【4 - 分组】Sql Server - 郝斌(分组group by、过滤having、聚合函数max() / count()、排序order by、select语句的执行顺序)
课程地址:数据库 SQLServer 视频教程全集(99P)| 22 小时从入门到精通_哔哩哔哩_bilibili

目录
group by(分组)
group by a,b 的用法
having(对分组之后的信息进行过滤)
having和where的区别
总结
PPT内容总结与复习
函数的分类
聚合函数的使用
max() 函数
count() 函数
group by子句
聚合函数的错误用法
基于多个字段分组
having子句的用法
order by子句
select语句的执行顺序问题
select语句的基本结构
为什么select语句执行顺序很重要
select语句执行顺序
切换数据库也可以用SQL语句:use 数据库名称
group by(分组)
输出每个部门的编号 和 该部门的平均工资
select deptno, avg(sal) as "部门平均工资" from emp group by deptno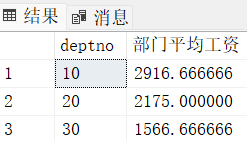
判断下面语句是否正确
select deptno, avg(sal) as "部门平均工资", ename
from emp
group by deptno
-- 错误,前面两个字段都只有3行,第三个字段有14行(ename是组内详细信息)一旦使用了group by,select后的字段只能写组的整体信息,不能写组内某个字段的详细信息
rollup 和 cube 查询
- group by rollup(a,b,c) 统计结果等同于 group by(a)、group by(a,b)、group by(a,b,c)、group by() 结果的并集
- group by cube(a,b,c) 统计结果等同于 group by(a)、group by(b)、group by(c)、group by(a,b)、group by(a,c)、group by(b,c)、group by(a,b,c)、group by() 结果的并集

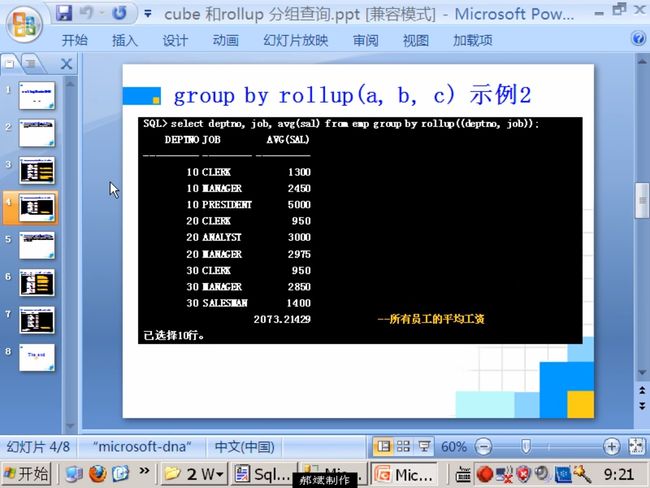
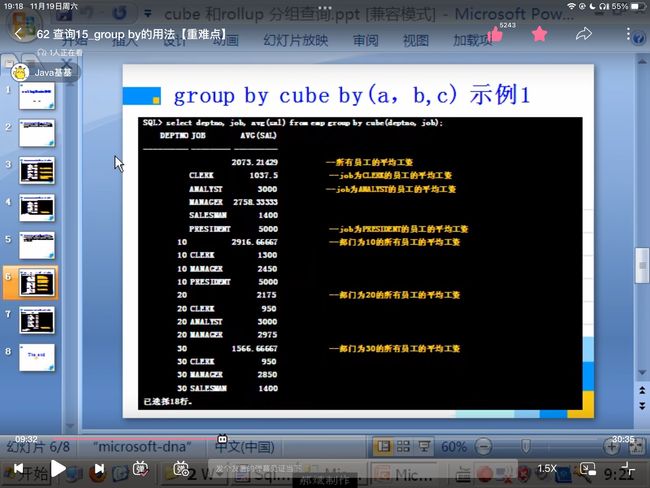

总结:使用了group by之后,select中只能出现分组后的整体信息,不能出现组内的详细信息
group by a,b 的用法
以a和b整体为分组依据,组内的个体都是有着相同的a和b信息的
select deptno, job, sal from emp group by deptno, job -- error
select * from emp group by deptno, job -- error
select deptno, job, avg(sal) "平均工资", count(*) "人数", sum(sal) "总工资", min(sal) "最低工资"
from emp
group by deptno, job
order by deptno -- OK
select job from emp group by deptno, job -- OK
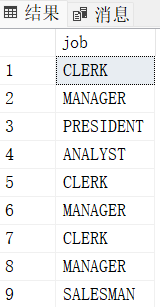
总结:
- 格式:group by 字段的集合(一个或多个)
- 功能:把表中的记录按照字段分成不同的组
- 例子:查询不同部门的平均工资
- 注意:理解 group by a,b,c 的用法,先按a分组,如果a相同,再按b分组,如果b相同,再按c分组,最终统计的是最小分组的信息
- 一定要明白下列语句为什么是错误的:
select deptno, avg(sal) as "部门平均工资",enamefrom emp group by deptno
select deptno,enamefrom emp group by deptno
select deptno, job,salfrom emp group by deptno, job
select comm, count(*) from emp group by comm 
group by分组之后,count 也可以对 null 计数
having(对分组之后的信息进行过滤)
输出部门平均工资大于2000的部门的部门编号、部门平均工资
select deptno, avg(sal) from emp group by deptno having avg(sal)>2000判断下列SQL语句是否正确:
select deptno, avg(sal) as "平均工资" from emp
group by deptno having avg(sal)>2000 -- OK
select deptno, avg(sal) as "平均工资" from emp
group by deptno having "平均工资">2000 -- error
select deptno, avg(sal) as "平均工资" from emp
group by deptno having deptno>10 -- OK
select deptno, avg(sal) as "平均工资" from emp
group by deptno having count(*)>3 -- 按部门人数过滤也OK
select deptno, avg(sal) as "平均工资" from emp
group by deptno having ename like '%A%' -- error把姓名不包含A(not like)的所有员工按部门编号分组,输出部门平均工资大于2000的部门的部门编号、部门平均工资
select deptno, avg(sal) "平均工资" from emp
where ename not like '%A%'
group by deptno
having avg(sal) > 2000having和where的区别
having与where都是对数据过滤,只保留有效的数据;且都不允许出现字段的别名,只允许出现最原始的字段的名字(SQL Server和Oracle都成立)
但存在以下区别:
- where是对原始的记录过滤,不能使用聚合函数,因为还没分组
- having是对分组之后的记录过滤
所有select的参数的顺序是不允许变化的,否则编译时出错。where必须得写在having的前面,顺序不可颠倒,否则运行出错
总结
- having子句是用来对分组之后的数据进行过滤,因此使用having时通常都会先使用group by
- 如果没使用group by,但使用了having,则意味着having把所有的记录当做一组来进行过滤,但这种写法极少用
select count(*) from emp having avg(sal)>1000
- having子句出现的字段必须是分组之后的组的整体信息,不允许出现组内的详细信息
- 尽管select字段中可以出现别名,但having子句中不能出现字段的别名,只能使用字段最原始的名字,原因在SQL语句的执行顺序上
- having和where的异同
PPT内容总结与复习
函数的分类
单行函数:对每一行记录都起作用,对每一行记录都能返回一个结果
- 例子:select ename, lower(ename) from emp
- lower(ename) 会对每一个记录的ename字段都返回一个结果
多行函数:对一组记录返回一个结果,即对多行记录返回一个结果。聚合函数就是多行函数
- 例子:select max(sal) from emp -- OK
- select sal, max(sal) from emp -- error
聚合函数的使用
- max
- count
- min
- sum
- avg

max() 函数
- 适用于数值型、字符型和日期型的列
- 对于列值为null的列,max函数不将其列为对比的对象
count() 函数
- count(*) 返回组中总记录数目
- count(exp) 返回表达式exp值非空的记录数目
- count(distinct(exp)) 返回表达式exp值不重复的、非空的记录数目
例子:
- select * from emp
- select count(*) from emp 返回emp表记录的总个数,包含空行
- select count(comm) from emp 返回emp表中佣金不为空的职工个数
注意0和null是两个不同的概念,个数包含comm为0的记录,但不包含comm为null的记录
用聚合函数作用某个字段时,会忽略掉所有的null行
- select count(distinct deptno) from emp 统计emp表中员工所处部门的个数
group by子句
用于对查询的结果分组统计
聚合函数的错误用法
1、如果没有group by子句,select列表中不允许出现字段(单行函数)与分组函数混用的情况
select empno, sal from emp -- ok
select avg(sal) from emp -- ok
select lower(ename), sal from emp -- ok
select lower(ename), avg(sal) from emp -- error2、不允许在where子句中使用分组函数,牵扯到select的执行顺序问题
3、出现在select列表中的字段,如果不是包含在分组函数中,那么该字段必须同时在group by子句中出现。但是包含在group by子句中的字段则不必须出现在select列表中
select avg(sal) from emp group by deptno -- ok
select deptno, avg(sal) from emp group by deptno -- ok
select ename, avg(sal) from emp group by deptno -- error基于多个字段分组
错误代码:
select deptno, job, ename, avg(sal) from emp group by deptno, job
-- select_list中不能出现ename字段having子句的用法
下述4个结论在SQL Server和Oracle中均成立:
- having子句是用来对分组之后的数据进行进一步的过滤,所以使用having时通常都会先用group by进行分组;如果没有使用group by,但使用了having,则意味着having是把所有的记录当做一组来进行过滤,这种情况很少用
select deptno from emp group by deptno having deptno > 10 -- ok select deptno from emp having deptno > 10 -- error -- Oracle和SQL Server是一样的,要使用having子句,都必须得先有group by子句 select max(sal) from emp having max(sal) = 5000 -- ok,结果为5000 - having子句出现的字段必须是分组之后整个组的总体信息,不能出现组内部的详细信息,这在SQL Server和Oracle中均成立
select deptno, job, avg(sal) from emp where hiredate >= '1981-05-01' group by deptno, job having sal > 1200 -- error,因为sal不是select_list中的 order by deptno, jobcreate table ST_CU ( sid int, -- 学号 cid int, -- 课程号 score float -- 分数 ) insert into ST_CU values (1,1,66.6) -- 查询学号为sid,课程为cid的学生的平均成绩 select sid, cid, avg(score) "平均分数" from ST_CU group by sid, cid -- 查询学号为sid,课程为cid的学生这门课只考了两次的平均成绩 select sid, cid, avg(score) "平均分数" from ST_CU group by sid, cid having count(score) > 2 -- 虽然select_list中没有,但是仍然正确 - 尽管select_list中字段可以出现别名,但是having子句不能出现字段的别名,只能使用字段最原始的名字,对于SQL Server和Oracle都适用
select deptno dt, job, avg(sal) as "avg_sal" from emp group by deptno, job having avg(sal) = 5000 -- ok having avg_sal = 5000 -- error having "avg_sal" = 5000 -- error having dt = 100 -- error having deptno = 10 -- ok - where和having一样,都不允许出现字段别名,只允许出现原始的字段名字
order by子句
如果不指定排序方式的话,默认是升序排序,升序用ASC表示
为某一个字段指定的排序方式并不会对另一个字段生效,强烈建议为每一个字段都指定排序方式
select * from emp order by deptno -- 按deptno升序,默认是升序
select * from emp order by deptno desc -- 按deptno降序
select * from emp order by deptno, sal desc -- 按deptno升序,再按sal降序select语句的执行顺序问题
select语句的基本结构
select语句基本结构中包含了8个子句,这些子句的排列顺序是固定的。其中除select子句外,其他子句都可省略,但若出现,则必须按照基本结构中的顺序排列
-- select语句的基本结构
select select_list
[into new_table_name]
from table_list
[where search_conditions]
[group by group_by_list]
[having search_conditions]
[order by order_list [ASC|DESC]]例子:
select deptno, avg(sal)
from emp -- 从哪张表去查询
where sal > 2000 -- 对单条记录进行过滤
group by deptno -- 对数据进行分组
having avg(sal) > 1500 -- 对分组后的数据进行过滤
order by avg(sal) desc -- 对最后的结果进行排序为什么select语句执行顺序很重要
-- 错误的代码
select deptno, avg(sal) from emp
where avg(sal) > 2000
group by deptno
-- 原因
不允许在where子句中使用分组函数实例
先执行where,后执行group by,所以执行where时对emp表还没有进行分组,因此编译时会报错select deptno, avg(sal) "平均工资", count(*) "部门人数", max(sal) "部门最高工资"
into emp_2
from emp
where sal > 2000 -- where是对原始记录过滤
group by deptno
having avg(sal) > 3000 -- 对分组之后的记录过滤select语句执行顺序
select deptno, job, avg(sal) from emp
where hiredate >= '1981-05-01'
group by deptno, job
having avg(sal) > 1200
order by deptno, job- 先执行 where hiredate >= '1981-05-01' ,只保留满足条件的记录
- group by deptno, job 对满足条件的记录先按部门编号分组,再按职称进行分组
- 接下来不是执行 having avg(sal) > 1200 子句,而是执行 select deptno, job, avg(sal) from emp,即先得到每组的部门编号、职称、每组工资平均值,即 having 子句用于过滤分组
- 再执行 having avg(sal) > 1200,只保留平均值大于1200的组的部门编号、职称、每组工资平均值
- 最后是 order by 进行显示效果的设置
注意:
- having后面只能出现 avg(sal) job deptno,不能出现其他字段或表达式
- order by后面只能出现 avg(sal) job deptno,不能出现其他字段或表达式