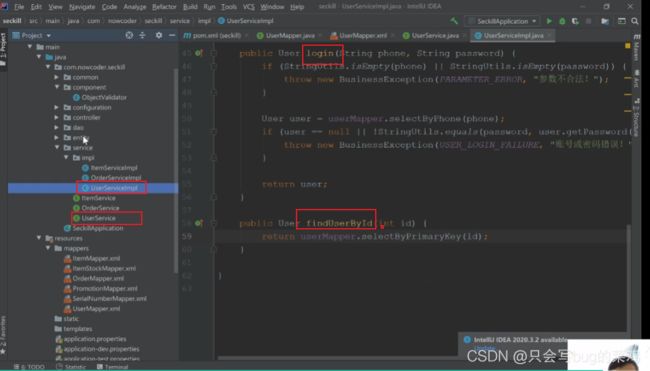
- controller层,看userController,模拟发送验证码
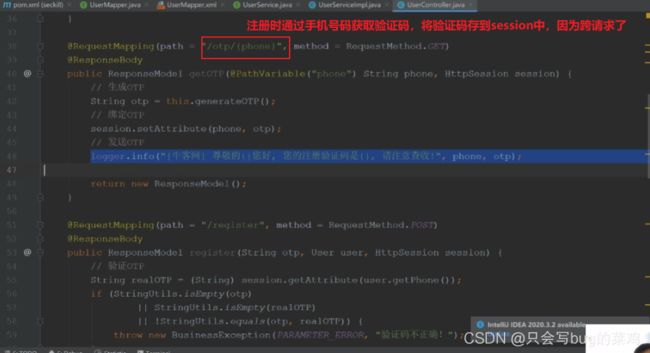
- 注册方法
- 登陆就是将user保存在session中。session保存在服务器上,相当于一个私人保险柜。
- 注销登录就是销毁session中的数据
- 查看登录状态
- 前端注册登录的逻辑。主要看js代码
- register.js代码。
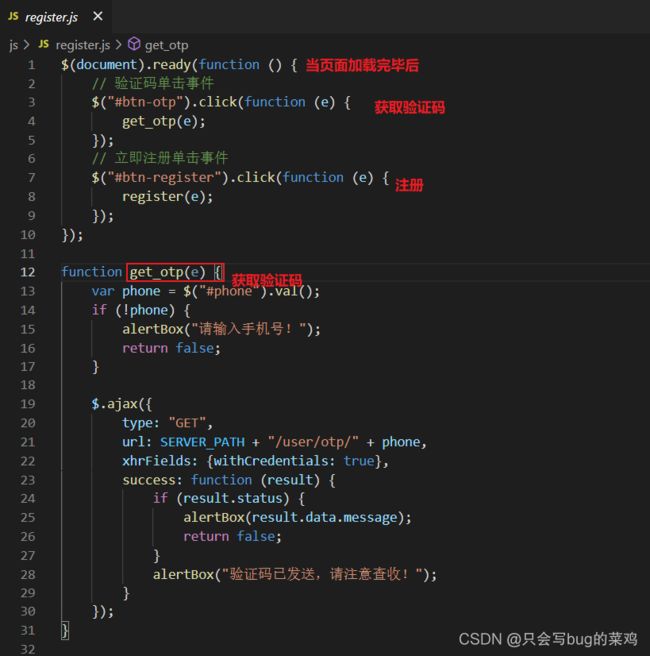
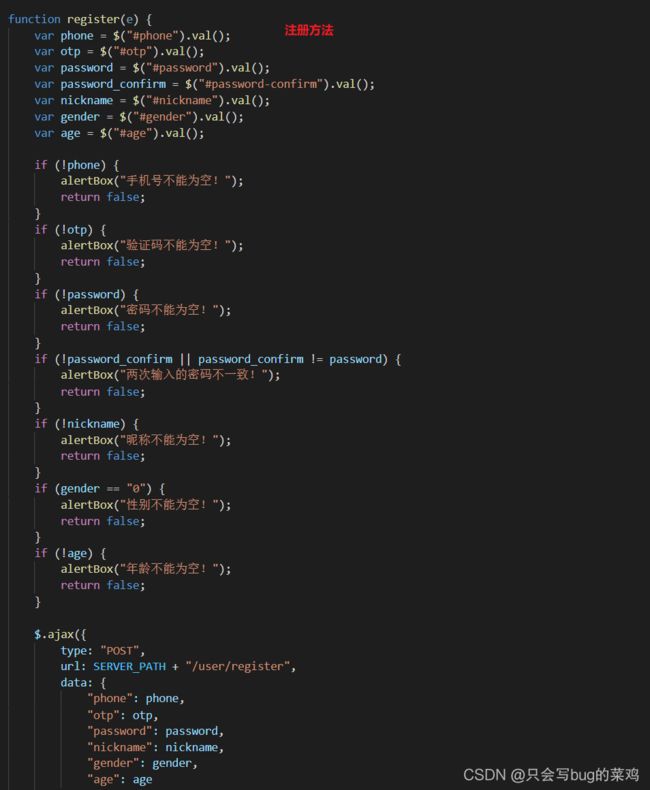
- 注册成功后跳转到注册页面
- login.js
- 如果一旦controller报错后,直接跳转到ExceptionAdvice进行处理
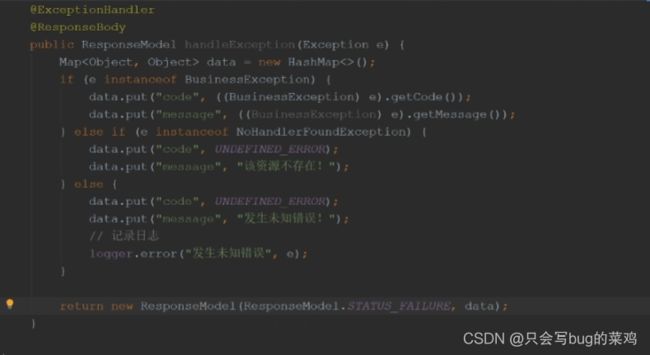
- 解决跨域问题

第四节 商品列表与详情
- Aop和拦截器的区别?使用场景?
很多地方都需要去验证用户是否登录,在这样情况下,很容易就想到aop实现,但是在这种情况下,应该使用拦截器实现。Aop是面向方法名,面向方法去过滤的。拦截器是面向url去过滤的。Filter是更高层的过滤,一般不用filter。
- 定义拦截器
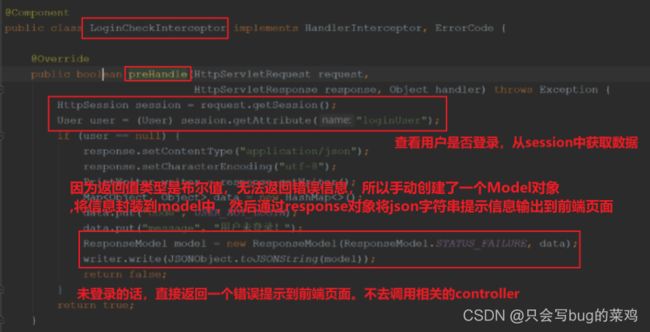
- 注册拦截器,配置需要拦截的路径。
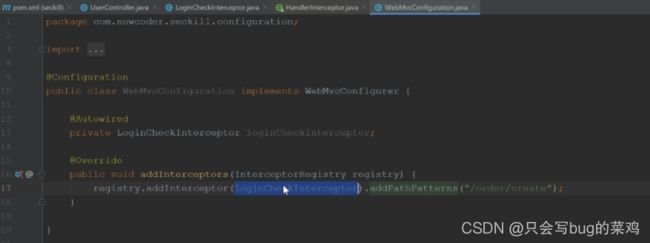
- 显示登录用户的登录信息(登录状态)
主要关键是说清楚拦截器,以及拦截器的三个方法的执行时机。为什么要使用prehandle。
热点问题1:跨域问题
方法1:代理方式,不管是访问前台服务器还是后台服务器,都通过代理服务器Nigix进行访问,
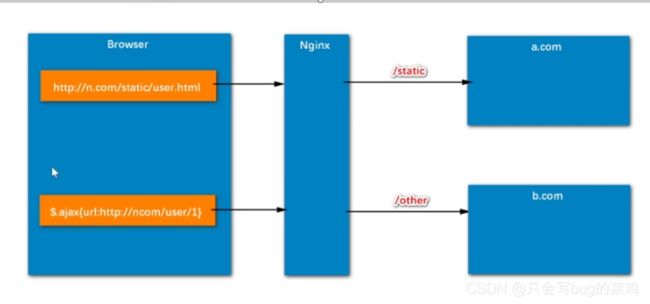
- 缺点:不灵活。
方法2:通过纯前端方法解决,是一种欺骗行为,浏览器其实是要访问动态资源,但是假装访问静态资源。
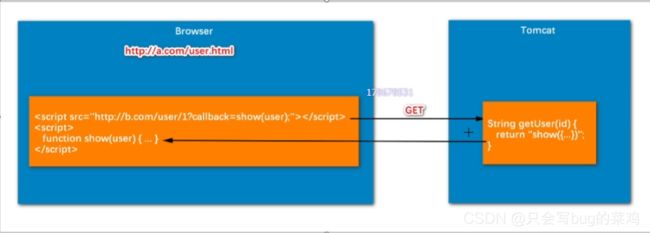
- 局限性很大【请求方式只能是Get,不能是post】,不建议使用,理解就行
方法3:通过后端注解实现。只需要后台代码中允许就可以。
在前端ajax请求中设置一下:
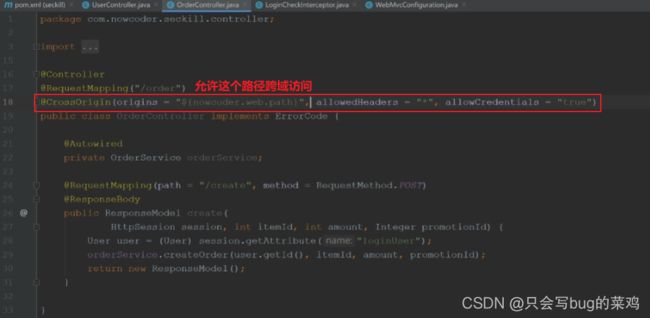
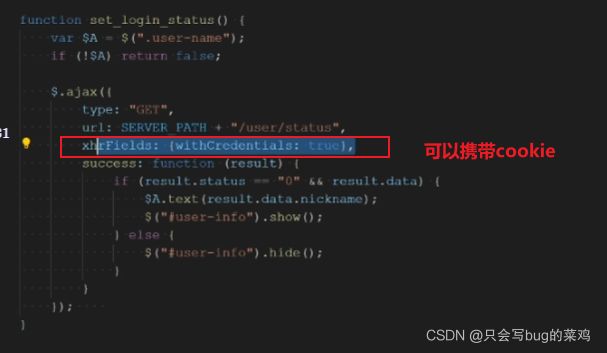
- cookie中就可以携带允许跨域的路径。
热点问题2:cookie和session
cookie是会员卡,用户可以带走,不安全,可以篡改。session是保险柜,存放在服务器上,用户只保存一个保险柜编号,比较安全。敏感信息使用session。cookie携带的信息有限,2k。session不限制。
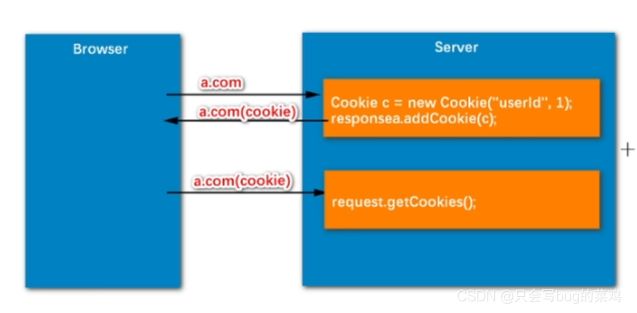
- cookie是手动创建的,session是tomcat自动创建的。
- session是依赖于cookie实现的,可以保存Object类型的数据。
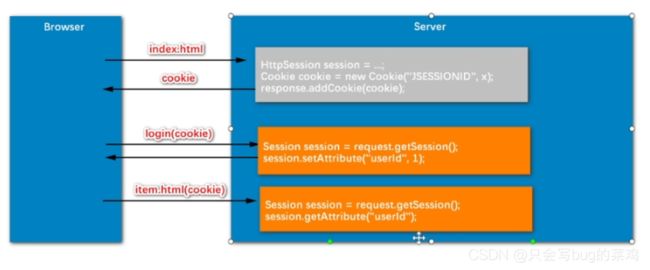
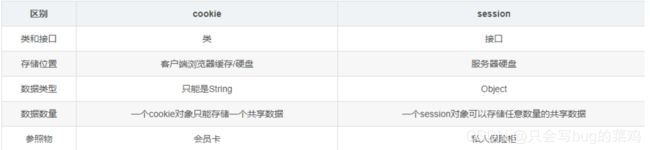
- 注意的是session是保存在服务器的tomcat内存中,不能保存在硬盘上,在硬盘保存效率太低了。因为每次请求都要访问。
- 但是session的缺点是服务器压力过大,保存太多的session。session默认30分钟后过期。
- 搞清楚状态管理和权限管理的区别,先记住用户状态,权限管理是依赖于状态,判断用户类型,决定角色的权限。
但是上面的情况只适用于单个服务器的情况,不适用于分布式。
分布式:使用redis存储session。
多个服务器就可以共享session。
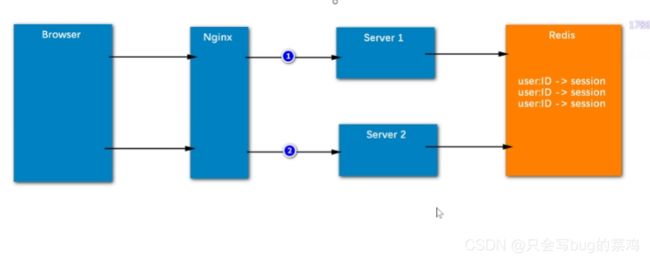
- 但是对于多客户端的情况下,使用session不能解决问题。使用tocken解决。用户请求后server1,就给他创建一个tocken返回给客户端,等到下次访问另一台服务器的时候就会携带这个tocken(通过request对象携带),server2就会去redis中查询有没有这个tocken。这个tocken可以设置永久保存。
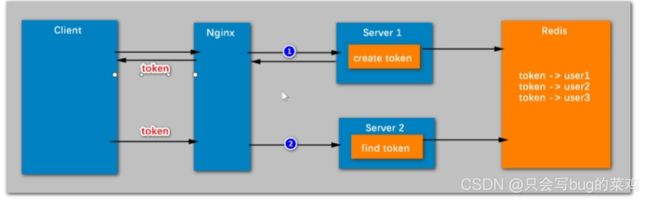
热点问题4:状态管理以及单点登录的实现机制【系统太大,拆分几个子系统,只需要登陆一次就可以访问所有子系统】
- 根域名相同的情况
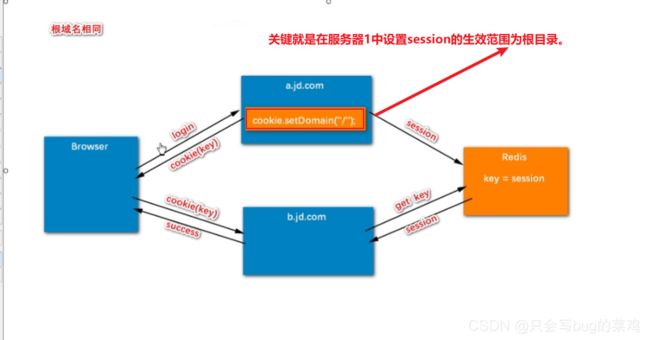
- 根域名不同的情况【基于一个中间服务器做全局验证,颁发一个全局的tocken。】
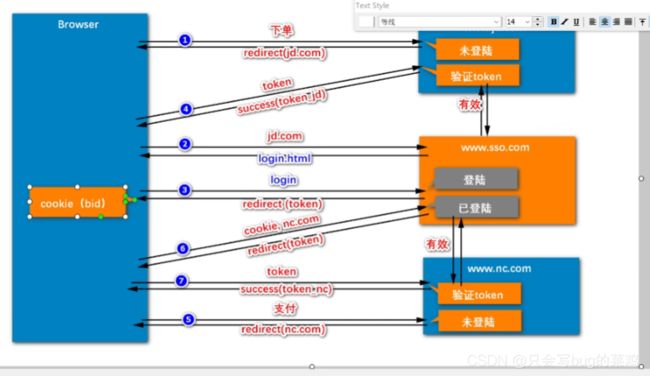
1、下单操作,jd发现他没登录,重定向让用户去sso登录,并且携带jd的路径。
2、去sso进行登录。给用户返回一个登录页面
3、用户提交登录信息,登录成功,sso给用户一个全局tocken,并且重定向回到jd下单页面。
4、用户携带tocken去访问jd,jd要验证tocken,去向sso验证tocken,得到结果有效。jd给用户发一个自己的tocken_jd。
5、用户去访问nc,重定向让用户去登录。
6、用户访问sso进行验证,发现用户已登录,重定向让它去访问nc(携带tocken返回)
7、用户携带tocken去访问nc,nc向sso验证,得到有效信息。返回一个局部的tocken_nc。全局tocken设置30分钟有效期(无操作30分钟后),有效期到之后销毁的同时通知其他子系统将tocken销毁。
商品列表与详情
商品表item
商品库存表item_stock
商品活动表promotion
除了自动生成的方法外,手动补充一些方法。
前端逻辑大致了解就行。
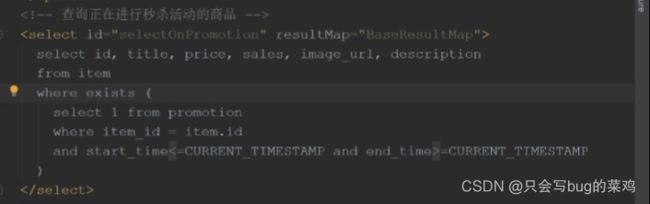
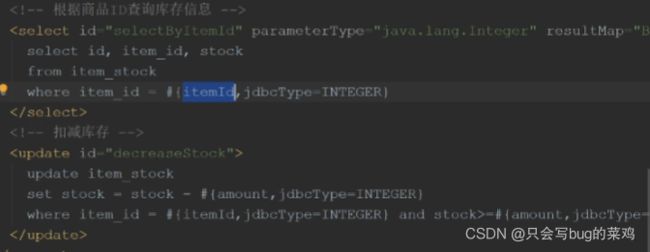
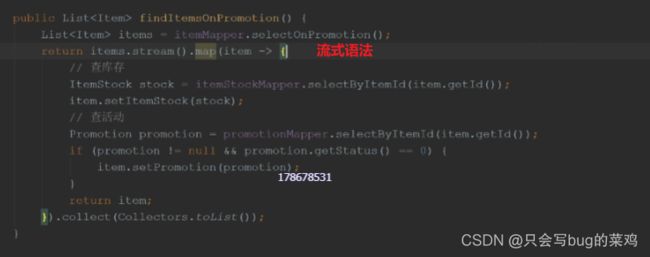

热点问题:索引
使用explain查看sql语句的执行效果,能看到是否使用了索引。type=ALL,表示全局扫描。rows表示预计扫描30条数据。
索引分类

普通索引、唯一索引、全文索引、空间索引
按照存储方式:B-tree、Hash
按照列数分类:单列索引、组合索引
按照数据分布:聚簇索引、二级索引(辅助索引,索引的索引)
按照回表情况:覆盖索引
最左前缀


秒杀相关的面试题
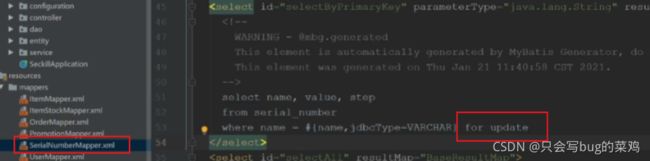
1、表结构设计
item:订单将来很庞大,肯定要把历时订单的数据拆分出去,所以设计表的时候,以年月日开头,后面加一个流水号,便于后面的表拆分
serial_number:专门为了记录订单生成的流水号,每次查流水号的时候,会给它for update,加一个行锁,避免两个用户的订单号重复。【查流水号是因为要创建新订单,更新流水号,所以要加锁。】
2、秒杀问了 redis 和数据库的同步怎么解决的
3、消息丢失 重试什么的
4、秒杀这一块你当时是怎么设计的,怎么想的。
5、redis缓存和库存数据的一致性问题怎么保证的。
6、消息没有消费怎么办。
7、消息丢失怎么办。 发到mq之前丢了,发送到mq没人消费。
8、死信队列怎么处理。
9、秒杀什么保证了竞争的并发安全。
10、什么命令是原子操作的。
11、你有对扣减到负数库存做校验吗。
12、异常如何管理的。
13、数据库有加锁的操作吗
14、怎么解决超卖问题?
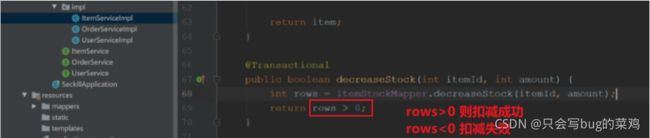
下单时要扣库存。所以要锁库存,锁库存表即可,不用锁商品表。
15、什么情况下会触发行锁。
慢查询分析
1、开启慢查询日志:set global slow_query_log = ''ON; 2、设置超时时间:set global
long_query_time = 1;
p5-p6简书排版
面试题:查询功能优化
启用了慢查询日志,看到,某一个sql执行时间大于0.1s,我认为比较慢,通过explain命令去查看后发现本次查询没有通过索引,但是我创建了索引,为什么没有走呢,可能是索引的条件不符合最左前缀原则,所以针对这个问题去解决,然后性能就提高了。编一个这样的故事。有理有据。
p5/p11 用户下单与秒杀【主要是事务处理】
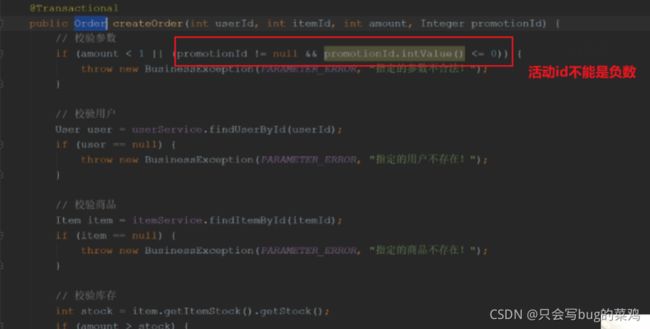
下单的时候要判断商品是否参与了活动,如果参与了活动就要修改商品价格。这两个操作要保证事务性。
少卖问题
下单时锁库存,不会产生超卖问题,但是有可能产生少卖问题,解决方法是超时自动释放订单,回补库存。
超卖问题
付款时锁库存,会产生超卖问题,即下单的人无法付款,库存不够。体验不好。
所以我们项目中采用的方式是下单时锁库存,比较好一点。
数据库表
查看订单表order_orderinfo

order_info
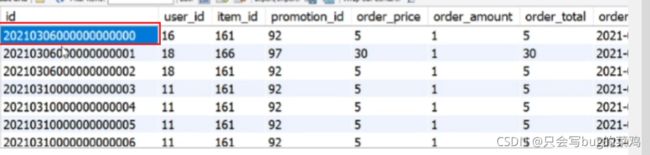
订单id自增,为了生成订单id设计的表。那当前id自增到了多少,这个数字需要另外去保存一下,不能保存内存,要持久性存储。serial_number表就是专门用来记录索引的最大序号。这个表同样可以存放其他表的最大值。
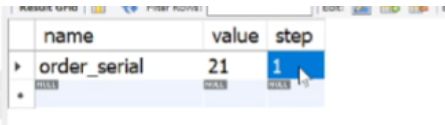
order_serial
数据访问层
ItemMapper
ItemStockMapper
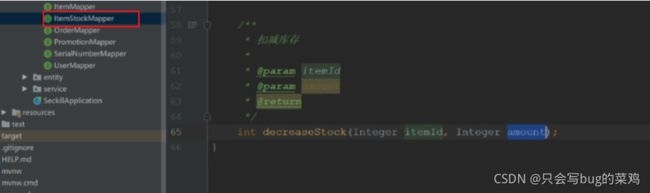

SerialNumberMapper
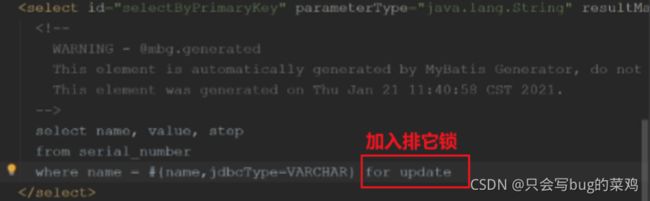
此时加入x锁的目的是为了不让读取历史版本的更新,而是强制使其读取最新的数据,而最新的数据有人正在改,那就互斥,等待其改完之后再读。p6:15:14
Service层
orderService

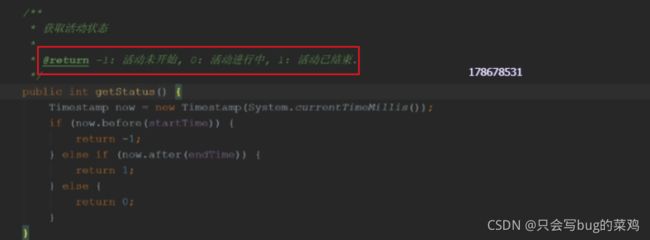
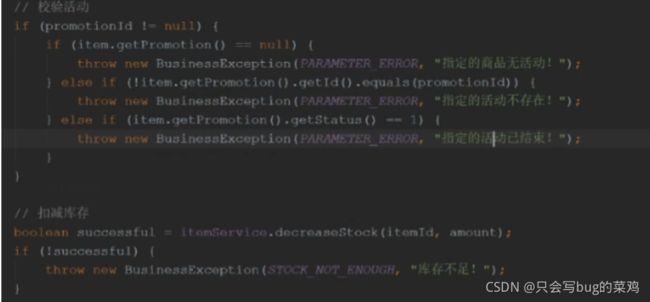
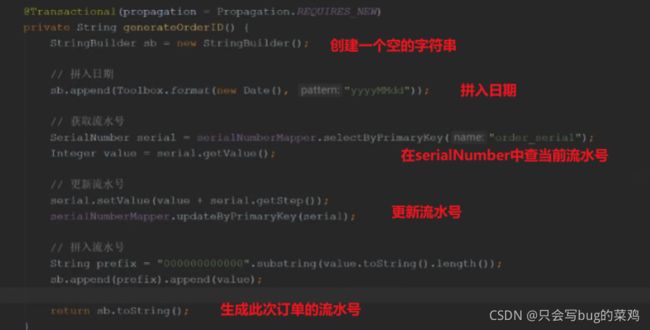
生成订单id的方法
Controller层
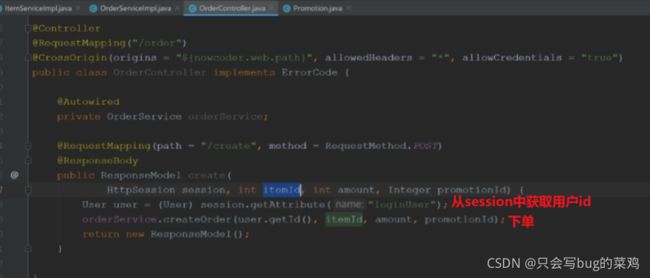
前端页面item.js
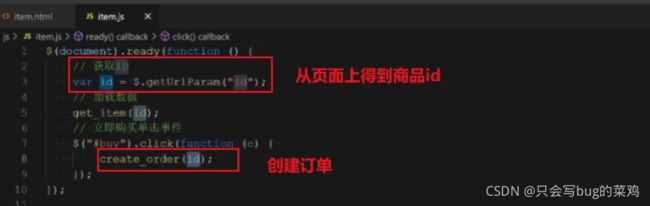
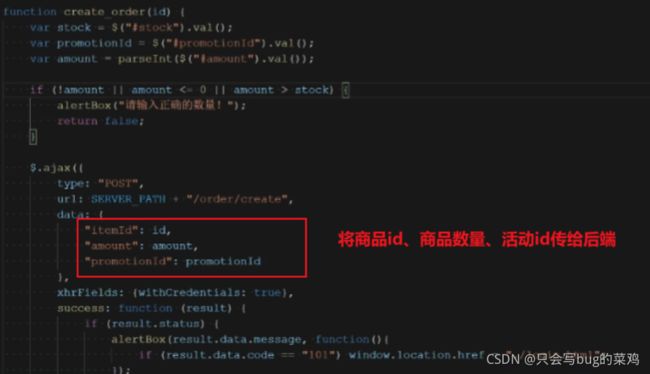
数据库事务(InnoDB)
事务的四大特性
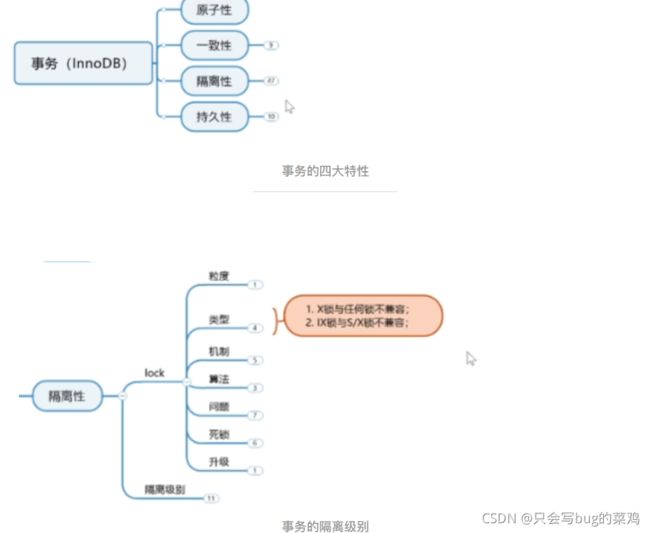
事务的隔离级别
锁的粒度
表锁:不是锁整个表,实际可能锁锁一页就可以。
行锁:锁的也不是一行,是锁这一行前后的数据。
锁的类型
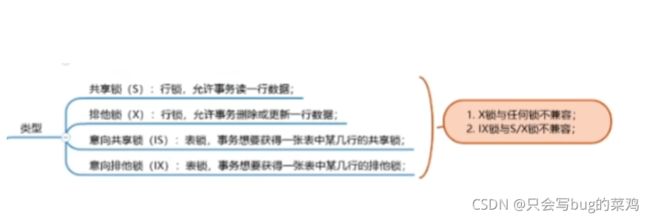
共享锁
排它锁
意向共享锁
意向排它锁
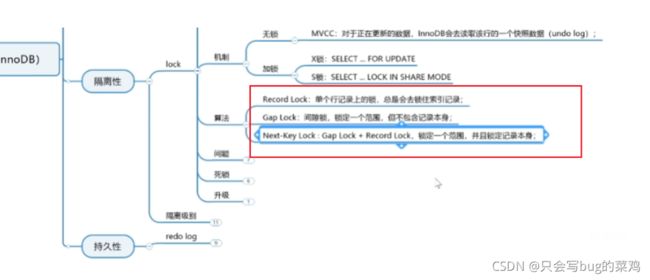
锁的机制

查询的时候同样可以加锁,并不是只有修改的时候可以加,如果想在查询的时候显示的加锁,就可以使用上面的两条语句;1是排它锁,2是共享锁。
select … for update
select … lock in share mode
锁的算法
锁的问题
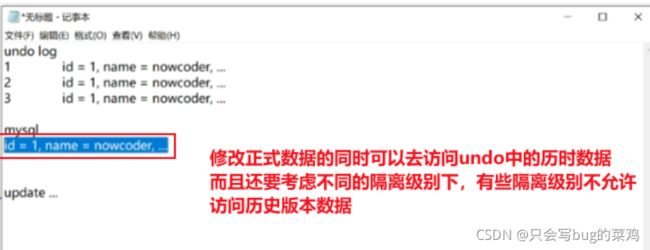


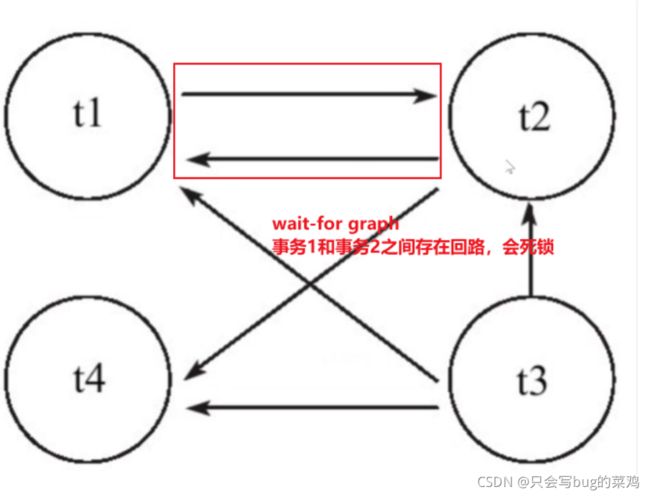
死锁

锁升级

隔离级别
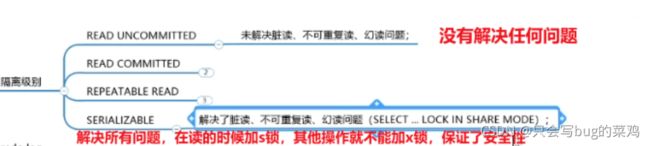
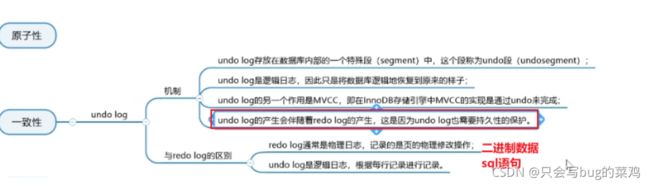
注意,一个事务读取到其他事务未提交的事务。而一个事务读取到undo log中的历时数据,不叫脏读。
Read Commited :record Lock解决了脏读问题,MVCC提高了并发性。
binlog和redo log 的区别:
bin log记录的是sql,redo log存储的是二进制数据。
bin log是事务提交时记录,redo log是每次操作都会记录
redo log是InnoDB独有的日志。

框架处理事务的方式
使用@Transactional注解,自动处理异常,自动begin、自动commit,实际底层是aop实现的。
事务的传播方式
在Spring中对于事务的传播行为定义了七种类型分别是:REQUIRED、SUPPORTS、MANDATORY、REQUIRES_NEW、NOT_SUPPORTED、NEVER、NESTED。
P6/P11项目部署与压测
主要压测商品详情页和下单功能
遇到问题:ping 114.116.228.176 请求超时 在安全组中配置,一键放通,ICMP:全部
步骤:
1、修改项目的配置
本地是dev环境,服务器是linux,是test环境,需要修改对应的配置文件,再进行上传
1、修改application-test.properties
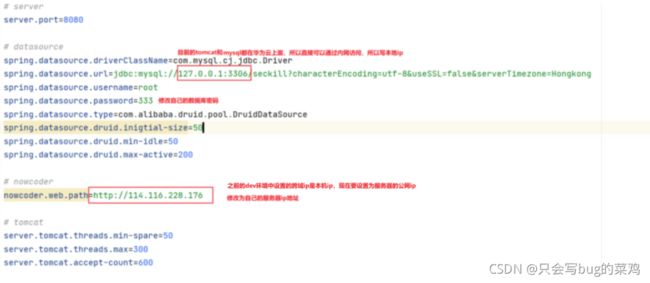
2、修改日志logback-spring-test.xml

2、项目打包
mvn clean package -Dmaven.test.skip=true
3、将项目jar包上传到服务器。在到target目录
scp seckill-0.0.1-SNAPSHOT.jar [email protected]:/root
4、在服务器安装jdk
yum list java* yun install -y java-1.8.0-openjdk.aarch64
5、测试java安装是否成
java version
6、将脚本上传到服务器中。
scp startup.sh [email protected]:/root
7、开启权限
chmod -R 777 startup.sh
8、启动tomcat服务器
sh startup.sh
9、查看启动信息
tail nohup.out
10、安装Nigix
yum list nginx* yum install -y nginx.aarch64
11、将前端页面传到服务器上的指定位置,在指定文件夹下打开cmd窗口
scp seckill-site.zip [email protected]:/usr/share/nginx/html
12、解压缩文件
unzip seckill-site.zip
13、修改/usr/share/nginx/html/seckill-site/js下的common.js文件
vim common.js
修改为114.116.228.176:90端口
14、配置nginx,使其80端口代理前端服务器,90端口代理后端端口。
进入目录:/etc/nginx 配置:vim nginx.conf
15、重启nginx服务器
nginx -s reload
配置nginx时遇到若干问题
1、 nginx: [error] invalid PID number “” in “/run/nginx.pid”
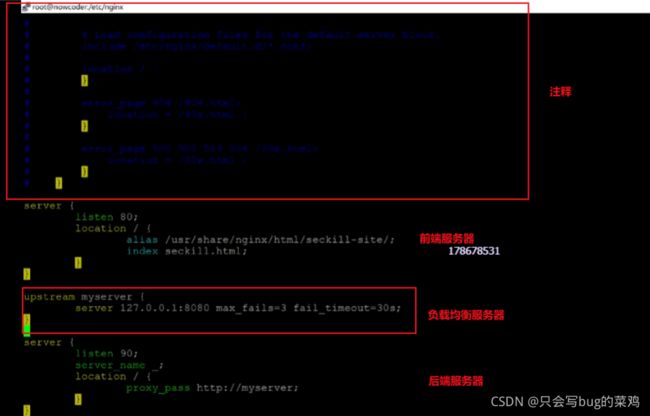
16、访问114.116.228.176
安装jmeter,配置jmeter.properties中的编码方式为UTF-8,配置jmeter到环境变量中。配置jmeter,进行商品详情页压力测试。
商品详情页压力测试:
结果如下:结果不好
下单操作压力测试:1:21
imeter进行压力测试,通过post请求访问下单操作,携带参数itemId,amount,promotionId,还要携带用户身份,携带cookie模拟实现。
1000个线程模拟1000次下单测试,带来的压力和1000个用户各下单一次是差不多的。
热点问题1:32【分布式部署,核心还是mysql】
Nginx一般做热备
tomcat服务器做分布式
mysql一般不做分布式(很麻烦),但是做读写分离。
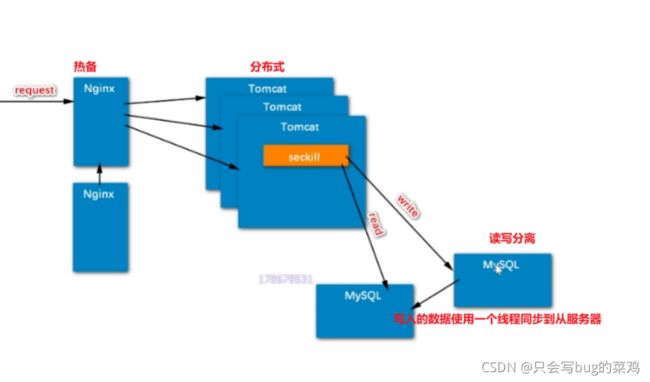
将来可以优化的地方:负载均衡、分布式服务器、读写分离、本地缓存、redis二级缓存(Redis集群)、消息队列
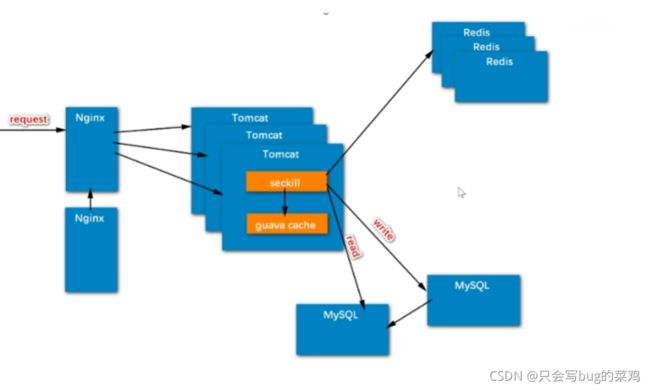
消息队列
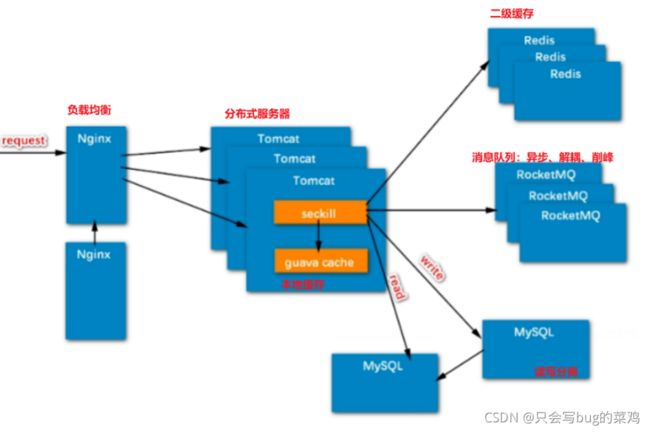
总结一下:

热点问题:读写分离
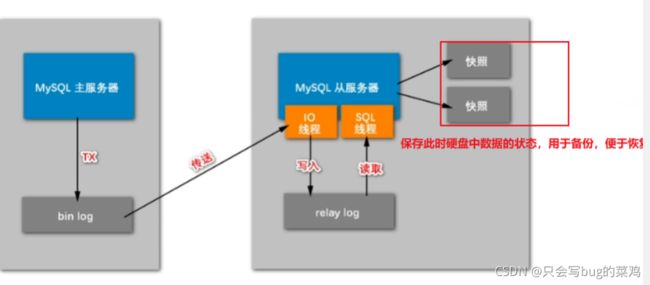
热点问题:分布式事务【跨行转账,数据库不一样】2:00
如果不可避免的要是用分布式事务,就按照如下操作:
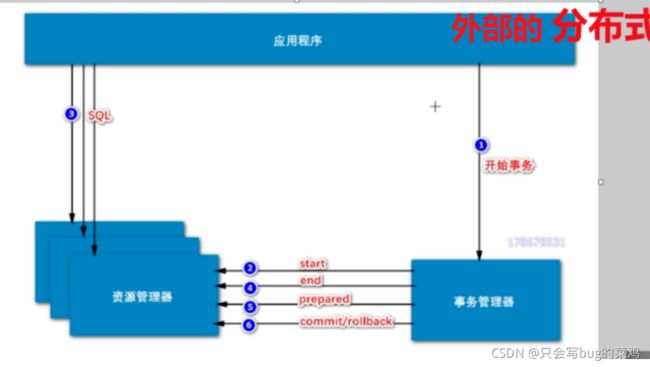
数据库内部的分布式事务【解决bin log和redo log 的同步问题】
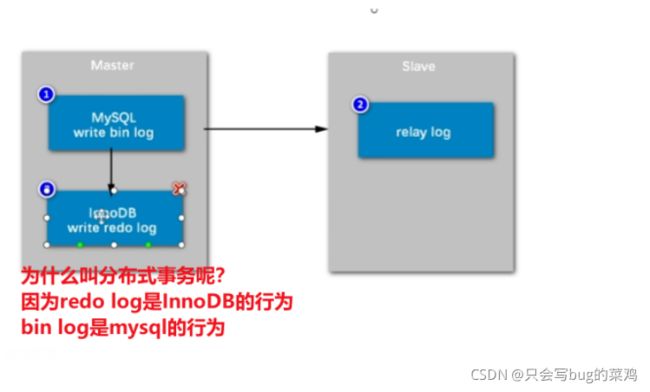
怎么解决呢?
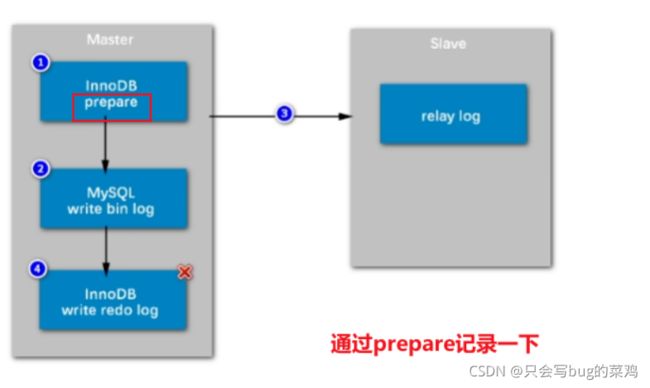
8P/11P 分布式状态管理【Redis】
- 把项目改造成一个可以分布式部署的项目,关键就是分布式状态管理,即把原来保存登录信息的session通过在tocken保存在reids中
在服务器中安装Redis
yum list redis*
yum install -y redis.aarch64
- 配置reids
vim /etc/redis.conf
打开行号 :set nu
69行:注释,就可以通过内网和外网去访问
136行:daemonize yes 后台运行
507 :解除注释,设置密码:333
保存退出
- 启动redis
redis-server /etc/redis.conf
- 进入reids的命令行客户端
redis-cli -a 密码
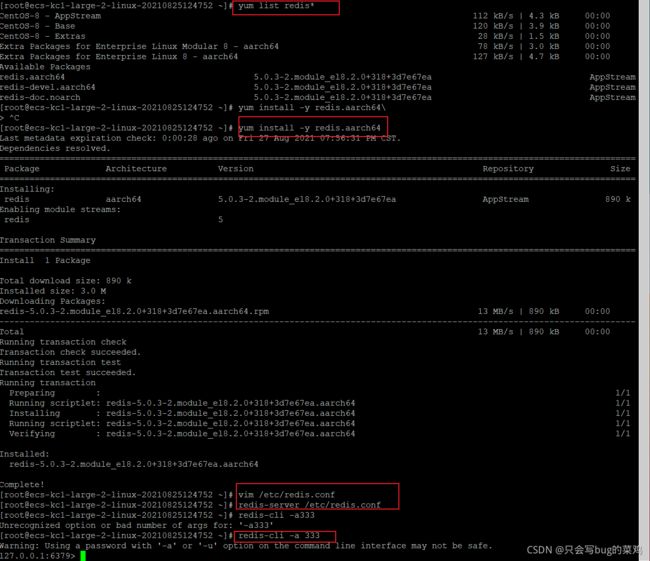
- redis的5种数据类型
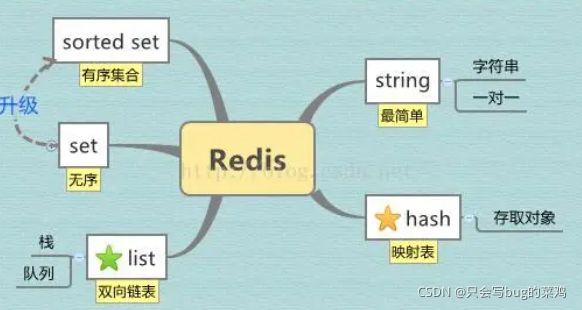
秒杀项目v2版本导入idea,引入redis
- 链接数据库
- 修改配置文件
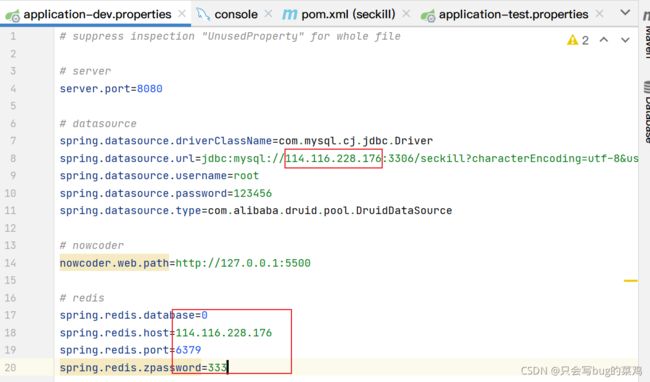
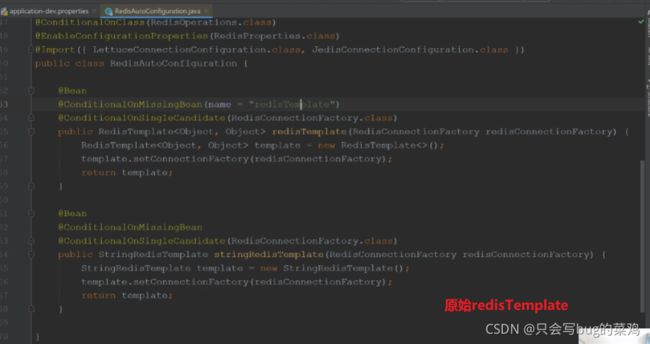
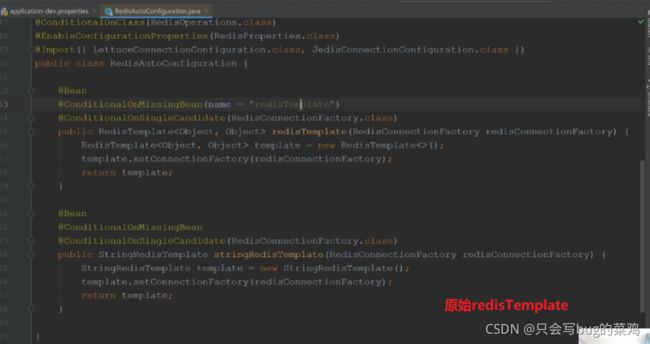
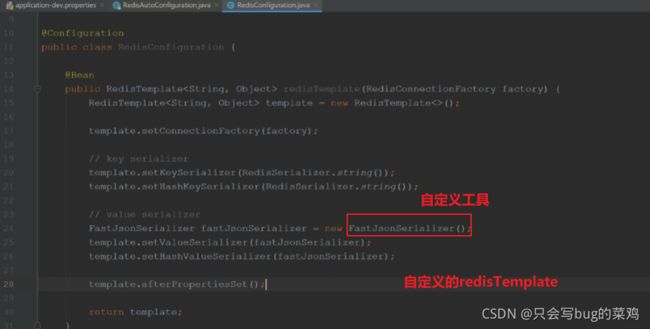
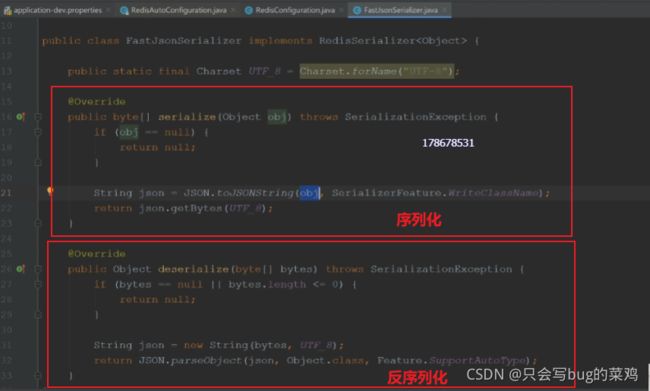
- 自定义redis的配置类redisTemplate
我们去自定义一个RedisTemplate(在Redis源码中,当我们自定义一个RedisTemplate,就不会去调用SpringBoot默认的RedisTemplate了),主要 是提供序列化的方式
- 测试代码,测试redis。报错如下:
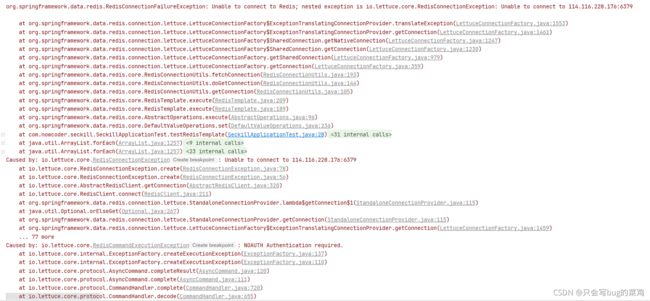
- 关闭防火墙
systemctl stop firewalld.service
- 重新测试,报错如下:
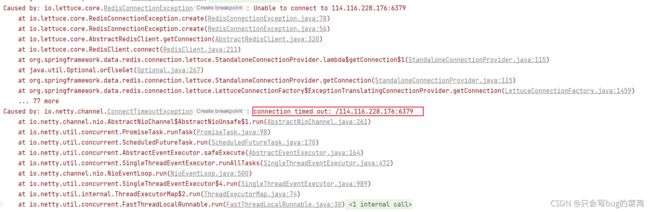
- 找到问题了,配置文件中不知道啥时候失误打错了密码
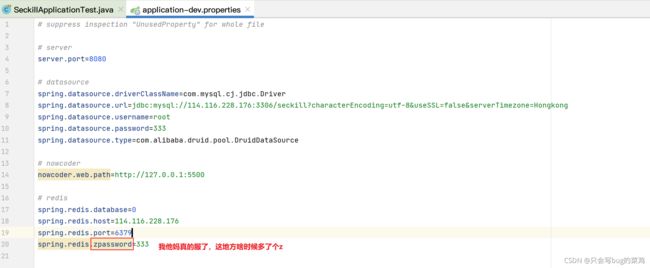
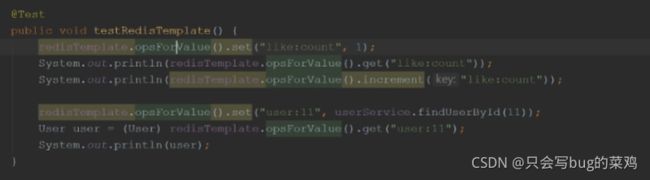
- 修改后,测试成功。

集中管理用户的登录凭证
- session只有在controller层出现,在userController中处理session
- 在所有文件中搜session
ctrl+shift+f
- 在userController中
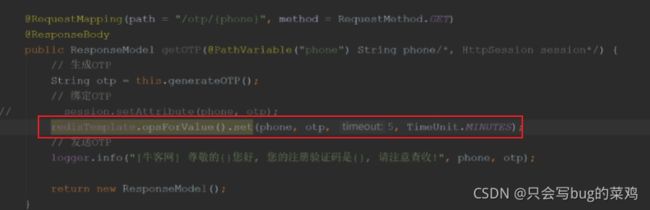
- 验证码保存在redis中
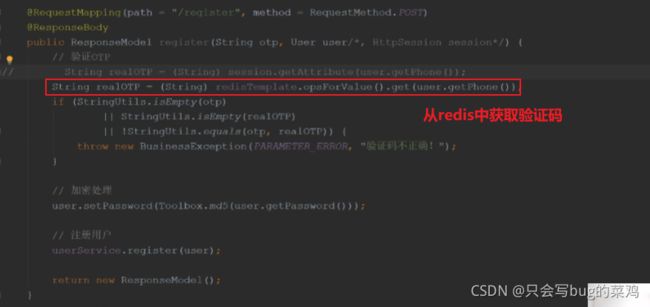
- 注册时,从redis中获取真实的验证码
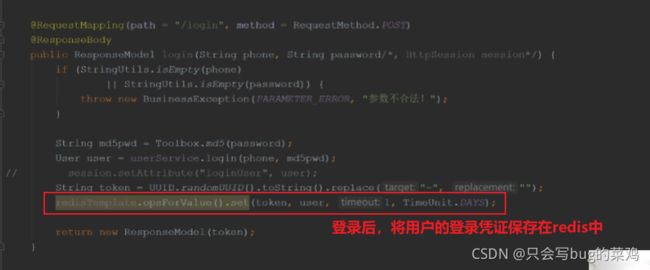
- 登录后将用户的登录凭证保存在reids中
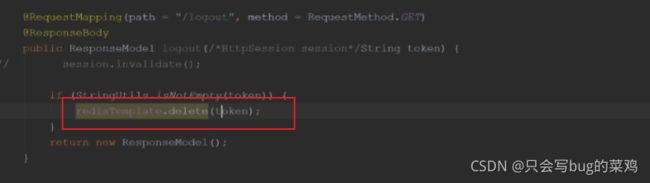
- 在登出的时候删除tocken。
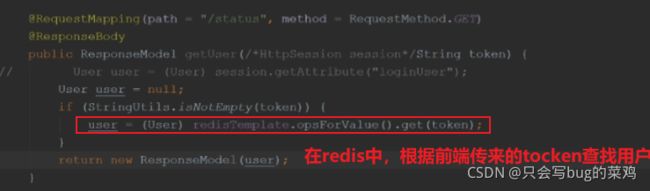
- 根据前端传来的tocken在redis中查user。
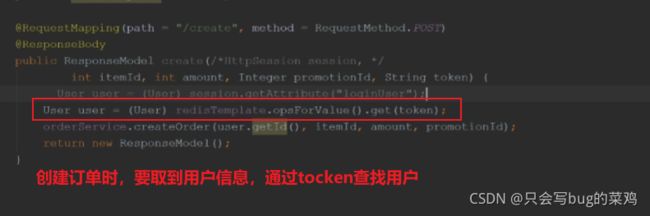
- 在orderController
- 创建订单时,要查找用户,通过tocken在redis中查找用户
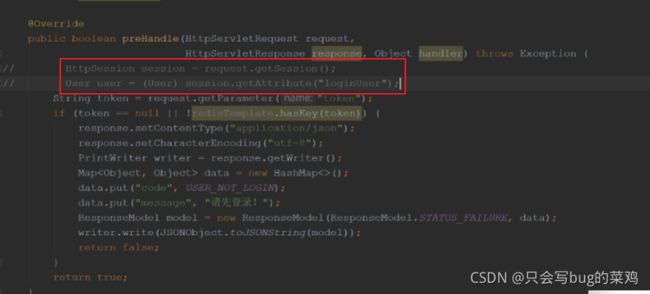
- interceptor。拦截器要在制定的请求之前做拦截,判断用户是否登录。之前是采用session保存用户信息。如果能从session中取到loginUser,那就是已登录,反之则没有登陆。那么凭什么能保证在session中取到loginUser呢?是因为每次请求客户端都会通过cookie携带“”JSESSIONID "075E3C51E51280EFF2AA32DA90431092"匹配自己的session。因为在后端代码userController中用户登录后将user保存在了seesion中。所以才能查询到。中如果能匹配到,并且其中有loginUser,那就说明用户已经登陆。
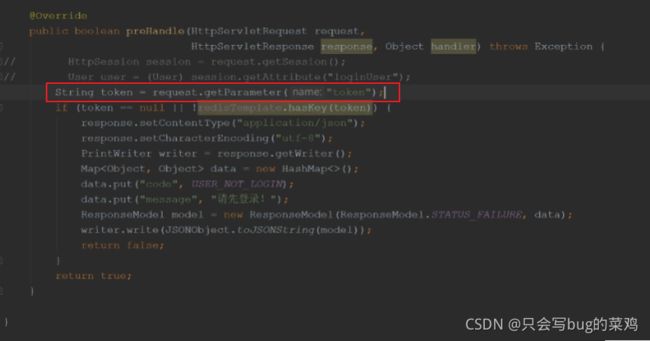
- 现在要改变思路,使用redis,通过tocken保存.在拦截器的prehandle方法中,获取tocken,但是prehandle的参数是固定的,所以就可以通过request对象去获取tocken。
request是请求对象,请求中的所有数据都会在request中。请求行,消息头,实体等等都可以通过request获得。
- 现在有一个疑问,在登录时也没有往request中保存tocken,那么拦截器的prehandle中为什么可以使用方法request.getParameter(“tocken”)取到tocken呢???
是不是在每次请求的时候通过cookie携带了tocken?如果用session的话,session会给客户端返回一个cookie,cookie里面保存了sessionID,浏览器会将cookie自动地保存在浏览器的内存或者硬盘中。【session自动处理】
而tocken是一个类似的东西,它存到哪了呢?【在前端js代码中手动处理】
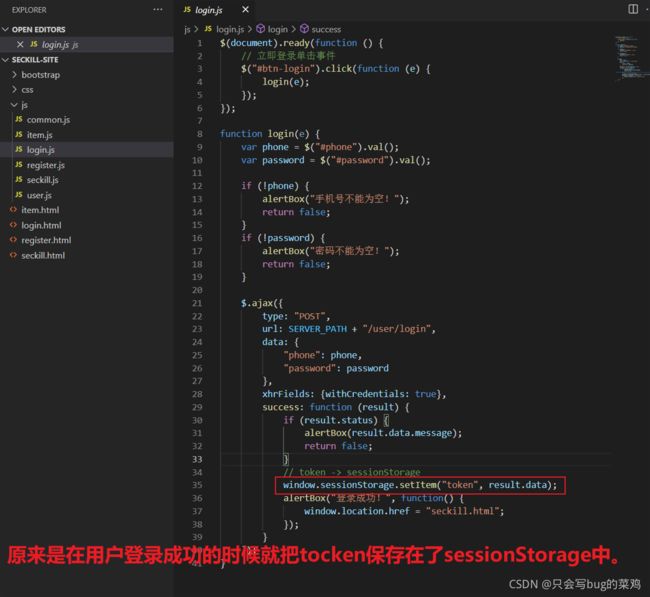
前端代码,同样也是v2版本,不是v1版本。
- 以下是一些修改过的地方
- user.js中
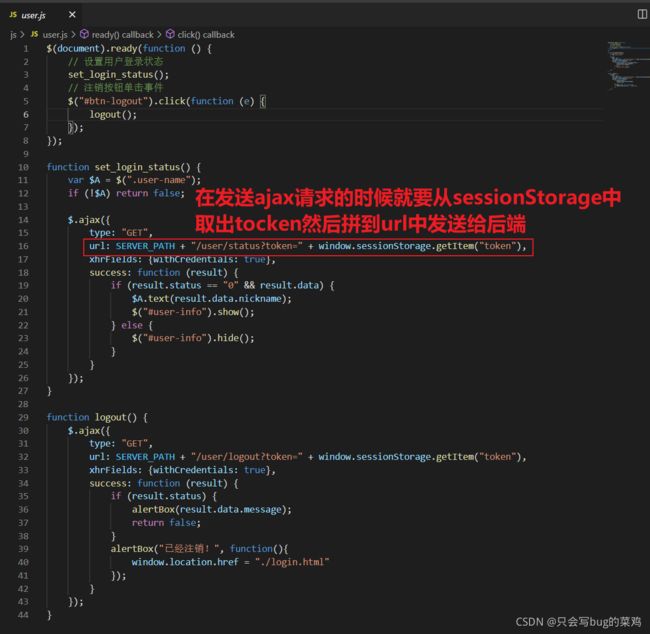
- item.js中,同样也需要在url上面拼接tocken给后端。

- 但是每次ajax请求都拼接很麻烦,所以可以使用jquery的监听器,监听请求事件,做一个拦截。在发送请求的时候给他拼一个tocken就行。了解即可。
这个tocken保存在本地的浏览器的sessionStorage中,比较安全,其他人得不到。

热点问题:Redis的数据类型

热点问题:Redis的编码和底层实现
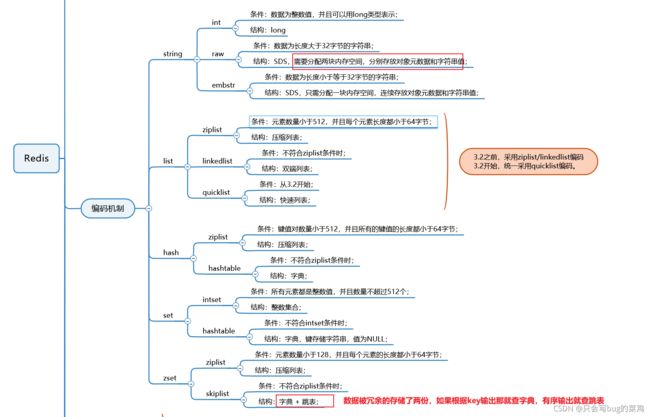
因为Redis是基于内存实现的,空间有限,很宝贵。需要合理的编码设计。
- 重点关注String、ziplist、跳表。Hashtable
- Redis的事务机制

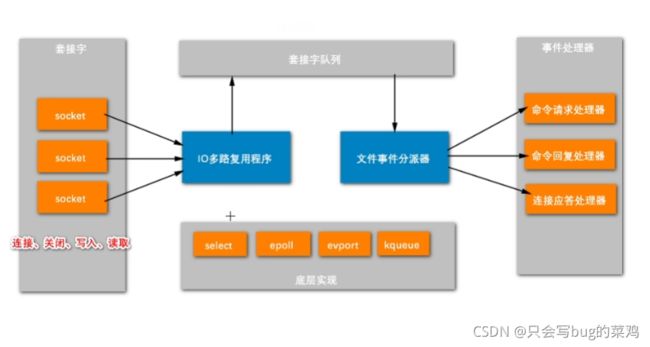
- Redis的线程模型,Redis是单线程,避免线程切换,提高性能。但是内部其他功能也是多线程的。
- Redis单线程怎么实现1s钟10万的并发呢?通过IO多路复用。

-
Redis的线程模型

-
IO多路复用2:00
分布式:服务器扛不住。分布式是一定要用的。
微服务:不是必需品。项目规模太大了,业务功能要拆解。一个简单的微服务系统有几十个子系统,拆解也会带来复杂的问题,开发难度大,不到迫不得已不会用微服务。微服务一定是基于分布式。微服务主要就是两种体系,dubbo和Spring cloud -
Redis的持久化方式
Redis支持RDB和AOF两种持久化机制,持久化功能有效地避免因进程退出造成的数据丢失问题,当下次重启时利用之前持久化的文件即可实现数 据恢复。理解掌握持久化机制对于Redis运维非常重要
RDB持久化是把当前进程数据生成快照保存到硬盘的过程,触发RDB持久化过程分为手动触发和自动触发
AOF(append only file)持久化:以独立日志的方式记录每次写命令, 重启时再重新执行AOF文件中的命令达到恢复数据的目的。AOF的主要作用 是解决了数据持久化的实时性,目前已经是Redis持久化的主流方式
P9/P11 缓存商品与用户
- 缓存离客户端越接近,性能就越好,mysql和mybatis级别的缓存离客户端很远了,性能不是很好。
- 二级缓存,服务器本地缓存guava,Redis分布式缓存。因为服务器中tomcat和guava在一起,所以说分配给guava的内存很小,只有很热的数据才会缓存在ghuava中,次热的数据缓存在redis中。两者相互配合,相互备份。通常会做两级缓存
本地缓存实现
- guava
- caffeine
导入依赖
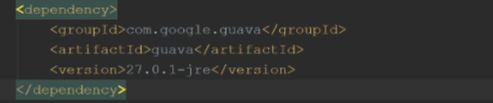
- 测试guava
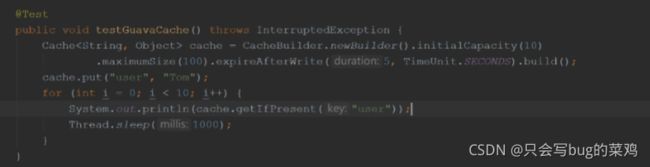
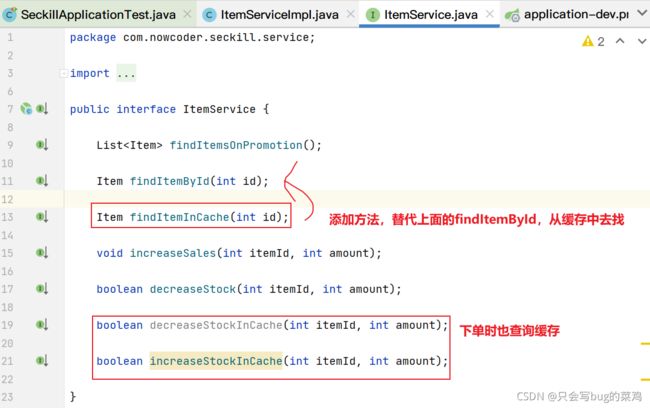
- 将guava引入项目中
- item.service中


- 在userService中,用户登录信息缓存一下。因为用户每次刷新页面时都要请求用户的登录状态,很频繁。使用redis缓存即可。不使用2级缓存。
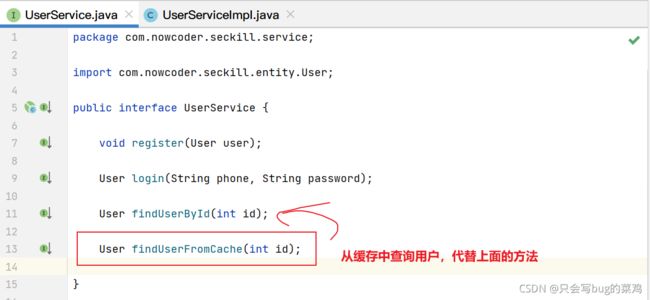
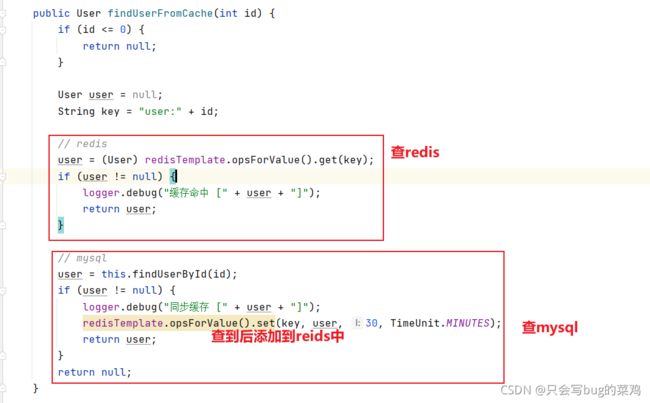
- 注意一些场景,有些使用2级缓存,有些只使用redis缓存
- 启动服务测试。
继续回顾Redis
-
Redis的持久化机制

-
RDB持久化流程
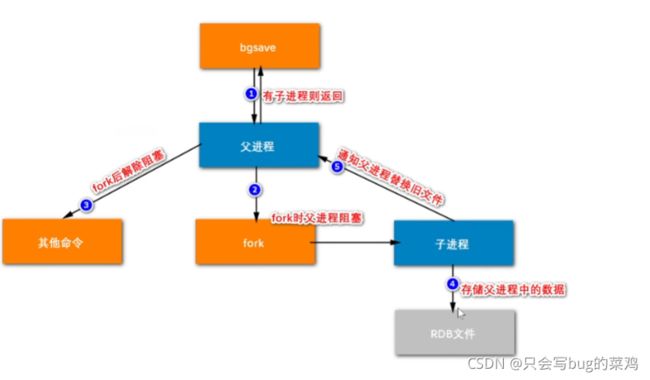
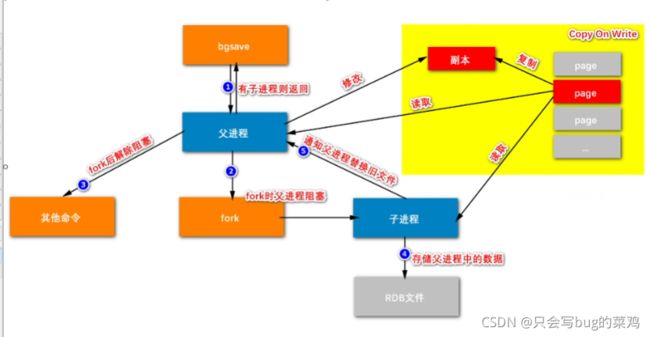
-
AOF持久化流程1:20
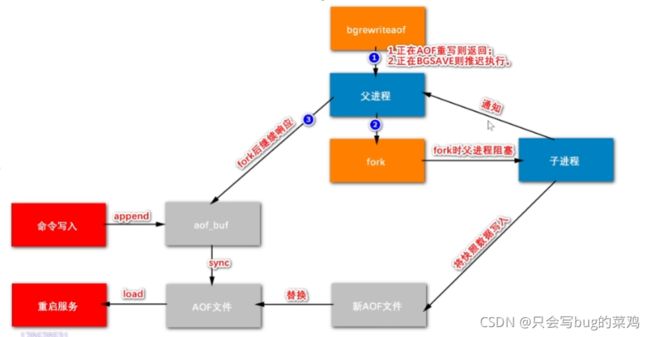
-
重写过程中,保证新的命令不丢失的机制,引入rewrite buf【听懂了,下次再听一下】
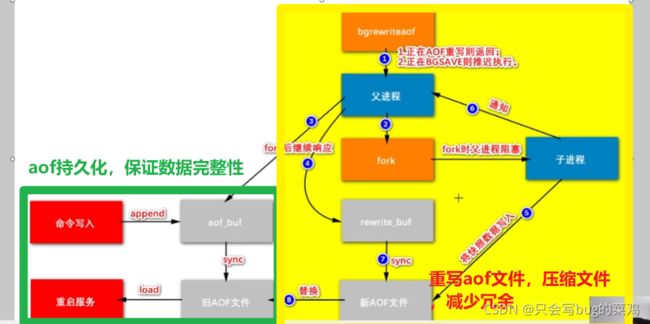
-
AOF的重写机制
不需要将下面的所有命令都记录下来,因为最终把name删除了,上面的命令没有用。所以冗余了。所以aof文件会进行重写,删除冗余的命令。重新生成一个压缩版的aof文件。
- RDB-AOF混合持久化
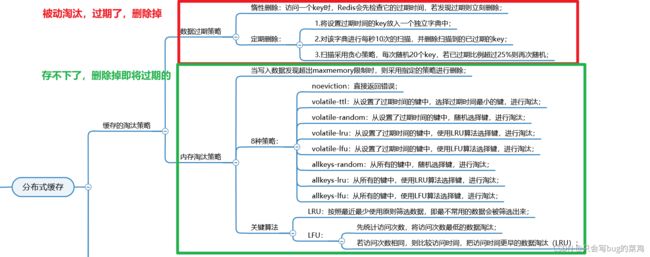
分布式缓存
-
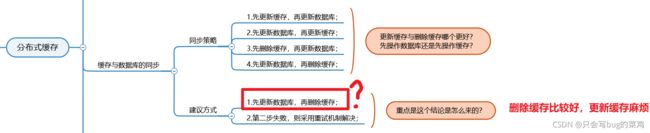
缓存与数据库的同步1:50
-
假设请求2都失败的情况下,先删除缓存和先更新数据库的区别。
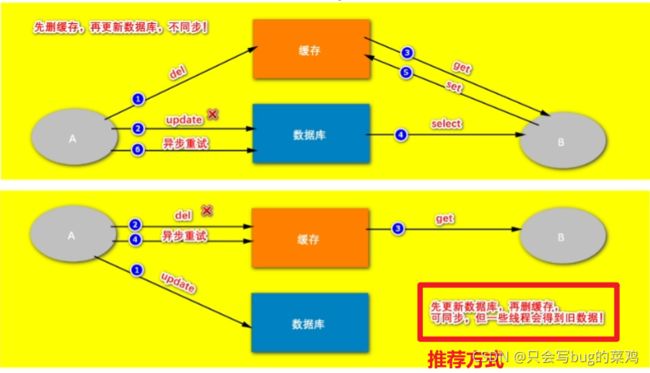
-
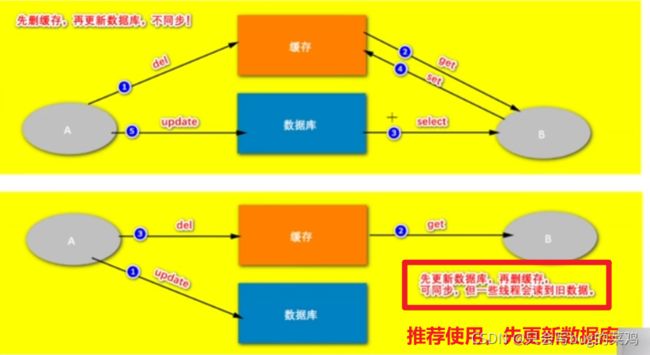
假设请求都成功,先删除缓存和先更新数据库的区别
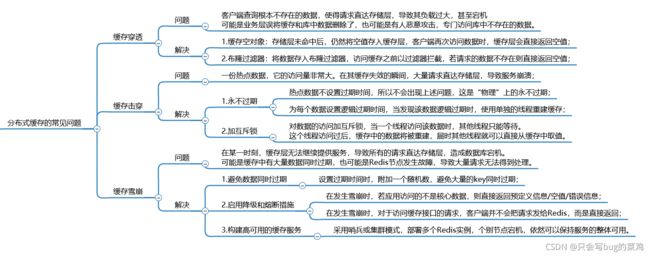
分布式缓存的常见问题
- 缓存穿透:查询不存在的数据
解决方法:
1、缓存空对象
2、布隆过滤器
- 缓存击穿:热点数据缓存过期导致大量请求直达数据库
解决方法:
1、热点数据永不过期
2、加互斥锁
- 缓存雪崩:缓存中的很多数据同时过期了
解决方法
1、避免同时过期
2、降级和熔断
3、集群模式,实现高可用。
缓存的思想,下单操作可以实时执行,但是扣减库存和销量递增可以通过缓存,异步处理。提高性能。
P10/P11 异步化扣减库存【重要、难度大】
RocketMQ入门


基本概念

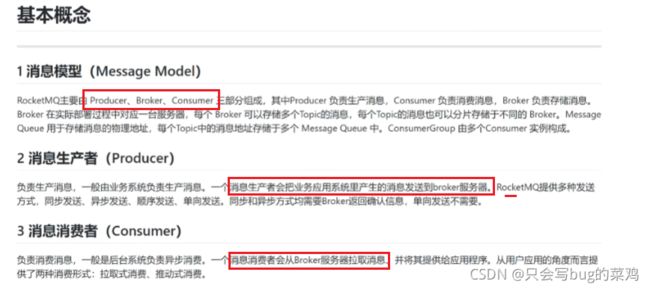

部署架构
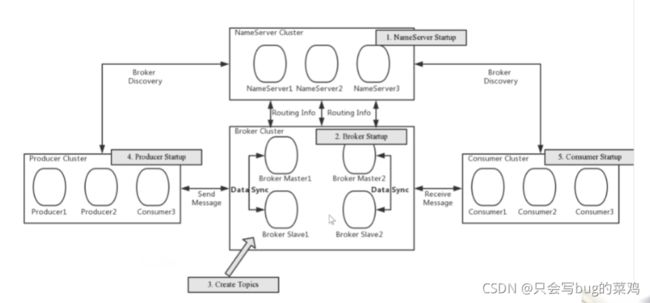

刷盘机制
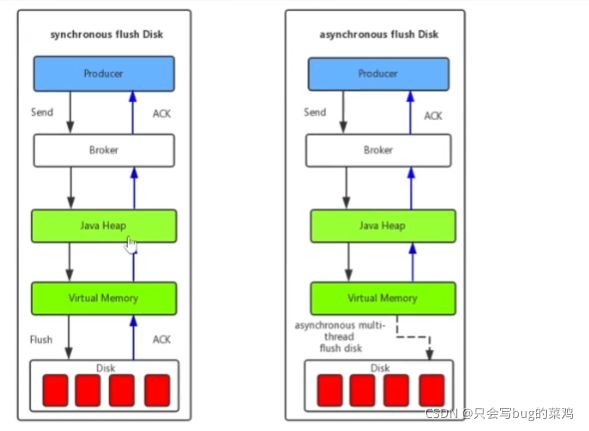

事务消息,项目中用到了,必须要理解
安装RocketMQ以及学习
下载 解压 权限设置 修改配置文件【启动程序的内存大小】修改配置文件【conf】启动rocketMQ
# 开放端口
9876, 10909, 10911
# 安装
wget https://mirror-hk.koddos.net/apache/rocketmq/4.8.0/rocketmq-all-4.8.0-bin-release.zip
unzip rocketmq-all-4.8.0-bin-release.zip
chmod -R 777 rocketmq-all-4.8.0-bin-release
# 配置
cd /root/rocketmq-all-4.8.0-bin-release
# ./bin/runserver.sh (82)
-server Xms256m Xmx256m Xmn128m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m
# ./bin/runbroker.sh (67)
-server Xms256m Xmx256m Xmn128m
# ./conf/broker.conf (追加)
brokerIP1 = 139.9.119.64
autoCreateTopicEnable = true
# 启动
# namesrv
nohup sh ./bin/mqnamesrv -n localhost:9876 &
tail -f /root/logs/rocketmqlogs/namesrv.log
# broker
nohup sh ./bin/mqbroker -n localhost:9876 autoCreateTopicEnable=true -c ./conf/broker.conf &
tail -f /root/logs/rocketmqlogs/broker.log
# 测试
export NAMESRV_ADDR=localhost:9876
sh bin/tools.sh org.apache.rocketmq.example.quickstart.Producer
sh bin/tools.sh org.apache.rocketmq.example.quickstart.Consumer
# 关闭
sh ./bin/mqshutdown broker
sh ./bin/mqshutdown namesrv
- 测试成功,继续
在idea项目中,导入V3版本项目。
- 导入rocketMQ依赖
- 配置rocketmq

- 延时消息样例:下单后,15分钟去检查是否付款,没有付款就取消订单
在idea中进行测试
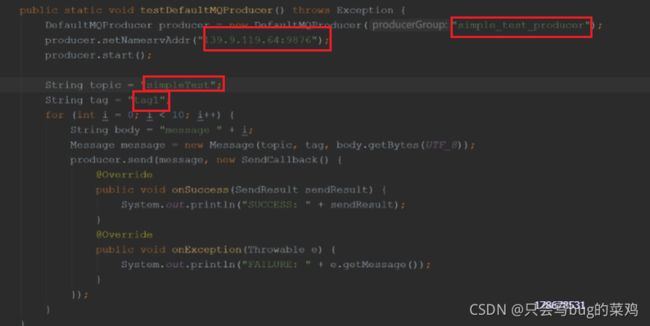
生产者
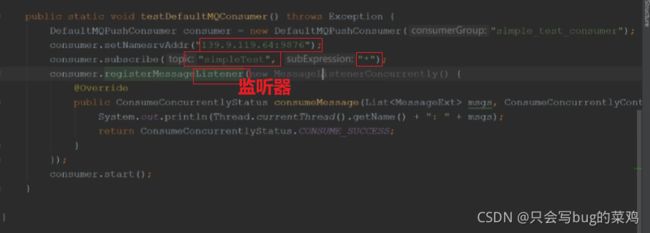
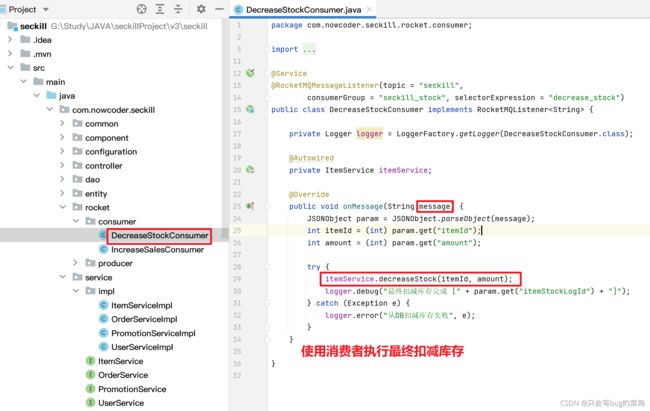
- 消费者
查看rocketMQAutoConfiguration源代码1:30
- rocketMQ的事务性
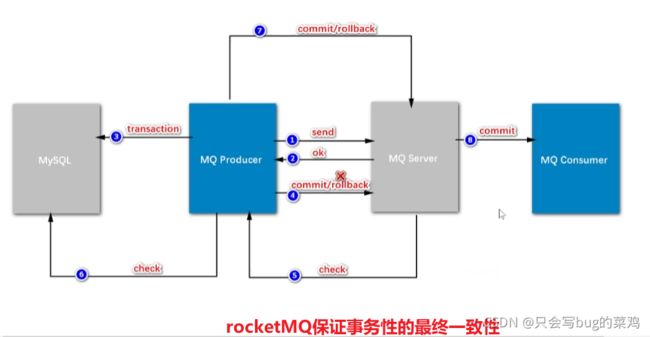
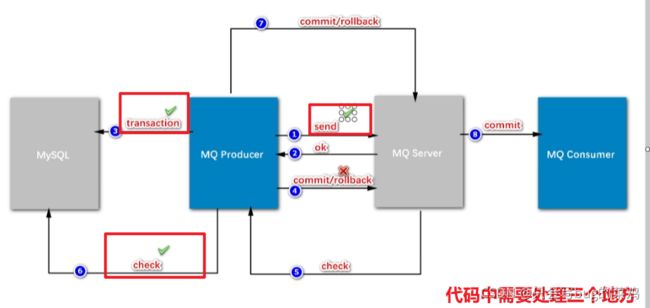
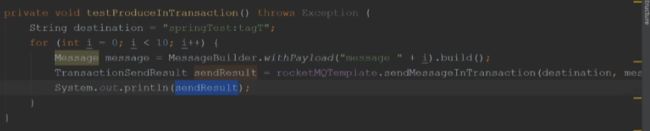
- send方法体现的代码
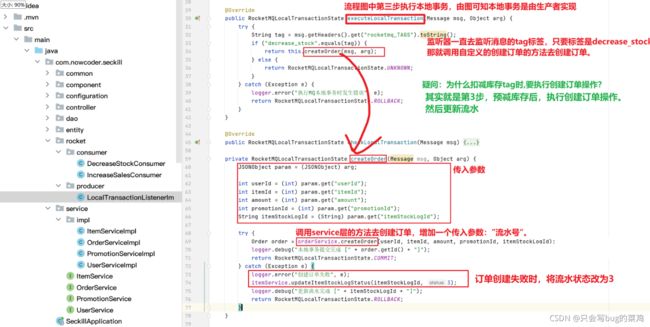
- 执行本地事务
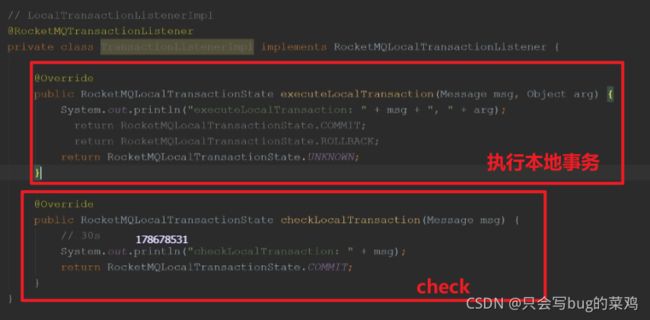
- 第6步检查check需要检查什么呢?需要建一个订单流水号,用来检查。
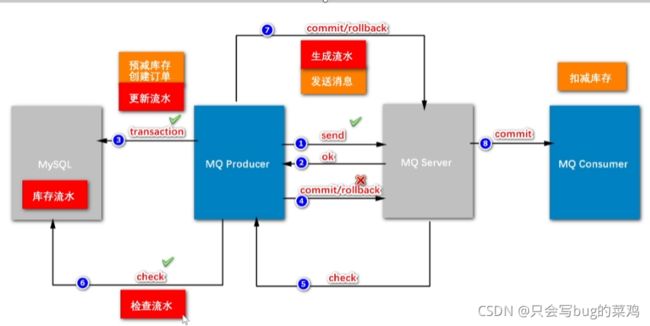
- 逻辑整理
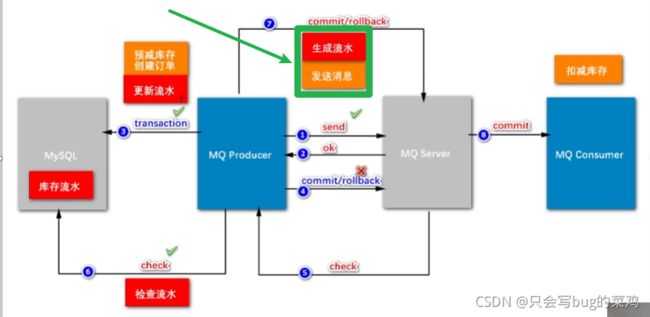
- 什么叫两阶段提交呢?
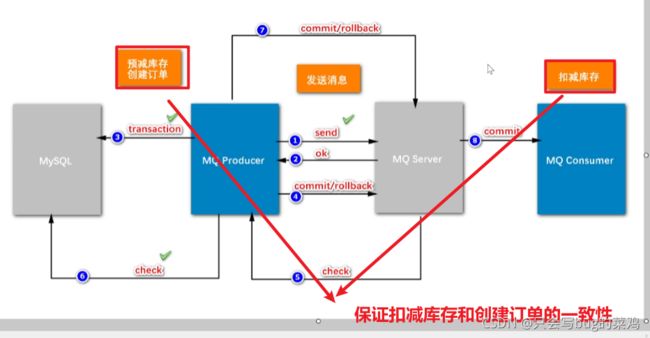
- 两阶段提交的模式下,把扣减粗存和创建订单异步处理。为什么要把扣减库存单独拿出来?
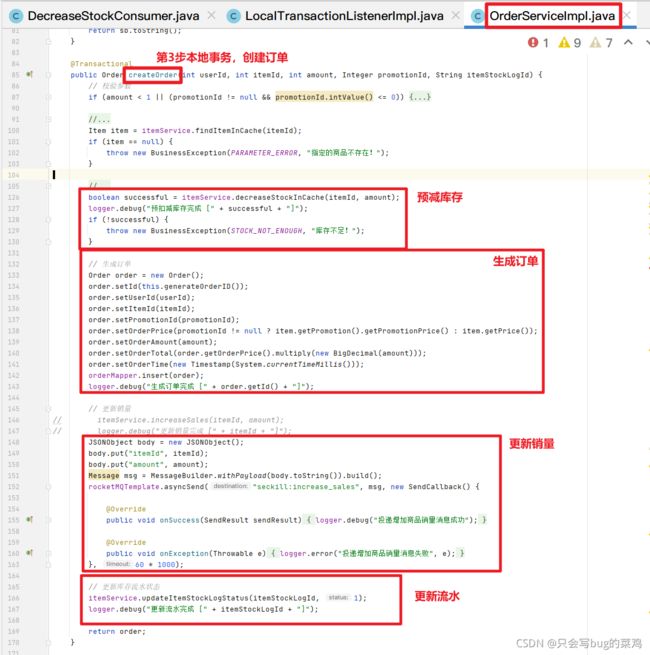
一个商品比如说库存有100,所有人都去秒杀这个商品,并发改这个数据,库存和商品是一一对应的,一个商品对应一个库存。所以我们100万人去秒杀同一个商品,我们是改同一份数据,这个并发量很大。但是创建订单不一样,100万人创建订单是插入新数据,互相之间没有影响,而且最终只有100人能够成功创建订单,而修改库存不一样,如果我们去加锁的话,影响就太大了。所以说要把扣减库存这个功能拆出来,延迟处理,只要保证最终扣减库存即可。但是有一个新问题,如果我们始终不去扣减库存的话,那么库存始终为100,那所有人都能秒杀到。这个业务就出错了。所以前面加入了一个预减库存的功能。在缓存中去扣减库存(这样就能提高性能),当缓存中的库存扣光了,那就不能继续创建订单了。最终在mysql中的库存可以延时扣减,延时几秒都能接受。
- 本地事务的作用:创建订单
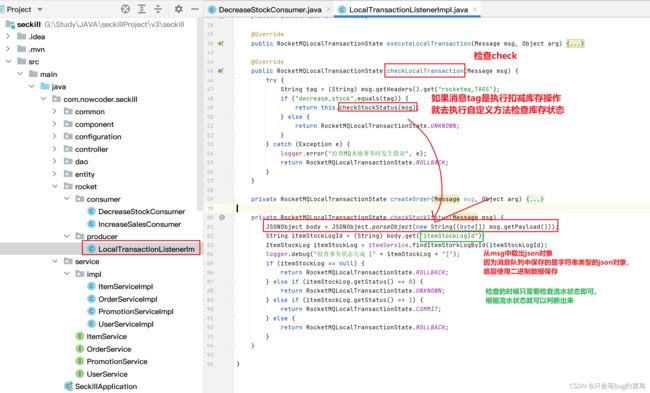
- 检查,检查什么呢?
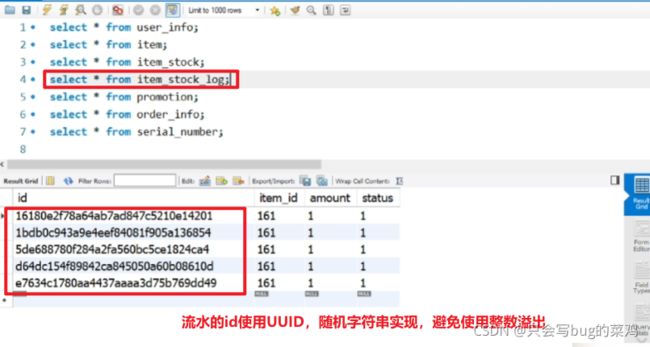
- 为什么要引入流水?
如果我们在二阶段回查check的时候,要检查“创建订单”这个事务有没有成功,如果没有流水,直接去查订单,此时有两种情况,假设订单创建成功,那没有问题,ok,提交commit。但是如果此时由于数据库阻塞,导致30s后回查的时候订单还没创建出来,可能会在40s的时候创建出来。延迟了不见得一定是失败了。所以回查的时候检查订单不靠谱。业内的解决方案一般是引入流水。
先生成流水,再发送消息。如果流水都没有生成的话,消息根本不会发出。流水生成之后,发送消息,发送消息之后,就执行本地事务,
本地事务创建订单之后,就开始更新流水。那这个流水的状态就是ok的;即使第1步发送消息失败,第4步回滚,回查check的时候检查流水,如果流水状态是ok的,那就说明订单创建成功,那就第7步commit。
- 引入流水也是数据库操作,这样不会导致性能下降吗?
扣减库存是100万人同时修改1个数据,但是库存流水不是,每个人创建订单的时候都是去新建一个库存流水,顺序创建,速度很快,不影响。一般来说对硬盘的顺序读写速度可以和对内存的随机写入速度持平。
- 预减库存
就是提前把Mysql里的库存挪到redis中,这叫缓存预热。目的就是记录库存的变化,当库存扣减到0后,就不能继续下单了。
- 扣减库存和更新销量的区别?
更新销量可以异步处理,可以延迟处理。销量晚一点更新,对于购买不会构成影响,但是库存数量影响下单。所以更新销量只需要简单的做一个异步处理就可以,但是扣减库存要保证事务性。
P10/P11 削峰限流与防刷1:23:00
查看更新销量的代码,理解思想。再去看扣减库存的代码。
- 在orderService中。
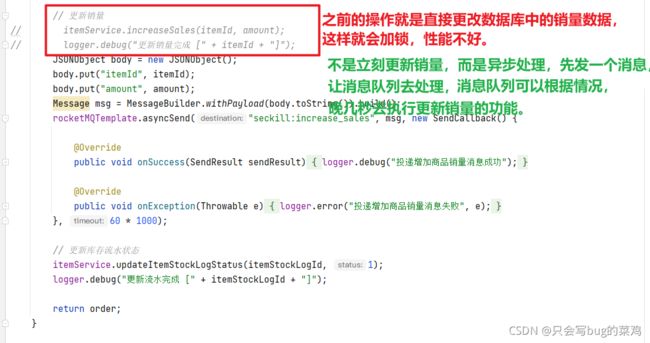
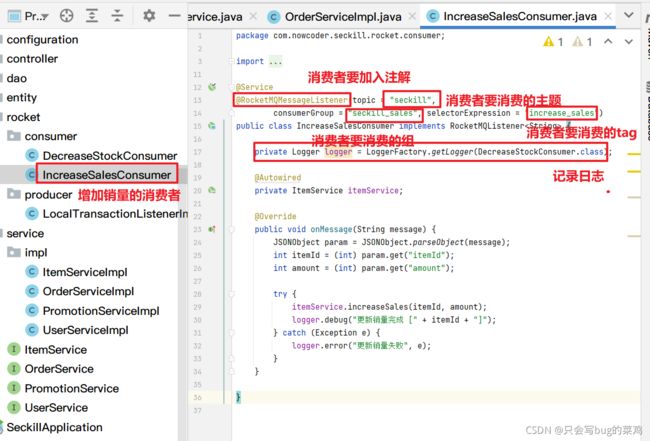
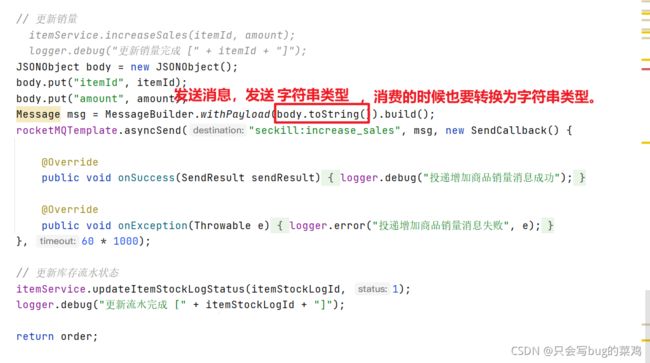

扣减库存的逻辑
缓存预热:
预减库存要在缓存中减库存,前提是缓存中有数据,一般网站的方案是在秒杀活动开始之前就把库存中的数据添加到缓存中【可以用定时器实现】。但是我们没有做那么复杂,就是在秒杀之前,使用自定义方法模拟,将数据库库存信息添加到缓存中。
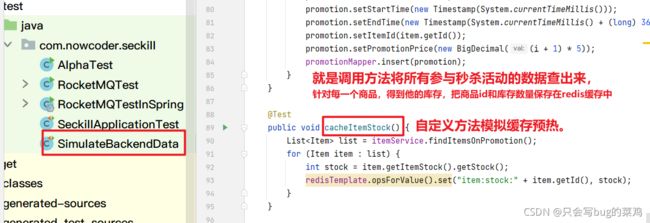
redis错误,Caused by: java.net.ConnectException: Connection refused: connect
解决问题,mysql没有启动。重新启动执行initItemStock即可。在redis中查询到结果如下:
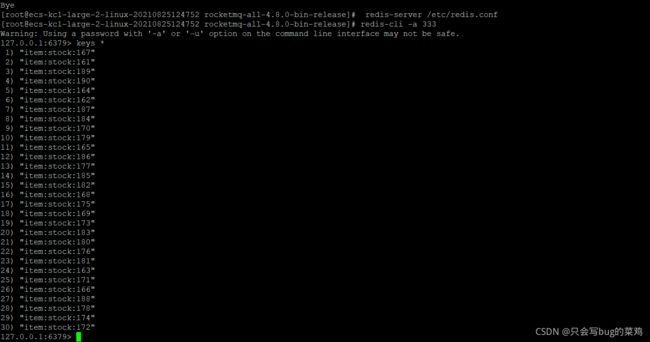

整个流程的关键就是流水,查看流水表
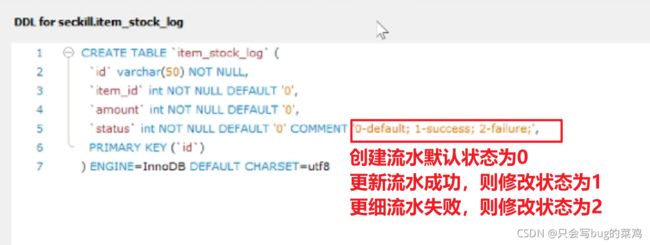
- 实体类、Mapper、mapper.xml文件都是可以借助插件生成的,不用额外处理。
- 先看容易理解的 ,最终在数据库中扣减库存是容易理解的。
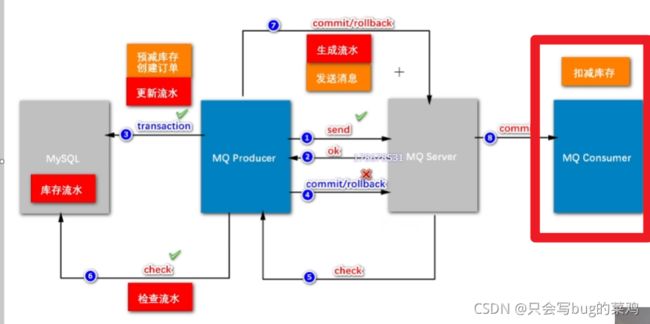
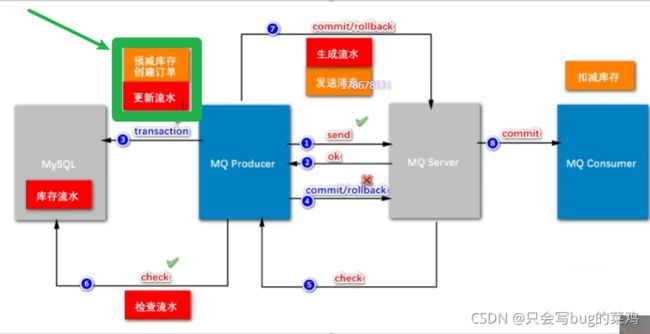
- 查看代码中预减库存,创建订单、更新流水的代码【在本地事务中处理】
- 查看第6步回查check的代码
- 查看第1步发送的消息,怎么去做。应该是在controller里做。在orderController中
- 在OrderController中
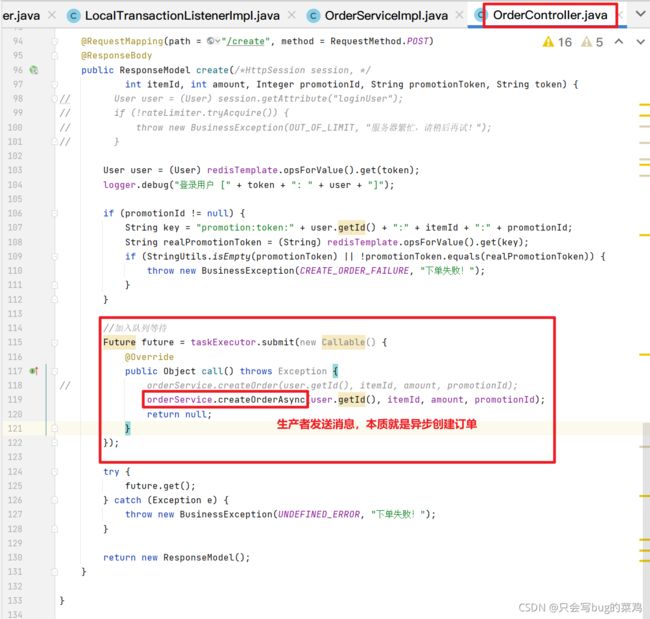
- 在OrderServiceImpl中
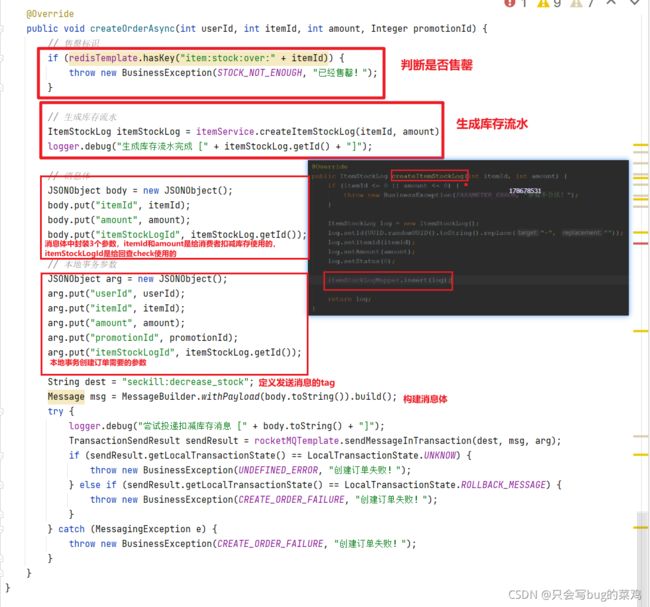
- 图中标注了具体实现方法。对照去看。

热点问题 
热点问题1:消息丢失问题
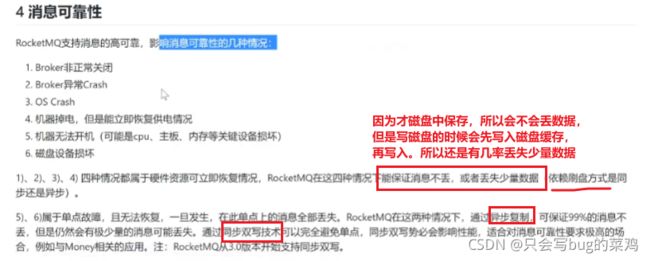
热点问题2:消费失败问题

热点问题3:重复消费问题

热点问题3:如何保证最终一致性
使用事务性消息保证预减库存和最终扣减库存的一致性。
开始削峰限流防刷

- 在交易之前进行验证,限制流量
在交易环节去限制流量就晚了,所以之前单独做一步验证的逻辑,去限制流量,比如说有100个库存,现在通过验证环节削减流量,只放1000人进来交易。
验证通过后不是直接去交易,而是给通过验证的用户发一个令牌(凭证),交易环节用户携带令牌,有令牌就能交易,没有令牌就出去。
此时出现一个新问题,如果不去限制令牌的数量,100个库存商品,来了100万人,没有必要去给这100万人都发令牌,只要发1000个令牌就足够了。这1000人去入围去抢商品就可以了。所以要去限制令牌数量。
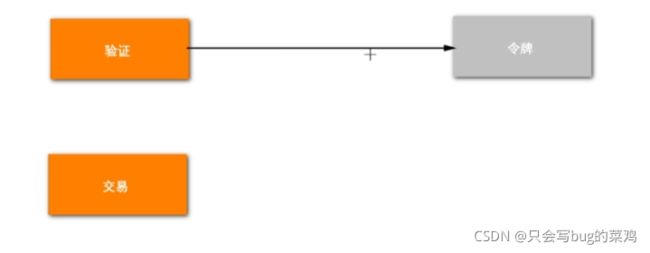
- 使用大闸限制令牌数量
大闸就是一个参数,限制了令牌的数量。加入说这个商品的流量是1000,那就把大闸设置为1000,每次发一个令牌,大闸就减1,通过这个数限制令牌的数量。用户做验证时,先看一下大闸,如果还有余量,如果够了就去发令牌,不够就不给发令牌。
此时有一个问题,如果拿到令牌直接就去交易,假设商品库存很多,有30张电影票,1000万人来抢,考虑到有人下单不付款等等情况,30万张电影票需要100万人来抢,就发100万个令牌,这个访问量也太大了,大闸对这种业务场景不太有效。库存很多,的确需要发百万级别的令牌。此时就需要加限流器去限流了。不加限制的话,大量请求访问同一个服务器(Nginx负载不均衡的情况下),就很可能导致服务器挂掉。需要用限流器去限制单机tps,让单机1s钟最多处理1万个请求。不管有多少令牌。
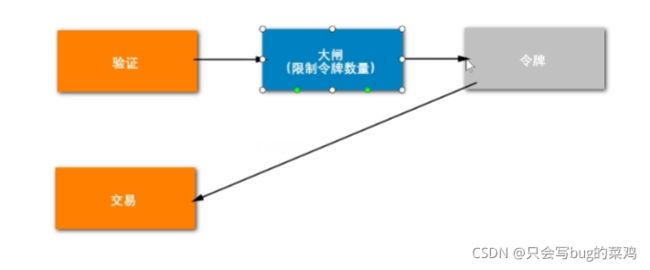
- 限流器限制流量
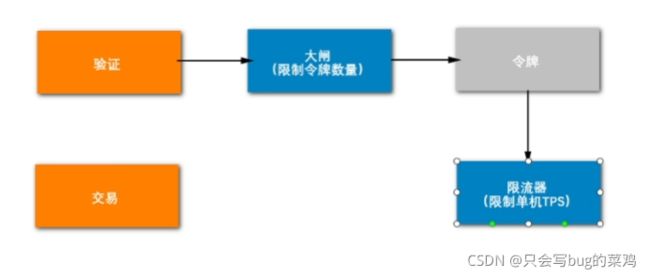
限流器一般限制服务器接近极限的值,假如说限制是1万,这1万用户进入交易环节,有可能这个交易环节的服务器由于某些原因产生的阻塞,这个线程就被卡住了。交易环节就变慢了。怎么能让这1万个流量到交易环节有一个缓冲呢?所以加入一个队列(线程池)。本来交易环节是单线程去处理,现在交给多线程的线程池去处理,增加了服务器的缓冲能力。 - 使用线程池(队列)去增加缓冲能力
由这个线程池去执行交易的代码。
还有一个问题,这是在请求发送时候做的限制,那能不能在发送请求之前做限制呢?可以在申请令牌之前使用验证码平滑流量。
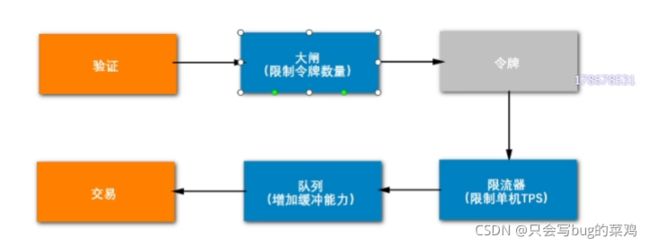
- 验证码机制平滑流量
验证码可以平滑流量,在用户点击下单时,不是马上去抢令牌,如果下单的一瞬间,1000万人都去抢令牌,那nigix的压力很大,所以点击下单的时候,输入验证码,强制让用户慢一点,将1s内的操作放慢到5s内。
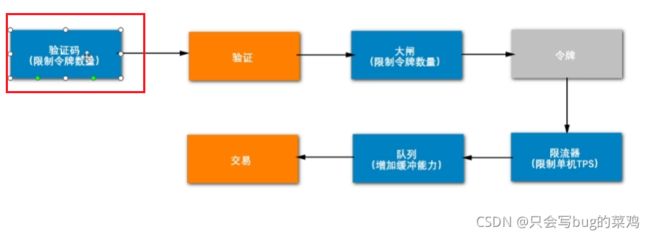
- 最终的解决方案:
验证码机制使用easy captcha,,大闸使用redis缓存,大闸数量设置为库存的5倍。限流器使用guava自带的ReteLimiter。
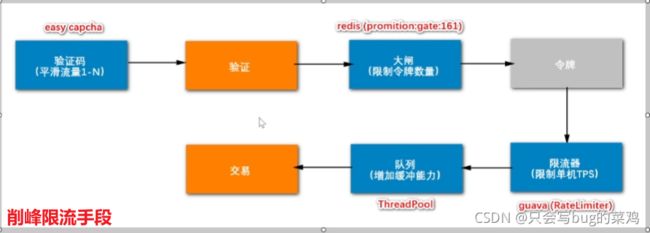
代码部分
使用验证码要先引入依赖
配置文件中设置线程池参数

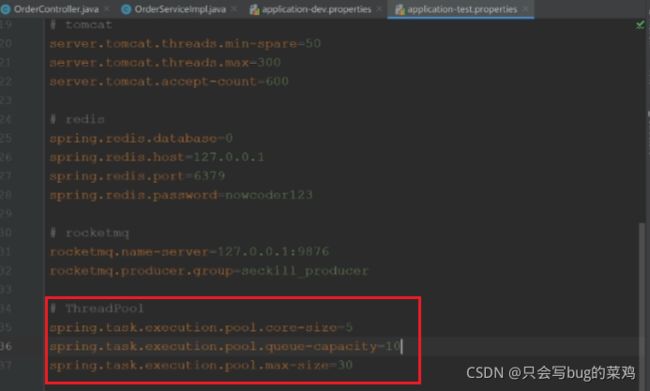
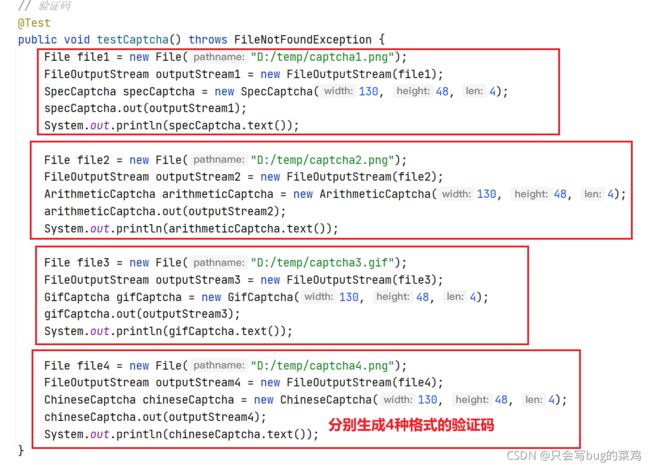
- 测试代码测试一下验证码
- 测试代码模拟大闸

- 在orderController中
获取验证码
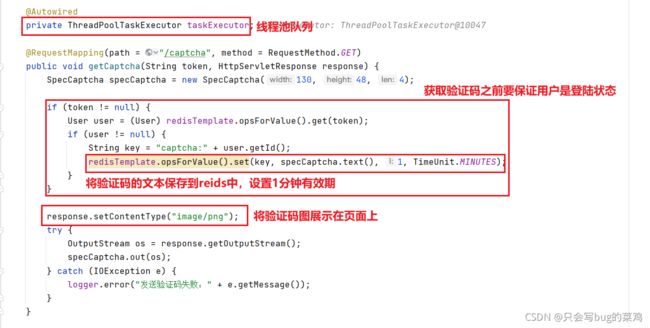
拦截器中对其处理,获取验证码的前提是要先登录。
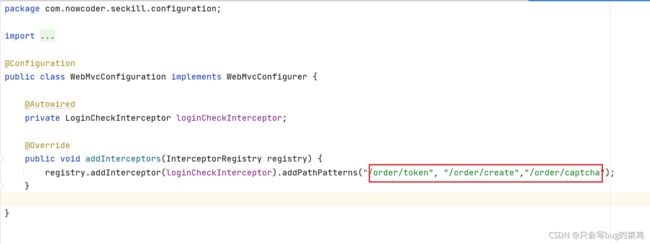
- 获取验证码成功之后,就去抢令牌
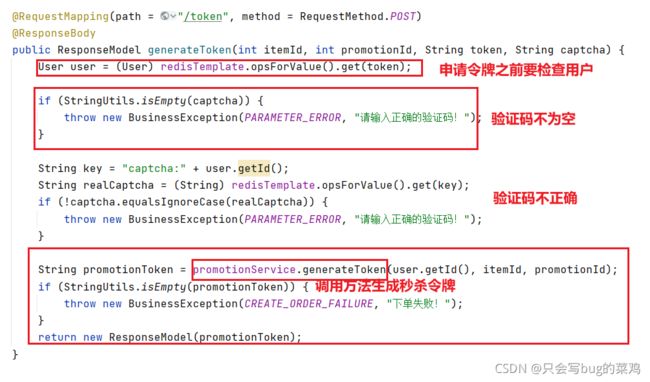
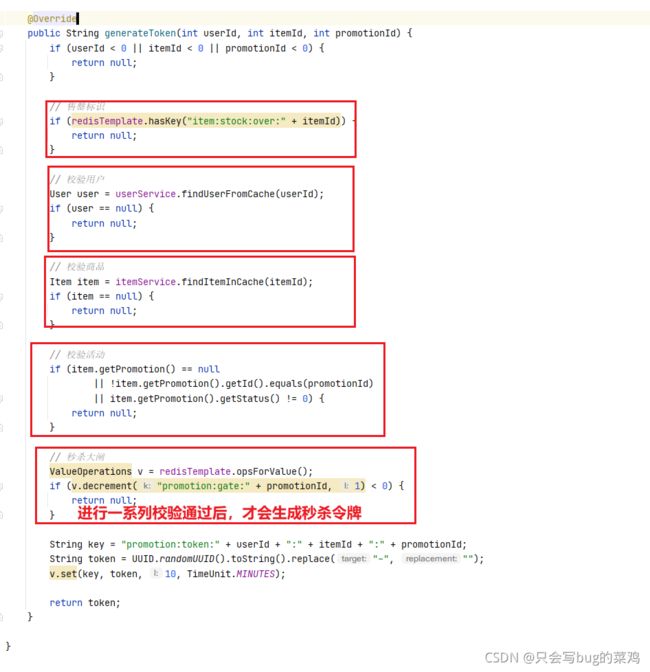
- 抢到秒杀令牌后,进入创建订单方法

前端代码【大致了解就行】
P11/P11 再次压测与总结

- 削峰、限流主要是针对正常流量,但是防刷是针对黄牛。
- 防刷实现
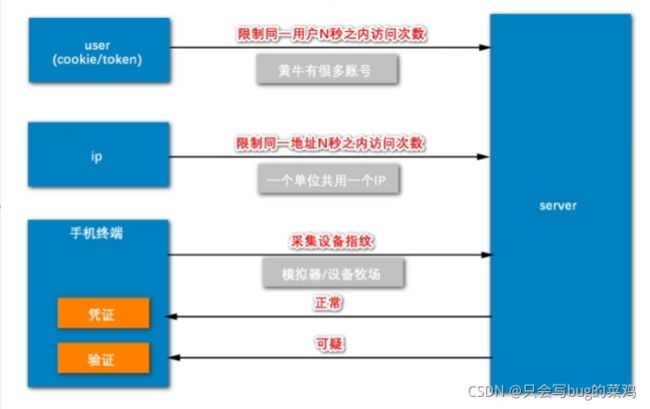
限流器底层采用令牌桶算法和漏桶算法,我们采用令牌桶算法
- 令牌桶
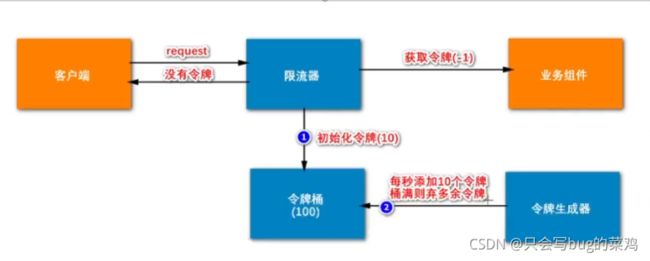
- 漏桶
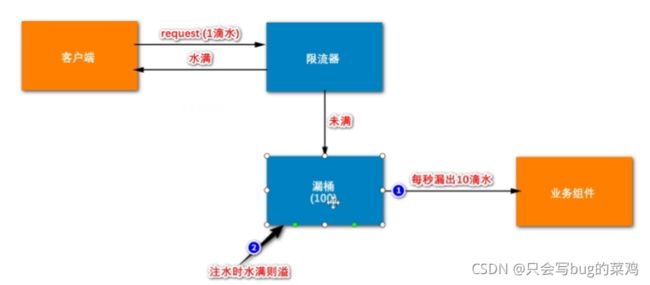
- 区别:漏桶很稳健,每次最多10个请求。服务器速率永远恒定
- 令牌桶则可以处理突发的大量请求。我们的秒杀业务中使用令牌桶可以处理大量高峰数据。
目前位置所有的业务功能已经结束。
压测数据可以编一个,不要太夸张,5500。QPS被拒绝了很多,相对较快。TPS每次走到数据库环节,相对较慢。
QPS:Queries Per Second意思是“每秒查询率”,是一台服务器每秒能够相应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
TPS是 TransactionsPerSecond的缩写,也就是事务数/秒。它是软件测试结果的测量单位。一个事务是指一个客户机向服务器发送请求然后服务器 做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数,最终利用这些信息来估计得分。客户机使 用加权协函数平均方法来计算客户机的得分,测试软件就是利用客户机的这些信息使用加权协函数平均方法来计算服务器端的整体TPS得分。
JAVA并发知识点47:00
多线程是解决并发的手段之一,但是不是唯一的手段。
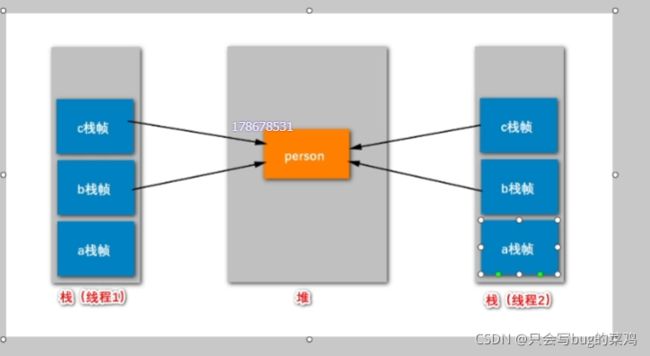
了解并发,首先要对JVM有一个了解。
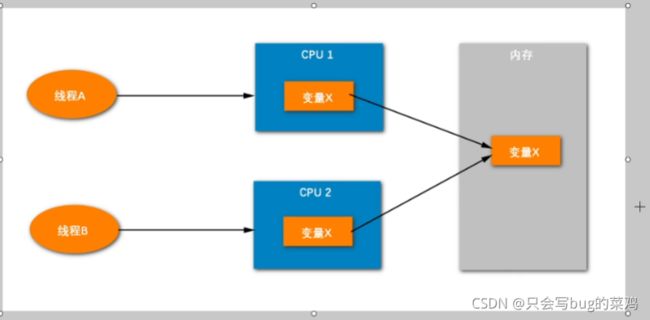
方法栈中保存方法的栈帧,等方法结束后,栈帧出栈,不需要垃圾回收。并且每一个线程都有自己的栈空间,当我们并发修改方法栈帧中的局部变量值本身的时候,不会存在并发问题。但是修改引用的时候,其实就是修改了堆内存中的值,就会出现并发问题。
- 分析:
是不是多线程环境?
是不是需要同时修改同一份数据
这份数据是不是在堆里
满足以上,才需要解决并发问题。

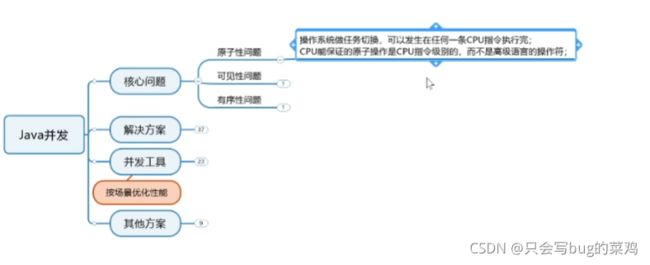



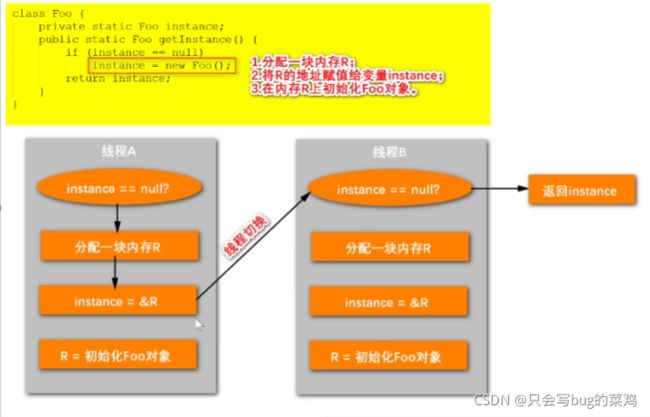
- 解决可见性问题:不使用缓存,直接使用内存空间

- 解决有序性问题:happends-before

- 解决原子性问题:监视器(锁)和信号量

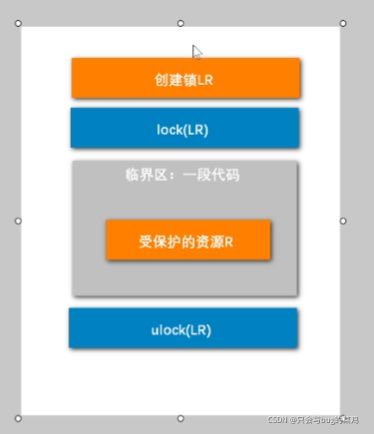
- 死锁
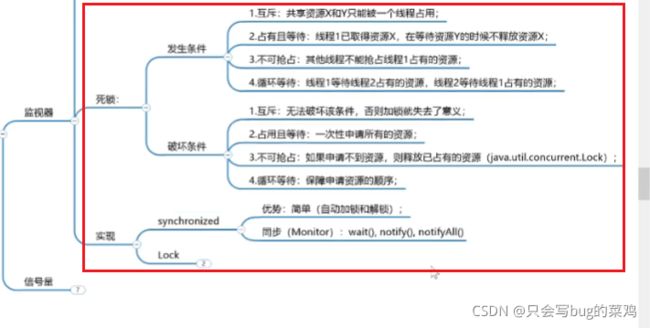
- 加锁后可以解决原子性问题,同时也顺便解决了可见性问题和有序性问题。
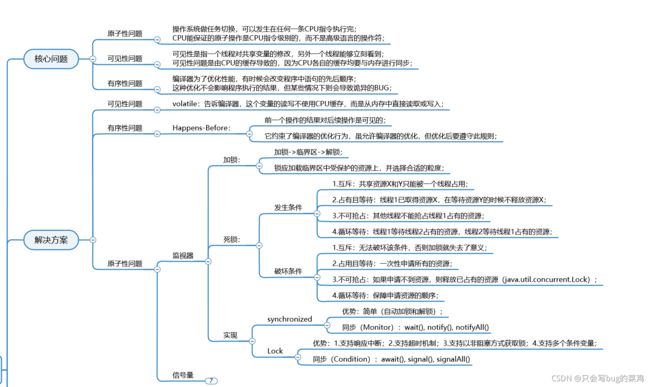
- 既然监视器能解决所有问题,为什么引入信号量?
加锁只允许一个线程操作临界区,但是信号量可以允许多个线程访问临界区。
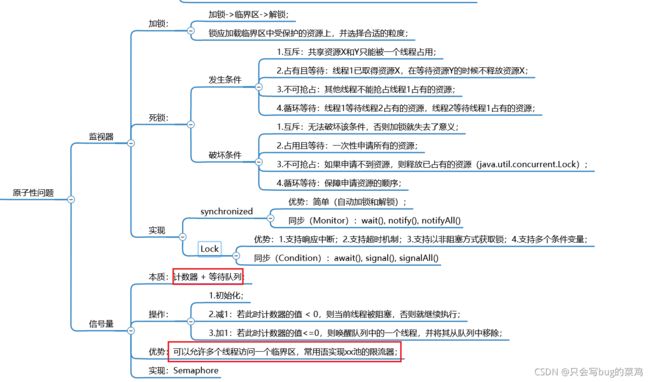
- 可以使用以上方法解决问题,但是过于麻烦,java提供了一些并发工具解决特定场景的问题。
- 比如说原子类。以Atomic开头的类,它不是解锁的,它是无锁的,基于CAS机制实现
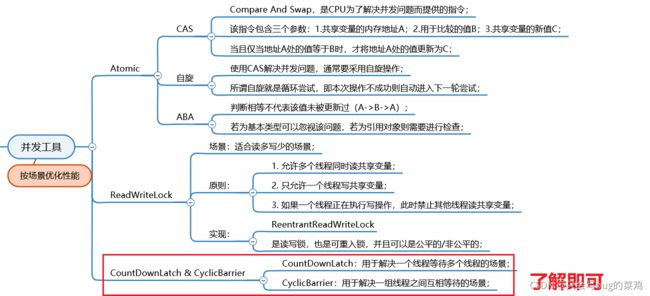
- 读写锁:适合读多写少的场景

补充:少卖问题
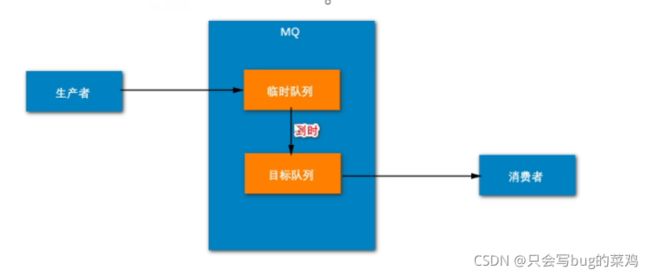
1、使用Redis延时队列去解决,隔30s后再去消费一次,把消费失败的再处理一下。

2、使用RocketMq解决,类似redis,但是自带定时器,可以自动检查时间到没到。
- 为什么我们的代码中没有加锁?是因为我们很多时候去调用方法,不需要加锁。而一旦引入缓存需要加锁的时候,引入的对象底层已经加了锁。