身处技术创新驱动的时代,只有开放协作才能带来巨大进步,创造非凡成就。
We are learning by contributing.
We crowdsource from community.
StarRocks 社区的发起和发展,正是立足于各个开发者的“贡献”和“集智”。
周康,冯浩桉。一个是在云厂商从业多年的超级奶爸,一个是步入职场不久的“萌新”技术宅。两人都在 StarRocks 社区成立第一天加入,过去五个多月里为 StarRocks 项目作出了重要贡献。
近期,经过 StarRocks 社区 PMC 提名与投票,两位开发者接受 StarRocks 社区邀请,正式成为 StarRocks 项目的 Committer。
他们在技术上有哪些癖好,如何看待当下的 OLAP 产品,又如何走上了社区之路?StarRocks 社区和两位有故事的男同学聊了聊。
✨✨✨
周康:公有云时代,要善用业务优势提出创新架构

就职于阿里云开源大数据平台,负责 EMR OLAP 产品研发,包括 StarRocks、ClickHouse、Presto(Trino)等开源组件。曾参与基于开源组件构建的分布式调度平台、分布式计算平台、数据分析平台的建设。
他热情帮助社区伙伴解决实际使用问题,在项目上的主要贡献有:
- 支持通过外表的方式查询 Apache Iceberg 数据湖中的数据;
- 支持读取 CSV 文件格式;
- 支持 GZip 压缩格式;
- 提升外表的 HDFS 存储 block size 过大时的查询性能。
个人的多年爱好是篮球,去年增加了一项——遛娃。
- Committer 首先是开发者,谈起“开发者”的身份,你会怎么说?
从初学者到稍有经验的开发者,我觉得最重要的就是热爱。作为一个开发者,很多瞬间我都会感到兴奋:遇到一个难解决的性能问题,看到一篇新的有意思的论文,看到一段很精妙的代码……
比较喜欢 Debug 一些自认为复杂的问题,对于代码细节会有强迫症和小洁癖。
- 谈谈你与技术社区的结缘
我最早深度关注的社区是 Redis 和 Cassandra,为了将其作为基础组件使用,看了一些分布式系统的论文和项目。我对这两个组件的实现非常感兴趣,在当时激发了我对于分布式系统和开源的兴趣。后来,工作中经常接触 Spark,也就会开始不定期把自己的一些想法反馈给社区。

第一个 Spark Jira
最早接触到 Redis 和 Cassandra 社区时,我意识到自己在分布式、计算、存储等方向的理论储备都非常匮乏。于是就带着补课的想法找到了 MIT 6.824 这门课,这门课让我对 CAP 和一致性协议有了最基础的认识,而能发现这门课也得益于社区里的分享。
- 你在 OLAP 产品方面都有怎样的经历和心得?如何成为了 StarRocks Committer?
最早接触 OLAP 是源于公司内部要基于 Spark SQL+Kudu 构建数据分析平台,虽然项目上线了,但支撑起来的业务量不算大,也遇到过很多稳定性问题。经历了技术和产业的变迁,如今作为公有云上 OLAP 产品的开发者,我最大的体会就是,要有创造和改变的意识,去利用自己的业务洞察能力提出创新架构,来解决未来可能出现的问题。
2021年,我们团队在进行 OLAP 产品选型时接触到了 StarRocks。作为云厂商一侧,我在想应该先给 StarRocks 带来什么能力?首先想到的几点里就包含数据湖分析方向。当时看到 Presto CPP 版本在推进,那么作为已经具备向量化、CBO 这些能力的 StarRocks 是否可以做得更好呢?
经过和社区 PMC、Committer 们的交流,我们决定先开始这方面的初步探索。目前,极速数据湖分析在 StarRocks 中已经迈出了第一步。(产品详情:https://help.aliyun.com/document_detail/404790.html)
作为 Committer,我是真的觉得目前的工作还不够,有很多想法还没落地。对于如何成为 Committer 这件事,最重要的是在社区积极发声,我们团队在数据湖分析方向迈出第一步的过程就是例证。
还有一次,我基于 Spark 的经验判断当时 HDFS Scan 部分存在优化空间,于是就提出了自己的 PR,发现刚好社区伙伴也在尝试优化这个问题。最终经过讨论,我的实现被 Merge 了。所以,积极发现问题并勇敢提出来吧!
- 作为最早加入 StarRocks 社区的开发者之一,遇到过哪些问题?最有成就感/获得感的事情是什么?
接触到 StarRocks 时,我对向量化、CBO、并行执行引擎等技术方向很感兴趣,很想快速加入做出贡献。但是当时我对这个系统的内核几乎没有了解,而项目已经发布了一两个版本,想参与这些事情对我来说短期内不太现实。那么我应该先给这个项目带来些什么呢?
为了找到答案,我尝试和PMC与Committer沟通,最终判断作为云厂商可以先立足数据湖分析这个方向去做尝试。而上面提到的向量化等技术对于数据湖分析都是至关重要的。(戳《如何打造一款极速数据湖分析引擎》)
最有成就感的事情是什么?Good First Issue 就挺有里程碑意义的,是我在社区最早的探索。

Good First Issue
- 作为首批 StarRocks Committer,对这个社区有怎样的感想和建议?
作为还处在发展早期阶段的技术社区,StarRocks 机会很多,需要大家一起努力去完成的工作有非常多。然而作为一个数据库领域的基础软件系统,参与的门槛也是相对有点高的。
因此,我建议社区的 PMC 、Committer 们能够多分享一些源码、原理级别的内容给大家,让更多人能够参与共创。(上 B 站搜索“StarRocks_labs”,探访 StarRocks 技术内幕 )
随着社区用户越来越多,希望能有更多使用者共建生态,社区需要创造机会让他们参与。
关于未来,我主要会集中在云原生、存算分离、数据湖、极速等方面进行具体工作的展开和探索。

技术教育从娃娃抓起
冯浩桉:何谓开发者?天生不老实,总想搞事情!

StarRocks 核心研发工程师,“萌新”数据库开发者。
他在StarRocks很多重大 Feature 实现和改进上做出了贡献,包括:
- 全局低基数字典功能的核心开发者
- 主导实现了 Java UDF,UDAF,UDTF
- 实现了 Insert into MySQL 外表 BE 部分
- 优化了 Hive 外表 Scan 性能
- 优化了 多个日期函数计算性能
- 优化了 Sum(case when)表达式计算性能
热衷敲敲打打,做过一些游戏 demo,参加过游戏开发界的“华山论剑 ” GAMEJAM。喜欢观察不同的领域思考与解决问题的方式。
- Committer 首先是开发者,谈起“开发者”的身份,你会怎么说?
天生不老实,总想搞事情。内心极度渴望想要支持更酷的功能、更好的性能,把一个 Query 的执行从上到下优化到极致。总之,想做很多事情。
- 谈谈你与技术社区的结缘
最早接触技术社区是两年前,那时候组内做项目用到了一个 redis-cluster-proxy 的组件。临近上线遇到了一个小 Bug,就连夜排查修复了。当时还不会提 PR,就在 Issue 里截图说明,然后就收到了第一条来自社区的反馈。
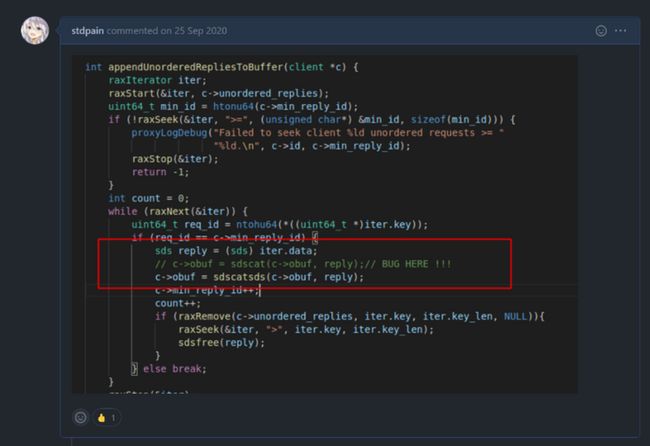
收到的第一条来自技术社区的反馈
之后工作遇到过 CRoaring/gperftools/brpc/wasmer 等第三方库的问题,提过一些小的修改,虽然有的解决过程比较曲折,最终还是得到了社区的支持和反馈,非常感谢这些社区的技术大牛愿意 review 我的 PR。
在这里夸一下 CRoaring 社区和 GCC 社区的大佬!我睡觉之前发 Issue,基本上起床后就能收到反馈。
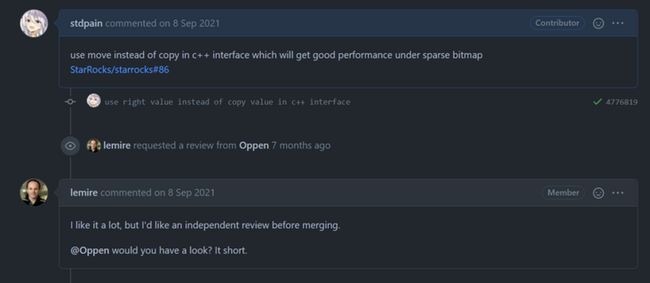
起床后收到的社区反馈
- 你在 OLAP 产品方面都有怎样的经历和心得?如何成为了 StarRocks Committer?
我在社区里面灌水比较多哈哈哈图片 运气比较好,手速比较快,解决了一些 Bad Case,例如优化了聚合函数以及某些表达式执行性能。同时也跟社区的同学一起合作开发了全局字典优化和一些时间函数的优化。
2020 年毕业后进入 OLAP 领域,对向量化执行比较感兴趣。去年 9 月份就加入到 StarRocks 的开发者阵营中,给 StarRocks 做了一些小改进。在社区里接触了很多大佬,给了我非常多的帮助和建议。
StarRocks 社区目前除了要在功能上发力外 ,比如云原生、数据湖、更好的易用性,在性能上仍在继续深度探索,例如排序/JOIN 性能,甚至未来还会去支持 Codegen,提升在高并发的场景下的性能和稳定性表现。这也是能引起我热情、共同进步的地方。
- 作为最早加入 StarRocks 社区的开发者之一,遇到过哪些问题?最有成就感/获得感的事情是什么?
最开始还是对代码不熟悉,在尝试优化 Shuffle 或者是优化表达式的时候忽略了很多场景和特殊的 Case,给社区提的几个 PR 中直接被肉眼 Review 出问题了。
- 作为首批 StarRocks Committer,对这个社区有怎样的感想/建议/探索计划?
社区氛围比较开放,和我交流过的不少海外地区的小伙伴都有提过 Commit,一天之内就解决了社区整理过的 Good First Issue。
对新人比较友好,Reply 和 Review 都很快,新同学可以很快融入社区建设中。80% 的 Issue 问题当天就会有人 Reply,Slack 上几个小时就有人回复。
作为深入参与的开发者,对于需要改进的地方也能及时感受到,比如:
社区文档还需进一步完善,很多已经支持的函数或者是功能的描述都需要进一步优化。
易用性上可以继续探索,争取早日抛弃手动指定分桶,另外数据导入的易用性也有进一步提高的空间。
支持 DataFrame 的方式可以再探索,某些场景下 SQL 对数据分析人员还存在一定局限性。
如何对用户屏蔽参数、让产品用起来更加无脑?一些功能的设计还需要更加人性化。
未来对社区的期望嘛,就是大家一起把 StarRocks 做成最强最好用的产品,让接触到它的一瞬间就感到惊艳的使用体验。遇到觉得性能或者功能不佳的 Case 可以甩在 Issue 里面,我相信很快这些问题都会一一优化掉。
✨✨✨
让代码为更多人所用是不少工程师的梦想
两位在社区根深叶茂的 StarRocks Committer
也是从 Good First Issue 开始:
https://github.com/StarRocks/...
了解 StarRocks 社区规范和贡献流程:
https://github.com/StarRocks/...
祝各位开发者拥有正向循环的社区之旅
欢迎在 GitHub 为 StarRocks 点亮你的