Python数据分析1-NumPy入门和实战
目录
1.1ndarry数组
1.1.1创建ndarray数组
1.zeros函数
2.ones函数
3.empty函数
4.arange函数
1.1.2ndarray对象属性
1.1.3ndarray数据类型
1.1.4数组变换
1.数组重塑
2.数据合并
3.数组拆分
4.数组转置和轴对换
1.1.5NumPy的随机数函数
2.2数组的索引和切片
2.2.1数组的索引
2.2.2数组的切片
2.2.3布尔型索引
2.2.4花式索引
2.3数组的运算
2.3.1数组和标量间的运算
2.3.2通用函数
2.3.3条件逻辑运算
2.3.4统计运算
2.3.5布尔型数组运算
2.3.6排序
2.3.7集合运算
2.3.8线性代数
2.4数组的存取
2.4.1数组的存取
2.4.2数组的读取
2.5综合实例-图像变换
Numpy库是用于科学计算的一个开源Python托充程序库,是其他数据分析包的基础包,他为Python提供了高性能数组与矩阵运算处理能力。本节将讲解多维数组的创建及其基本属性、数组的切片和索引方法、数组的运算与存取等内容。最后还有案例。
1.1ndarry数组
Numpy库为Python带来了真正的ndarry多维数组功能。ndarray对象是一个快速而灵活的数据集容器。本节主要学习ndarray多维数组的创建方法、数组的属性和数组中的简单操作等内容。
1.1.1创建ndarray数组
通过NumPy库的array函数,即可轻松的创建ndarray数组。NumPy库能将序列数据(列表、元组、数组或其他序列类型)转换为ndarray数组
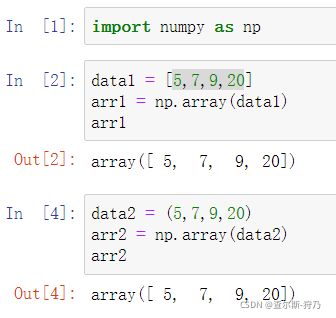
对于多维数组的创建,使用嵌套序列数据即可完成,这时我们可以数" [ " 来确定是几维数组,下列括号第一个括号后面两个“ [ ”那么这就是一个二维数组。

通常来讲,ndarray是一个通用的同构数据容器,即其中的所有元素都需要是相同的类型,当创建好一个ndarray数组时,同时会在内存中存储ndarray的shape和dtype。shape是ndarray维度大小的元组,dtype是解释说明ndarray数据类型的对象。下面数组arr3的shape的意思是2行3列,dtype的意思是int32类型。

在创建数组时,NumPy会为新建的数组推断出一个合适的数据类型,并保存在dtype对象中,如下图。当序列中有整数和浮点数时,NumPy会把数组的dtype定义为浮点数类型数据。

除了可以使用np.array创建数组外,NumPy库还有一些函数可创建一些特殊的数组,下面就简单介绍几个常用的数组创建函数。
1.zeros函数
zeros函数可以创建指定长度或形状的全0数组,如下图

2.ones函数
ones函数可以创建指定长度或形状全1数组,如下图

3.empty函数
empty函数可以创建一个没有具体值的数组(垃圾值),如下图创建的是2个2行3列的数组。
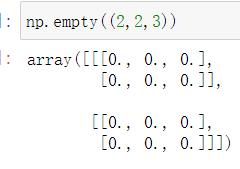
注意:数据的基本类型基本都是float64类型。
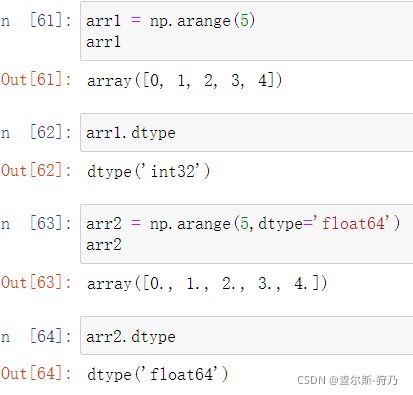
4.arange函数
arange函数类似于Python的内置函数range,但是arange函数主要用于创建数组,如下图

更多数组创建函数,如下表
| 函数 | 使用说明 |
| arange |
类似于内置range函数,用于创建数组 |
| ones | 创建指定长度或形状的全1数组 |
| one_like | 以另一个数组为参考,根据其形状和dtype创建全1数组 |
| zeros、zeros_like | 类似于ones、ones_like,创建0数组 |
| empty、empty_like | 同上,创建没有具体值的数 |
| eye、identity | 创建正方形的N*N单位矩阵数值或0或1 |
这里再介绍以下ones_like函数的用法,如下图

1.1.2ndarray对象属性
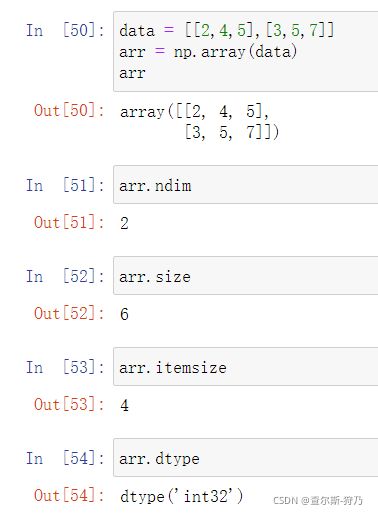
Numpy创建的ndarray对象属性,如下表
| 属性 | 使用说明 |
| .ndim | 秩,即数据轴的个数(个人来看这才是数组的维度) |
| .shape | 反应几行几列 |
| .size | 元素的总数 |
| .dtype | 数据类型 |
| .itemsize | 数组中每个元素字节大小 |
对于shape和dtype属性在前面已经说过了,这里看下其他属性的使用,如下图
arr数组的类型数据是int32位,对于计算机而言,1个字节是8位,所以arr的itemsize属性值为4
1.1.3ndarray数据类型
由前面内容得知:在创建数组时,NumPy会为新建的数组推断出一个合适的数据类型。同样,也恶意通过dtype给创建的数组指定数据类型,如下图
数组的数据类型有很多,我们只需要记住最常见的几种数据类型就行,如浮点数(float)、整数(int)、复数(complex)、布尔值(bool)、字符串(string_)和Python对象(object)
对于创建好的ndarray,可以通过astype方法进行数据类型的转换,如下图
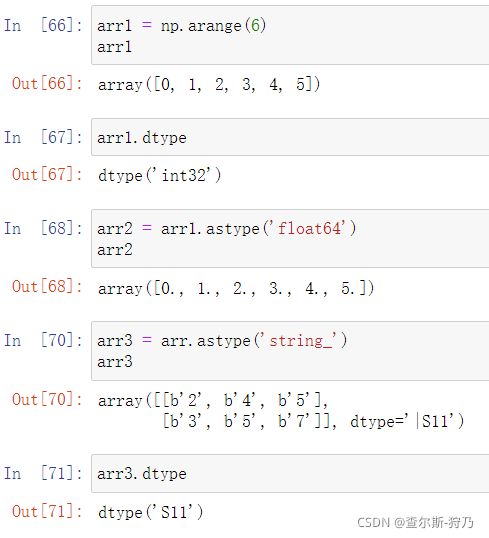
注:np.float64和“float64”都可以完成操作
如果将浮点数转换为整数,并不会使用四舍五入的方式来转换,二十元素的小数部分被截断如下图

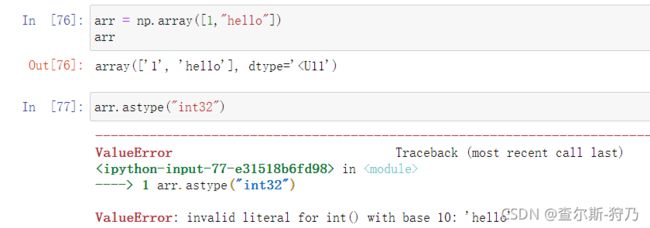
如果数组是字符串类型且全是数字的话,也可以通过astype方法将其转换为数值类型

但如果字符串中有字符时,转换时就会报错,如下图
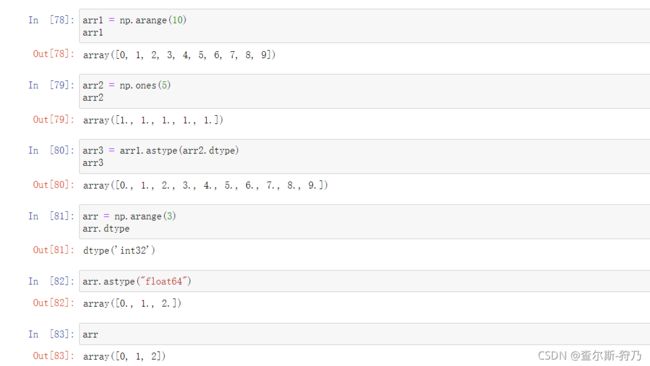
 astype方法也可以通过另外一个数组的dtype进行转换,如下图,astype方法会创建一个新的数组,并不会改变原有数组的数据类型。
astype方法也可以通过另外一个数组的dtype进行转换,如下图,astype方法会创建一个新的数组,并不会改变原有数组的数据类型。
1.1.4数组变换
1.数组重塑
对于定义好的数组,可以通过reshape方法改变其数组的维度。传入的新参数为新维度的元组

对多维数组也可以被重塑

还可以低纬度向高维度转换

reshape的参数的一维参数,可以设置为-1,表示数组的维度可以通过数据本身来推断。

与reshape相反的方法是数据散开(ravel)数据或扁平化(flatten)如下图

2.数据合并
数据合并用于几个数组间的操作,concatenate方法通过指定轴方向,及那个多个数组合并在一起。
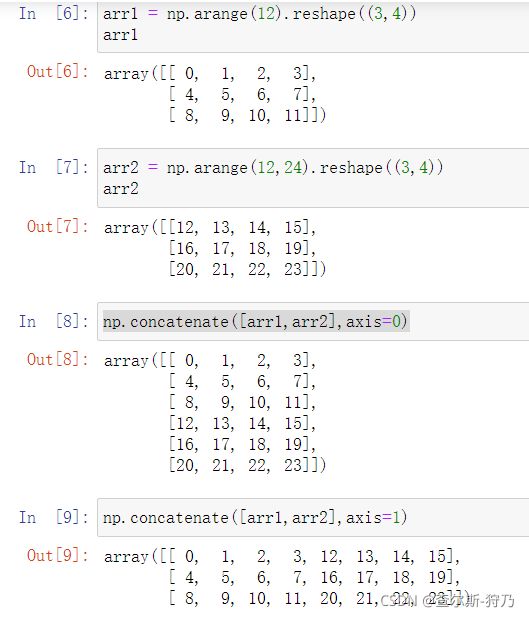
此外,Numpy中提供了几个比较简单移动的方法,也可以进行数组合并,如vstack和hstack如下图

3.数组拆分
数组拆分是数组合并的反向操作,通过split方法可以将数组拆分为多个数组,如下图

4.数组转置和轴对换
转置是重塑的一种特殊形式,可以通过transpose方法进行转置。transpose需要传入轴编号组成的元组,这样就完成了数组的转置。除了使用transpose方法外,数组有着T属性,可用于数组的转置。如下图

ndarray的swapaxes方法用于轴对换1.

1.1.5NumPy的随机数函数
在numpy.random模块中,提供了多种随机数生成函数。例如,可以通过randint函数生成随机整数如下图

random模块中还提供了一些概率分布的样本值函数,如randn函数,例如生成平均数为0,标准差为1的正态分布随机数如下图

通过normal函数生成指定均值和标准差的正态分布的数组。如下图

下表给出了部分numpy.random模块中的随机数函数
| 函数 | 使用说明 |
| rand(x,y,z) 几个几行几列 | 产生均匀分布的样本值 |
| randint(low,highsize) 取值+几行几列 | 给定范围内去随机整数 |
| randn(x,y,z) | 产生正态分布的样本值 |
| seed(x,y,z) | 随机数种子 |
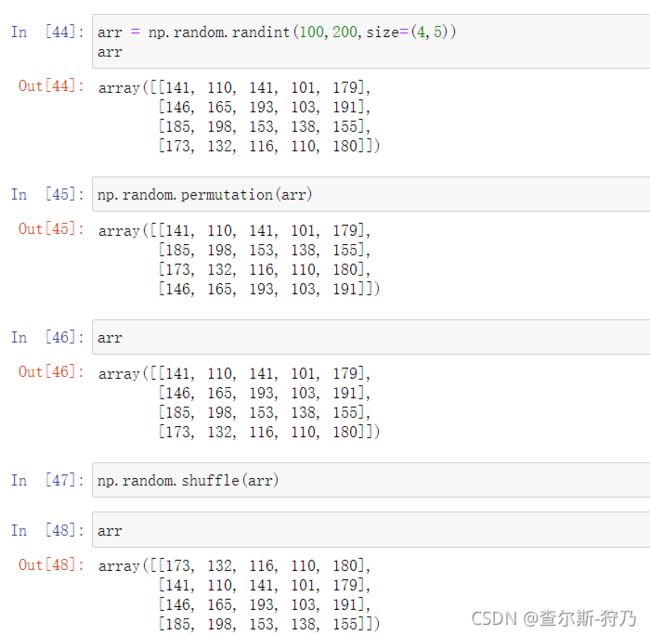
| permutation(arr) | 对一个序列随机排序,不改变原数组 |
| shuffle(arr) | 对一个序列随机排列改变原数组 |
| uniform(low,high,size) | 产生具有均匀分布的数组,low表示起始值,high表示结束值,size表示形状 |
| normal(loc,scale.size) |
产生具有正太分布的数组,loc表示均值,scale表示标准差 |
| poisson(lam,size) | 产生具有泊松分布的数组,lam表示随机时间发生率 |
下面看看permutation和shuffle函数的用法,如下图
2.2数组的索引和切片
在数据分析中长需要选取符合条件的数据,本节主要讲解数组的索引和切片方法,并学会数组的灵活选择
2.2.1数组的索引
一堆数组的索引类似Python列表,如下图

从代码中可以看出,数组的切片返回的是原始数组的视图。简单的说,视图就是原始数组的表现形式,切片操作并不会产生新数据,这就意味着在视图上的操作都会使原始数据发生改变如下图

注:数组的切片和索引返回都是原始数组的视图
如果需要的并非视图而是要复制数据,则可以通过copy方法来实现,如下图

对于二维数组,可在单个或多个轴向上完成切片,也可以跟整数索引一起混合使用如下图

三维数组

变量值和数组都可以赋值给arr[0],如下图

2.2.2数组的切片
一维数组的切片同样类似于Pyhton列表如下图
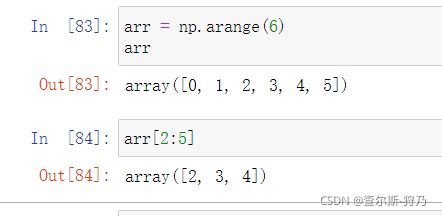
多维数组的切片是按照轴方向进行的,当在中括号输入一个参数是,数据就会按照0轴(也就是第一轴)方向进行切片如下图

通过传入多个参数(可以是整数索引和切片),即可完成任意数据的获取,如图所示

2.2.3布尔型索引
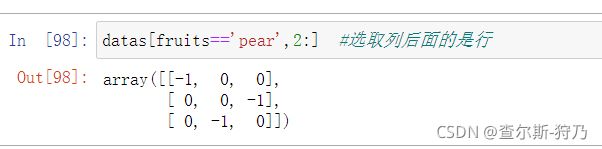
创建两个数组,如果每个水果对应datas数组中的每一行,我们要去除“pear”对应的datas的行,这时就需要用到布尔选择器如下图
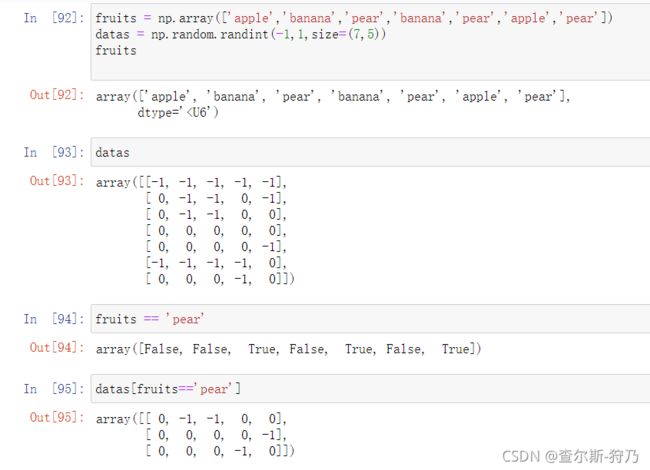
注:布尔型数组的长度必须和被索引的轴长度一致
既然可以使用不二选择,那么也同样适用于不等号(!=)、符号(-)、和(&)、或(|)如下图
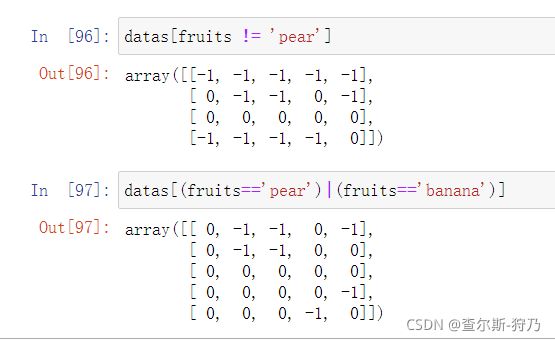
此外,布尔数组也可以结合切片和索引来使用
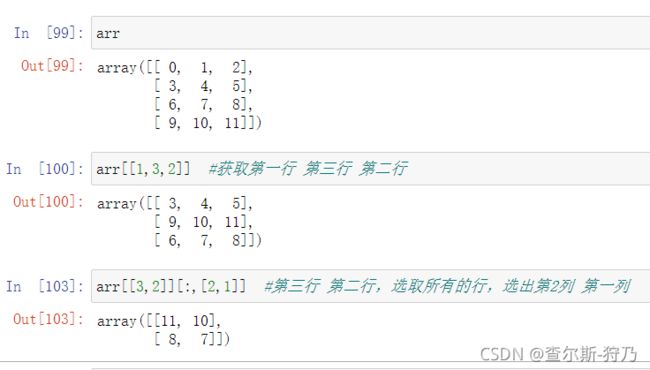
2.2.4花式索引
花式索引是NumPy中的术语,它可以通过整数列表或数组进行索引,如图
2.3数组的运算
数组的运算支持向量化运算,将本来需要在Python级别进行的循环,放到C语言的运算中,明显的提高了程序运算速度。
2.3.1数组和标量间的运算
数组之所以很强大而且重要的原因,是其不需要通过循环就可以完成批量计算,也就是矢量化。如下图。

相同维度的数组的运算都可以直接应用到元素中,也就是元素级运算

2.3.2通用函数
通用函数(ufunc)是一种对数组中的数据执行元素级运算的函数,用法也很简单。例如,通过abs函数求绝对值,square函数平方。如下图

以上函数都是传入一个数组,所以这些函数都是一元函数。有些函数需要传入两个数组并返回一个数组,这写函数被称为二元函数。例如,add函数用于两个数组的相加,minimum函数可以计算元素最小值,如下图

有些函数还可以返回两个数组,例如modf函数,可以返回数组元素的小数和整数部分,如下图

2.3.3条件逻辑运算
首先创建三个数组
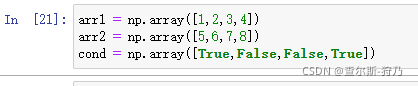
如果需要通过cond的值来选取arr1和arr2的值,当cond为True时,选择arr1的值,否则选择arr2的值,那么可以通过if语句判断来实现。

但这种方法存在两个问题:第一,对大规模数组处理速度不是很快:第二,无法用于多维数组。若使用Numpy的where函数则可以解决这两个问题
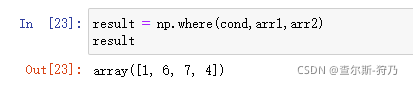
where函数中的第二个和第三个参数可以为标量。在数据分析中,经常需要通过一些条件将数组进行处理。例如,新建一个随机符合正太分布的数组,通过数据处理将正值替换为1,负值替换为-1

使用elif函数可以进行多条件的判别。np.where函数通过嵌套的where表达式也可以完成同样的功能,

2.3.4统计运算
Numpy库支持对整个数组或按指定轴向的数据进行统计计算。例如,sum函数用于求和:mean函数用于求算数平均数:std函数用于求标准差
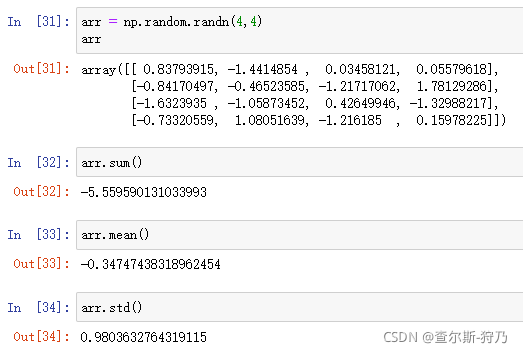
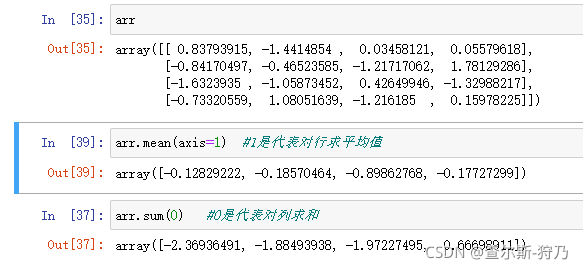
上面的这些函数也可以传入axis参数,用于计算指定轴方向的统计值,如图
cunmsum和cumpod方法会产生计算结果组成的数组,如下图

基本数组的统计方法如下
| 方法 | 使用说明 |
| sum |
求和 |
| mean | 算数平均数 |
| std、var | 标准差和方差 |
| min、max | 最小值和最大值 |
| argmin、argmax | 最小和最大元素的索引 |
| cumsum | 所有元素的累计和 |
| cumprod | 所有元素的累计积 |
2.3.5布尔型数组运算
对于布尔型数组,其布尔值会被强制转换为1(True)和0(False),如下图

另外,还有两个方法any和all也可以用于布尔型数组运算。any方法用于测试数据中是否存在一个或多个True:any方法用于检查数组中的所有值是否为True,如下图

2.3.6排序
与Python列表类似,Numpy数组也可以通过sort方法进行排序。如下图

对于多维数组,可以通过指定轴方向进行排序。

2.3.7集合运算
Numpy库中提供了针对一维数组的基本集合运算。在数据分析中,常使用np.unique方法来找出数组中的唯一值
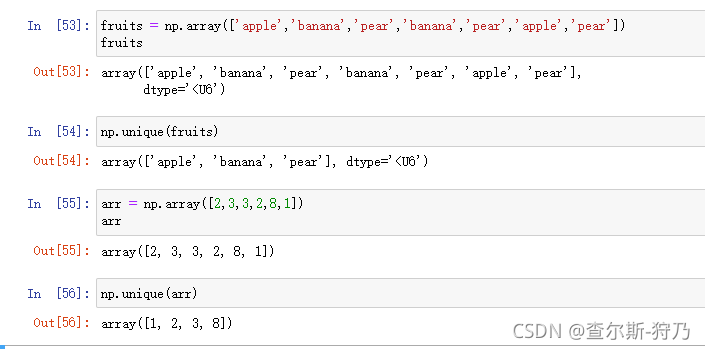
注:对唯一值进行了排序
np.in1d方法用于测试几个数组中是否包含相同的值,,返回一个布尔数组,如下图

数组的集合运算如表
| 方法 | 使用说明 |
| unique(x) |
唯一值 |
| intersect1d(x,y) | 公共元素 |
| union1d(x,y) | 并集 |
| in1d(x,y) | x的元素是否在Y中返回布尔型数组 |
| setdiff1d(x,y) | 集合的差 |
| setxor1d(x,y) | 交集取反 |
2.3.8线性代数
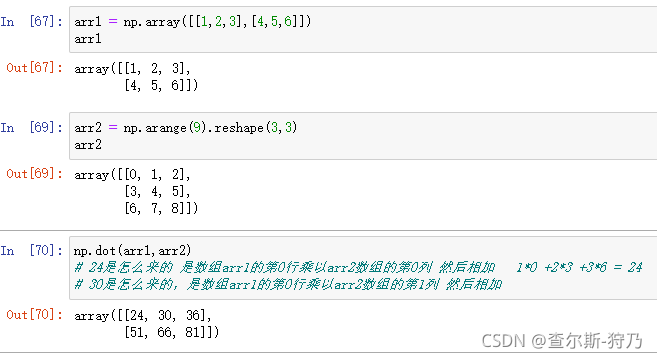
前面讲过数组的运算是元素级的,数组相乘的结果是对各对应元素的积组成的数组。而对于矩阵而言,需要求的是点积,这里Numpy库提供了用于矩阵乘法的dot函数,如图
对于更多的矩阵计算,可通过Numpy库的linalg模块来完成,如图
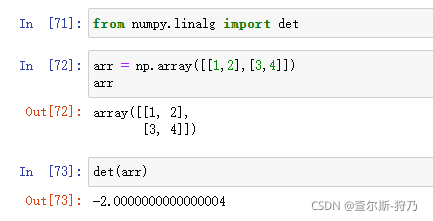
注:更多的矩阵运算说明可查看linalg帮助
2.4数组的存取
已经处理号的数组数据需要进行存储,而存储的数据也需要读取使用。
2.4.1数组的存取
通过np.savetxt方法可以对数组进行存储

2.4.2数组的读取
对于存储的文件,可以通过np.loadtxt方法进行读取,并将其加载到一个数组中,如图

2.5综合实例-图像变换
图像一般采用的是RGB色彩模式,即每个像素点的颜色有R(红)、G(绿)、B(蓝)组成。通过三种颜色叠加可以得到更重颜色,每个颜色的取值范围为0~255.Python中的PIL库是一个处理图像的第三方库,通过下列代码可以把图片转换为数组格式

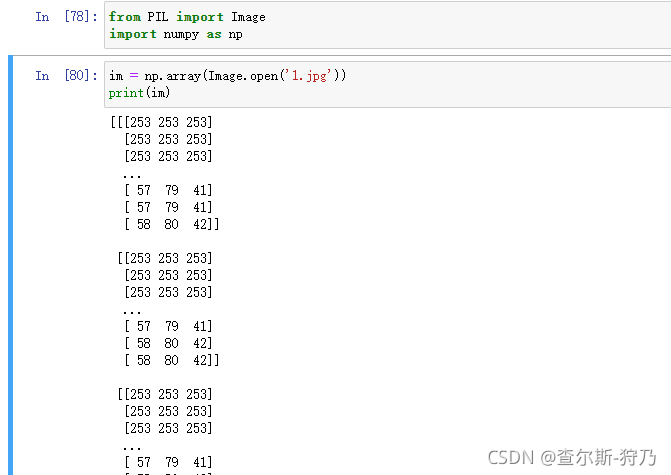
通过代码可以看出,图像转换为三位数组后,维度分别为宽度,长度和RGB值
注:在Anaconda中已经默认安装了PIL库,库名为pillow
转换为数组后,可对数组进行运算,运算完成后将其保存为新图像就完成了图像的变化。
