Numpy库速通教程典藏版 #一篇就够了系列
Numpy库速通教程典藏版 #一篇就够了系列 一文带你拿下numpy

文章目录
- 1. 创建数组
-
- 1.1 通过 array( object ) 创建
-
- 1.1.1 通过列表创建
- 1.1.2 通过元组创建简单
- 1.1.3 通过字符串创建
- 1.1.5 通过数组创建
-
- 1.1.5.1 创建
- 1.1.5.2 数组的复制
- 1.1.4 通过range创建
- 1.2 arange()方法
- 1.3 linspace()方法 --等差
- 1.4 logspace()方法 --等比
- 1.5 empty()方法 创建全空数组
- 1.6 ones()方法 创建全一数组
- 1.7 zeros()方法 创建全零数组
- 1.8 full()方法 创建指定值填充的数组
- 1.9 eye()方法 创建对角矩阵数组
- 1.10 diag()方法 创建对角线矩阵数组
- 1.11 生成随机数组
-
- ①rand()方法
- ② random()方法
- ③randint()方法
- ④randn()方法
- ⑤normal()方法
- ⑥随机数种子 seed()
- ⑦随机排序
- ⑧随机抽取 choice()方法
- 1.12从已有数组中创建数组
-
- ①asarray()方法
- ②formbuffer()方法
- ③fromiter()方法
- ④empty_like()方法
- ⑤zeros_like()方法
- ⑥ones_like()方法
- ⑦fulls_like()方法
- 2. numpy数组 数据类型
-
- 2.1 关于默认值(要求高时不建议使用)
- 2.2 数组数据类型表
- 2.3 指定数据类型详解
-
- 2.3.1 整数与浮点数
- 2.3.2 字节类型
- 2.3.3 字符串类型
- 3. 数组的属性 与 操作
-
- 3.1 数组的属性
- 3.2 数组的重塑
-
- 3.2.1 reshape()与resize()
- 3.2.2flatten() 与 ravel()
- 3.3 数组转置
- 3.4 数组的索引与切片
-
- 3.4.1 索引
-
- ①一维数组为例
- ②二维数组为例
- ③三维数组为例(高维)
- 3.4.2 切片
-
- ①一维数组为例
- ②二维数组为例
- ③三维数组为例(高维)
- 3.4.3 布尔索引
- 4. 数组运算
-
- 4.1 加、减、乘、除 & 幂运算
- 4.2 比较运算
- 4.3 标量运算
- 5. 数组增、删、改、查
-
- 5.1 数组的增加(也称扩展、拼接)
-
- 5.1.1 hstack()方法 与 vstack()方法
- 5.1.2 np.concatenate()方法
- 5.1.3合并的逆操作---数组的分割split()
-
- hsplit()、vsplit()、array_split()
- 5.2 数组的删除
-
- 5.2.1 关于二维数组
- 5.2.2站在更高维度来理解
- 5.3 数组的修改
- 5.4 数组的查询
- 6.Numpy常用统计分析函数
-
- 6.1 基本运算函数
- 6.2统计分析函数
- 6.3数组的排序
-
- sort()
- argsort()
- lexsort()
- 6.4 自定义功能函数 np.apply_along_axis()
- 6.5 数组的去重 unique()
- 7.numpy矩阵
-
- 7.1 创建矩阵
-
- mat()方法创建简单矩阵
- 创建随机小数 矩阵
- 创建随机整数矩阵
- 创建全零矩阵
- 创建全一矩阵
- 创建对角矩阵
- 创建 对角线 矩阵
- 7.2 矩阵运算
-
- ①矩阵与标量运算
- ②矩阵与矩阵运算
- 7.3 矩阵转换
-
- 转置
- 逆矩阵
ʚʕ̯•͡˔•̯᷅ʔɞ
欢迎各路大佬来到小啾主页指点☀️
✨博客主页:云雀编程小窝 ꧔ꦿ
꧔ꦿ支持我:点赞 + 关注 + 收藏✨
꧔ꦿ欢迎大家在评论区交流分享!

numpy导包 和 查看版本 命令
import numpy as np
print(np.__version__)

1. 创建数组
1.1 通过 array( object ) 创建
array()语法
array(object,dtype=None, copy=True, order=‘K’, subok=False, ndmin=0)
- odject:任何具有数组借口方法的对象。通常也可以理解为是可迭代对象。
- dtype:数据类型。
- copy:布尔类型值,是否复制,默认为True。设为true可以避免对数组数据有修改操作时影响到原数组。具体见下文**“数组的复制”** 部分。
- order:元素在内存中出现的顺序,可以是"K"、“A”、“C”、“F"四个字符。
默认为“K”,表示元素在内存中出现的顺序。
“C”表示按行排列,“F”表示按列排列。
如果object是一个数组,则还可以是"A”,表示原顺序。 - subok:布尔类型。默认为False,表示返回的数组默认为基类数组。如果为True则将传递子类。
- ndmin:生成数组的 最小维度。(最小,意味着可以大于这个数字,当不足这个数字时,补充到这个数字。)
1.1.1 通过列表创建
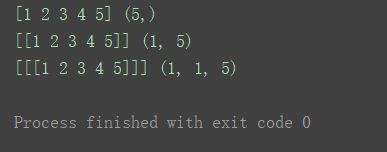
a1 = np.array([1, 2, 3, 4, 5])
print(a1,a1.shape)
a2 = np.array([1, 2, 3, 4, 5], ndmin=2)
print(a2, a2.shape)
a3 = np.array([1, 2, 3, 4, 5], ndmin=3)
print(a3, a3.shape)
如图,分别创建出了一维、二维、三维数组,并打印出了其shape。
1.1.2 通过元组创建简单
a2 = np.array((1., 2., 3, 4., 5.))
print(a2)
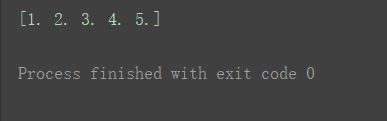
效果差不多同上,这个没啥特别的。
1.1.3 通过字符串创建
a3 = np.array('123')
print(a3)
print(type(a3))
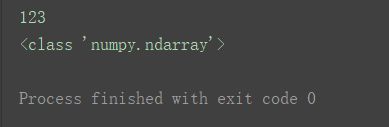
如图,创建出的是一个长度为1的一维数组。
而不是将字符串分割长度为3的。
1.1.5 通过数组创建
1.1.5.1 创建
n1 = np.array([1, 2, 3])
n2 = np.array(n1)
print(n2)
print("=======================================")
n3 = np.array([[1, 2, 3], [4, 5, 6]])
n4 = np.array(n3)
print(n4)
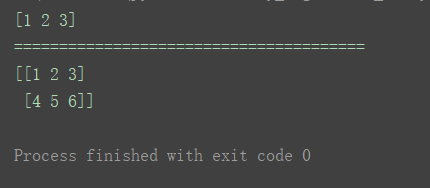
如图分别创建了一个一维数组和一个二维数组。
1.1.5.2 数组的复制
当我们需要修改数组又不想影响到目标数组时,通常可以通过“用数组创建数组”,进而实现对目标数组的复制操作。
- 选择不复制,把copy参数设置为False时:
n1 = np.array([1, 2, 3])
n2 = np.array(n1)
n1 = np.array([1, 2, 3])
n2 = np.array(n1, copy=False)
print("n1:", n1)
print("n2:", n2)
n2[0] =100
print("**********修改n2的第一个数据***********")
print("n1:", n1)
print("n2:", n2)
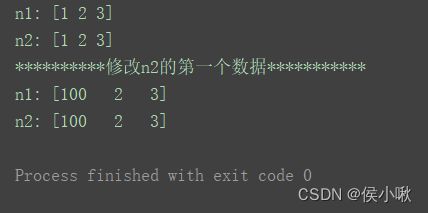
如图,n2和n1共用存储。当修改n2时,n1也被修改了。
- 选择复制时,即copy=True,也是copy的默认值。
n3 = np.array([[1, 2, 3], [4, 5, 6]])
n4 = np.array(n3)
print("n3:", n3)
print("n4:", n4)
n4[0][1] =100
print("**********修改n4(0,1)位置的数据***********")
print("n3:", n3)
print("n4:", n4)
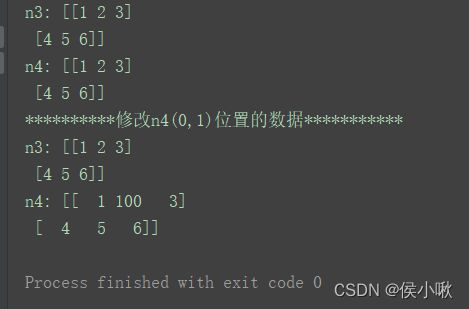
如图,n3和n4没有共用存储,所以当n4被修改时,不影响n3。
1.1.4 通过range创建
将range对象转化为列表对象即可传入。
a1 = np.array(list(range(10)))
print(a1)
(结果数据类型是整数型)
也可以直接传入一个range()对象
print(np.array(range(10)))
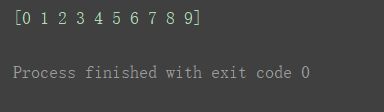
arrange是numpy对range优化过后的方法,常用来创建数组。而通常不再采用上边的range()方法。
此处了解即可。
1.2 arange()方法
语法
arange([start],stop,[,step],dtype=None)
取值方式为取左不取右,[start, stop),不包含终止值stop。
使用示例
a1 = np.arange(0, 10, 2)
print(a1)
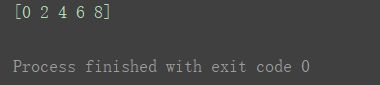
(此时结果数据类型是整数型)
a2 = np.arange(0, 10, 0.2)
print(a2)

(此时结果数据类型是浮点类型)
1.3 linspace()方法 --等差
使用linspace()方法,可以快捷地通过指定范围和数据个数的形式,来创建出数组(等差数列形式)。
语法
linspace(start, stop, num=50, end_point=True, restep=False, dtype=None)
- 不同于arange()方法,linspace()方法传入参数表示的区间是从起始值到结束值的闭区间,而arange()传入的参数表示的区间是左闭右开区间。
- num 表示生成数组的数字个数。
- endpoint 布尔类型,默认为True,表示包含stop。否则可以不包含。
- restep 布尔类型,默认为True,表示生成的数组显示间距。否则不显示。
创建两个数组作为示例:
n1 = np.linspace(100, 200, 11)
print(n1)
print("======================================================================")
n2 = np.linspace(10, 20, 101)
print(n2)
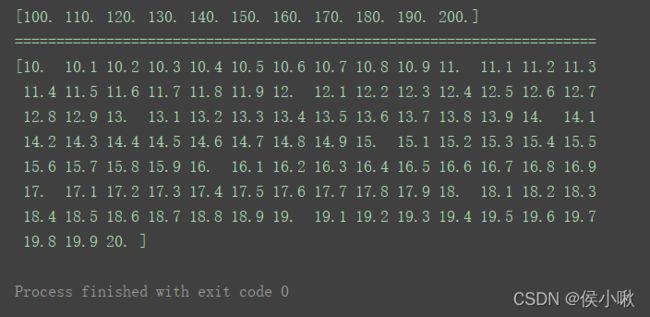
可以看出无论结果是否是整数,都默认为是浮点型。
1.4 logspace()方法 --等比
使用logspace()方法,可以创建出等比数列形式的数组。
语法
logspace(start, stop, num=50, end_point=True, base=10.0, dtype=None)
-
start 序列起始值的指数 ,序列的起始值为 b a s e s t a r t \displaystyle base^{start} basestart
-
stop 序列结束值的指数,序列的结束值为 b a s e s t o p \displaystyle base^{stop} basestop
-
base表示对数log的底数。值得注意的是,base未必是等比数列的公比。
通过下例具体感受其用法:
n1 = np.logspace(0, 10, 6, base=2, dtype='int')
print(n1)
print("======================================================================")
n2 = np.logspace(0, 10, 11, base=2, dtype='int')
print(n2)
print("======================================================================")
n3 = np.logspace(0, 10, 21, base=4, dtype='int')
print(n3)
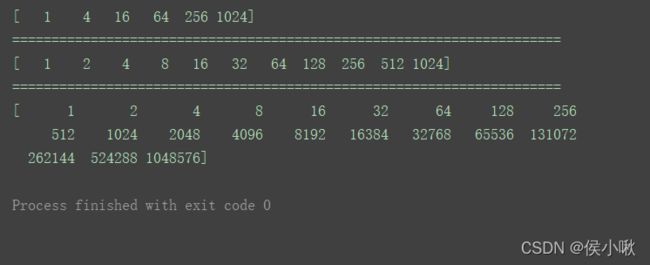
如图,n1的公比为4,n2的公比为2,n3的公比为2。
1.5 empty()方法 创建全空数组
empty()方法常用于创建指定维度和数据类型未初始化 的数组。
n1 = np.empty([2, 3])
print(n1)
print("======================================================================")
n2 = np.empty([2, 3], dtype=int)
print(n2)
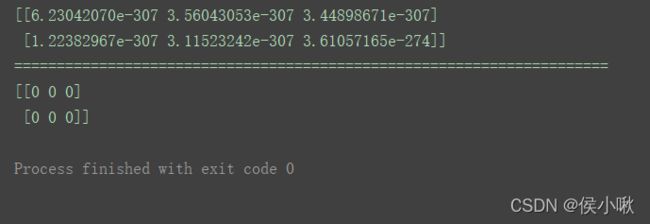
其中,数组n1的元素为随机值。
1.6 ones()方法 创建全一数组
a1 = np.ones(10)
print(a1)
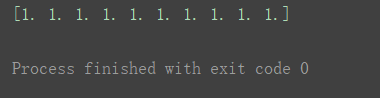
(结果数据类型默认是浮点类型)
1.7 zeros()方法 创建全零数组
a1 = np.zeros(10)
print(a1)
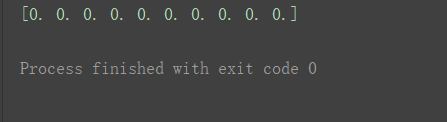
(结果数据类型默认是浮点类型)
1.8 full()方法 创建指定值填充的数组
shape为(3,4),以整数类型数字 9 填充。
n = np.full((3, 4), 9)
print(n)

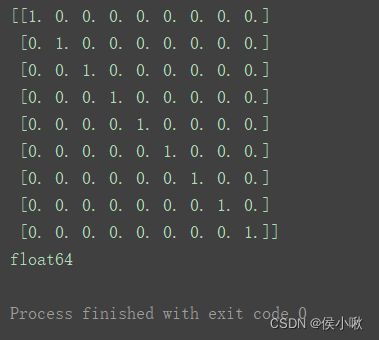
1.9 eye()方法 创建对角矩阵数组
n1 = np.eye(9)
print(n1)
print("======================================================================")
n2 = np.eye(9, dtype=int)
print(n2)
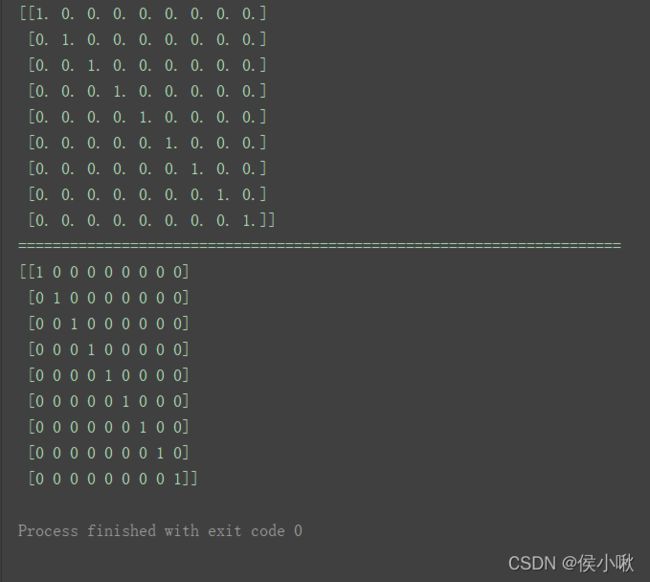
1.10 diag()方法 创建对角线矩阵数组
diag()方法用于创建对角线矩阵形式的数组,且diag()方法没有dtype参数。
a = [1, 2, 3, 4, 5]
print(np.diag(a))

1.11 生成随机数组
①rand()方法
语法
np.random.rand(d0,d1,d2,d3,d4,…,dn)
randn()函数可以用于生成随机数或者随即数组。当不传入参数时,生成一个随机数。当传入参数时,则生成指定shape的随即数组。
- 数据的范围为[0, 1)
指定shape时不要求元组形式。参数个数不限制。这一点是区别于np.random.random()方法。
print("生成一个随机数")
n1 = np.random.rand()
print(n1)
print(type(n1))
print("==============================")
print("生成一个一维随机数")
n2 = np.random.rand(3)
print(n2)
print(type(n2))
print("==============================")
print("生成一个二维随机数")
n3 = np.random.rand(2, 3)
print(n3)
print(type(n3))
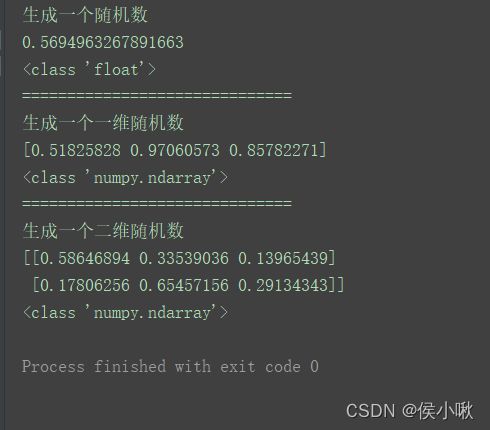
② random()方法
random()的用法及作用于rand相似,只是需要传入的参数是一个元组。
生成数据的范围也是[0, 1)
print("生成一个随机数")
print(np.random.random())
print("==============================")
print("生成一个一维随机数")
print(np.random.random(5))
print("==============================")
print("生成一个二维随机数")
print(np.random.random((3, 5)))
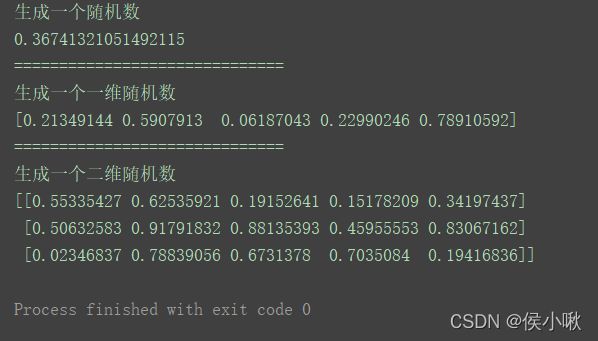
③randint()方法
randint()方法可以用于生成有一定范围的随机整数。
- 语法
np.random.randint(low, high=None, size=None)
- low 起始值 整数
- high 终止值 整数 应满足 low < high 否则会报错
- [low, high) 左闭右开,可取左,不可取右。
- size 整数或描述shape的元组。整数表示一维。
print(np.random.randint(0, 100, 5))
print("==============================")
print(np.random.randint(0, 100, (4, 4)))
④randn()方法
通过randn()方法可以得到满足标准正态分布的数组
X X X~ ( 0 , 1 ) (0, 1) (0,1)
语法
randn(d0,d1,d2,d3,…,dn)
参数形式同rand(),不是元组。表示shape。
print("生成一个标准正态分布下的数字,这样没啥意义")
print(np.random.randn())
print("=====================================")
print("生成一个一维数组")
print(np.random.randn(8))
print("=====================================")
print("生成一个二维数组")
print(np.random.randn(2, 3))
print("=====================================")
print("生成一个三维数组")
print(np.random.randn(2, 3, 4))
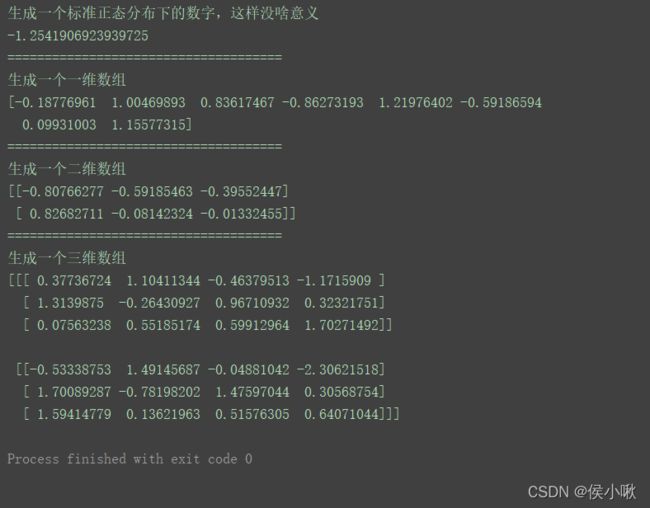
数组的数据越多,才越能体现其分布特点。
⑤normal()方法
normal()方法也可以用于生成正态分布数组,且不限于标准正态分布,可以自定义分布参数。
语法
np.random.normal(loc=0.0, scale=1.0, size=None)
- loc 均值
- scale 标准差
- size,即shape,或维度。要求是一个元组或一个数字。
默认生成数据满足标准正态分布。
print("生成一个标准正态分布下的数字,这样没啥意义")
print(np.random.normal())
print("=====================================")
print("生成一个一维数组,均值为5标准差为10,元素个数为10")
print(np.random.normal(5, 10, 10))
print("=====================================")
print("生成一个二维数组,均值为4,标准差为5,shape为(4, 5)")
print(np.random.normal(4, 5, (4, 5)))
print("=====================================")
print("生成一个三维数组,均值为2,标准差为4,shape为(2, 3, 4)")
print(np.random.normal(2, 4, (2, 3, 4)))
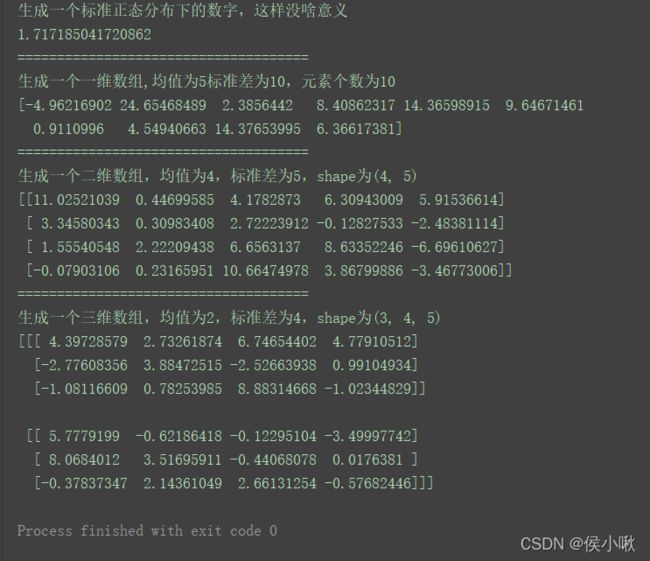
⑥随机数种子 seed()
有的情况下,为了保证得到一致的随机数,需要用到随机数种子
即给np.random.seed()传入一个大于等于0的整数
不管是在同一台电脑上多次允许,还是在不同的电脑上执行程序,只要随机数种子设置相同,则就可以保证得到相同的随机数。
写法示例:
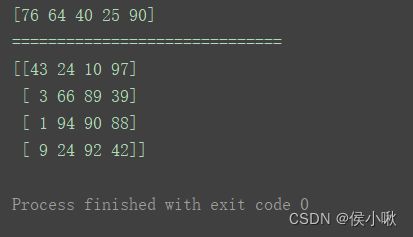
np.random.seed(1)
print(np.random.randint(100, 200, (4, 4)))
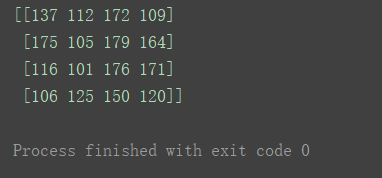
⑦随机排序
- 对数组随机排序可以使用shuffle() 和 permutation() 两个方法。
- 区别在于shuffle()方法直接修改的是原数组,而permutation()不影响原数组。
- 两个方法均只有一个参数,为一个数组。
- 对数组对象中1数据随机排序
- 随机排序时,仅对数组最外层的维度排序,即axis=0。就是说,以shape为(5,6,7,8,9)的数组为例,随机排序打乱的是元素个数为“5”这个维度的5个对象。五个对象自身内部结构不会被改变。
- 此外,随机数种子固定的时候,随机排序的效果也是固定的。
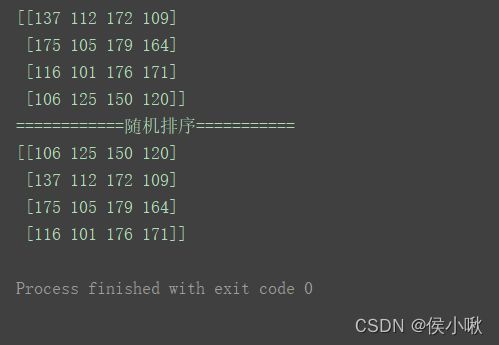
代码示例 shuffle() :
np.random.seed(1)
n = np.random.randint(100, 200, (4, 4))
print(n)
print("============随机排序===========")
np.random.shuffle(n)
print(n)
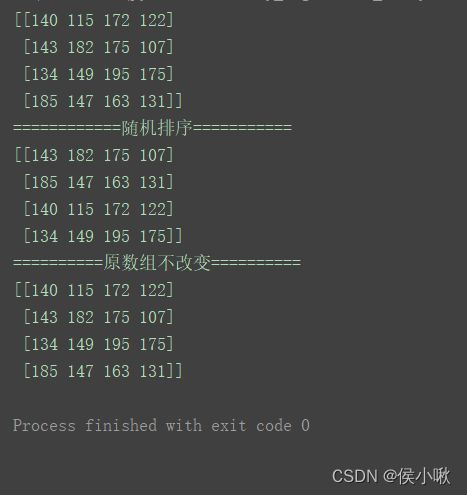
代码示例 permutation() :
np.random.seed(2)
n = np.random.randint(100, 200, (4, 4))
print(n)
print("============随机排序===========")
print(np.random.permutation(n))
print("==========原数组不改变==========")
print(n)
⑧随机抽取 choice()方法
语法
numpy.random.choice(a, size=None, replace=True, p=None)
- a 一个列表 或者 一个数组,表示要从中抽样的对象。
也可以是一个正整数,是正整数的话则表示从[0, a)的整数中随机抽取 。 - size 即shape,元组。也可以是一个数字,表示一维数组。
- replace 是否有放回。默认为True是有放回的抽取。
- p 抽取到的概率。默认为None,表示所有元素抽取到的概率相等。也可以是一个数组,是数组的话,该数组的shape应与参数a数组的shape相同。该数组中的每个元素对应着数组a中相同位置的每个元素被抽取到的概率。
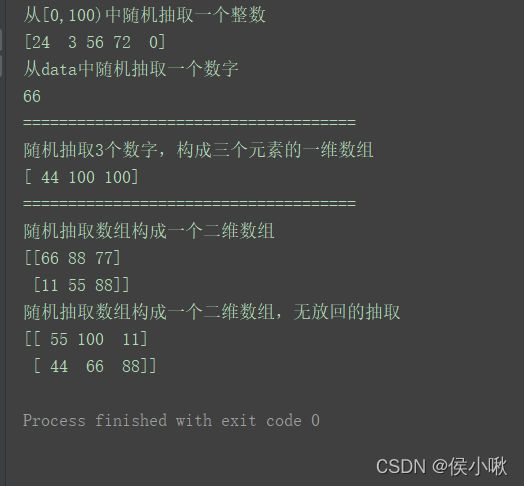
np.random.seed(3)
print("从[0,100)中随机抽取一个整数")
print(np.random.choice(100, 5))
data = [11, 22, 33, 44, 55, 66, 77, 88, 99, 100]
print("从data中随机抽取一个数字")
print(np.random.choice(data))
print("=====================================")
print("随机抽取3个数字,构成三个元素的一维数组")
print(np.random.choice(data, 3))
print("=====================================")
print("随机抽取数组构成一个二维数组")
print(np.random.choice(data, (2, 3)))
print("随机抽取数组构成一个二维数组,无放回的抽取")
print(np.random.choice(data, (2, 3), replace=False))
1.12从已有数组中创建数组
①asarray()方法
asarray()方法与array()函数类似,差别不大。这里了解即可。
asarray(a,dtype=None,order=None)
- a可以是数组,也可以是列表、元组等对象。而且是列表元组等时,可以支持一直套娃,套多少层,创建出来的维度就有多高。
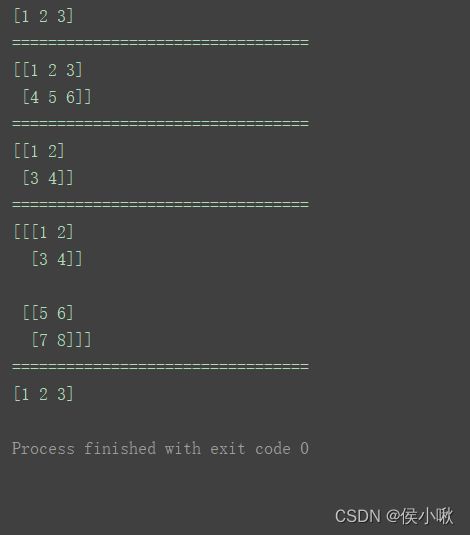
a = np.asarray([1, 2, 3])
print(a)
print("=================================")
b = np.asarray([[1, 2, 3], [4, 5, 6]])
print(b)
print("=================================")
c = np.asarray(((1, 2), (3, 4)))
print(c)
print("=================================")
d = np.asarray((((1, 2), (3, 4)), ((5, 6), (7, 8))))
print(d)
print("=================================")
e = np.asarray(a)
print(e)
②formbuffer()方法
用formbuffer()方法创建数组,该方法的特点及优势在于,该方法接收字节流形式的参数。
语法
np.frombuffer(buffer, dtype=None, count=-1, offset=0)
- buffer指实现了__buffer__方法的对象。当buffer参数值为字符串时,因为python3默认字符串是Unicode类型,所以要转换成Byte string类型,需要在原字符串前加上b。
- dtype 即数据类型,默认为浮点型。
- count 读取数据的数量,默认值-1表示读取所有数据。
- offset 读取的起始位置,默认从0位置开始。
通过以下一系列示例,快速理解其用法。
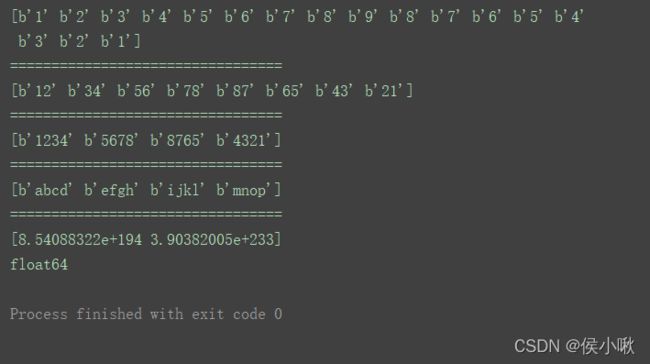
n1 = np.frombuffer(b"12345678987654321", dtype='S1')
print(n1)
print("=================================")
n2 = np.frombuffer(b"1234567887654321", dtype='S2')
print(n2)
print("=================================")
n3 = np.frombuffer(b"1234567887654321", dtype='S4')
print(n3)
print("=================================")
n4 = np.frombuffer(b"abcdefghijklmnop", dtype='S4')
print(n4)
print("=================================")
n5 = np.frombuffer(b"abcdefghijklmnop") # 转浮点型了
print(n5)
print(n5.dtype)
③fromiter()方法
fromiter()方法可用于从可迭代对象(iterable) 中创建数组。
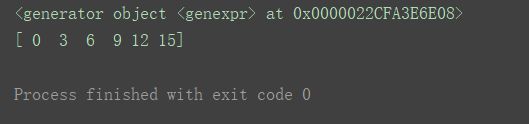
# 创建一个生成器
a1 = (x * 3 for x in range(6))
print(a1)
# 通过生成器这个可迭代对象创建数组
a2 = np.fromiter(a1, dtype='int')
print(a2)
数据较多时这种方法比较高效。可以实现快速将生成器中的大量数据导入数组中。
a3 = np.fromiter((2, 5, 6, 8, 5, 2), dtype='int')
print(a3)
a4 = np.fromiter([2, 5, 6, 8, 5, 2], dtype='int')
print(a4)

- 需要注意的一点是,使用fromiter()方法时,传入的可迭代对象不能是 有嵌套其他可迭代对象 的可迭代对象。fromiter()方法不支持套娃。
④empty_like()方法
创建一个与给定数组相同shape的未初始化的数组
语法
empty_like(prototype, dtype=None, order=None, subok=None, shape=None)
n = np.arange(1, 7).reshape(2, 3)
print(n)
print("===============================")
a = np.empty_like(n)
print(a)
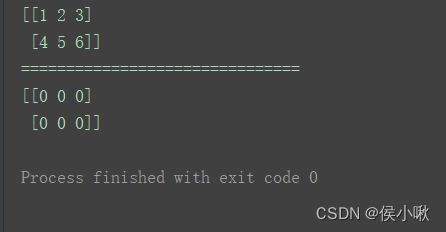
⑤zeros_like()方法
创建一个与给定数组相同shape的全零数组
语法
zeros_like(a, dtype=None, order=‘K’, subok=True, shape=None)
n = np.arange(1, 7).reshape(2, 3)
print(n)
print("===============================")
a = np.zeros_like(n)
print(a)
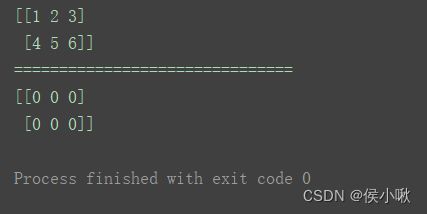
⑥ones_like()方法
创建一个与给定数组相同shape的 全一数组
语法
ones_like(a, dtype=None, order=‘K’, subok=True, shape=None)
n = np.arange(1, 7).reshape(2, 3)
print(n)
print("===============================")
a = np.ones_like(n)
print(a)
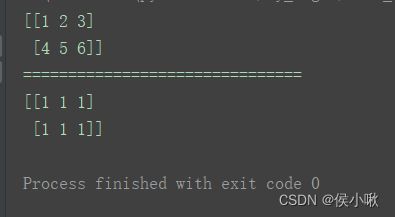
⑦fulls_like()方法
创建一个与给定数组相同shape的指定值填充的数组
语法
full_like(a, fill_value, dtype=None, order=‘K’, subok=True, shape=None)
n = np.arange(1, 7).reshape(2, 3)
print(n)
print("===============================")
a = np.full_like(n, 100)
print(a)
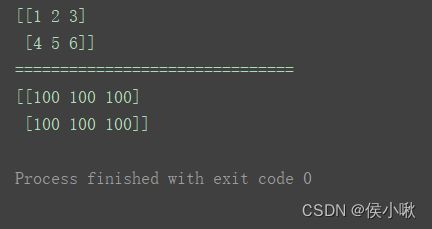
2. numpy数组 数据类型
2.1 关于默认值(要求高时不建议使用)
通过上述方法创建数组时,上边的示例中并未指定数据类型。
通过上边的示例可以看到,不指定数据类型创建数组时,如果不是根据一个传入的 具体的有数组接口方法对象来创建,则创建出的数组的数值类型默认为浮点型。其中,除了使用arange()且各个数字刚好是整数时,是个例外,得到的数组的数据类型为整数型(回顾一下上文的arange即可理解,因为arange方法与array()里边放一个 list(range(n)) 是类似的。)
关于创建数组时数据类型默认具体是怎么样的(int32, int64, float32, float64…),我现在所了解的资源中说法有很多,有的说是跟个人的操作系统有关,有的认为是保存对象所需的最小类型。目前我不清楚哪一种是对的,不过可以确定的是,我们最好在创建数组的时候,我们通常不采用默认值,最好自己指定,这样就不会产生因为数据类型带来的问题了。(如有观点或其他答案欢迎在评论区补充。)
对类型的位数有需求时,不建议使用常规的时int,float,unit指定,而后边不跟数字,也不建议使用默认值。最好自己手动指定到位。
2.2 数组数据类型表
常用的基本数据类型如下表所示:
| 类型 | 类型代码/简写 | 描述 |
|---|---|---|
| int8,uint8 | i1,u1 | 有符号和无符号的8数位整数(-128~127)(0~255) |
| int16,uint16 | i2,u2 | 有符号和无符号的16数位整数(-32768~32767)(0~65535) |
| int32,uint32 | i4,u4 | 有符号和无符号的32数位整数(-2147483648~2147483647)(0~4294967295) |
| int64,uint64 | i8,u8 | 有符号和无符号的64数位整数(-9223372036854775808~9223372036854775807)(0~18446744073709551615) |
| float16 | f2 | 半精度浮点数:1个符号位,5位指数,10位尾数 |
| float32 | f4 | 标准单精度浮点数:1个符号位,8位指数,23位尾数 |
| float64 | f8 | 标准双精度浮点数:1个符号位,11位指数,52位尾数 |
| bool | ------------ | 存储一个字节的布尔值,存储True或False。(也可写为bool_) |
| complex64 | ------------ | 复数,由两个32位浮点表示(实部和虚部) |
| complex128 | 简写:complex_ | 复数,由两个64位浮点表示(实部和虚部) |
| datatime64 | ------------ | 日期和事件类型 |
| timedelta | ------------ | 两个时间类型的间隔 |
| string_ | S | ASCII字符串类型(即字节类型),eg:‘S10’ |
| unicode_ | U | Unicode类型(python3的默认字符串是Unicode类型),eg:‘U10’ |
其中unit16表示16位无符号整数,unit32表示32位无符号整数。
其中,复数不能转化为其他数值类型。
几种变换,简单了解。
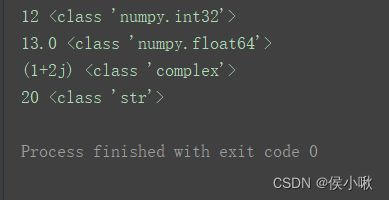
print(np.int32(12.56), type(np.int32(12.56)))
print(np.float64(13), type(np.float64(13)))
print(np.complex128(1+2j), type(np.complex(1+2j)))
print(np.unicode('20'), type(np.unicode('20')))
2.3 指定数据类型详解
根据上表,创建数组时,指定数据类型,可以使用类型的全名,也可以使用类型代码。
使用array(),zeros(),ones(),empty(),arange(),linspace(),logspace(),eye()等方法创建数组时都可以通过dtype参数指定数据类型。dtype默认为None。
下边通过一些调用示例,来完成这个部分的学习。
2.3.1 整数与浮点数
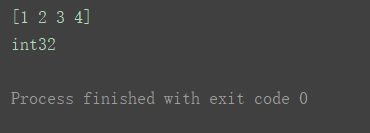
a1 = np.array([1.23, 2.34, 3.45, 4.56], dtype=int)
print(a1)
print(a1.dtype)
a2 = np.arange(0, 10, 2, dtype='int')
print(a2)
print(a2.dtype)
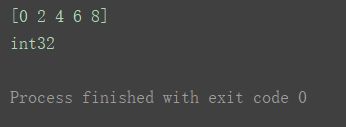
(不同:a1中传入的是关键字int,a2中传入的是字符串int。达到的效果一样。)
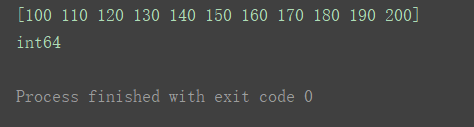
a3 = np.linspace(100, 200, 11, dtype='int64')
print(a3)
print(a3.dtype)
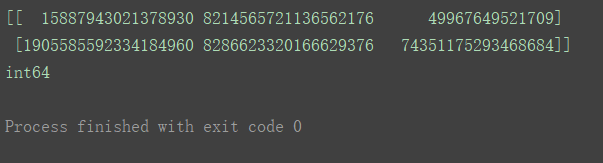
a4 = np.logspace(0, 10, 11, base=2, dtype='int32')
print(a4)
print(a4.dtype)
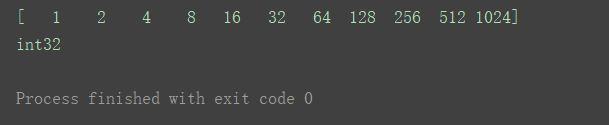
a5 = np.empty([2, 3], dtype='i8')
print(a5)
print(a5.dtype)
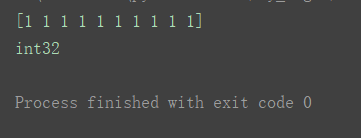
a6 = np.ones(10, dtype='i4')
print(a6)
print(a6.dtype)
a7 = np.zeros(10, dtype='f4')
print(a7)
print(a7.dtype)

print(a8)
print(a8.dtype)
2.3.2 字节类型
a9 = np.full((3, 4), '99.0', dtype='S')
print(a9)
print(a9.dtype)
a10 = np.full((3, 4), '99.0', dtype='S2')
print(a10)
print(a10.dtype)
a11 = np.full((3, 4), 'aaaaaaaaaaa', dtype='|S5')
print(a11)
print(a11.dtype)
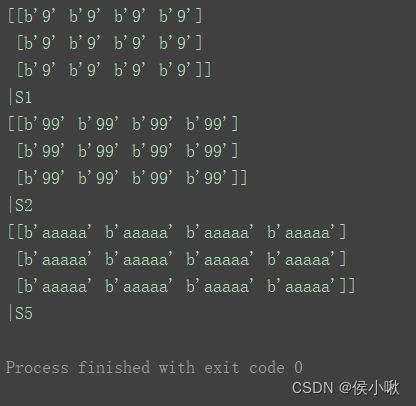
如图,数据类型分别是,一个字节,二个字节,五个字节。
直接指定为"S"表示S1,也可以在S前加一个竖杠"|’ 符号,这个符号可有可无。
如果传入汉字,则无法转化为字节,则发生报错。
a11 = np.full((3, 4), '侯小啾', dtype='S5')
print(a11)
print(a11.dtype)
报错。

2.3.3 字符串类型
python3的默认字符串是Unicode类型。
a12 = np.full((3, 4), '99.0')
print(a12)
print(a12.dtype)
a13 = np.full((3, 4), 99.0, dtype='U1')
print(a13)
print(a13.dtype)
a14 = np.full((3, 4), 99.0, dtype=')
print(a14)
print(a14.dtype)
a15 = np.full((3, 4), 99.0, dtype='U9')
print(a15)
print(a15.dtype)
字符长度长短不一时,数组的数据类型由数据中最长的字符串所决定。 支持汉字,这里一个汉字记为一个长度。 为了方便快速查看数组的属性,特定义以下函数,务必带走方便在学习及编程过程中随时调用。 对数据的结果进行重塑可以使用reshape() 或 resize()方法。 使用flatten()和ravel()方法,可以直接将数组从多维变为一维。 首先创建一个一维数组 创建一个二维数组 (关于三维及其以上的高维数组,使用为描述趋于) 重点,易混淆点!如果想要取出多个值(不用切片),则可以在括号内嵌套括号。 首先创建一个一维数组 创建一个二维数组 一种不太常用的用法可以了解一下, 使用布尔索引,不管原数组是几维,取出的数据存放在一个一维数组中。 准备两个数组的数据,两个数组的shape必须相同,才能进行加减乘除运算 数据具有广播机制 其规则为:如果两个数组的后缘维度(trailing dimension,即从末尾开始算起的维度)的轴长度相符或其中一方的长度为1,则认为他们是广播兼容的。广播会在缺失和(或)长度为1的维度上进行。 这里的后缘维度,即指的是二维数组中的行和列这两个维度,在更高维数组中则指0轴和1轴的两个维度。在进行加减乘除幂等运算时,广播机制将发挥作用, 这一点可以分为以下几种情况来理解: 例如, 再例如,一个1行8列的数组,可以和一个7行1列的数组进行运算,因为1行可以广播为7行,1列也可以广播为8列,经过广播后两数组之间的运算就相当于两个7行8列的数组之间的运算。 具体见下方示例演示: 读代码体会广播机制 读代码体会广播机制 读代码体会广播机制 行、列都不相同的两个数组,但是只要后缘轴存在长度为1的,就嫩运算: 比较运算,即可以得到能够作为布尔索引的条件的数组。 对于二维数组,可以按照水平方向增加数据,也可以按照垂直方向增加。 首先创建两个二维数组 在二维数组中,也许hstack()函数 和 vstack()比较常用,但是对于更高维度的数组之间,hstack()方法 与 vstack()方法则显得有些能力有限。它又是怎么执行的呢? 下边先准备一组三维数组合并的示例,然后对其进行解读。 在多维数组的0,1,2,3,4,5…众多轴中, vstack()函数仅仅作用于0轴 , hstack()函数 仅仅作用于1轴。不不能再以所谓的行、列来描述。 np.concatenate()方法在数组的合并中显得更为灵活,可以更好地操作高维数组,指定到每一个轴。 语法 concatenate(arrays, axis=None, out=None) 由于程序执行结果过长,这里不再展示,还请自行测试查看。 刚刚详述了合并的写法,这里的分割也是同理的。也是有三个方法,分别是上边三个方法hstack()、 vstack() 和 concatenate()的逆操作: 语法 hsplit(ary, indices_or_sections) 其中 indices_or_sections表示分割成几部分。分割时是均等分割,所以这个数字必须要够分。比如,所分的轴有4个对象的话,则可以被分成4部分,2部分。不能被分成3部分,5部分,否则会报错。 创建一个二维数组 创建一个更高维度的数组,以该四维数组为例。 遂执行以下删除操作,观察结果。依次删除每个维度的第一个对象。 对2轴 对3轴 准备一个简单二维数组 使用索引的方式对齐值进行修改 数组的查询除了可以使用索引和切片,还可以使用where方法。 np.where(condition,x,y) 结果返回一个数组,满足condition的元素位置为x,不满足的元素的位置为y。具体如下所示: 准备一个简单二维数组 表中,n1,n2,n都表示数组,x表示常数。 计算倒数时,要注意数据类型,如果数组数据类型为整数的话,多数整数的倒数会被显示为0。 调用示例展示如下: 语法 sort(a, axis=-1, kind=None, order=None) argsort()函数即排名函数。 argsort(a, axis=-1, kind=None, order=None) lexsort()可以实现对多个序列进行排序。(即多轮排序,可以当做是给表格排序,当第一个字段的值相同时比较第二个字段,第二个相同时比较第三个。) 要排序的列放在一个元组中传入lexsort()函数。排序时,优先排序传入时位置靠后的列。 如某选拔标准:先按照score排名,score相同的按ability,ability相同的按contribution 当要对数组进行某种变换时,可以将这种变换打包在函数中。这里使用到了np.apply_along_axis()方法。 语法: apply_along_axis(func1d, axis, arr, *args, **kwargs) 示例: 需求,求出数组每一行去除最大值和最小值后的平均值。 数组array和矩阵matrix是Numpy库中存在的两种不同的数据类型。 创建矩阵时,参数采用字符串形式传入,数据之间用空格隔开,行之间用引号隔开。 显然这样过于麻烦。 mat()方法只适用于创建二维矩阵,维度超过二维的array数组则更通用。 矩阵与标量之间的运算,即 (矩阵与标量的加减乘除运算效果与numpy数组相同。矩阵没有幂运算) 矩阵之间从乘法运算较特殊。 矩阵转置使用矩阵的 T T T属性。 可逆矩阵才可以求逆矩阵。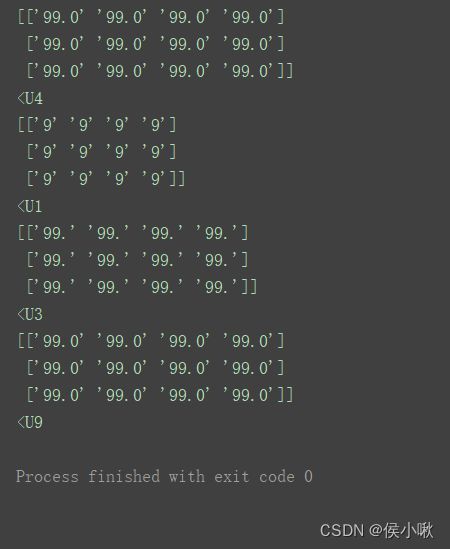
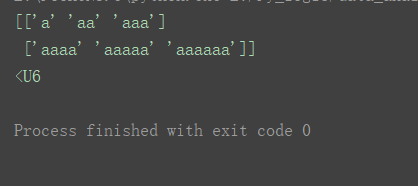
不指定时,则为数据中心字符串的长度的字符串类型,这里为U4,也可以写为
a16 = np.array([['a', 'aa', 'aaa'], ['aaaa', 'aaaaa', 'aaaaaa']])
print(a16)
print(a16.dtype)
a17 = np.array(['侯小啾', '支持小啾', '关注他!', '给他四连!'])
print(a17)
print(a17.dtype)
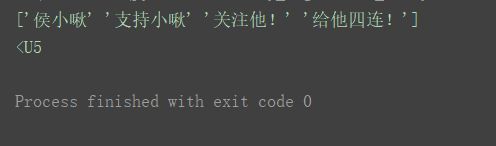
最长的字符是“给他四连!”,长度为5,所以数组的数据类型为"
3. 数组的属性 与 操作
3.1 数组的属性
def print_array(name, a):
print(name)
print(a)
print('rank = ', a.ndim) # 秩,即有几个轴,几维
print('shape = ', a.shape) # 形状
print('size = ', a.size) # 数据个数
print('data type = ', a.dtype) # 数据类型
print('element size = ', a.itemsize) # 每个元素占的字节数
print('data location = ', a.data) # 数据存储的位置
print()
n = np.array([[1, 2, 3], [4, 5, 6]])
print_array("数组n:", n)

3.2 数组的重塑
3.2.1 reshape()与resize()
这两种方法的区别在于使用reshape()不修改原数组,而resize()是对原数组进行修改。
# 新建一个一维数组
a1 = np.arange(30)
print(a1)
print("=====================")
# 一维变二维
a2 = a1.reshape((5, 6))
print(a2)
print("=====================")
# 一维变三维
a3 = a1.reshape((2, 3, 5))
print(a3)
print("=====================")
# 三维变一维
a4 = a3.reshape((30,))
print(a4)
print("=====================")
# 三维变二维
a5 = a3.reshape((5, 6))
print(a5)
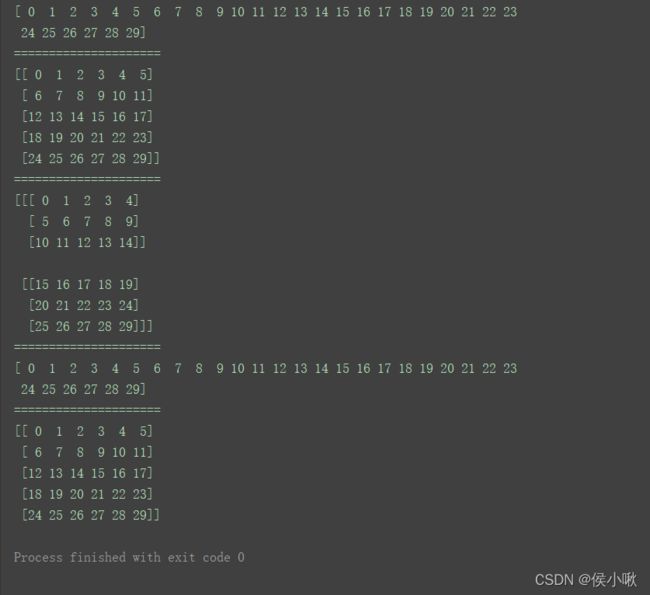
a1 = np.arange(30)
print(a1)
print("=====================")
# 一维变二维
a1.resize((5, 6))
print(a1)
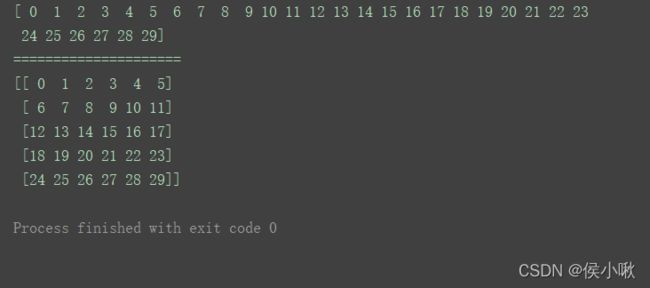
如图,用法resize()用法与reshape()一致,只是resize()直接修改了原数组a1。具体根据实践过程合理选择使用。
3.2.2flatten() 与 ravel()
a6 = a3.flatten()
print(a6)

a7 = a3.ravel()
print(a7)

fallen()与ravel()的区别在于,fallen()得到的新数组与原数组不共享存储,即为copy过来的,所以修改a3.fallen()时不会影响a3。而ravel()得到的新数组与原数组共享存储,修改a3.ravel()时,a3会被同步修改。
3.3 数组转置
n1 = np.arange(12).reshape(3, 4)
print(n1)
print(n1.shape)
print("=====================")
n2 = n1.T
print(n2)
print(n2.shape)
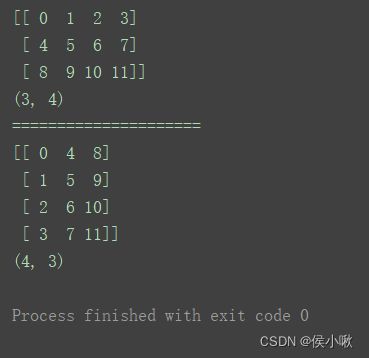
3.4 数组的索引与切片
3.4.1 索引
①一维数组为例
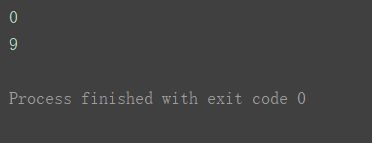
a1 = np.arange(10)
print(a1)
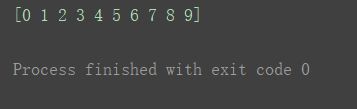
取出该数组第一个数值 和 最后一个数值print(a1[0])
print(a1[-1])
②二维数组为例
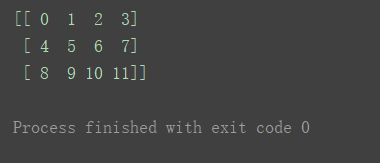
a2 = np.arange(12).reshape(3, 4)
print(a2)
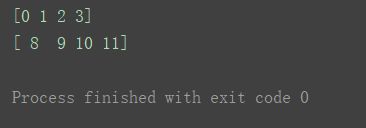
取出第一“行” 和 最后一“行”(这里说“行”只能用于二维数组,在更高维的数组是不准确的,不能说是行,而需要理解为是 在其所有维度中,序号为第一层的维度,或者说是最外层的维度 处的坐标。计数从0计起。):print(a2[0])
print(a2[-1])
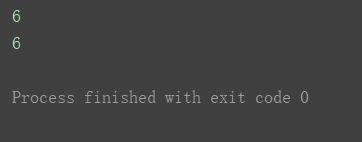
print(a2[1][2])
print(a2[1, 2])
③三维数组为例(高维)
a3 = np.arange(30).reshape((2, 3, 5))
print(a3)
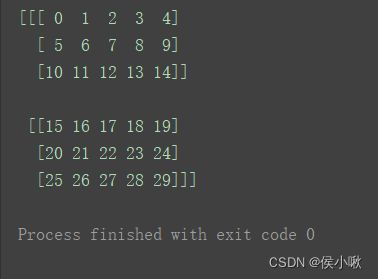
取出其最外层维度下的第一个对象:print(a3[0])
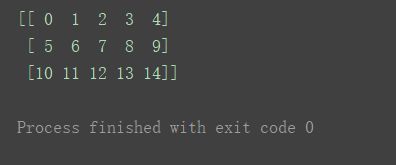
再剥一层:print(a3[0][1])
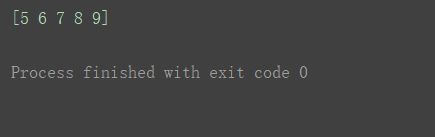
再剥一层:print(a3[0][1][2])
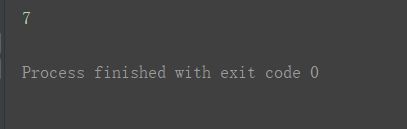
一个括号的写法:print(a3[0, 1, 2])
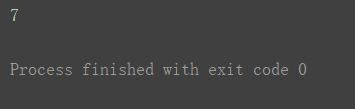
如下列代码,值得注意的是,这样取出的不是四个值,而是两个值。
不是在第二次取出1,2后,再分别在1,2两个行中取出2和3。而是取出的是(0,1,2)和(0,2,3)。print(a3[0, [1, 2], [2, 3]])
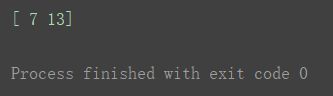
(这一点在学习了DataFrame的操作后后如果理解得不够透彻则容易弄混淆。)
3.4.2 切片
①一维数组为例
a1 = np.arange(10)
print(a1)
print(a1[2:5])
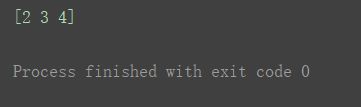
②二维数组为例
a2 = np.arange(30).reshape(5, 6)
print(a2)
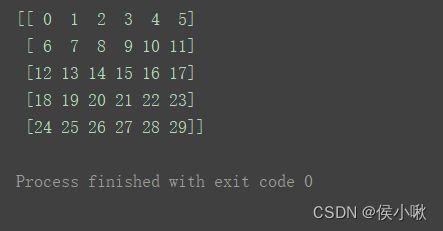
print(a2[2:4, 1:3])

start:stop 后边可以再接一个冒号和数值,该数值表示step,步长。
步长通常为正。
如果想要倒序取值,则需要满足start>stop,然后把步长设置为负值。(只把步长设为负值的话会得到一个空数组。)a1 = np.arange(10)
print(a1[2:7])
print(a1[2:9:2])
print(a1[9:2:-1])
print(a1[9:2:-2])

③三维数组为例(高维)
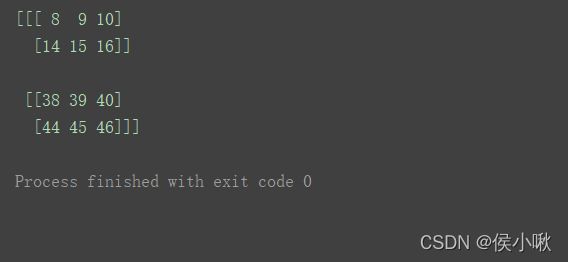
a3 = np.arange(120).reshape(4, 5, 6)
print(a3)
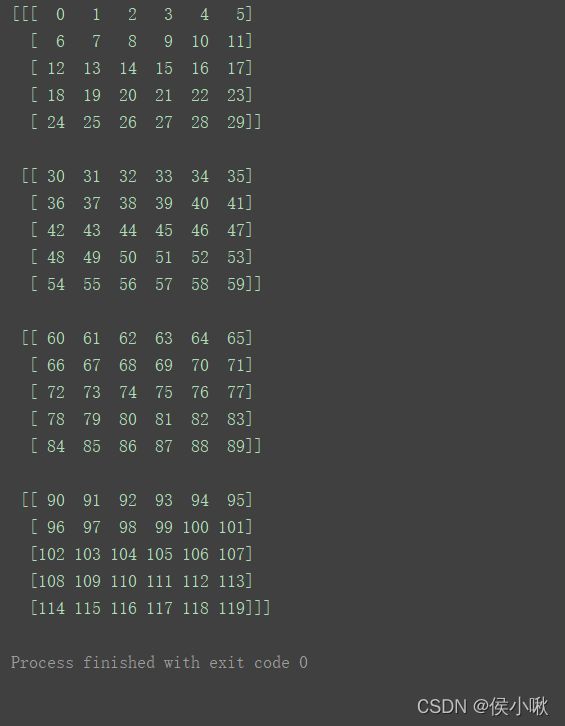
print(a3[0:2, 1:3, 2:5])
3.4.3 布尔索引
n1 = np.arange(30).reshape(5, 6)
print(n1)
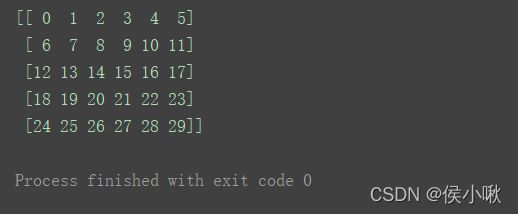
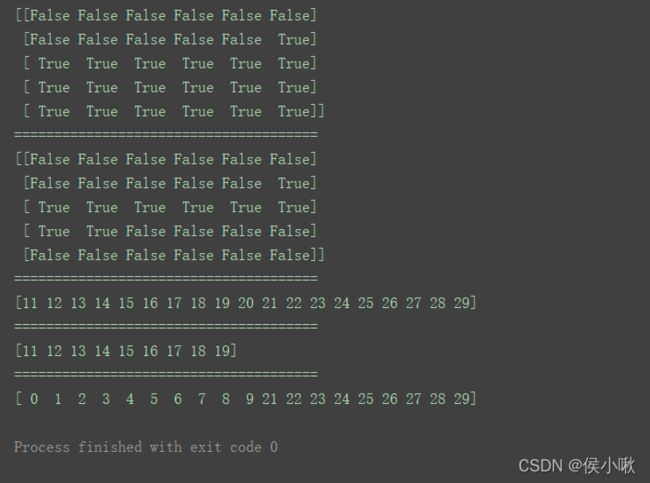
print(n1 > 10)
print("======================================")
print((n1 > 10) & (n1 < 20))
print("======================================")
print(n1[n1 > 10])
print("======================================")
print(n1[(n1 > 10) & (n1 < 20)])
print("======================================")
print(n1[(n1 < 10) | (n1 > 20)])
4. 数组运算
n1 = np.arange(1, 7).reshape(2, 3)
n2 = np.arange(7, 13).reshape(2, 3)
n3 = np.arange(4, 7).reshape(1, 3)
n4 = np.arange(5, 7).reshape(2, 1)
print(n1)
print("-------------------------------")
print(n2)
print("-------------------------------")
print(n3)
print("-------------------------------")
print(n4)
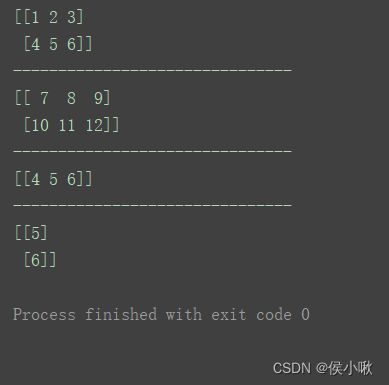
4.1 加、减、乘、除 & 幂运算
则广播机制不启用,数组中相同位置的数据一一对应进行运算。
具体可以分为以下几种情况:
一个4行5列的数组,可以与与一个1行5列的数组运算,运算时将次1行复制为4行;
也可以与一个5行1列的数组进行运算,运算时将该1列复制为5列。
但是不可以与一个4行2列、2行5列的数组进行运算。
也不可以与一个3行1列的数组,或者一个1行6列的数组进行运算。
print(n1+n2)
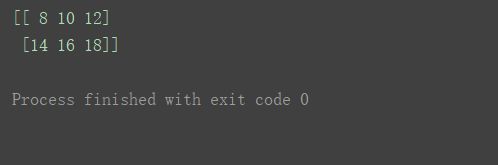
print(n1+n3)
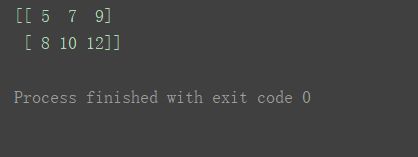
print(n1+n4)
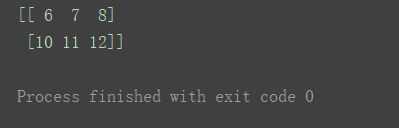
print(n3+n4)

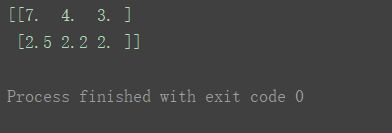
print(n2-n1)
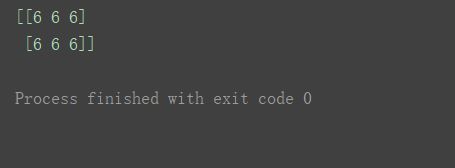
print(n1*n2)
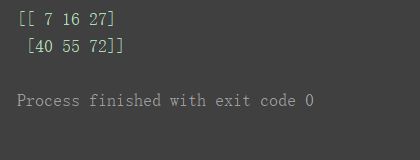
print(n2/n1)
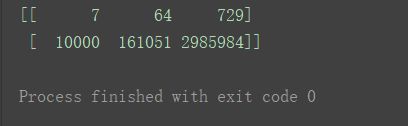
print(n2**n1)
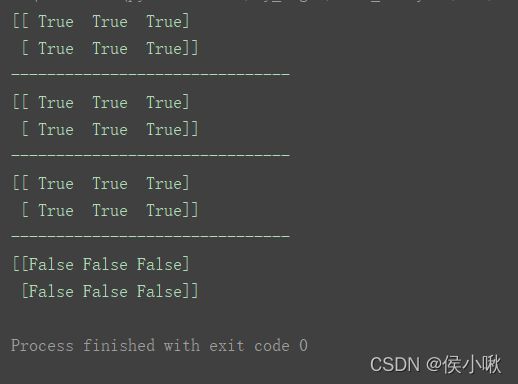
4.2 比较运算
print(n2 > n1)
print("-------------------------------")
print(n1 <= n2)
print("-------------------------------")
print(n1 != n2)
print("-------------------------------")
print(n1 == n2)
4.3 标量运算
print(n1 + 2)
print("-------------------------------")
print(n1 - 2)
print("-------------------------------")
print(n1 * 2)
print("-------------------------------")
print(n1 / 2)
print("-------------------------------")
print(n1 ** 2)

5. 数组增、删、改、查
5.1 数组的增加(也称扩展、拼接)
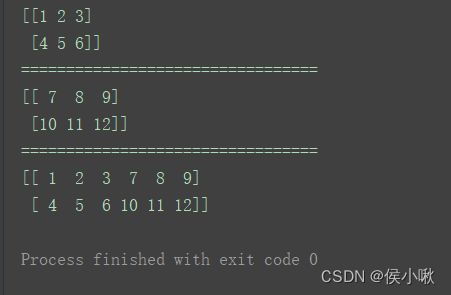
5.1.1 hstack()方法 与 vstack()方法
水平方向上的二维数组合并可以使用hstack()方法
垂直方向上的二维数组合并可以使用vstack()方法n1 = np.arange(1, 7).reshape((2, 3))
n2 = np.arange(7, 13).reshape((2, 3))
print(n1)
print("=================================")
print(n2)
print("=================================")
print(np.hstack((n1, n2)))
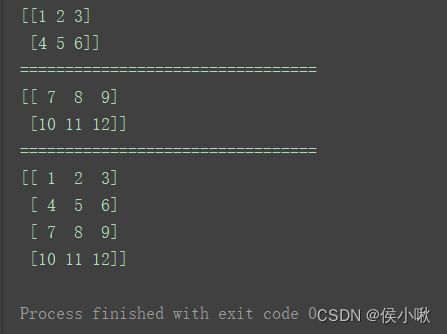
print(n1)
print("=================================")
print(n2)
print("=================================")
print(np.vstack((n1, n2)))
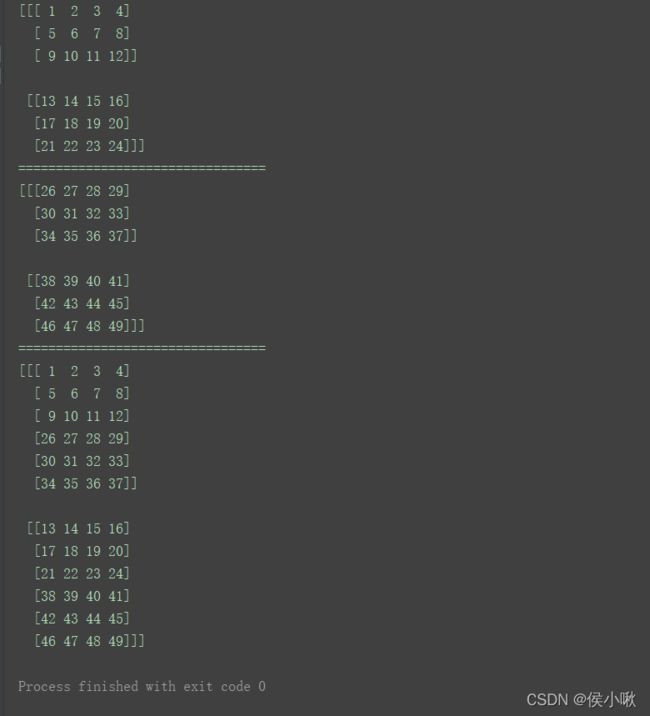
n1 = np.arange(1, 25).reshape((2, 3, 4))
n2 = np.arange(26, 50).reshape((2, 3, 4))
print(n1)
print("=================================")
print(n2)
print("=================================")
print(np.hstack((n1, n2)))
print(n1)
print("=================================")
print(n2)
print("=================================")
print(np.vstack((n1, n2)))
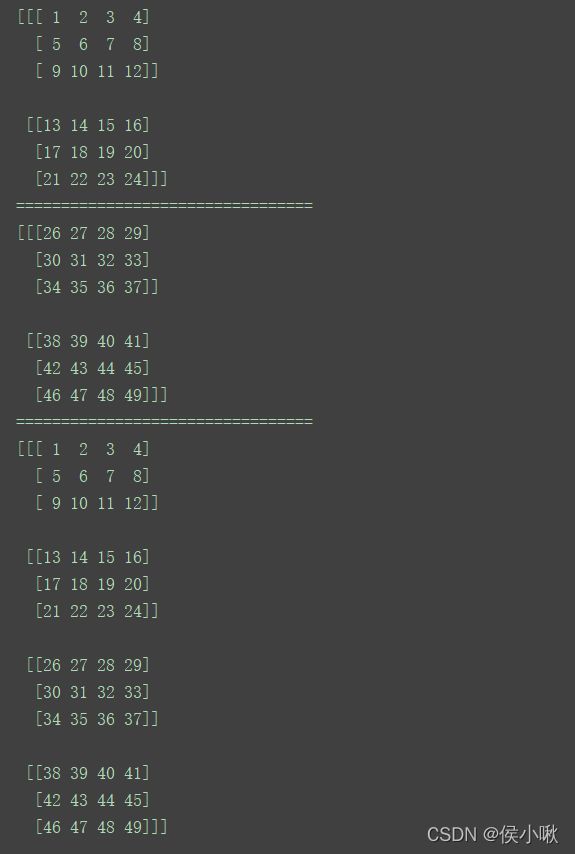
观察上述程序执行结果,不难发现规律。
根据上边二维数组和三维数组合并的四组示例,针对其shape的改变,可以表示为:
(2,3) + (2,3) → (4,3)
(2, 3, 4) + (2, 3, 4) → (4,3,4)
(2,3) + (2,3) → (2,6)
(2, 3, 4) + (2, 3, 4) → (2,6,4)
如果想要更方便地对数组进行合并,而且不限于数组的维度和轴,推荐使用使用**np.concatenate()**方法。
5.1.2 np.concatenate()方法
n1 = np.arange(1, 25).reshape((2, 3, 4))
n2 = np.arange(26, 50).reshape((2, 3, 4))
print(np.concatenate((n1, n2), axis=0))
print(np.concatenate((n1, n2), axis=1))
print(np.concatenate((n1, n2), axis=2))
5.1.3合并的逆操作—数组的分割split()
hsplit()、vsplit()、array_split()
hsplit()、vsplit()、array_split()。
vsplit(ary, indices_or_sections)
array_split(ary, indices_or_sections, axis=0)
a1 = np.arange(16.0).reshape(4, 4)
print(a1)
print("=================================")
print(np.hsplit(a1, 2))
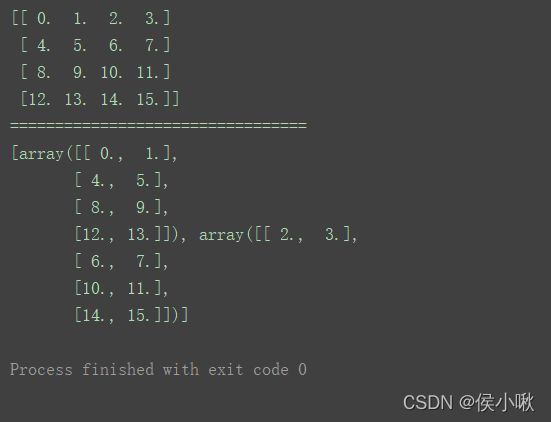
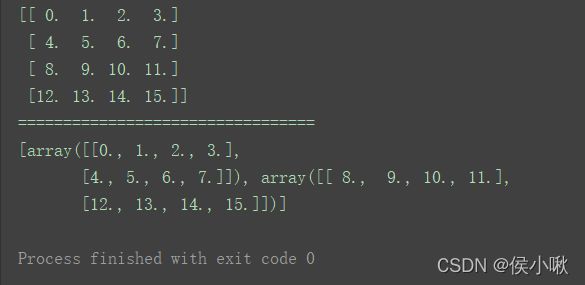
print(a1)
print("=================================")
print(np.vsplit(a1, 2))
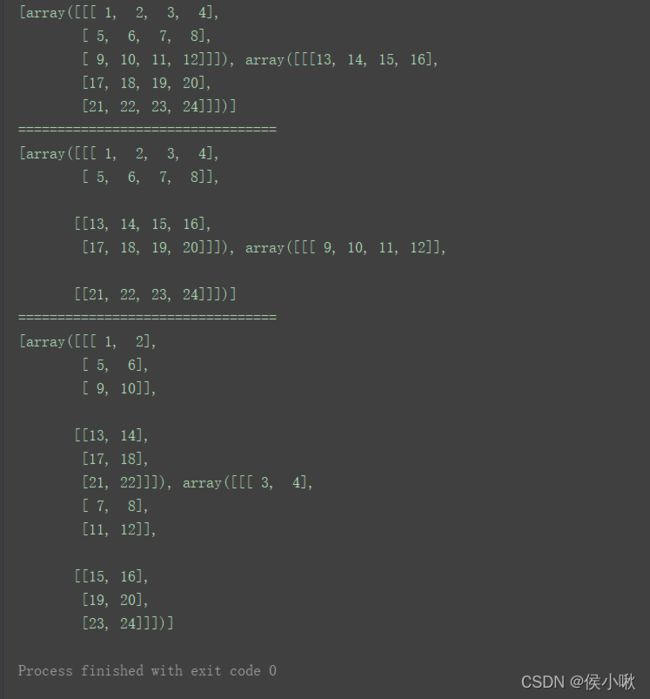
对一个三维数组:n = np.arange(1, 25).reshape((2, 3, 4))
print(n)

# 对0轴
print(np.array_split(n, 2)) # 默认axis=0
print("=================================")
# 对1轴
print(np.array_split(n, 2, axis=1))
print("=================================")
# 对2轴
print(np.array_split(n, 2, axis=2))
5.2 数组的删除
5.2.1 关于二维数组
n = np.array([[1, 2], [3, 4], [5, 6]])
print(n)
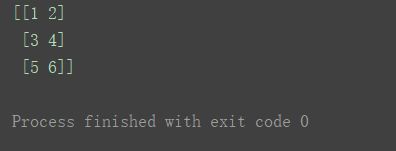
axis为0表示删除行,axis为1表示删除列。n1 = np.delete(n, 2, axis=0) # 删除一行 (第3行)
print(n1)
print("-------------------------------")
n2 = np.delete(n, 0, axis=1) # 删除一列,第1列
print(n2)
print("-------------------------------")
n3 = np.delete(n, (1, 2), 0) # 删除多行
print(n3)
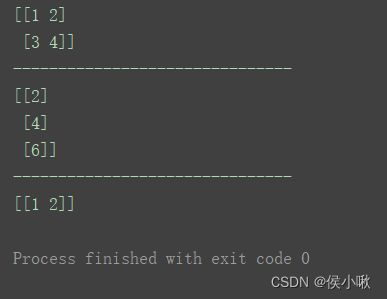
5.2.2站在更高维度来理解
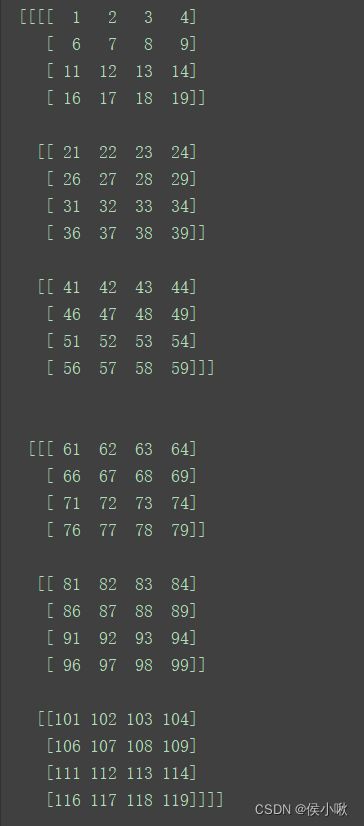
a = np.arange(120).reshape(2, 3, 4, 5)
print(a)
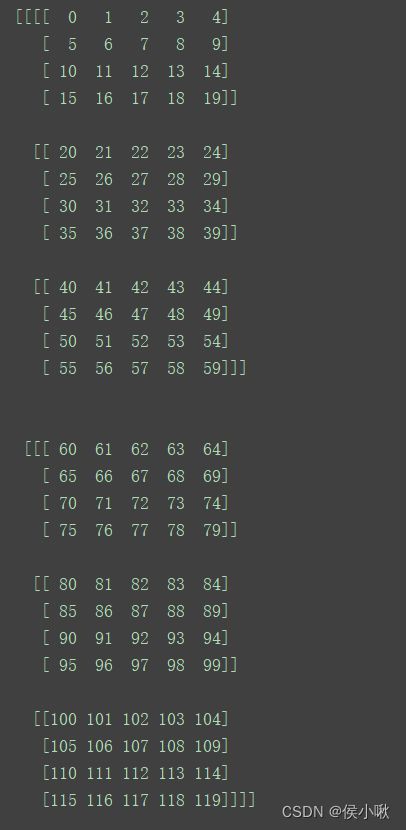
该数组的数据结构如图所示。该数组shape为(2 ,3, 4, 5)共有4个轴,分别记为0轴,1轴,2轴,3轴。
从上图数据来看,0轴即最外层的部分,包含两个数组对象。
1轴,2轴,3轴依次向内。
其中1轴则包含三个数组对象
2轴包含四个数组对象,即我们在二维中所说的“行”,
3轴在最内层,包含了5个数据对象(不再是数组对象),也即为二维中我们所说的“列”。
a1 = np.delete(a, 0, axis=0)
print(a1)
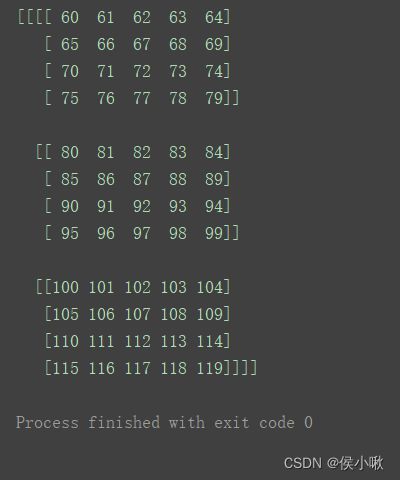
a2 = np.delete(a, 0, axis=1)
print(a2)
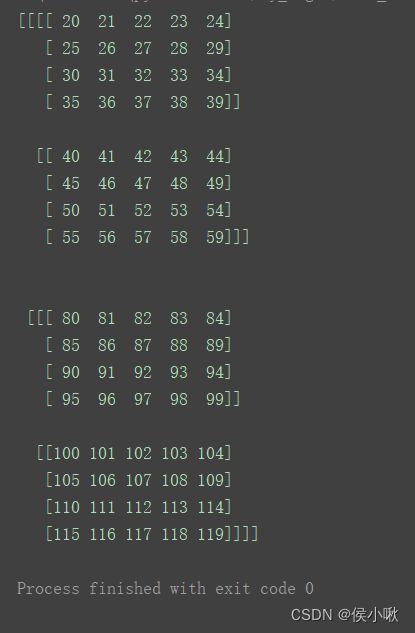
a3 = np.delete(a, 0, axis=2)
print(a3)
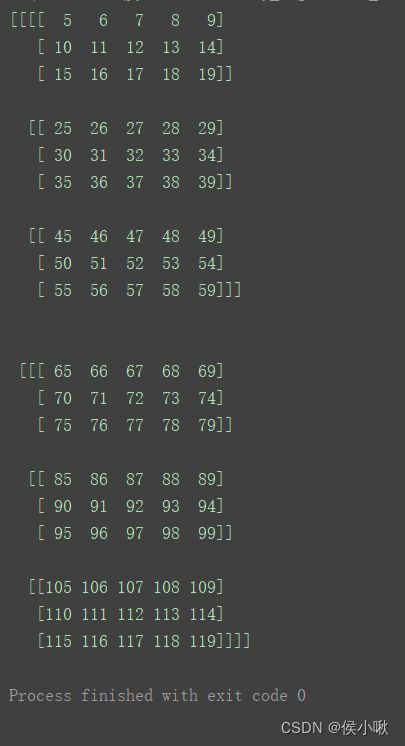
a4 = np.delete(a, 0, axis=3)
print(a4)
5.3 数组的修改
n = np.array([[1, 2], [3, 4], [5, 6]])
print(n)
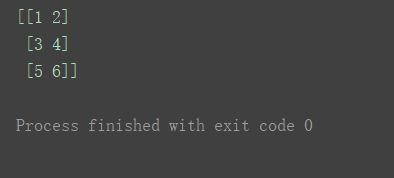
则用一个数组来赋值n[1] = [10, 20]
print(n)
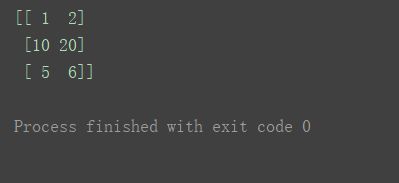
如过要修改为相同的值,也可以这样,直接某一轴(行、列)赋值一个常数。n[1] = 10
print(n)
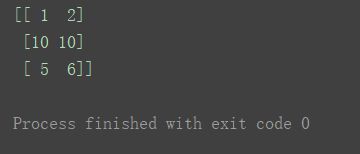
n[1][1] = 100
print(n)
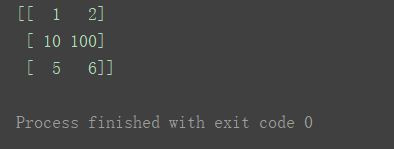
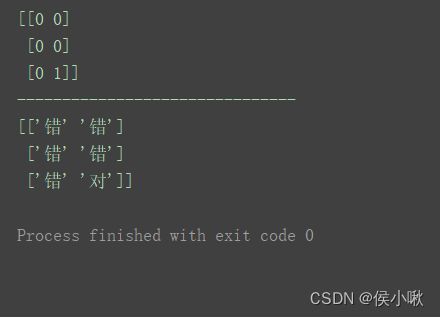
5.4 数组的查询
语法:
n = np.array([[1, 2], [3, 4], [5, 6]])
print(n)
print(np.where(n > 5, 1, 0))
print("-------------------------------")
print(np.where(n > 5, '对', '错'))
6.Numpy常用统计分析函数
6.1 基本运算函数
函数
描述
示例
add()
加
np.add(n1,n2),np.add(n1,2)
subtract()
减
subtract(n1,n2),subtract(n1,3)
multiply()
乘
multiply(n1,n2),multiply(n1,3)
divide()
除
divide(n1,n2),divide(n1,2)
abs()
绝对值
abs(n)
square()
平方
square(n)
sqrt()
平方根
sqrt(n)
log()
自然对数
log(n)
log10()
以10为底的对数
np.log10(n)
log2()
以2位底的对数
np.log2(n)
reciprocal()
求倒数
np.reciprocal(n)
power()
第一个数组中的元素作为底数,第二个数组中元素为指数,相应位置之间求幂
np.power(n1, n2)
mod()
求相除后的余数
np.mod(n1, n2)
around()
制定小数位数,四舍五入
around(n, x)
ceil()
向上取整
np.ceil(n)
floor()
向下取整
np.floor(n)
sin()
正弦函数
np.sin(n)
cos()
余弦函数
np.cos(n)
tan()
正切函数
np.tan(n)
modf()
将元素的小数部分和整数部分分割开,得到两个独立的数组(两个数组放在一个元组里返回)
np.modf(n)
exp()
以自然对数的底e为底数,数组中的数字为指数,求幂
np.exp(n)
sign()
求符号值,1表示正数,0表示0,-1表示负数
np.sign(n)
maximum()
求最大值
np.maximum(n)
fmax()
求最大值,同上
----------
minimum()
求最小值
np.minimum(n)
fmin()
求最小值,同上
-----------
copysign(a,b)
将数组b的符号给数组a对应的元素
copysign(n1,n2)
6.2统计分析函数
函数
描述
sum()
求和
cumsum()
累计求和
cumprod()
累计求积
mean()
求均值
min()
求最小值
max()
求最大值
average()
求加权平均值
meaian()
求中位数
var()
求方差
std()
求标准差
eg()
对数组第二维度的数据求平均
argmin()
获取最小值的下标 (是变换为一维下的下标)
argmax()
获取最大值的下标 (是变换为一维下的坐标)
unravel_index()
一维下标转为多维下标
ptp()
计算数组最大值和最小值的差(极差)
n = np.array([[3, 2, 1], [4, 5, 6], [9, 8, 7]])
print(n)
print("==================")
# 求和
print(n.sum())
# 求累加
print(n.cumsum())
# 求累积

n = np.array([[3, 2, 1], [4, 5, 6], [9, 8, 7]])
print(n)
print("==================")
print(n.cumprod())
# 求均值
print(n.mean())
# 求最大值
print(n.max())
# 求最小值
print(n.min())
# 求每一列的最大值
print(n.max(axis=0))
# 求每一列的最小值
print(n.min(axis=0))
# 求每一行的最大值
print(n.max(axis=1))
# 求每一行的最小值
print(n.min(axis=1))
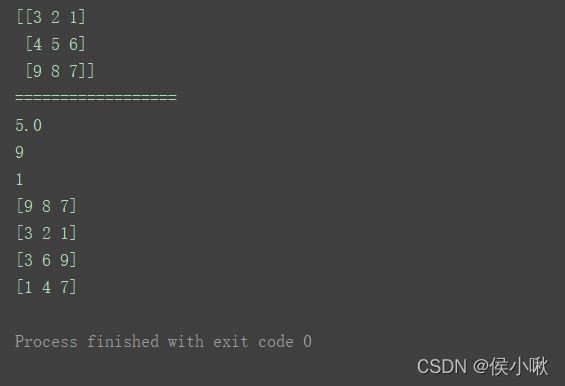
n = np.array([[3, 2, 1], [4, 5, 6], [9, 8, 7]])
print(n)
print("==================")
# 求加权平均
w = [[12, 15, 16], [14, 10, 8], [10, 14, 12]]
print(np.average(n, weights=w))
# 求中位数
print(np.median(n))
# 求方差、标准差
print(np.var(n))
print(np.std(n))
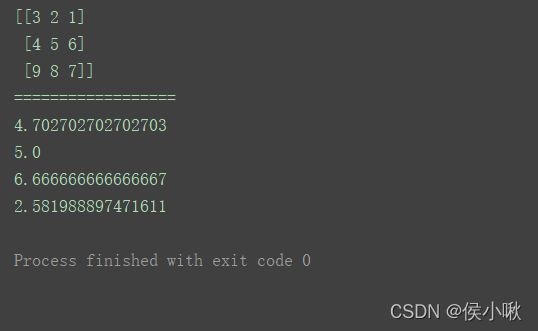
# 求最小值、最大值在 数组变换为一维下 的坐标
print(np.argmin(n))
print(np.argmax(n))
# 输入一个一维下的坐标(一个数字),返回这个坐标在多维数组下的坐标
print(np.unravel_index(5, n.shape))
# print(np.unravel_index(np.argmax(n),n.shape))
# 求极差
print(np.ptp(n))

6.3数组的排序
sort()
n = np.array([[3, 5, 9], [4, 1, 6], [2, 8, 7]])
print(n)
print("======按最后一个轴(1轴)======")
np.sort(n)
print(n)
print("=======按0轴========")
np.sort(n, axis=0)
print(n)
print("========按1轴========")
np.sort(n, axis=1)
print(n)
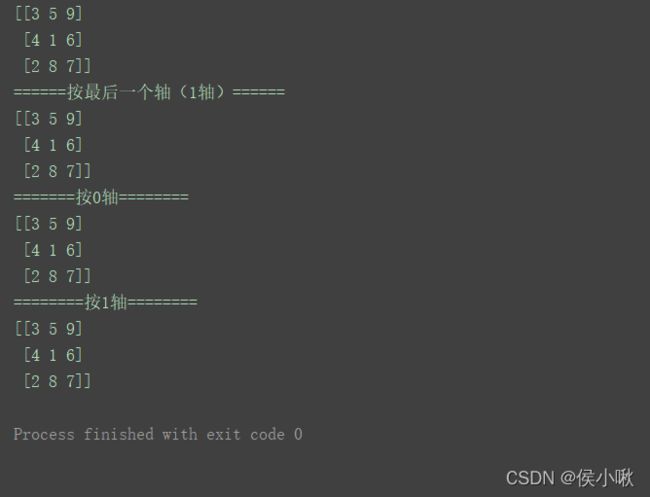
argsort()
语法
print("======按最后一个轴(1轴)======")
print(np.argsort(n))
print("=======按0轴========")
print(np.argsort(n, axis=0))
print("========按1轴========")
print(np.argsort(n, axis=1))
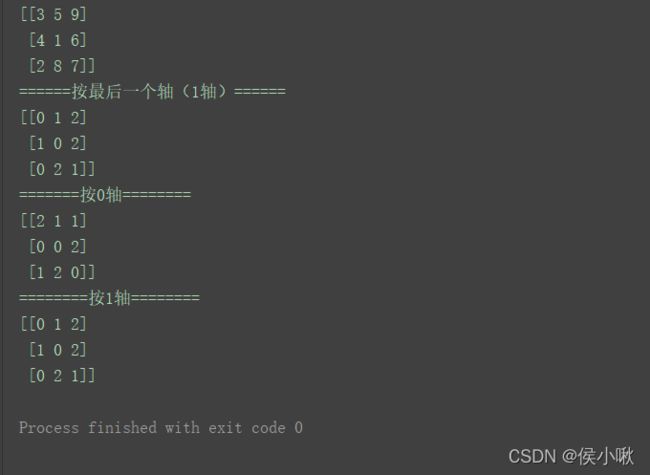
lexsort()
具体见下例:
按此标准进行排名:names = np.array(["a某", "b某", "c某", "d某", "e某", "f某"])
score = np.array([97, 90, 100, 97, 96, 96])
ability = np.array([80, 94, 86, 80, 77, 89])
contribution = np.array([98, 81, 94, 93, 88, 83])
# sort_result排序时,优先排序传入时位置靠后的列
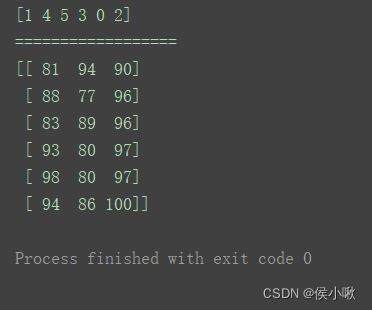
sort_result = np.lexsort((contribution, ability, score))
print(sort_result)
print("==================")
# 输出排名后的表格:
print(np.array([[contribution[i], ability[i], score[i]] for i in sort_result]))
6.4 自定义功能函数 np.apply_along_axis()
a = np.arange(16).reshape(4, 4)
print(a)
print("=========================================")
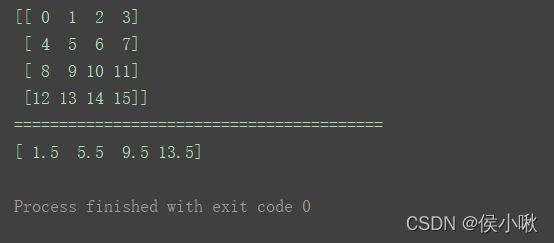
b = np.apply_along_axis(lambda x: x[(x != x.max()) & (x != x.min())].mean(), axis=1,arr=a)
print(b)
6.5 数组的去重 unique()
a = np.array([12, 14, 23, 28, 12, 11, 35, 30, 12, 35])
print(np.unique(a))
print(np.unique(a, return_counts=True))
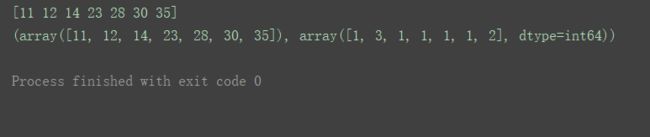
return_counts设置为True后,可以同时打印出每个值在原数组中出现的次数。
7.numpy矩阵
7.1 创建矩阵
mat()方法创建简单矩阵
如下示例所示:a1 = np.mat("1 2;3 4")
print(a1)
print("==========================")
a2 = np.mat("1 2 3;4 5 6;7 8 9")
print(a2)
print(type(a2))

此外,也可以通过传入数组 来实现矩阵的快速创建。
创建随机小数 矩阵
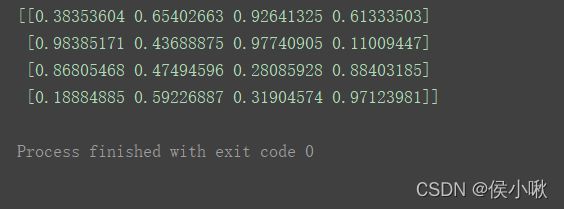
print(np.mat(np.random.rand(4, 4)))
创建随机整数矩阵
print(np.mat(np.random.randint(1, 100, size=(5, 5))))
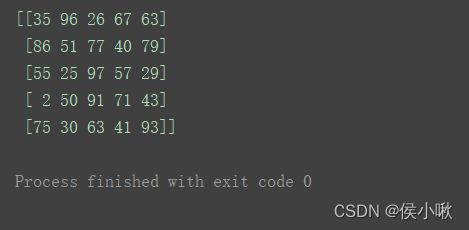
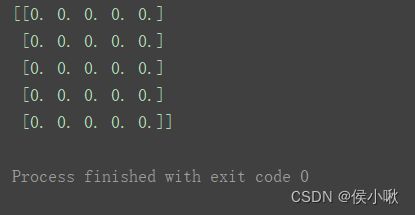
创建全零矩阵
m = np.mat(np.zeros((5, 5)))
print(m)
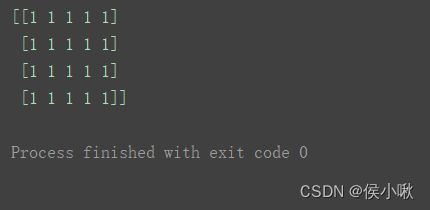
创建全一矩阵
m = np.mat(np.ones((4, 5), dtype='i8'))
print(m)
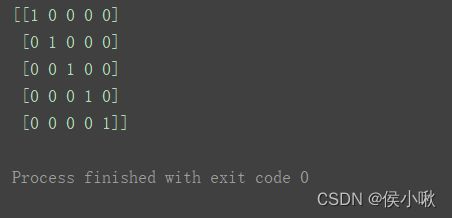
创建对角矩阵
m = np.mat(np.eye(5, dtype='i8'))
print(m)
创建 对角线 矩阵
a = [1, 2, 3, 4, 5]
m = np.mat(np.diag(a))
print(m)
7.2 矩阵运算
①矩阵与标量运算
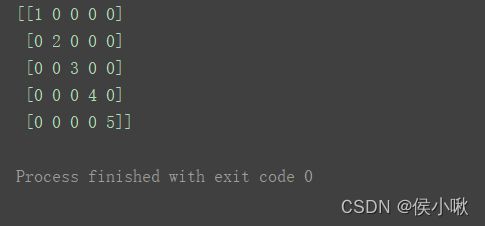
将矩阵中的每一个元素分别与这个标量运算,结果得到的矩阵与原矩阵有着相同的shape。m1 = np.mat([[3, 4], [6, 12], [9, 20]])
print(m1)
print("=======================")
print(m1 + 2)
print("=======================")
print(m1 - 2)
print("=======================")
print(m1 * 2)
print("=======================")
print(m1 / 2)
②矩阵与矩阵运算
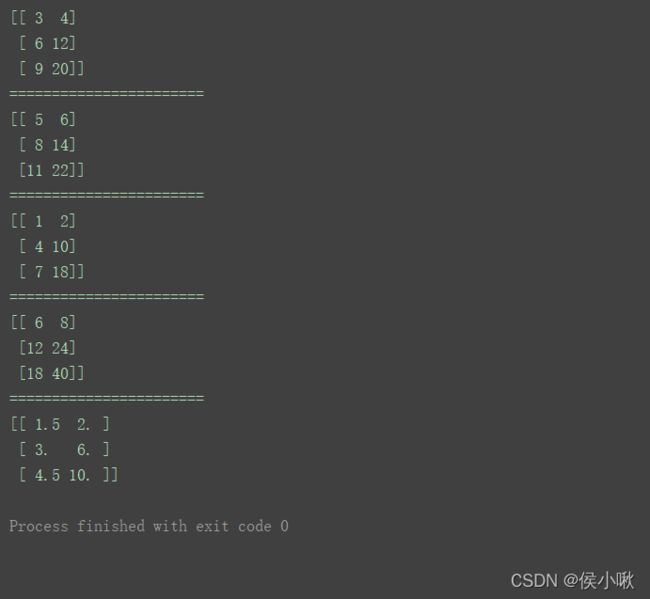
m1 = np.mat([[3, 4], [6, 12], [9, 20]])
m2 = np.mat([3, 4])
print("==========m1===========:")
print(m1)
print("==========m2===========:")
print(m2)
print("======= m1 + m2 =======:")
print(m1 + m2)
print("======= m1 - m2 =======:")
print(m1 - m2)
print("========m1 / m2 =======:")
print(m1 / m2)
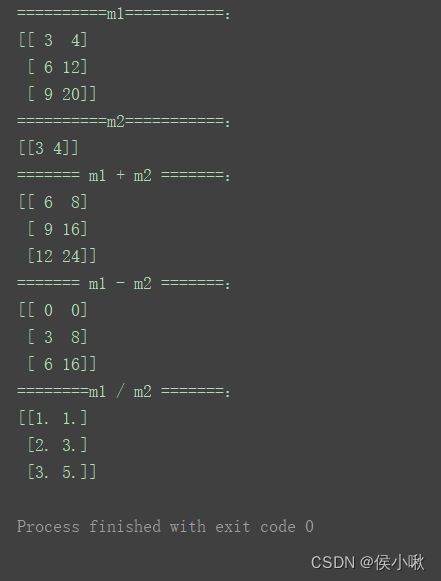
这里展示了矩阵之间加、减、除的运算。
m1 × m2 ,必须满足m1的列数等于m2的行数,才可计算。
且 m1 × m2 与 m2 × m1 是不可逆的。
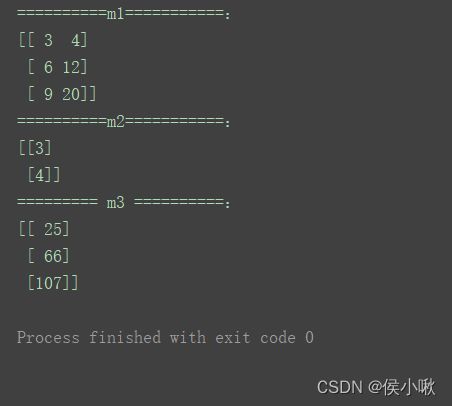
示例如下:m1 = np.mat([[3, 4], [6, 12], [9, 20]])
m2 = np.mat([[3], [4]])
m3 = m1 * m2
print("==========m1===========:")
print(m1)
print("==========m2===========:")
print(m2)
print("========= m3 ==========:")
print(m3)
7.3 矩阵转换
转置
m = np.mat([[3, 4], [6, 12], [9, 20]])
print(m)
print("====================")
print(m.T)
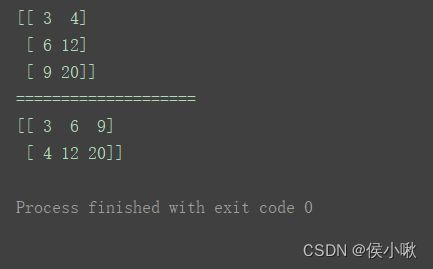
逆矩阵
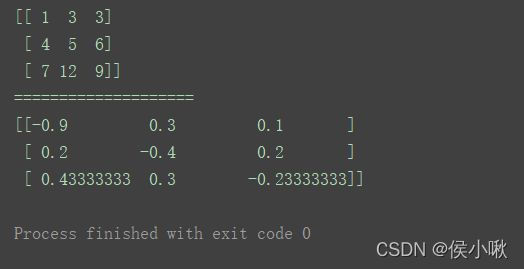
求逆矩阵使用矩阵的 I I I属性即可。m = np.mat("1 3 3;4 5 6;7 12 9")
print(m)
print("====================")
print(m.I)