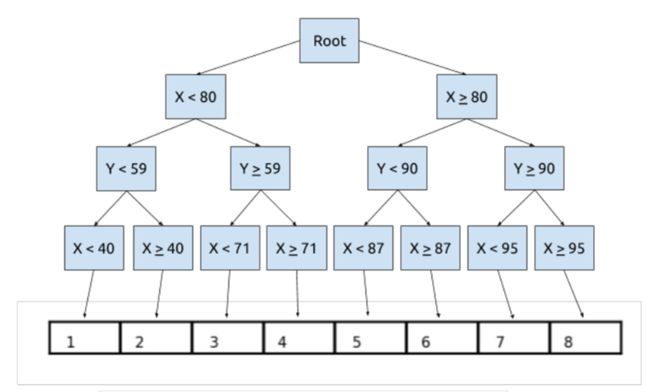
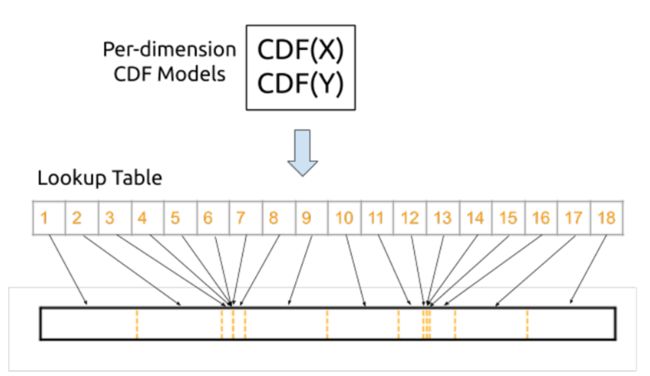
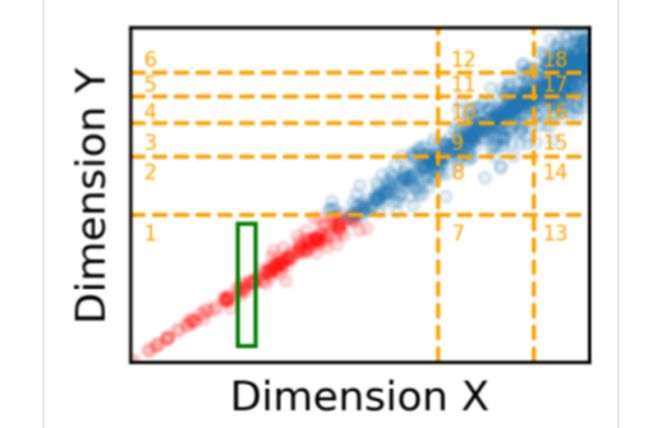
- 「感恩日语」2021-303篇,吸渣体质
能学多少学多少
学习感悟,避免成为“吸渣”体质很重要,“环境”能改变人,学会甄别那些“书籍”、那些“文章”(论文)对自己成长有利,而非“奶头乐”系统算法之类推送的让自己无法自拔的内容,个人每天、每周、每月、每年、一生总时间是有限的,缩小到每天,计算一下每天浪费有多少,真正发挥价值时间效力有多少,简单做个记录,会发现很可怕。同时找到了为什么每天进步一点点的重要性,只跟昨天的自己,前天的自己比较一下,很重要,多做对自
- zabbix自动发现告警配置
yeahzxw
监控#zabbix服务器linux运维
自动发现告警配置一、目录文件数详细配置1、编写shell自动发现脚本cd/home/yeahzxw/script/discoverdir.sh#!/bin/bashconf=/home/yeahzxw/script/conf/key_dir.cfgINDEX=0echo'{'echo'"data"':[COUNT=`cat$conf|wc-l`cat$conf|whilereadLINEDIRCO
- OpenSearch SQL 查询完整指南
OpenSearchSQL查询完整指南目录基础查询字符串查询数值查询日期时间查询数组和嵌套查询聚合查询地理空间查询全文搜索复杂查询性能优化基础查询基本SELECT--查询所有字段SELECT*FROMindex_name;--查询特定字段SELECTname,age,emailFROMusers;--使用别名SELECTnameASuser_name,ageASuser_ageFROMusers;
- 如何通过 WebSocket 接口订阅实时外汇行情数据(PHP 示例)
quant_1986
websocketphp网络协议开发语言后端网络金融
步骤1:准备工作确保已安装PHP和Composer安装WebSocket客户端库:composerrequiretextalk/websocket步骤2:编写代码订阅行情以下是最简可运行的PHP示例,订阅EUR/USD的1分钟K线数据:60]);//构造订阅请求$initMessage=["code"=>10004,"trace"=>uniqid(),"data"=>["arr"=>[["type
- 力扣 hot100 Day49
qq_51397044
Hot100leetcode算法数据结构
105.从前序与中序遍历序列构造二叉树给定两个整数数组preorder和inorder,其中preorder是二叉树的先序遍历,inorder是同一棵树的中序遍历,请构造二叉树并返回其根节点。//抄的classSolution{private:unordered_mapindex;TreeNode*myBuildTree(constvector&preorder,constvector&inord
- DeepSeek 助力 Vue3 开发:打造丝滑的日历(Calendar),日历_宠物护理示例(CalendarView01_26)
宝码香车
#DeepSeek前端vue.jsecmascriptjavascriptdeepseek
前言:哈喽,大家好,今天给大家分享一篇文章!并提供具体代码帮助大家深入理解,彻底掌握!创作不易,如果能帮助到大家或者给大家一些灵感和启发,欢迎收藏+关注哦目录DeepSeek助力Vue3开发:打造丝滑的日历(Calendar),日历_宠物护理示例(CalendarView01_26)前言本文简介:本文页面效果组件代码代码测试测试代码正常跑通,附其他基本代码编写路由\src\router\index
- DeepSeek 助力 Vue3 开发:打造丝滑的日历(Calendar),日历_植物浇水示例(CalendarView01_25)
宝码香车
#DeepSeek前端vueecmascriptjavascriptDeepSeek
前言:哈喽,大家好,今天给大家分享一篇文章!并提供具体代码帮助大家深入理解,彻底掌握!创作不易,如果能帮助到大家或者给大家一些灵感和启发,欢迎收藏+关注哦目录DeepSeek助力Vue3开发:打造丝滑的日历(Calendar),日历_植物浇水示例(CalendarView01_25)前言本文简介:本文页面效果组件代码代码测试测试代码正常跑通,附其他基本代码编写路由\src\router\index
- 前端------Filter
童小纯
前端系列---从入门到深化htmlvue
其实数组的很多函数需要的参数都是一样的arr.fun((item,index,arr)=>{item:数组的元素index:数组元素在的位置arr:整个数组})Filter是数组的一个用法,用来返回一个数组,满足特定条件的数组中的元素letarr=[1,2,3,4];letnewArr=arr.filter((item,index,arr)=>{console.log("数组元素${item}")
- 2021/1/1 星期五 晴
40b358b2b093
2020再见!跨过了这不平凡的一年,终于迎来了崭新的2021,新的一年,新的愿望,新的开始,今天是孩子们小长假的第一天,早上睡了个懒觉,醒来时,艳阳高照太的阳已经照进来了,看来今天肯定是个大晴天了,下午皓轩在写作业,趁小的睡了抓紧时间把韭菜,荠菜摘了一下,一会小家伙也跑了过来,坐在旁边和我一起摘了起来,真是长大了,能帮忙干活了,菜洗好烫好,切好把肉放进去调好了,正要准备和面的时候小的醒了,没办法只
- 《当我遇见一个人》读书心得
hebl
中原焦点团队高级五期贺变丽坚持分享第1027天2021—4—4去年十月份,我买了李雪老师的《当我遇见一个人》,当时只读了十几页,因为没有时间就放下了,今天终于把这本书读完。这是写母婴关系的一本书,对于即将成为父母的人来说,这本书是必读的教材。在书的封面上有一句话:母婴关系决定孩子的一切关系。这本书分为五个部分:一、觉察——遇见内在的婴儿;二、态度——放下评判,全然看见;三、关系——童年的沟通模式,
- 【周检视】5.0第11周 2021年第15周检视
StevenWangSH
量变带来质变很多时候会感觉进步很慢,甚至感觉倒退。看着别人飞速前进,而自己止步不前不由得焦虑万分,给自己平添了很多压力。甚至会觉得是不是走错了方向,明明是世间真理,为什么到了自己这里就不灵验了,但是坚持一段时间以后会体会到,不是没有进步,而是我们要遵循进步的规律,我们要跨越一阶一阶的台阶,那么就要在一个个的台阶上进行积累,不把该补的课补齐,是难以实现跨越的。就如同同样的世界,但是我们每个人的看法不
- MongoDB创建集合命令db.createCollection详解
ywb201314
Mongodb
完整的命令如下:db.createCollection(name,{capped:,autoIndexId:,size:,max})name:集合的名字capped:是否启用集合限制,如果开启需要制定一个限制条件,默认为不启用,这个参数没有实际意义size:限制集合使用空间的大小,默认为没有限制max:集合中最大条数限制,默认为没有限制autoIndexId:是否使用_id作为索引,默认为使用(t
- 2023让人放心的6款海外代购app下载推荐
高省APP珊珊
随着人们网购需求的越来越大,很多人也想要购买海外产品,逐渐的海外代购app出现了,那么哪款海外代购app好用呢?代购回来的东西靠谱吗?小编今天就为大家推荐几款放心的海外代购app。【高省】是一个自用省钱佣金高,分享推广赚钱多的平台,百度有几百万篇报道,也期待你的加入。高省APP,是2021年推出的平台,0投资,0风险、高省APP佣金更高,模式更好,终端用户不流失。珊珊导师高省邀请码666123,注
- 2021年2月3日,周三,天气晴,杭州6~17°
是朱朱呀
今天3号了,一般公司就两种情况:一:年底了,很多事情都差不多落实、处理完了,只剩下一些需要处理的个别事情。二:年底了,赶项目赶项目,抓紧上线,忙忙忙我所在单位属于第一种,我男票单位属于第二种,年前这几天程序要抓紧写好,能早点测试就早点测试,每天上班时间都没有时间摸鱼的那种。和我形成了鲜明的对比,我这个周应该算是比较清闲的。我还有一个问题,我和我男票都在杭州上班,非浙江户口、单位也在杭州缴纳了社保,
- mongodb创建集合命令db.createCollection详解
weixin_34209851
数据库pythonshell
mongodb创建集合命令db.createCollection详解完整的命令如下:db.createCollection(name,{capped:,autoIndexId:,size:,max})name:集合的名字capped:是否启用集合限制,如果开启需要制定一个限制条件,默认为不启用size:限制集合使用空间的大小,默认为没有限制max:集合中最大条数限制,默认为没有限制autoInde
- mysql创建集合collection_MongoDB创建集合命令db.createCollection详解
kokosK
MongoDB创建集合命令db.createCollection详解完整的命令如下:db.createCollection(name,{capped:,autoIndexId:,size:,max})name:集合的名字capped:是否启用集合限制,如果开启需要制定一个限制条件,默认为不启用,这个参数没有实际意义size:限制集合使用空间的大小,默认为没有限制max:集合中最大条数限制,默认为没
- 2021-08-05
Bemyselfqueen
人生在世,别留遗憾时间无情第一,它才不在乎你是否是个孩子,你要是稍稍一耽搁,稍一犹豫,它立马帮你决定故事的结局——题记天空还未放明,刚下过阴雨的傍晚,水泥铺的小路因年久积起的小坑洼的水末秋的风吹的它泛起阵阵波澜,泛着微微的光芒,甚是迷人,凌乱的思绪悄然平静,打开心门那落满尘埃而又陈旧的窗棂。让她想起来孩时奶奶因她淘气玩水弄湿衣服而追得她满巷跑的情景来,多让人怀念啊!记得小学放学时她可喜欢去奶奶的地
- 关于JS中回调函数的个人理解
Jack_陈
近期在看到jQuery中test(index,test)的用法涉及到回调函数,之前未有涉及,于今晚专门看看了看,将个人对于回调函数的理解感悟记录一下,有不正确的地方希望指出。回调函数(callback),英文中的解释其实更容易理解:Acallbackisafunctionthatispassedasanargumenttoanotherfunctionandisexecutedafteritspa
- python 连接数据库
小鱼拉灯
mysql数据库python
一.连接MYSQL1.下载PyMySql模块2.在MYSQL中创建数据库并连接importpymysqlconn=pymysql.connect(host='localhost',user='root',password='123456',database='ikun',charset='utf8',port=3306)3.创建表importpymysqlconn=pymysql.connect(
- pip路径设置
更改pip默认下载路径Windows系统:直接在user目录中创建一个pip目录,如:C:\Users\xx\pip,并新建文件pip.ini文件,pip文件内容如下:[global]index-url=https://pypi.tuna.tsinghua.edu.cn/simple[install]trusted-host=mirrors.aliyun.com引用:https://www.cnb
- 【开源项目】实测 Google 开源的 AI MCP 数据库网关:10行代码隔离风险,连接池自动复用
1.引言这两天试了谷歌新开的MCPToolboxforDatabases,它用不到10行代码就能让AI助手(比如LangChain智能体)安全地操作数据库。作为一个常年和数据库连接池、凭证泄露搏斗的开发者,这东西确实解决了我的痛点——把数据库访问抽象成“工具”,通过集中管控的MCPServer隔离风险,还自带性能优化。下面分享实测体验和避坑指南。2.正文2.1核心逻辑:为什么需要MCP?传统AI代
- 2021-9-24每日检视Day307
洒脱转身
每日检视307/365起床:6:20就寝:11:20天气:晴心情:平静纪念日:叫我起床的不是闹钟是梦想2021年度目标年度(2020.11.20-2021.11.20)目标及关键点:在平衡健康、家庭、工作、生活、兴趣、个人发展的基础上,提升情商和财商,重点发展记忆竞技能力,让每一天都成为一部杰作。健康:①身材曲线——香肩美背,腹部肌肉紧实,臀部微翘②神态:眼睛有神,笑容亲和③健身房每周不少于4次。
- jxORM--整体说明
jxandrew
jxWebUI数据库pythonORM
系列文章目录:jxORMI–编程指南jxORM是配套jxWebUI使用的数据库操作库。使用说明jxORM的使用非常简单,主要包括几个步骤:1、导入依赖fromjxORMimportjxORMLogger,ORM,DBDataType,ColType,jxDB2、设置数据库连接#用默认设置,设置本地的mysql数据库连接jxDB.set('testDB',password='password')目前
- 2021-12-19
明月青苔
这两天都得监考,昨天四级,今天A级。别的系监考老师是轮流安排,我们系总是全员安排,要有不可抗力因素才能请假。谁愿意监考呢?学校去年的监考费都没发。想起有些男老师开的玩笑,说是被“强监”的。星期五的考务会上,领导说这次监考有新政策:监得不好的要进入期末考核扣分,监得好的要表扬加分。新来的杜老师说,第一次监考有些紧张。我说,紧张啥,都是义务劳动。
- python venv不适合变更路径(路径变更)的几种解决方案(venvpack、pip download、pip install --no-index --find-links=packages)
文章目录**为什么会出现路径问题?**1.**`pyvenv.cfg`文件**:该文件记录了虚拟环境的Python解释器路径(`home`字段)。如果源和目标机器的Python安装路径不一致,虚拟环境将无法找到正确的解释器。2.**脚本路径硬编码**:虚拟环境中的激活脚本(如`activate`)和可执行文件(如`python`)可能包含绝对路径或硬编码的相对路径,导致路径不匹配时失效。**解决方
- 读《品格之路》笔记(2021年11月16日)。
敏于事而慎于言
今天阅读了本书第三章内容,主题为:自我控制——从暴脾气的火药桶到杰出的美国总统。这一章的主角是德怀特.艾森豪威尔——美国五星上将,二战时期欧洲盟军最高司令,后成为美国第34任总统。有意思的是,在他当选总统半年后,签订了《朝鲜停战协定》——这件事情与中国关系密切。读了这一章,我觉得主角还应该包括艾森豪威尔的母亲艾达.斯托弗.艾森豪威尔。正是在这个充满活力、自信乐观、诙谐风趣的女人的教导下,才有了德怀
- 西门子WinCC Unified服务器硬件要求
D-海漠
其他
WindowsServer2019Standard(标准版)是微软推出的服务器操作系统WindowsServer2019的三个主要版本之一(另两个为Datacenter数据中心版和Essentials基础版)。它定位于满足中小企业或轻量级虚拟化需求的场景,在功能完整性与成本之间提供平衡。以下是其核心特性的详细解析:一、定义与核心定位基础架构角色:作为物理服务器或轻量虚拟化环境的核心操作系统,支持A
- 2021-02-05
桂亘
昨天做到了早晨5点起床,感觉精神状态还不错,证明了每天4点起床那本书讲的有一定道理。问题是早睡有困难。所以,这两天我试着将作息时间作一定的调整,就是每天晚上九点过点睡觉,争取在十点左右进入睡眠状态,这样,可以在每天五点左右起床。这样睡眠时间也可以在7个小时左右。只是工作上每天都很忙,看来这个岗位是难得调整了,只得干下去。要怎么应对这么多的工作呢,也只能超前计划,尽量往前赶。因为明天又不知道会增加什
- DPDK(25.03) 零基础配置笔记
_Chipen
DPDK计算机网络
DPDK零基础配置笔记DPDK(DataPlaneDevelopmentKit,数据面开发工具包)是一个高性能数据包处理库,主要用于绕过Linux内核网络协议栈,直接在用户空间对网卡收发的数据进行操作,以此实现极高的数据吞吐。DPDK的核心价值是:使用轮询+巨页内存+用户态驱动,提升网络收发性能。适用场景:高频交易、软件路由器、防火墙、负载均衡器等对网络性能要求极高的系统。基本数据简要解释igb_
- 2021-12-26
逸风雨无阻
喜欢,大概是这个世界上,最独断最没有道理的事了,不是权衡利弊,不是见色起意,而是突然间有了一个你让我牵肠挂肚,割舍不下。你是我安稳岁月里的节外生枝,是我平淡生活里的日月星辰。不管是清晨的日出,还是正午的小憩,又或是漫天星辰的夜晚,我都想和你一起度过。别怀疑我为什么爱你,就像云恋着风风恋着雨,其实我也不太懂这是什么道理,我想这就好像呼吸,不用练习,只因为是你。遇见你是故事的开始,走到底是余生的欢喜。
- SAX解析xml文件
小猪猪08
xml
1.创建SAXParserFactory实例
2.通过SAXParserFactory对象获取SAXParser实例
3.创建一个类SAXParserHander继续DefaultHandler,并且实例化这个类
4.SAXParser实例的parse来获取文件
public static void main(String[] args) {
//
- 为什么mysql里的ibdata1文件不断的增长?
brotherlamp
linuxlinux运维linux资料linux视频linux运维自学
我们在 Percona 支持栏目经常收到关于 MySQL 的 ibdata1 文件的这个问题。
当监控服务器发送一个关于 MySQL 服务器存储的报警时,恐慌就开始了 —— 就是说磁盘快要满了。
一番调查后你意识到大多数地盘空间被 InnoDB 的共享表空间 ibdata1 使用。而你已经启用了 innodbfileper_table,所以问题是:
ibdata1存了什么?
当你启用了 i
- Quartz-quartz.properties配置
eksliang
quartz
其实Quartz JAR文件的org.quartz包下就包含了一个quartz.properties属性配置文件并提供了默认设置。如果需要调整默认配置,可以在类路径下建立一个新的quartz.properties,它将自动被Quartz加载并覆盖默认的设置。
下面是这些默认值的解释
#-----集群的配置
org.quartz.scheduler.instanceName =
- informatica session的使用
18289753290
workflowsessionlogInformatica
如果希望workflow存储最近20次的log,在session里的Config Object设置,log options做配置,save session log :sessions run ;savesessio log for these runs:20
session下面的source 里面有个tracing
- Scrapy抓取网页时出现CRC check failed 0x471e6e9a != 0x7c07b839L的错误
酷的飞上天空
scrapy
Scrapy版本0.14.4
出现问题现象:
ERROR: Error downloading <GET http://xxxxx CRC check failed
解决方法
1.设置网络请求时的header中的属性'Accept-Encoding': '*;q=0'
明确表示不支持任何形式的压缩格式,避免程序的解压
- java Swing小集锦
永夜-极光
java swing
1.关闭窗体弹出确认对话框
1.1 this.setDefaultCloseOperation (JFrame.DO_NOTHING_ON_CLOSE);
1.2
this.addWindowListener (
new WindowAdapter () {
public void windo
- 强制删除.svn文件夹
随便小屋
java
在windows上,从别处复制的项目中可能带有.svn文件夹,手动删除太麻烦,并且每个文件夹下都有。所以写了个程序进行删除。因为.svn文件夹在windows上是只读的,所以用File中的delete()和deleteOnExist()方法都不能将其删除,所以只能采用windows命令方式进行删除
- GET和POST有什么区别?及为什么网上的多数答案都是错的。
aijuans
get post
如果有人问你,GET和POST,有什么区别?你会如何回答? 我的经历
前几天有人问我这个问题。我说GET是用于获取数据的,POST,一般用于将数据发给服务器之用。
这个答案好像并不是他想要的。于是他继续追问有没有别的区别?我说这就是个名字而已,如果服务器支持,他完全可以把G
- 谈谈新浪微博背后的那些算法
aoyouzi
谈谈新浪微博背后的那些算法
本文对微博中常见的问题的对应算法进行了简单的介绍,在实际应用中的算法比介绍的要复杂的多。当然,本文覆盖的主题并不全,比如好友推荐、热点跟踪等就没有涉及到。但古人云“窥一斑而见全豹”,希望本文的介绍能帮助大家更好的理解微博这样的社交网络应用。
微博是一个很多人都在用的社交应用。天天刷微博的人每天都会进行着这样几个操作:原创、转发、回复、阅读、关注、@等。其中,前四个是针对短博文,最后的关注和@则针
- Connection reset 连接被重置的解决方法
百合不是茶
java字符流连接被重置
流是java的核心部分,,昨天在做android服务器连接服务器的时候出了问题,就将代码放到java中执行,结果还是一样连接被重置
被重置的代码如下;
客户端代码;
package 通信软件服务器;
import java.io.BufferedWriter;
import java.io.OutputStream;
import java.io.O
- web.xml配置详解之filter
bijian1013
javaweb.xmlfilter
一.定义
<filter>
<filter-name>encodingfilter</filter-name>
<filter-class>com.my.app.EncodingFilter</filter-class>
<init-param>
<param-name>encoding<
- Heritrix
Bill_chen
多线程xml算法制造配置管理
作为纯Java语言开发的、功能强大的网络爬虫Heritrix,其功能极其强大,且扩展性良好,深受热爱搜索技术的盆友们的喜爱,但它配置较为复杂,且源码不好理解,最近又使劲看了下,结合自己的学习和理解,跟大家分享Heritrix的点点滴滴。
Heritrix的下载(http://sourceforge.net/projects/archive-crawler/)安装、配置,就不罗嗦了,可以自己找找资
- 【Zookeeper】FAQ
bit1129
zookeeper
1.脱离IDE,运行简单的Java客户端程序
#ZkClient是简单的Zookeeper~$ java -cp "./:zookeeper-3.4.6.jar:./lib/*" ZKClient
1. Zookeeper是的Watcher回调是同步操作,需要添加异步处理的代码
2. 如果Zookeeper集群跨越多个机房,那么Leader/
- The user specified as a definer ('aaa'@'localhost') does not exist
白糖_
localhost
今天遇到一个客户BUG,当前的jdbc连接用户是root,然后部分删除操作都会报下面这个错误:The user specified as a definer ('aaa'@'localhost') does not exist
最后找原因发现删除操作做了触发器,而触发器里面有这样一句
/*!50017 DEFINER = ''aaa@'localhost' */
原来最初
- javascript中showModelDialog刷新父页面
bozch
JavaScript刷新父页面showModalDialog
在页面中使用showModalDialog打开模式子页面窗口的时候,如果想在子页面中操作父页面中的某个节点,可以通过如下的进行:
window.showModalDialog('url',self,‘status...’); // 首先中间参数使用self
在子页面使用w
- 编程之美-买书折扣
bylijinnan
编程之美
import java.util.Arrays;
public class BookDiscount {
/**编程之美 买书折扣
书上的贪心算法的分析很有意思,我看了半天看不懂,结果作者说,贪心算法在这个问题上是不适用的。。
下面用动态规划实现。
哈利波特这本书一共有五卷,每卷都是8欧元,如果读者一次购买不同的两卷可扣除5%的折扣,三卷10%,四卷20%,五卷
- 关于struts2.3.4项目跨站执行脚本以及远程执行漏洞修复概要
chenbowen00
strutsWEB安全
因为近期负责的几个银行系统软件,需要交付客户,因此客户专门请了安全公司对系统进行了安全评测,结果发现了诸如跨站执行脚本,远程执行漏洞以及弱口令等问题。
下面记录下本次解决的过程以便后续
1、首先从最简单的开始处理,服务器的弱口令问题,首先根据安全工具提供的测试描述中发现应用服务器中存在一个匿名用户,默认是不需要密码的,经过分析发现服务器使用了FTP协议,
而使用ftp协议默认会产生一个匿名用
- [电力与暖气]煤炭燃烧与电力加温
comsci
在宇宙中,用贝塔射线观测地球某个部分,看上去,好像一个个马蜂窝,又像珊瑚礁一样,原来是某个国家的采煤区.....
不过,这个采煤区的煤炭看来是要用完了.....那么依赖将起燃烧并取暖的城市,在极度严寒的季节中...该怎么办呢?
&nbs
- oracle O7_DICTIONARY_ACCESSIBILITY参数
daizj
oracle
O7_DICTIONARY_ACCESSIBILITY参数控制对数据字典的访问.设置为true,如果用户被授予了如select any table等any table权限,用户即使不是dba或sysdba用户也可以访问数据字典.在9i及以上版本默认为false,8i及以前版本默认为true.如果设置为true就可能会带来安全上的一些问题.这也就为什么O7_DICTIONARY_ACCESSIBIL
- 比较全面的MySQL优化参考
dengkane
mysql
本文整理了一些MySQL的通用优化方法,做个简单的总结分享,旨在帮助那些没有专职MySQL DBA的企业做好基本的优化工作,至于具体的SQL优化,大部分通过加适当的索引即可达到效果,更复杂的就需要具体分析了,可以参考本站的一些优化案例或者联系我,下方有我的联系方式。这是上篇。
1、硬件层相关优化
1.1、CPU相关
在服务器的BIOS设置中,可
- C语言homework2,有一个逆序打印数字的小算法
dcj3sjt126com
c
#h1#
0、完成课堂例子
1、将一个四位数逆序打印
1234 ==> 4321
实现方法一:
# include <stdio.h>
int main(void)
{
int i = 1234;
int one = i%10;
int two = i / 10 % 10;
int three = i / 100 % 10;
- apacheBench对网站进行压力测试
dcj3sjt126com
apachebench
ab 的全称是 ApacheBench , 是 Apache 附带的一个小工具 , 专门用于 HTTP Server 的 benchmark testing , 可以同时模拟多个并发请求。前段时间看到公司的开发人员也在用它作一些测试,看起来也不错,很简单,也很容易使用,所以今天花一点时间看了一下。
通过下面的一个简单的例子和注释,相信大家可以更容易理解这个工具的使用。
- 2种办法让HashMap线程安全
flyfoxs
javajdkjni
多线程之--2种办法让HashMap线程安全
多线程之--synchronized 和reentrantlock的优缺点
多线程之--2种JAVA乐观锁的比较( NonfairSync VS. FairSync)
HashMap不是线程安全的,往往在写程序时需要通过一些方法来回避.其实JDK原生的提供了2种方法让HashMap支持线程安全.
- Spring Security(04)——认证简介
234390216
Spring Security认证过程
认证简介
目录
1.1 认证过程
1.2 Web应用的认证过程
1.2.1 ExceptionTranslationFilter
1.2.2 在request之间共享SecurityContext
1
- Java 位运算
Javahuhui
java位运算
// 左移( << ) 低位补0
// 0000 0000 0000 0000 0000 0000 0000 0110 然后左移2位后,低位补0:
// 0000 0000 0000 0000 0000 0000 0001 1000
System.out.println(6 << 2);// 运行结果是24
// 右移( >> ) 高位补"
- mysql免安装版配置
ldzyz007
mysql
1、my-small.ini是为了小型数据库而设计的。不应该把这个模型用于含有一些常用项目的数据库。
2、my-medium.ini是为中等规模的数据库而设计的。如果你正在企业中使用RHEL,可能会比这个操作系统的最小RAM需求(256MB)明显多得多的物理内存。由此可见,如果有那么多RAM内存可以使用,自然可以在同一台机器上运行其它服务。
3、my-large.ini是为专用于一个SQL数据
- MFC和ado数据库使用时遇到的问题
你不认识的休道人
sqlC++mfc
===================================================================
第一个
===================================================================
try{
CString sql;
sql.Format("select * from p
- 表单重复提交Double Submits
rensanning
double
可能发生的场景:
*多次点击提交按钮
*刷新页面
*点击浏览器回退按钮
*直接访问收藏夹中的地址
*重复发送HTTP请求(Ajax)
(1)点击按钮后disable该按钮一会儿,这样能避免急躁的用户频繁点击按钮。
这种方法确实有些粗暴,友好一点的可以把按钮的文字变一下做个提示,比如Bootstrap的做法:
http://getbootstrap.co
- Java String 十大常见问题
tomcat_oracle
java正则表达式
1.字符串比较,使用“==”还是equals()? "=="判断两个引用的是不是同一个内存地址(同一个物理对象)。 equals()判断两个字符串的值是否相等。 除非你想判断两个string引用是否同一个对象,否则应该总是使用equals()方法。 如果你了解字符串的驻留(String Interning)则会更好地理解这个问题。
- SpringMVC 登陆拦截器实现登陆控制
xp9802
springMVC
思路,先登陆后,将登陆信息存储在session中,然后通过拦截器,对系统中的页面和资源进行访问拦截,同时对于登陆本身相关的页面和资源不拦截。
实现方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23