深度学习经典网络解析(五):VGG
深度学习经典网络解析(五):VGG
- 1.背景介绍
- 1.VGG网络与AlexNet网络
- 2.VGG网络架构
-
- 2.1 INPUT层
- 2.2 CONV1层(2层卷积)
- POOL1层
- 2.3 CONV2层 (2层卷积)
- POOL2层
- 2.4 CONV3层 (3层卷积)
- POOL3层
- 2.5 CONV4层 (3层卷积)
- POOL4层
- 2.6 CONV5层 (3层卷积)
- POOL5层
- 2.7全连接层(3层)
- 3. VGG总结
-
- 3.1 VGG的多尺度训练
- 3.2 VGGNet创新点
- 3.3 实验结论
VGG论文翻译详情见我的博客:
https://blog.csdn.net/muye_IT/article/details/123808935?spm=1001.2014.3001.5501
1.背景介绍
VGGNet是在ImageNet Challenge 2014在定位和分类过程中分别获得了第一名和第二名的神经网络架构。VGGNet是牛津大学计算机视觉组和DeepMind公司的研究员一起研发的深度卷积神经网络。VGG主要探究了卷积神经网络的深度和其性能之间的关系,通过反复堆叠3×3的小卷积核和2×2的最大池化层,VGGNet成功的搭建了16-19层的深度卷积神经网络。与之前的网络结构相比,错误率大幅度下降;同时,VGG的泛化能力非常好,在不同的图片数据集上都有良好的表现。到目前为止,VGG依然经常被用来提取特征图像。自从2012年AlexNet在ImageNet Challenge大获成功之后,深度学习在人工智能领域再次火热起来,很多模型在此基础上做了大量尝试和改进。主要有两个方向:
- 卷积核大小的变化:上一篇的ZFNet相对前面的AlexNet在模型上没有大的变化,但是把卷积核的尺寸从11×11变成了7×7
- 多尺度:训练和测试使用整张图的不同尺度,也就是VGG网络的改进。
1.VGG网络与AlexNet网络

VGG网络与AlexNet网络相比:
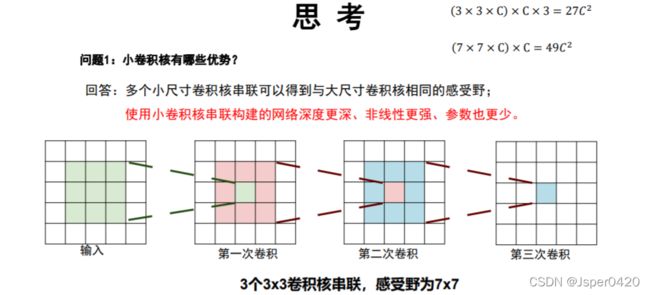
1.使用尺寸更小的3x3卷积核串联来获得更大的感受野,放弃使用11x11和5x5这样的大尺寸卷积核:
在VGG中,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。因为在3个3×3卷积核串联后的的感受野与7×7卷积的感受野是一样的,但是3×3卷积可以得到更多的细节,7×7卷积会忽略一些细节。7×7卷积只是用一次变换就得到某个区域的特征,而3×3卷积是用了三次变换得到某个区域的感受野,这个三次3×3卷积非线性能力更强,那么他的描述能力就更强,他就能学习到更复杂的特征。
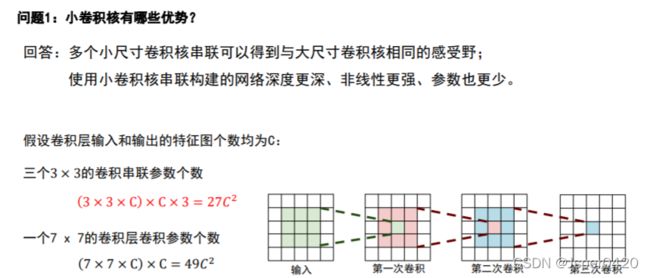
2.深度更深、非线性更强,网络的参数也更少 :
使用小卷积核串联构建的网络深度更深、非线性更强、参数也更少。
使用3个3 × 3的卷积:3 × 3 × × × 3 = 27²
使用1个7 × 7的卷积:7 × 7 × × = 49²
3个3 × 3的卷积相比1个7 × 7的卷积参数量少了一半!
3. 去掉了AlexNet中的局部响应归一化层(LRN)层。
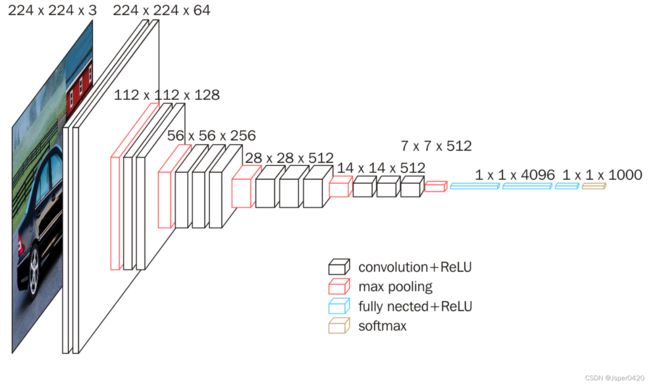
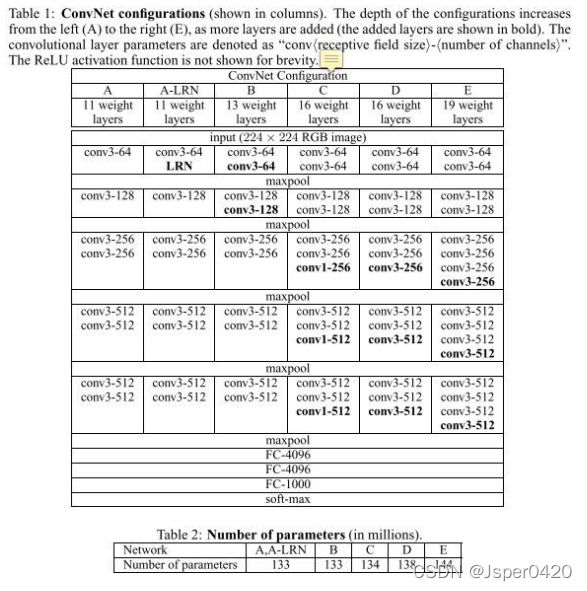
2.VGG网络架构
VGG16
- ➢ 13个卷积层与3个全连接,一共16层;
- ➢ 分为5段conv1,…,conv5,每一段中卷积层的卷积核个数均相同 ;
- ➢所有卷积层均采用3x3的卷积核及ReLU激活函数;
- ➢ 所有的池化层都采用最大池化,其窗口大小为2x2、步长为2;
- ➢经过一次池化操作,其后卷积层的卷积核个数就增加一倍,直至到达512;

2.1 INPUT层
VGGNet的图片预处理
VGG的输入224*224的RGB图像,预处理就是每一个像素减去了所有像素的均值。
data Data
include
phase: train
transform param
mirror: true
crop size: 224
mean value: 103.939, 116.779, 123.68
data param
source:
data/ilsvrc12 shrt 256/ilsvrc12 ftrain_ leveldb
batch size: 64
backend: leveldb
blob shapes
data: [1, 3, 224, 224 ]
labe:[ 1 ]
2.2 CONV1层(2层卷积)
输入图像经过两个卷积层,也就是VGG16网络结构十六层当中的第一层(CONV1-1)和第二层(CONV1-2),合称为CONV1。将224x224x3的输入矩阵变成一个224x224x64的矩阵。
CONV1: 64 个3x3 卷积核,步长为 1,padding设置为1
- 输入:224x224x3 大小的图像
- 尺寸:(224-3+2×1)/1+1 = 224
- 卷积核个数:64
- 输出尺寸:224×224×64 (padding设置为SAME)
第一个卷积层提取了64种结构的响应信息,得到了64个特征相应图; 特征图每个元素经过ReLU函数操作后输出。
conv1 Convolution
param
Ir mult: 1
decay mult: 1
Ir mult: 2
decay mult: 0
convolution param
num output: 64
pad: 1
kernel size: 3
weight fller
type: gaussian
std: 0.01
bias fller
type: constant
value: 0
blob shapes
conv1 1:[1, 64, 224, 224]
relu1_ 1 ReLU InPlace
blob shapes
conv1 1:[1, 64, 224, 224]
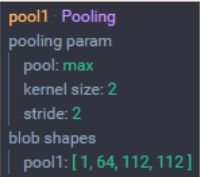
POOL1层
第二层 (POOL1):池化大小为 2x2,步长为 2,那么得到的矩阵维数刚好为原来的一半
- 输入:224x224x64 大小的图像
- 尺寸:(224-2)/2+1 = 112
- 池化层个数:64
- 输出尺寸:112×112×64
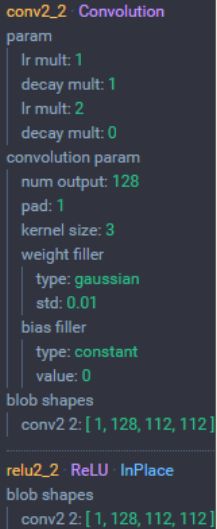
2.3 CONV2层 (2层卷积)
我们从上面的过程中知道了,input为300x300x3的图片,经过第一层之后变成150x150x64,那么第二层里面有128个卷积核,可以推出经过第二层后得到是75x75x128。
CONV2层 (2层卷积): 2个128 通道3x3 卷积核,步长为 1,padding设置为1
- 输入:112×112×64 大小的图像
- 尺寸:(112-3+2×1)/1+1 = 112
- 池化层个数:128
- 输出尺寸:112×112×128
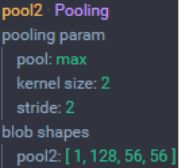
POOL2层
POOL2层 :池化大小为 2x2,步长为 2
- 输入:112×112×128 大小的图像
- 尺寸:(112-2)/2+1 =56
- 池化层个数:128
- 输出尺寸:56×56x128
2.4 CONV3层 (3层卷积)
CONV3层 (3层卷积): 3个256 通道的3x3 卷积核,步长为 1,padding设置为1
- 输入:56x56x128 大小的图像
- 尺寸:(56-3+2×1)/1+1 = 56
- 卷积层通道数:256
- 输出尺寸:56×56×256
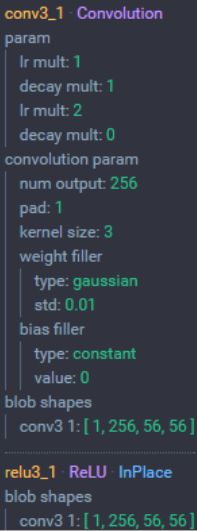
POOL3层
POOL3层 :池化大小为 2x2,步长为 2
- 输入:56×5×6256 大小的图像
- 尺寸:(56-2)/2+1 = 28
- 池化层个数:256
- 输出尺寸:28x28x256
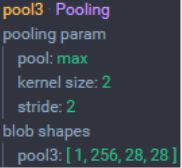
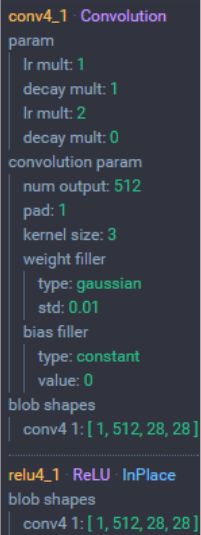
2.5 CONV4层 (3层卷积)
CONV4层 (3层卷积): 3个512 通道的3x3 卷积核,步长为 1,padding设置为1
- 输入:28x28x256 大小的图像
- 尺寸:(28-3+2×1)/1+1 = 28
- 卷积层通道数:512
- 输出尺寸:28×28×512
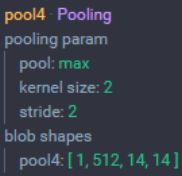
POOL4层
POOL4层 :池化大小为 2x2,步长为 2
- 输入:28×28×512 大小的图像
- 尺寸:(28-2)/2+1 =14
- 池化层个数:512
- 输出尺寸:14x14x256
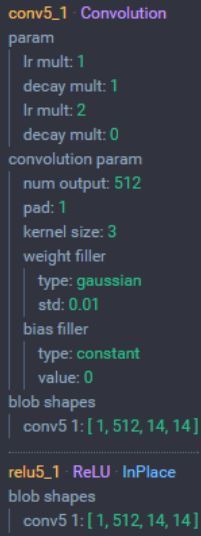
2.6 CONV5层 (3层卷积)
CONV5层 (3层卷积): 3个512 通道的3x3 卷积核,步长为 1,padding设置为1
5. 输入:14x14x512 大小的图像
6. 尺寸:(14-3+2×1)/1+1 = 14
7. 卷积层通道数:512
8. 输出尺寸:14×14×512
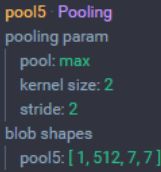
POOL5层
POOL4层 :池化大小为 2x2,步长为 2
9. 输入:14×14×512 大小的图像
10. 尺寸:(14-2)/2+1 =7
11. 池化层个数:512
12. 输出尺寸:7x7x512
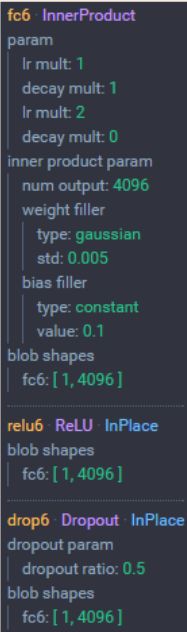
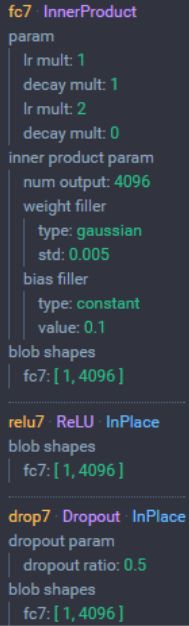
2.7全连接层(3层)
进入全连接层之前是7x7x512的张量,通过flatten展平后编程25088维的向量,通过fc6全连接层输出后编程4096维的向量,通过去fc7全连接层输出后变成4096维的向量,之后通过 fc8全连接层输出后变成1000维的向量(ImageNet中的类别数量)

3. VGG总结
3.1 VGG的多尺度训练
VGGNet使用了Multi-Scale的方法做数据增强,将原始图像缩放到不同尺寸S,然后再随机裁切224′224的图片,这样能增加很多数据量,对于防止模型过拟合有很不错的效果。实践中,作者令S在[256,512]这个区间内取值,使用Multi-Scale获得多个版本的数据,并将多个版本的数据合在一起进行训练。VGG作者在尝试使用LRN之后认为LRN的作用不大,还导致了内存消耗和计算时间增加。
虽然网络层数加深,但VGG在训练的过程中比AlexNet收敛的要快一些,主要因为:
- 使用小卷积核和更深的网络进行的正则化;
- 在特定的层使用了预训练得到的数据进行参数的初始化。对于较浅的网络,如网络A,可以直接使用随机数进行随机初始化,而对于比较深的网络,则使用前面已经训练好的较浅的网络中的参数值对其前几层的卷积层和最后的全连接层进行初始化。
3.2 VGGNet创新点
- 使用了更小的3×3卷积核,和更深的网络。两个3×3卷积核的堆叠相对于5×5卷积核的视野,三个3×3卷积核的堆叠相当于77卷积核的视野。这样一方面可以有更少的参数(3个堆叠的3×3结构只有77结构参数数量的(3×3×3)/(7×7)=55%);另一方面拥有更多的非线性变换,增加了CNN对特征的学习能力。
- 在VGGNet的卷积结构中,引入1×1的卷积核,在不影响输入输出维度的情况下,引入非线性变换,增加网络的表达能力,降低计算量。
- 训练时,先训练级别简单(层数较浅)的VGGNet的A级网络,然后使用A网络的权重来初始化后面的复杂模型,加快训练的收敛速度。
- 采用了Multi-Scale的方法来训练和预测。可以增加训练的数据量,防止模型过拟合,提升预测准确率。
3.3 实验结论
- LRN层无用(A和A-LRN)。作者通过网络A和A-LRN发现AlexNet曾经用到的LRN层(local response normalization,LRN是一种跨通道去normalize像素值的方法)没有性能提升,因此在后面的4组网络中均没再出现LRN层。当然我也感觉没啥用,想到max-pooling比average-pooling效果好,我就感觉这个LRN没啥用,不过如果把LRN改成跨通道的max-normal,我感觉说不定会有性能提升。特征得到retain更明显。
- 深度增加,分类性能提高(A、B、C、D、E)。从11层的A到19层的E,网络深度增加对top1和top5的error下降很明显,所以作者得出这个结论,但其实除了深度外,其他几个网络宽度等因素也在变化,depth matters的结论不够convincing。
- conv1x1的非线性变化有作用(C和D)。C和D网络层数相同,但D将C的3个conv3x3换成了conv1x1,性能提升。这点我理解是,跨通道的信息交换/融合,可以产生丰富的特征易于分类器学习。conv1x1相比conv3x3不会去学习local的局部像素信息,专注于跨通道的信息交换/融合,同时为后面全连接层(全连接层相当于global卷积)做准备,使之学习过程更自然。
- 多小卷积核比单大卷积核性能好(B)。作者做了实验用B和自己一个不在实验组里的较浅网络比较,较浅网络用conv5x5来代替B的两个conv3x3。多个小卷积核比单大卷积核效果好,换句话说当考虑卷积核大小时:depths matters。