哈工大操作系统实验四——基于内核栈切换的进程切换(极其详细)
目录
- 总览
- 第一部分、switch_to相关
-
- 一、改写switch_to
- 二、配合switch_to修改的补充
-
-
- 2.1 开放switch_to
- 2.2改写task_struct
- 2.3 ESP0和KERNEL_STACK 以及一些参数的设置
- 2.4 全局变量tss的声明
- 2.5 在sche.c声明switch_to
-
- 三、在schedule()调用switch_to
- 四、PCB结构如下
- 第二部分、fork()相关
-
- 一、为什么要修改fork()
- 二、内核栈视角下的五段论
-
-
- 2.1中断进入阶段(第一阶段)
- 2.2 调用schedule引起PCB切换(第二阶段)
- 2.3切换内核栈(第三阶段)
- 2.4 中断返回前(第四阶段)
-
- 2.5 中断返回(第五阶段)
-
- 三、修改fork()
-
-
- 3.1 主体修改
- 3.2 first_return_from_kernel的编写
-
- 完结
-
-
- 附录(I)
- 附录(II)
- 致谢:
-
总览
本实验可以分为两个主要部分:
一部分是对应switch_to五段论中的中间段——内核栈的切换,主要是对switch_to代码的修改。
(原来的switch_to是基于TSS切换和长跳转指令来切换到下一个线程);
另一部分则在更改进程切换方式的情况下,如何修改fork()使其配合新的进程切换方式。
(因为fork()需要在新建一个子线程后,切换到子线程执行,而切换方式在上一部分改变了)
本文旨在将实现的整个流程讲清楚,在switch_to的注释和内核栈视角下的五段论务必详细观看,在理解整个流程起的作用非常大。
第一部分、switch_to相关
一、改写switch_to
switch_to原来在include/linux/sched.h的宏定义中,我们将那部分注释掉并在kernel/system_call.s中添加以下switch_to汇编代码
首先我们要明确以下几点:
1、switch_to主要是用来切换进程的,包括切换内核栈、LDT、PCB等
2、由于每个任务都有一个LDT,LDT是映射表,避免不同进程的符号地址产生错乱;
3、以下代码的p,pnext都是PCB的首地址,也就是sched.h里的task_struct就是PCB,如果看不明白偏移的话,可以看看task_struct是长什么样的。而且,查看task_struct可知,tss_struct在task_struct的最后一个位置。
4、我们将来以这样的方式调用switch_to:
switch_to(pnext, _LDT(next));
它含有两个参数
.align 2
switch_to:
pushl %ebp
movl %esp,%ebp
pushl %ecx
pushl %ebx
pushl %eax
# (1)判断要切换的进程和当前进程是否是同一个进程
movl 8(%ebp),%ebx /*%ebp+8就是从右往左数起第二个参数,也就是*pnext*/
cmpl %ebx,current /* 如果当前进程和要切换的进程是同一个进程,就不切换了 */
je 1f
/*先得到目标进程的pcb,然后进行判断
如果目标进程的pcb(存放在ebp寄存器中) 等于 当前进程的pcb => 不需要进行切换,直接退出函数调用
如果目标进程的pcb(存放在ebp寄存器中) 不等于 当前进程的pcb => 需要进行切换,直接跳到下面去执行*/
# (2)切换PCB
movl %ebx,%eax
xchgl %eax,current
/*ebx是下一个进程的PCB首地址,current是当前进程PCB首地址*/
# (3)TSS中的内核栈指针的重写
movl tss,%ecx /*%ecx里面存的是tss段的首地址,在后面我们会知道,tss段的首地址就是进程0的tss的首地址,
根据这个tss段里面的内核栈指针找到内核栈,所以在切换时就要更新这个内核栈指针。也就是说,
任何正在运行的进程内核栈都被进程0的tss段里的某个指针指向,我们把该指针叫做内核栈指针。*/
addl $4096,%ebx /* 未加4KB前,ebx指向下一个进程的PCB首地址,加4096后,相当于为该进程开辟了一个“进程页”,ebx此时指向进程页的最高地址*/
movl %ebx,ESP0(%ecx) /* 将内核栈底指针放进tss段的偏移为ESP0(=4)的地方,作为寻找当前进程的内核栈的依据*/
/* 由上面一段代码可以知道们的“进程页”是这样的,PCB由低地址向上扩展,栈由上向下扩展。
也可以这样理解,一个进程页就是PCB,我们把内核栈放在最高地址,其它的task_struct从最低地址开始扩展*/
# (4)切换内核栈
# KERNEL_STACK代表kernel_stack在PCB表的偏移量,意思是说kernel_stack位于PCB表的第KERNEL_STACK个字节处,注意:PCB表就是task_struct
movl %esp,KERNEL_STACK(%eax) /* eax就是上个进程的PCB首地址,这句话是将当前的esp压入旧PCB的kernel_stack。所以该句就是保存旧进程内核栈的操作。*/
movl 8(%ebp),%ebx /*%ebp+8就是从左往右数起第一个参数,也就是ebx=*pnext ,pnext就是下一个进程的PCB首地址。至于为什么是8,请查看附录(I)*/
movl KERNEL_STACK(%ebx),%esp /*将下一个进程的内核栈指针加载到esp*/
# (5)切换LDT
movl 12(%ebp),%ecx /* %ebp+12就是从左往右数起第二个参数,对应_LDT(next) */
lldt %cx /*用新任务的LDT修改LDTR寄存器*/
/*下一个进程在执行用户态程序时使用的映射表就是自己的 LDT 表了,地址空间实现了分离*/
# (6)重置一下用户态内存空间指针的选择符fs
movl $0x17,%ecx
mov %cx,%fs
/*通过 fs 访问进程的用户态内存,LDT 切换完成就意味着切换了分配给进程的用户态内存地址空间,
所以前一个 fs 指向的是上一个进程的用户态内存,而现在需要执行下一个进程的用户态内存,
所以就需要用这两条指令来重取 fs。但还存在一个问题,就是为什么固定是0x17呢?详见附录(II)*/
# 和后面的 clts 配合来处理协处理器,由于和主题关系不大,此处不做论述
cmpl %eax,last_task_used_math
jne 1f
clts
1: popl %eax
popl %ebx
popl %ecx
popl %ebp
ret
二、配合switch_to修改的补充
2.1 开放switch_to
在system_call.s的头部附近添加以下代码
.globl switch_to
即可使switch_to被外面访问到。
2.2改写task_struct
原来的进程切换是基于TSS切换和长跳转指令的,没有内核栈,也就是说PCB表内没有记录内核栈信息%esp的字段。所以,我们要为PCB增加这么一个字段kernelstack,里面记录了内核栈的栈顶指针,也就是%esp里会放置的内容
struct task_struct {
long state;
long counter;
long priority;
long kernelstack;
...
}
我们把它添加在第4个位置。避免需要更改太多硬编码。但还是有一个硬编码需要修改。
/*在kernal/system_call.s里*/
/*#define INIT_TASK { 0,15,15, 0,{{},},0,... 修改为*/
#define INIT_TASK { 0,15,15,PAGE_SIZE+(long)&init_task, 0,{{},},0,...
/*也就是增加了PAGE_SIZE+(long)&init_task*/
2.3 ESP0和KERNEL_STACK 以及一些参数的设置
/*在system_call.s下*/
ESP0 = 4 #此处新添
KERNEL_STACK = 12 #此处新添
state = 0 # these are offsets into the task-struct.
counter = 4
priority = 8
signal = 16 #此处修改
sigaction = 20 #此处修改
blocked = (37*16) #此处修改
1、定义 ESP0 = 4 是因为 内核栈指针 esp0 就放在进程0的TSS 中偏移为 4 的地方
2、KERNEL_STACK = 12的意思非常明显了,我们上面刚刚设过kernelstack放在task_struct第4个位置。
其它三个修改意思不明,网上是这么修改的。
2.4 全局变量tss的声明
虽然我们不再使用tss切换来切换进程,但是在中断的时候,要找到内核栈位置,并将用户态下的 SS:ESP,CS:EIP 以及 EFLAGS这五个寄存器压到内核栈中,这是沟通用户栈(用户态)和内核栈(内核态)的关键桥梁,而找到内核栈位置就依靠 TR 指向的当前 TSS。
现在虽然不使用 TSS 进行任务切换了,但是 Intel 的这态中断处理机制还要保持,所以仍然需要有一个当前 TSS,这个 TSS就是我们定义的那个全局变量 tss,即 0 号进程的 tss,所有进程都共用这个 tss,任务切换时不再发生变化。
总的来说,我们声明tss为0进程的TSS,该tss里面含有当前进程的一些信息(SS:ESP,CS:EIP 以及 EFLAGS),这些信息作为沟通用户态和内核态的关键桥梁
2.5 在sche.c声明switch_to
由于我们将要在schedule()调用switch_to,所以需要在sche.c声明一下这个外部函数。
/*添加在文件头部附近*/
extern long switch_to(struct task_struct *p, unsigned long address);
三、在schedule()调用switch_to
/*以下修改都在sched.c上进行*/
/*(1)在sched.c中要添加一个全局变量PCB,它的含义时下一个切换进程的PCB,但默认初始化为进程0的PCB*/
struct task_struct *pnext = &(init_task.task);
/* (2)将pnext赋为下一个进程的PCB
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i;
修改为
*/
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i,pnext = *p;
/*(3)修改调用switch_to
switch_to(next);
修改为
*/
switch_to(pnext, _LDT(next));
四、PCB结构如下
经过上面的讨论,我们知道PCB结构如下,其中task_struct结构可以进入include/linux/sche.h进行查看

第二部分、fork()相关
一、为什么要修改fork()
在开始修改fork()之前,我们需要明确为什么要修改fork()?
fork()是用来创建子进程的,而创建子进程意味着必须要该线程的一切都配置好了,以后直接切换就可以执行。而由于我们上面修改了进程切换方式,所以原来的配置不管用了。所以我们需要根据切换方式的改变,来改变这些配置
二、内核栈视角下的五段论
由于fork()的时候要配置子进程内核栈,所以我们先要明确内核栈里面应该有什么。
2.1中断进入阶段(第一阶段)
下面是关于从用户态中断进入内核态的阶段,内核栈的情况。
中断进入,是switch_to的第一阶段,就是int指令或其它硬件中断的中断处理入口,核心工作就是记录当前程序在用户态执行时的信息,如当前使用的用户栈、当前程序的执行位置、当前执行的现场信息等。
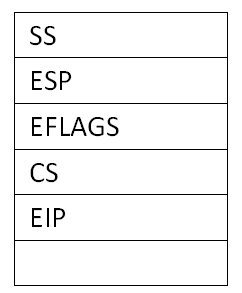
(1)其中用户栈地址SS:ESP和PC指针信息CS:EIP以及EFLAGS已经由中断处理硬件自动压入当前线程的内核栈了。
这时内核栈如下:
(2)当执行系统调用int 0x80从而执行到system_call(),又会把当前执行的现场信息压入内核栈。啥现场信息?就是一堆用户态寄存器的值,我们可以看看system_call.s的代码:
#在kernel/system_call.s下
system_call:
cmpl $nr_system_calls-1,%eax
ja bad_sys_call
push %ds
push %es
push %fs
pushl %edx
pushl %ecx # push %ebx,%ecx,%edx as parameters
pushl %ebx # to the system call
movl $0x10,%edx # set up ds,es to kernel space
mov %dx,%ds
mov %dx,%es
movl $0x17,%edx # fs points to local data space
mov %dx,%fs
call sys_call_table(,%eax,4)
pushl %eax
movl current,%eax
cmpl $0,state(%eax) # state
jne reschedule
cmpl $0,counter(%eax) # counter
je reschedule
ret_from_sys_call:
以下略,是从系统调用返回的代码
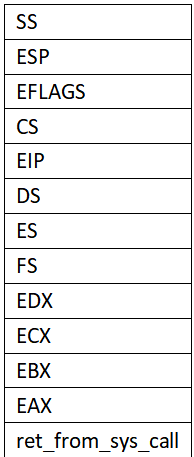
①执行system_call开头时按顺序压入ds、es、fs、gs、edi、esi、edx、ecx、ebx、eax这些用户态的寄存器现场信息。
此时内核栈如下:

②在system_call中执行完相应的系统调用sys_call_xx后,又将函数的返回值eax压栈。(以上代码17行)
③若引起进程调度,则跳转执行reschedule。否则则执行ret_from_sys_call。reschedule如下
reschedule:
pushl $ret_from_sys_call
jmp schedule
我们当然是考虑调度的这类情况,因为我们正在讨论switch_to五段论。在reschedule中,我们把ret_from_sys_call的地址压入内核栈,然后执行schedule()调度函数。
此时内核栈如下:
2.2 调用schedule引起PCB切换(第二阶段)
当在schedule()执行switch_to前会进行参数压栈以及下一条指令压栈
schedule(){
……
switch_to(pnext,_LDT(next));
}
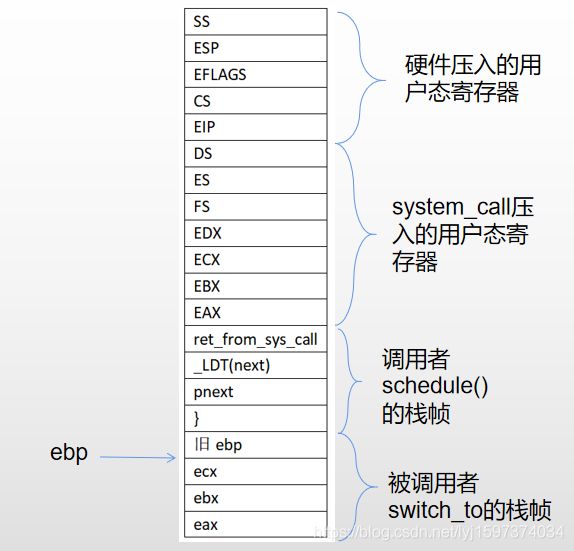
内核栈会压入参数_LDT(next)、pnext,然后压入它的下一条指令的位置,也就是 “}”
此时内核栈如下:

进入switch_to后,将一些调用者寄存器压栈,以便后续使用这些寄存器。
switch_to:
pushl %ebp
movl %esp,%ebp
pushl %ecx
pushl %ebx
pushl %eax
此时内核栈如下
2.3切换内核栈(第三阶段)
这个阶段内核栈变化了。一个进程被挂起,也意味着其内核栈被挂起,这时切换到一个之前被挂起的进程,并将其内核栈的栈顶地址加载到esp。
但是,我们要注意一点:任何进程被挂起,都要经过上面的过程,也就意味着内核栈的结构没变,但是里面的内容变了。
2.4 中断返回前(第四阶段)
(1)中断返回前的处理
①切换内核栈后,后续经过一些和内核栈无关的操作后,最后在switch_to弹出eax、ebx、ecx、ebp
switch_to:
……
1: popl %eax
popl %ebx
popl %ecx
popl %ebp
ret
②switch_to的ret
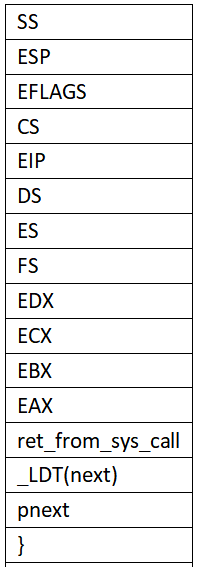
1、执行到switch_to 的ret会弹出 “}”并返回到schedule()的 “}”处执行。
2、在C函数的“}” 处,会自动弹出参数pnext 和_LDT(next),并弹出ret_from_sys_call的地址作为EIP开始执行ret_from_sys_call。
内核栈情况如下:
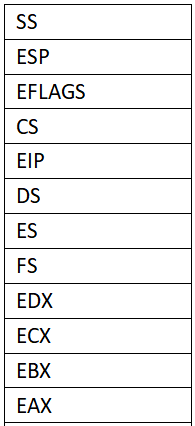
(3)ret_from_sys_call的最后弹出了一系列用户态寄存器信息
ret_from_sys_call:
……
3: popl %eax
popl %ebx
popl %ecx
popl %edx
pop %fs
pop %es
pop %ds
iret
此时内核栈信息如下:

2.5 中断返回(第五阶段)
然后再执行iret指令,该指令就可以设置好用户栈(SS:ESP)、EFLAGS、用户指令执行位置(CS:EIP)到相应寄存器,然后就直接跳转回用户态执行。这条硬件指令和int 0x80对应来看就很容易理解了。
iret就是interrupt return ,中断返回。
当返回到用户态执行时,内核栈就空了。大功告成!
三、修改fork()
3.1 主体修改
由之前学习可知,修改fork()就是修改fork.c的copy_process()。
经过上面的讨论,我们知道不再采用TSS切换,所以把tss切换相关的都注释掉。
/** 很容易看出来下面的部分就是基于tss进程切换机制时的代码,所以将此片段要注释掉
p->tss.back_link = 0;
p->tss.esp0 = PAGE_SIZE + (long) p;
p->tss.ss0 = 0x10;
...
*/
接下来的核心任务就是设计一个子进程的内核栈。话不多说,直接上代码。
/*在fork.c的copy_process()的第一行添加以下代码即可*/
long *krnstack;
p = (struct task_struct *) get_free_page();
krnstack = (long)(PAGE_SIZE +(long)p);
*(--krnstack) = ss & 0xffff;
*(--krnstack) = esp;
*(--krnstack) = eflags;
*(--krnstack) = cs & 0xffff;
*(--krnstack) = eip;
*(--krnstack) = ds & 0xffff;
*(--krnstack) = es & 0xffff;
*(--krnstack) = fs & 0xffff;
*(--krnstack) = gs & 0xffff;
*(--krnstack) = esi;
*(--krnstack) = edi;
*(--krnstack) = edx;
*(--krnstack) = (long)first_return_from_kernel;
*(--krnstack) = ebp;
*(--krnstack) = ecx;
*(--krnstack) = ebx;
*(--krnstack) = 0;//eax,到最后作为fork()的返回值,即子进程的pid
p->kernelstack = krnstack;
......
子进程内核栈图如下:

是不是几乎和上面的内核栈一模一样?是那就对了!到最后也是设置好用户态的寄存器然后返回到用户态,原理是一样的。至于为什么多了几个esi、edi、gs寄存器?因为fork()是完全复制父进程的内容到子进程,所以所有寄存器都要复制过去。
综上,经过switch_to和first_return_from_kernel的弹出,一共弹出了eax(0)、ebx、ecx、edx、edi、esi、gs、fs、es、ds10个寄存器,用户态的寄存器内容已经完全弹到相应的寄存器后,就可以执行iret了。
3.2 first_return_from_kernel的编写
1、这个first_return_from_kernel对应的是上面的ret_from_sys_call。
/*在system_call.s下*/
.align 2
first_return_from_kernel:
popl %edx
popl %edi
popl %esi
pop %gs
pop %fs
pop %es
pop %ds
iret
2、然后把first_return_from_kernel声明为全局函数。
/*在system_call.s头部附近*/
.globl first_return_from_kernel
3、由于在fork()里面调用到first_return_from_kernel,所以声明要使用这个外部函数
/*在fork.c头部附近*/
extern void first_return_from_kernel(void);
完结
如果没有其它错误的话,make all后系统如果可以运行就成功了。
附录(I)
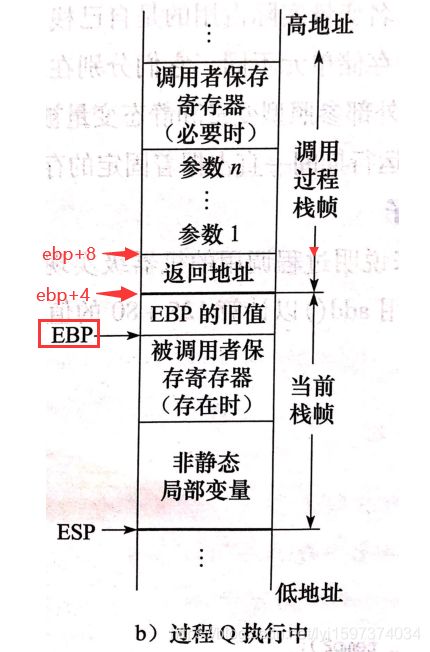
解析:
对应switch_to(pnext, _LDT(next))
1、图中参数1就是pnext,参数2就是_LDT(next)
2、图中当前栈帧就是对应switch_to()的栈帧,而调用过程栈帧就是schedule()的栈帧,因为是schdule()调用switch_to的,
附录(II)
fs 是一个选择子,即 fs 是一个指向描述符表项的指针,这个描述符才是指向实际的用户态内存的指针,所以上一个进程和下一个进程的 fs实际上都是 0x17,真正找到不同的用户态内存是因为两个进程查的 LDT 表不一样,所以这样重置一下 fs=0x17有用吗,有什么用?要回答这个问题就需要对段寄存器有更深刻的认识,实际上段寄存器包含两个部分:显式部分和隐式部分,如下图给出实例所示,就是那个著名的jmpi 0, 8,虽然我们的指令是让 cs=8,但在执行这条指令时,会在段表(GDT)中找到 8对应的那个描述符表项,取出基地址和段限长,除了完成和 eip 的累加算出 PC 以外,还会将取出的基地址和段限长放在 cs的隐藏部分,即图中的基地址 0 和段限长 7FF。为什么要这样做?下次执行 jmp 100 时,由于 cs 没有改过,仍然是8,所以可以不再去查 GDT 表,而是直接用其隐藏部分中的基地址 0 和 100 累加直接得到PC,增加了执行指令的效率。现在想必明白了为什么重新设置 fs=0x17 了吧?而且为什么要出现在切换完 LDT 之后?
关于问题的解析:新设fs后,会去再次查GDT表获得描述符,从而得到用户态内存基地址,而不是用之前查的记录,换句话来说,就是更新了用户态的基地址
致谢:
参考了网上多篇博客才弄清楚全部流程。
[1]https://blog.csdn.net/weixin_41761478/article/details/99777145?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-1.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-1.control
[2]https://www.cnblogs.com/XiangfeiAi/p/4758401.html
[3]https://blog.csdn.net/qq_41708792/article/details/89637248
[4]https://blog.csdn.net/xubing716/article/details/53412647
[5]https://blog.csdn.net/jump_into_zehe/article/details/106038473