微软语音AI技术与微软听听文档小程序实践 | AI ProCon 2019

【导语】9 月 7 日,在CSDN主办的「AI ProCon 2019」上,微软(亚洲)互联网工程院人工智能语音团队首席研发总监赵晟、微软(亚洲)互联网工程院 Office 365资深产品经理,Office 小程序负责人张鹏共同发表《微软语音AI与微软听听小程序实践》的主题演讲,分享微软人工智能语音的技术以及微软听听小程序的落地实践。
详情如何?我们一起来看看。
以下为演讲内容:
赵晟:小程序是现在移动开发的新生态、新趋势。语音AI技术跟移动开发是非常有关系的。大家平时开车时不方便用手输入,可以用语音输入,开车时想听一些东西,完全可以用文字转语音的技术去听这些内容。基于这些考虑,微软语音AI和微软听听小程序合作做了些尝试,今天给大家分享这里面的故事。

微软语音AI的技术突破
微软在30多年前开办微软研究院时,已开始投入大量的人力物力在语音和语言上。近几年来,微软在语音识别上首先取得突破,在2016年,语音识别的准确度已达到跟人相似的水平。
2018年,在中英机器翻译上和人类做比较,发现机器翻译的质量跟专业翻译人员的结果完全可以相媲美。
2018年9月,微软首先发布了基于神经网络的语音合成产品服务,它与人声的自然度得分的比例达到98.6%,也就是说非常接近人声。

语音识别之路
微软在语音识别的具体突破有哪些?
语音识别主要核心指标是词错误率,就是词识别错误占多少比例。在SwitchBoard会话数据集上,语音识别错误率开始非常高,根本不能用,到2016年,微软取得了突破,达到5.9%的错误率,2017年进一步降低到5.1%的错误率,这个错误率跟专业人员转写录音的错误率是相当的。
大家听听这个数据集的例子:电话上有两个人在交流,语音具有不连续性、噪音、口音,所以识别难度对机器来讲是非常大的,微软使用10个神经网络技术,比如:CNN、ResNet、VGG等,多模型输出打分、多系统融合,得到了这个了不起的突破。
机器翻译的里程碑
从1980年的传统机器翻译,到1990年的统计机器翻译,再到2010年,深度学习机器翻译技术开始兴起。2018年,微软首度提出一个任务,把机器跟人在中英新闻翻译上做比较,让专业翻译人员和机器翻译同样的句子,翻译后请懂双语的老师和学生去对翻译结果用0-100分进行打分。
可以看到微软的Human Parity机器翻译系统已经超过或者接近专业人员的翻译水平。它的突破用到了新技术比如对偶学习,用大量无标注数据提高现有的翻译系统。还有推敲网络,先有一个初始翻译,再用另外一个网络进行再一次的修正,同时运用多系统融合技术,最终达到这个突破性的结果。
语音合成技术
我们再看看语音合成技术,文字转语音这个技术也是非常悠久的语音AI技术。

最开始是基于人的发音原理的合成器,然后90 年代用拼接的方法,把一句话分成很小的单元,然后进行拼接,一开始的拼接是小语料库,自然度一般。在1999年左右,出现基于大语料库的拼接,这时需要收集到成千上万的句子,把它们切分开来,用一种选择策略去选择最合适的单元拼接在一起,自然度显著提升,但是带来新的问题,比如有些拼接不平滑。
2006年左右,基于HMM模型的合成技术兴起,它的好处是非常平滑,但是也带来负作用,就是声音过于平滑,让人听出来觉得不够具有表现力。深度学习的兴起在合成领域也得到了应用,最近两三年推出的神经网络TTS,是语音合成技术的突破。谷歌提出来Tacotron, WaveNet这些模型,把语音自然度提升新的水平。
微软在2018年,2019年提出了Transformer TTS、Fast Speech等高自然度神经网络TTS模型,并在2018年9月首度推出产品化接近人声的端到端Neural TTS。
Neural TTS模型
为什么Neural TTS模型可以接近人声?
传统的TTS是一个复杂的流程,每一步都要进行单独优化,有些模块需要经验规则,人工优化权重等等。神经网络的TTS是将合成流程简化了,我们可以看到它基本就三段,有一个前端文本分析,一个声学模型,一个Neural Vocoder声码器。神经网络的声码器可以非常接近人的音质。
采用最新的基于注意力的声学模型去进行建模韵律,更加接近人声的韵律。两者叠加起来,就可以到更符合人的韵律和音质的高质量合成语音。当然,带来的负作用是计算量非常大。
神经网络TTS的架构非常具有可扩展性,各家都提出不同的声学和声码器模型,有各自的特点,有的计算量大一点,有的计算量小一点,质量也有所不同。
Neural TTS还有一个特点是迁移学习,我们可以提取条件参数,对合成进行控制,比如我们可以先训练一个多说话人的基础模型,使用几十小时到上千小时数据训练得到一个模型。有了基础模型以后可以做很多有意思的事情,比如训练我自己的声音,或者生成有情感的、多风格的、跨语言的声音,这些都可以做到。
语音服务概览
前面讲了语音的新技术突破,可能有人就会问,有这么多新技术,怎么在产品里用它?我给大家介绍语音服务有哪些功能供大家使用。
微软的语音服务基本都在微软Azure这个平台上,提供语音转文字、文字翻译等标准服务。

语音转文字有很多功能,如实时识别文字、一个人说话、多人对话、会议场景。一个典型场景是大家开会后想看会议内容,可用语音服务把语音转成文字,并且做一些自动处理的摘要,这样可快捷地查看会议内容。
目前跟人类接近的文字翻译系统已上线,神经网络模型已更新,翻译质量大幅度提升。
文字转语音我们提供神经网络 TTS、4种语言、5个声音。这些服务都可以用Rest和WebSocket SDK调用。
我们还提供语音到语音的翻译系统,比如翻译机场景,把中文语音输入进去,翻译成英文,得到语音流,可以直接播放,不用再配置其他服务,简化开发步骤。这些服务都可以在以下网址访问使用。
https://azure.microsoft.com/en-us/services/cognitive-services/speech-services/
云端模型定制服务
前面我提到的API都是标准模型,所谓标准模型就是微软几十年收集的数据做的大模型,大模型适用于大量通用的场景。但是AI有一个特点是对于不同场景相关的数据做一些自适应,可达到更好的效果。
典型的例子是有些公司里面有自己的硬件采集语音、有自己的关键词,如果有这些场景数据,可以大幅度提高语音识别准确率。我们在语音识别、翻译、合成模型上都提供定制功能,提供给各位开发者一起创建生态系统,你可以把数据放进去,打造成行业的模型,提供给客户使用。
模型定制地址:https://speech.microsoft.com/
Edge 端的语音容器
前面提到基于云端的语音服务,云端模型定制,还有一个很重要的场景是需要把AI放到离线或者私有云里面,这就是常说的Edge计算。因为这些端的计算力得到很大提高,可以跑起来复杂的模型。
包括手机端的Tensorflow都是类似的利用Edge部署的想法。我们语音服务在Edge有一个部署方案,它是基于Docker的容器,这样带来很多好处,比如安全可靠、延迟很小,充分利用现有硬件,接口和云端化部署保持一致,使用起来非常方便。
比如呼叫中心里有大量的客服语音对话,对此进行分析就可以了解服务的满意度。我们已形成了解决方案:在呼叫中心里定制模型,定制后,用于大批量处理录音,然后使用自然语言处理进行智能分析。在国内我们联合了联合利华、中国移动利用容器化的语音服务去完成这些服务。
容器可以在此申请使用:https://docs.microsoft.com/en-us/azure/cognitive-services/speech-service/speech-container-howto
Unified Speech SDK
在客户端SAPI、SpeechFX是Windows系统自带的传统开发SDK。我们现在提出了Unified SDK,支持访问云端的语音识别、语音合成、语言翻译等语音服务。这个SDK也支持容器化的语音服务和离线语音引擎,它是真正跨平台的,支持Windows、Linux、安卓、iOS、浏览器平台。SDK采用跨平台架构,提供有各种语言的绑定,中间有统一的C API,底层有跨平台的库,可以快速支持跨平台的迁移。
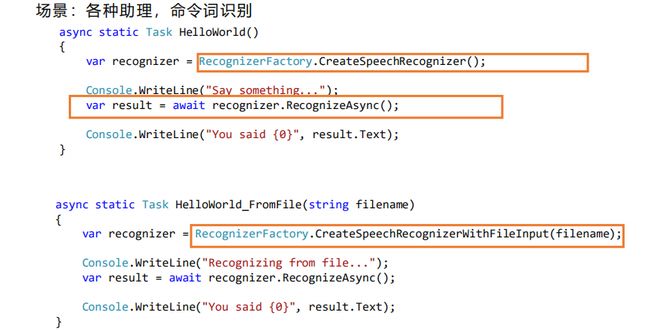
简单看几个语音识别例子,各种音箱助理要做识别,这是短句语音识别场景,你可以创建一个语音识别对象,然后异步开始识别,它是从声卡采集数据进行识别,然后把结果反馈给你。
SDK免费下载使用:https://docs.microsoft.com/en-us/azure/cognitive-services/speech-service/speech-sdk
语音合成平台
语音合成平台的使命是让每个人和组织都有喜欢的数字化声音。这个语音合成平台是既给内部客户使用,也给外部客户使用,内部客户比如像微软的语音助理用的就是同样这个语音合成平台。我们在不断迭代这个平台,在18个数据中心里都有部署,真正达到全球化的部署,出海企业可以使用我们国外的数据中心。
接下来看看基于神经网络TTS的多种风格语音。为什么要有多风格的语音?因为合成一段语音的话,文字和语音要有一定的匹配,读新闻时需要正式的声音,机器人回复的时候需要考虑上下文需要,采取带有情感的回复。我们提供了风格化的声音供大家使用,通过输入的SSML express-as标记进行风格控制,使用起来是非常容易的。
中文上我们也正在开发新的风格,比如有亲和力的助理场景,客服场景里,客服机器人的语气应该是比较热心的。有时机器人有需要一些技能,我们这个晓晓也会唱歌。另外新闻场景,需要比较正式的语气来读新闻。读微信公众号的文章不用那么正式,但是也要相对要规范。情感故事场景,大家晚上睡觉前可以听听心灵鸡汤等等。声音可以千变万化,我们根据用户的需求去定制风格,同时也有不同的音色,比如男生、老年人声音、小孩声音,这些都可以定制。
 语音合成API调用
语音合成API调用
这是语音合成API调用,创建一个合成器对象,你把文字送给它,它就可以开始合成了,这是合成到声卡。不同语言也非常类似,学习起来也非常容易。
调用API需要配置语言,我们有很多种语言,所以需要配置一下语言参数。不同的音色,声音也可以首先配置。输出格式,把语音输出到MP3压缩,也可以通过属性配置。

合成到文件保存,有时开发服务时需要把音频合成到一个流里然后转发到其他地方,那么就创建一个PullStream,后面的合成代码是一样的,可以像文件一样去读取这个合成的数据。还有一个PushStream,相当于回调的方式,不同的开发人员有不同的喜好,我们提供不同的API,方便大家使用。回调时的数据是通过回调方法来进行处理。
语音合成API也提供一些元数据,比如词边界,可以告诉你读到哪一个单词了,此外有些场景需要做口形匹配。这时注册一个事件,你可以得到这些元数据,这个功能在微软的Edge浏览器最新发布的新版本里已经用到了,朗读时文字高亮显示,供阅读者了解当前的进度。
语音助手合成
我们来看看语音助手的典型解决方案,典型场景有音箱、客服机器人、互联网车载语音、小程序集成。
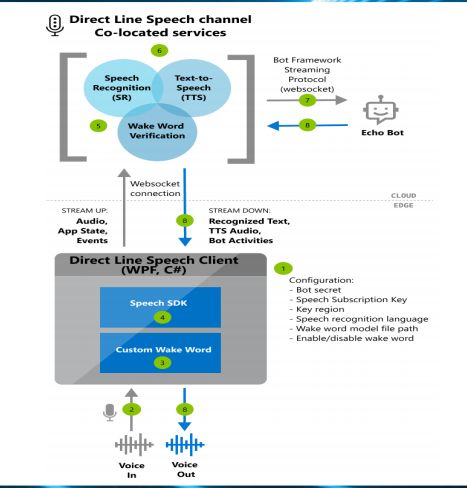
这是我们推荐的解决方案或者架构:客户端可以用语音激活,用自定义的唤醒词,比如“你好,小娜”,首先把服务唤醒,你可以采集数据通过SDK送到云端,云端有唤醒词校验,再确认一下这个唤醒是不是真的对,降低误触发,然后对音频流进行识别,识别出的文字送给机器人的服务。
这是实现松耦合的好办法,类似机器人的服务都是自然语言文字进入、文字输出,所有这样的服务可以注册到我们这个框架里来。回复文字之后回到语音服务,进行语音合成,合成的语音可以通过流式返回客户端通过SDK播放,这是整个调用流程。这个架构的优点是把云端语音服务和唤醒词放在一起,可以减少客户端调云端的次数。全双工对话也可以用类似方法实现,连接的协议是WebSocket。
更多信息可参见: https://docs.microsoft.com/en-us/azure/cognitive-services/speech-service/tutorial-voice-enable-your-bot-speech-sdk
在微信小程序里可以用类似这样的架构去做,我们在GitHub上提供了示例:
https://github.com/Azure-Samples/Cognitive-Speech-TTS/tree/master/TranslatorDemo
语音内容生产
当前现代快节奏的生活使得信息获取变得碎片化和多任务化,我们常常遇到一些痛点:传统的有声内容制作主要靠声优的录音;大量的文本内容正在等待有声化;有声内容生成受限于人员,时间,环境等因素,不能最大化产能。
那么如何提高人们的阅读效率呢?
一种很好的方式是通过听的方式消化这些信息,开车时、睡觉前都可以听一听,传统方案由人来读,这非常受到限制。有了基于神经网络的TTS,我们在想能不能提供效率更高的方案。
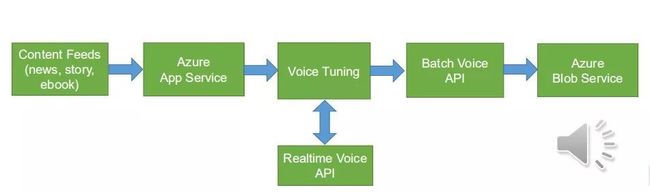
这个方案是这样工作的,各种信息流可以用云服务把它整理,送到语音调优服务,你可以选择调一下比如多音字,批处理合成API把调好的SSML合成为音频放在存储服务里,供你的应用去使用。
举一个电子书例子,这个电子书听起来更生动一点,还有角色的变化。前面说到了调音工具,TTS输入或者语音合成输入是SSML格式。我们提供界面工具可以可视化去调读音、停顿、背景音乐,一定程度上可以用它调出完全接近录音的效果。
定制语音
声音是一个品牌,每个人的声音都是自己的品牌,我们支持让每个企业都能定制自己的声音。定制语音的类型有两类:
1、自助服务开发人员通过网页或API操作、训练、部署声音,自助完成,面向个人开发者。支持三类模型的服务:
(1)基础模型:30-500句语音,比较相似,高可懂度。
(2)标准模型:3000-6000句语音,自然度比较高,接近Windows上标准模型。
(3)高质量模型:6000-8000句语音,自然度非常高,接近JessaRUS。
2、全包服务
全流程定制语音,专家工程师把控最高质量,也支持基于神经网络的定制,300句可以做到以前6000-8000句的效果。当然,对于神经网络的定制要非常小心,我们希望AI的技术不要被滥用,太像了之后人们会担心自己的声音被别人做了一个TTS,去外面打骗人的电话等等。所以需要有很严格的流程,通过客户同意才能使用。目前通过商务合作模式进行神经网络TTS定制,保证技术不被滥用。

自主服务界面接口里,可上传所有数据,我们自动进行处理,比如对读音进行检测,如果发音不标准的话训练出来的声音也不标准。数据较好的话可提交训练,后台会起一个训练流程在GPU去训练,训练之后试听效果,部署后可通过代码调用或者在网页上输文字实时测试。
模型定制也可调用API,这个API是Rest接口,在微信小程序可以调用,也可在后台调用。代码支持SWAGGER标准,可以自动生成多种语言代码。我们提供了管理数据的API,对模型进行管理的API。
做一个好声音是有技术门槛的,首先要了解你的场景需要什么样的风格、需要什么样的音色,去选择合适的风格,然后录音文本选择通用文本或者领域相关文本。
录音也是个技术活,需要尽可能安静,不要有噪音,保持录音风格,数据越好出来的质量越高。模型训练完成之后可以部署到云端或者容器,可以非常灵活的部署在各个地方。微软语音AI技术在微信小程序上有不错的实践,下面由张鹏分享听听小程序在AI的实践。
为什么是语音 AI +小程序?

张鹏
张鹏:Office 365是一套基于云平台的服务解决方案,除了大家熟悉的Office编辑工具服务外,还有邮件,社交,会话以及可视化数据与报告等,这些共同构成了一套服务,这套服务我们称之为Office 365,我们希望把Office 365带到更多中国用户使用习惯中去,第一个看重的是微信。
我们为什么要在微信里做?
有两个主要考虑的因素:
第一,微信是月活超过11亿的产品,这是任何跨国公司产品进入中国以及本土创新都必须要研究的,微信哪些功能满足了用户需求,哪些功能没有满足用户需求,因此Office 365要在中国取得成功,满足微信用户的对文档协作的需求是我们必须要做的事情。。
第二,微信沉淀了极其稳定的社交关系,基于这些社交关系可以看到你的通讯录里、各种群里已经不单是家人和朋友,看看我们微信的各种群,更多的是你的同事、客户以及上下游合作伙伴,也就是说很多群是因为工作而产生的,因此在微信里就有大量的文档在流转,我们如何让这些文档在微信生态里可以更高效的被创造出来,可以被安全的被管理,可以更顺畅且高效的传递,这是我们想在中国探索的一个方向。
第三,小程序2017年1月份诞生,市场上对小程序有各种解读,有看好的,有不看好的,我觉得任何定义现在下都为时过早。而我们看到的是小程序正在或者将要解决信息孤岛的问题,各个App之间信息不通的问题。
Office有同样的问题,很多文档内容是留在大家的PC里或者用户各种云盘里,这些信息并没有很高效的被协作起来,没有有效的途径把有价值的内容做分享。我们认为微信小程序未来正是解决这个问题的解决方案。
基于这几点,我们2018年投入到小程序里。
今天分享的小程序叫“微软听听文档”,“微软听听文档”探索的第一个问题是PPT在移动端应该是什么样子的?如何将信息更好与人协作。
我们有很多群,有很多文档在流转,然后这些文档在群里是以静态的形式在流转,很多情况下用户都是从PC端拉一个PPT扔到群里就完了,这种PPT其实是静态的Word文档。
如果将PPT下一个定义的话,突出它的主要功能就是怎样让大家演讲时更有力,提升演讲时的演示效果,这是我们移动端的目的。因此,我们打造了“微软听听文档”。
我们通过在移动端快速地给每一页文档做录音,快速发布,通过微信固有的社交关系去传播、发布。每页PPT下面除了有声音外,还有各种社交属性:传播、、发朋友圈、进群、点赞、打赏,这是我们认为PPT在移动端应该有的样子。更重要的是有人的声音,也就是演讲者的参与。
今天AI大会上我观察到有很多人会拍照发朋友圈、发到群里,这也是一种内容的分享方式,但这种分享方式并不很高效,为什么?
因为这种分享方式里缺少了最重要的因素,就是演讲者、创作者到底在PPT背后传递什么观点,通过几张图片是很难传递出来的,这是我们要打造这个产品的目的。
微软听听小程序
我们做这个探索时,关注点有:
第一,创建。我们可以给每个文档做录音,背景音乐可以通过微软AI技术去学习文字和图片,自动配背景音乐,不用大家主动去选。
第二,PPT有设计内容,Office365有AI设计灵感,未来在移动端也可以帮大家从手机相册去选择图片去制作演讲时,图片可以自动用设计功能去裁剪、排版,达到更好的效果。
第三,AutoSpeech,大家在移动端录音时,很多人不喜欢自己的声音,觉得自己的声音不好听,很多人基于环境的限制并不方便录音,我们基于深度神经网络可以将声音完美的匹配文字。
第四,Article听听文档,如果大家在行进路上或者不太方便看文字的情况下,简单的把公众号URL链接拷贝到里面,可以用几十秒时间迅速制作出来一种可以看、可以听的文本,是一种新的形式展示给大家,我们有真实企业案例就是这样用的。
在听的方面有哪些和AI结合?让听者可以更沉浸式的身临其境的去听人的分享。
1、引入字幕,字幕对辅助阅读很重要,有时大家听讲时开小差就跟不上了,字幕在这里起到非常关键的作用,通过微软的声音转文字,以字幕的形式转出来。
2、社交,点赞、转发等等。
3、PPT动画,把视频播放的东西引入进来,给大家更丰富的表现方式。
以下是语音文档的创作过程:

第一步,选择制作方式。
拥有微软帐户后可以选择文件,可以从电脑端拖一个文件里进来,也可以从手机相册里选,选择之后进入录音。
第二步,人工录音或者AI录音。
第三步,发布。
可以选择权限设置,是只给微信好友看,还是发布给整个互联网的人看,还是只给自己看,包括开启赞赏,如果觉得自己的内容有价值,期望别人打赏的话也可以开启。
第四步,查看个人页面,关注推荐。
发布之后你的作品在作品集,可以知道有多少用户关注你,知道每个分享有多少人去看去听,也方便你自己去管理你自己的内容,也可以让别人找到你去分享。
下面举一个真实例子,新民晚报。他们之前有一个问题,每天早上6点,编辑会在1小时内编辑一天24小时的新闻,7点钟有一个内审,审核通过以后,7点半就在公众号发布。
这个过程中要反复修改,不可能有人给公众号录音或者去修改,。他们现在利用以上的方式可以很快捷的嵌入小程序到公众号,我们这个小程序的速度非常快,大概十几秒的样子。AI的效率在这个场景中得到非常大的发挥和落地。
微软Office微信小程序布局
未来,微软Office微信小程序布局本地化策略有三个方向:信息输入;信息管理;信息输出。
文档怎么被创造出来,怎么被管理,怎么输出协作。这三个方向是我们想去探索的。
在我看来,什么样的小程序能够生命力很强?我们做了很多功能,但是发现反而让用户更多时间耗在这里,这样工具类的小程序时间长了,慢慢大家就不会用了,因为发现代价很大。所以从生产力小程序角度总结,只要真正能帮助用户节省时间、提高效率的生产力小程序都会有更好的生命力继续传播下去。最终让用户收益才是一切商业逻辑的起点。
大家可以在微信搜索“微软听听文档”,体验一下。
嘉宾简介:
赵晟 ,微软(亚洲)互联网工程院 人工智能语音团队首席研发总监。目前负责微软Azure语音服务的产品研发工作, 所开发的语音技术服务于微软Office、Windows、 Azure认知服务,小冰小娜以及广大的第三方开发者。曾担任微软亚洲研究院研究员,微软小娜资深研发经理。长期从事语音和语言方面的技术开发,包括语音合成,自然语言处理,语音识别等等,所负责的多语言合成项目也曾经获得微软中国杰出工程奖。
张鹏,微软(亚洲)互联网工程院 Office 365资深产品经理,Office 小程序负责人 。2013年加入微软MSN,承担MSN和必应搜索等产品设计和市场推广工作。2016年开始至今,负责Office 365在中国创新产品开发,成功发布officeplus.cn,微软AI识图,听听文档等产品发布。
◆
精彩推荐
◆

推荐阅读
肖仰华:知识图谱构建的三要素、三原则和九大策略 | AI ProCon 2019
10分钟搭建你的第一个图像识别模型 | 附完整代码
阿里披露AI完整布局,飞天AI平台首次亮相
程序员因接外包坐牢 456 天!两万字揭露心酸经历
限时早鸟票 | 2019 中国大数据技术大会(BDTC)超豪华盛宴抢先看!
Pandas中第二好用的函数 | 优雅的Apply
阿里开源物联网操作系统 AliOS Things 3.0 发布,集成平头哥 AI 芯片架构
雷声大雨点小:Bakkt「见光死」了吗?

你点的每个“在看”,我都认真当成了喜欢