实时语义分割调研
文章目录
-
- 0. 前言
- 1. 语义分割概述
- 2. 一些总结
- 3. 论文浏览
-
- 3.1 ENet
- 3.2 ICNet
- 3.3 BiSeNet
- 3.4 CGNet
- 3.5 DFANet
- 3.6 Fast-SCNN
- 3.7 BiSeNetV2
- 3.8 HyperSeg
- 3.9 Rethinking BiSeNet For Real-time Semantic Segmentation
0. 前言
- 实时语义分割(real-time semantic segmentation),目标是能实时跑在CPU上。
- 本文调研的基本都是普通的语义分割方法,之后还会调研一下 matting、foreground segmentation、portrait segmentation。
- 由于本次调研的目标是实现二分类语义分割,所以一开始在想是不是有一些专门为“二分类”设计的语义分割模型,调研了很多关键词,涨了很多见识,但最终没啥用(踩了不少坑),这里记录一下。
- Image Matting:就是所谓的抠图
- 乍一看需求非常类似,但实际有很大区别。对于原始图像中每一个像素:matting的结果包括三个部分,前景图像rgb、背景图像rgb、前景的透明度alpha;segmentation的结果只有一个,即类别标签。
- 由于任务定义明显不一样,而且好像没有特别好的移动端可运行的模型,所以没有进一步调研。
- 参考资料:【AI-1000问】segmentation和matting有什么区别?,人像抠图:算法概述及工程实现
- Video Object Segmentation:这个是实例分割与目标跟踪结合,代表数据集是 DAVIS。现在连多目标跟踪距离实际应用都还有较大差距,那基于实例分割的目标跟踪估计更差了,所以没细看。
- Background Subtraction(foreground detection、foreground segmentation):这个看起来跟我们想要的很像(至少看名字觉得这就是我们需要的),但其实还有区别
- 从我们目前SLAM的需求看,前景、背景的定义基本上就是类似于全景分割。
- 然而,在Background Subtraction 相关论文基本中,本质就是 Change Detection 或Moving Object Segmentation,就是移动移动物体的分割,这个与我需要的场景有所不同,所以没细看。
- 另外,浏览了几篇,感觉上速度都不是特别好。
- Image Matting:就是所谓的抠图
1. 语义分割概述
- 语义分割的定义:
- 简单说,就是“像素级分类”。
- 输出一张与输入图像尺寸相同的图片,每个像素的数值就是类别编号。
- 语义分割、实例分割、全景分割如下图所示:
- 语义分割:只区分类别,不区分个体
- 实例分割:只关注前景(可计数物体)的分割,并区分个体
- 全景分割:前景(可计数物体,如人、车)进行实例分割,背景(如天空、道路)进行语义分割。

- 常见数据集:其实没啥好说的,资料特别多(毕竟是自动驾驶场景)。
- 主要性能指标:mIoU
2. 一些总结
- 看了一些论文,浏览笔记参考第三章。本章谈一谈看完论文的一些感受。
- 要选就选最新的开源项目看看就好。
- 实现实时语义分割的总体模型结构结构并没有什么非常不一样的地方:
- 基本上不使用ASPP,因为太耗时了,不符合实时场景。
- 对基本结构的各种剪枝。
- 使用双路结构,一路空间信息,一路context(感受野大)信息,两路融合。
- 实现实时语义分割的方法、研究方向有:
- 缩小输入图像尺寸。这个立竿见影,会导致信息丢失,小目标、目标边缘信息容易搞错,而且有些场景不能缩小图像尺寸。
- 模型剪枝、压缩。大概就是使用轻量化模型结构(如depthwise/pointwise/depth seperable等),减少channels数量,减少卷基层数量等。
- 设计新的decoder结构
- 双路结构中:
- 双路结构本身如何设计(如两路公用卷基层)
- 两路信息如何融合
- 模型训练方法
3. 论文浏览
- 下面提到的网络基本都有开源。
3.1 ENet
- 相关资料:
- arxiv
- github
- 论文解读,翻译
- 论文基本信息
- 领域:图像分割
- 作者单位:华沙大学&普杜大学
- 发表时间:2016.6
- 一句话总结:早期的轻量化语义分割论文,在普通语义分割模型的基础上,使用了分解卷积、空洞卷积、轻量化decoder、减少下采样次数等trick
- 要解决什么问题
- 可以说是实时语义分割最早的文章(之一),目标就是设计能够实时运行的语义分割模型。
- 用了什么方法
- 一些轻量化语义分割模型的设计思路
- 减少上、下采样的次数(FCN中下采样到1/32,而ENet中只到1/4),因为频繁下采样会导致信息缺失。
- 使用轻量化的Decoder(本文就是使用了segnet的decoder),而不是UNet的对称结构。
- 实验发现,去掉前面几个conv的relu效果会变好,测试后认为原因是网络深度不够。所以使用prelu替换relu。
- 使用分解卷积(
5*5 -> 1*5+5*1,分解后计算量大概相当于3*3) - 使用空洞卷积,提高感受野,效果很好。
- 正则化,即dropout。
- 下采样很必要,但会丢失信息。为了减少信息丢失,下采样是分别进行conv和max pooling,然后对两者结果concat,保留更多信息。
- 网络结构如下图
- 在conv(可能是普通卷积、空洞卷积、转置卷积)后添加bn和prelu。
- 下表就是整体结构,可以看到下采样只下采样2次。
- 一些轻量化语义分割模型的设计思路

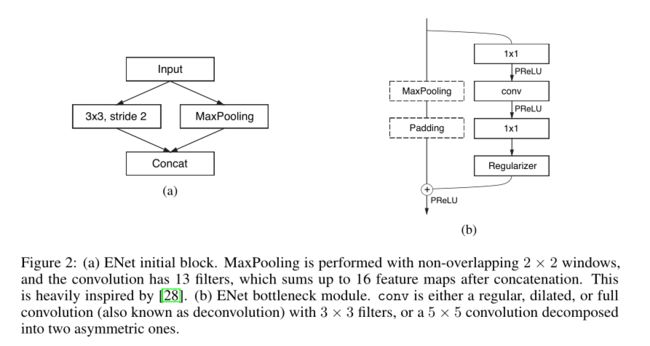
- 效果如何:与当时其他论文比,加速18倍,计算量减少75倍,参数减少79倍,效果差不多。
- 存在什么问题&有什么可以借鉴的:早期论文,看个热闹
- 减少下采样会对大物体识别分割造成影响,从而降低精度。
3.2 ICNet
- 相关资料:
- arxiv
- github(Matlab)
- 论文解读
- 论文基本信息
- 领域:图像分割
- 作者单位:港中文
- 发表时间:2017.4,ECCV 2018
- 一句话总结:设计了一种级联结构(同一张图像不同尺寸分别Encode,然后结果融合,统一decode),实现高清图像实时语义分割
- 要解决什么问题:
- 当时的实时语义分割,基本上都是要求减少输入图像尺寸。
- 然后,有一些应用,图像尺寸就是不能减少。
- 用了什么方法
- 分析不同尺寸输入数据对PSPNet的计算量影响可以发现,图片尺寸是影响语义分割计算量的主要因素。
- 基于这个发现,之前的研究使用一些策略来简化计算量,包括下采样输入、缩小特征图、模型压缩,但效果都不好。
- 使用了级联结构,同一张图片resize到不同尺寸作为输入。
- 可以认为是高(原始尺寸)、中(1/2)、低(1/4)三种分辨率作为输入,作为三个分支
- 分支融合,其实就是使用了CFF结构,两个尺寸不同的特征图的融合,结构图下面有图。
- CFF分支分为两路,一路用于计算loss,一路用于后续网络
- 分析不同尺寸输入数据对PSPNet的计算量影响可以发现,图片尺寸是影响语义分割计算量的主要因素。
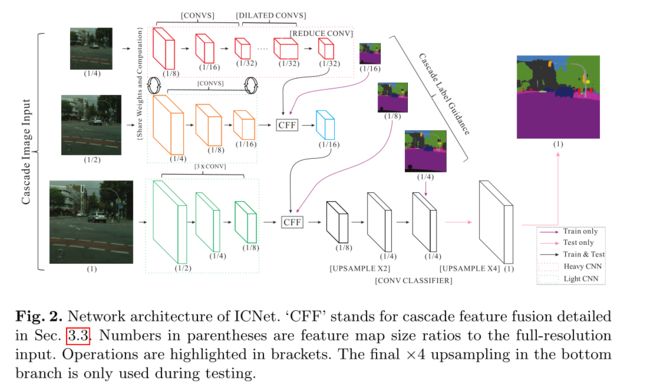

- 效果如何:输入1024*2048的图像,在TitanX上达到实时(30fps以上),且准确率降低较少。
- mIoU是Cityscapes test set的效果。
- 从下图中就可以看到,当时的实时语义分割多么匮乏。。

- 存在什么问题&有什么可以借鉴的:TitanX上勉强实时……感觉对现在的帮助并不大,看个热闹。
3.3 BiSeNet
- 相关资料:
- arxiv
- github
- 论文解读(旷视自己出的解读)
- 论文基本信息
- 领域:图像分割
- 作者单位:华中科技&北大&旷视
- 发表时间:2018.8,ECCV 2018
- 一句话总结:使用双路结构(spatial路保留空间信息,context路感受野较大)结构,实现实时语义分割。
- 要解决什么问题
- 实时语义分割中,降低计算量的主要方法是:减少输入图像尺寸,降低模型复杂度(即使用轻量化backbone,或减少backbone中特征图的channels,减少下采样次数如ENet),然而这两者都会大大降低精度。
- UNet是分割的基础结构,能够提高精度,增加空间信息。但在实时场景下缺陷很大,一是UNet增加计算量,2是由于轻量化网络会剪裁模型,导致UNet中Decoder不能通过浅层网络恢复空间信息,导致精度不够。
- 如何在语义分割任务中应用轻量级模型,兼顾实时性和精度性能具有相当大的挑战性。
- 用了什么方法
- BiSeNet是 Bilateral Segmentation Network 的缩写,Bilateral是“双边;左右对称”的意思,可以理解为“双路网络”。
- 双路分别是 Spatial Path 和 Context Path,分别解决空间信息缺失和感受野缩小的问题。
- Spatial Path 的网络比较浅,感受野较小,但特征图尺寸较大;Context Path网络比较深,感受野较大,但特征图尺寸小。两个网络融合,就能缓解感受野较小(对大目标分割效果较差)、特征图尺寸较小(物体边缘分割效果较差)的问题。
- PS:旷视自己的文章中翻译为双向,评论中提高觉得还是“双路”比较好,我也觉得后者比较好。
- 下面有两张图
- 第一张图介绍了 BiSeNet 的设计思路,a子图表示了通过输入数据resize和网络剪枝实现的轻量化语义分割,b子图表示UNet结构剪枝的实时语义分割,c子图就是BiSeNet的思路
- 第二张图详细说明了BiSeNet的结构,为了更好的融合两路信息,以及对结果再次修正,分别设计了Feature Fusion Module 和 Attention Refinement Module
- 最终结果是直接线性插值增加8倍
- BiSeNet是 Bilateral Segmentation Network 的缩写,Bilateral是“双边;左右对称”的意思,可以理解为“双路网络”。

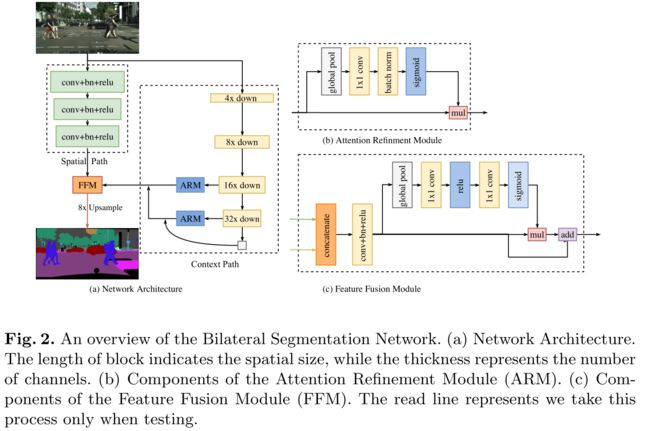
- 效果如何:跟之前的实时语义分割模型比,又快又好

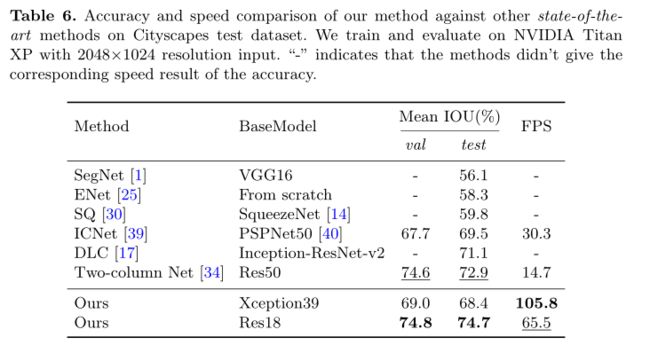
- 存在什么问题&有什么可以借鉴的:最后这个8倍的upsample,感觉还是不太靠谱
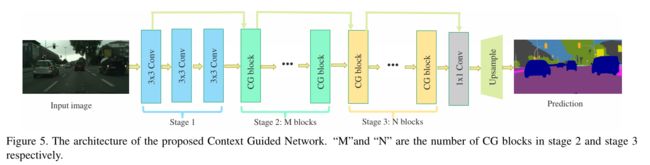
3.4 CGNet
-
相关资料:
- arxiv
- github
- 论文解读,解读2
-
论文基本信息
- 领域:图像分割
- 作者单位:中科院
- 发表时间:2018.11
-
一句话总结:实时语义分割
-
要解决什么问题:分别构建local/surrounding/global特征并融合,实现语义分割
-
用了什么方法
- CGNet 是 Context Guided Network 的缩写。
- 思路来源如人类视觉系统,即如果识别一个物体,不仅需要物体本身的信息,还需要周围环境(context)的信息。
- 为了实现上面的思路,实现了CG Block,主要就是构造 local/surrounding/global 特征,三者进行融合。
- 基于CG Block构造CGNet。
- 下面两张图,第一张是CG Block,第二张是CGNet。
- 注意,最终只下采样了1/4,没有decoder

- 效果如何:比同时期的BiSeNet快但精度低
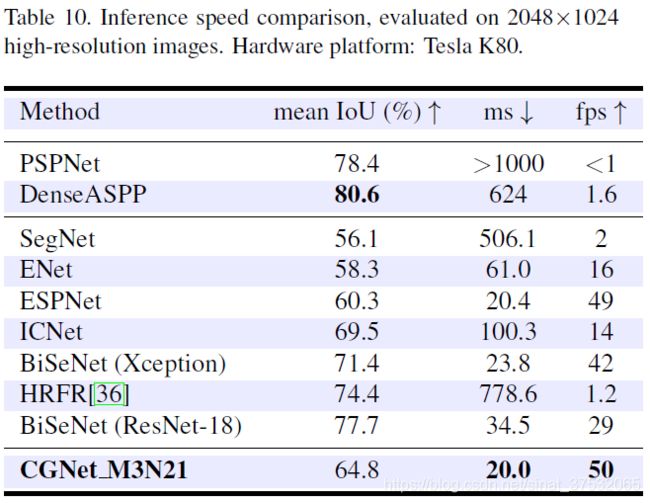
- 存在什么问题&有什么可以借鉴的:速度很快
3.5 DFANet
- 相关资料:
- arxiv
- github
- 论文解读(官方解读),解读2
- 论文基本信息
- 领域:图像分割
- 作者单位:旷视
- 发表时间:19.4,CVPR 2019
- 一句话总结:设计了多路多重融合(同一个stage不停downsample,前一个stage的输出upsample后作为后一个stage输入,前一个stage的中间输出作为后一个stage中间的输入)技术,使得移动端语义分割成为可能
- 要解决什么问题
- 解决轻量化语义分割的思路
- 对模型进行剪枝(模型抽象能力降低),或缩小输入图像尺寸(小目标检测效果差,边缘效果差)。
- 为了解决上面的问题,提出了多路结构(如BiSeNet),但存在分支之间独立性较强、限制了模型学习能力。
- 解决轻量化语义分割的思路
- 用了什么方法
- DFANet 是 Deep Feature Aggregation Network 的缩写
- 主要涉及思路就是解决上面说的存在的问题
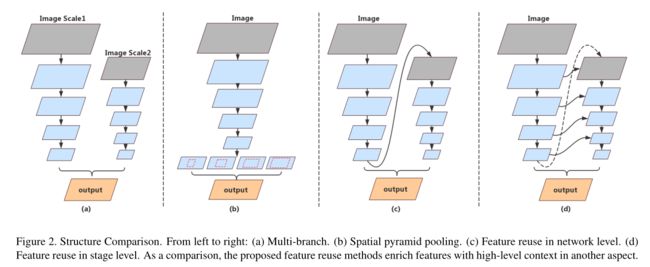
- 下面第一张图就介绍了分割的模型思路
- a 是多分支结构,即BiSeNet,分支间没有太大关系,导致性能不够;b是ASPP结构,应该是deeplab系列相关,消耗算力太多。
- c 和 d 就是本文的结构,特征图重复使用,达到类似ASPP的作用,核心就是Aggregation。
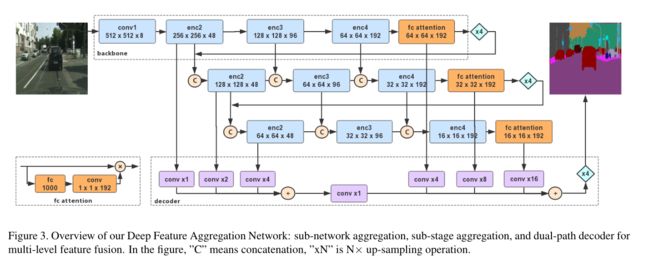
- 第二章图就是DFANet的结构
- 一个stage的输出进行upsample作为后一个stage的输入。
- 同一个stage中不停地downsample。
- 不同stage之间数据通过concat融合。
- 效果如何:真的快


- 存在什么问题&有什么可以借鉴的:可能这个网络就可以尝试跑在手机上了吧。
3.6 Fast-SCNN
- 相关资料:
- arxiv
- github
- 论文解读
- 论文基本信息
- 领域:图像分割
- 作者单位:东芝研究院&剑桥
- 发表时间:2019.2
- 一句话总结:在双路实时语义分割模型的基础上,复用浅层网络,并优化backbone组件,达到较好实时效果。
- 要解决什么问题:之前的多分支结构(如BiSeNet),多路之间没有相互关联,只是最终特征融合,这会浪费算力,并降低模型的抽象能力。
- 用了什么方法
- 多个分支的浅层结构通用卷积操作,从而节约算力。
- 提出了全局特征提取器来提取全局特征
- 第一张图介绍了设计思路
- 上面子图是unet结构
- 中间子图是双路结构(一路尺寸小但channels多、感受也打,一路尺寸大但channels少、感受野小)
- 下图是论文提出的结构,在双路结构的基础上,浅层网络共享卷基层,从而进一步降低计算量。
- 第二张图是FastSCNN的结构,组件大量利用了轻量化网络的结构,如depthwise conv和depth seperable conv等。


- 效果如何:但看起来比BiSeNet快多了
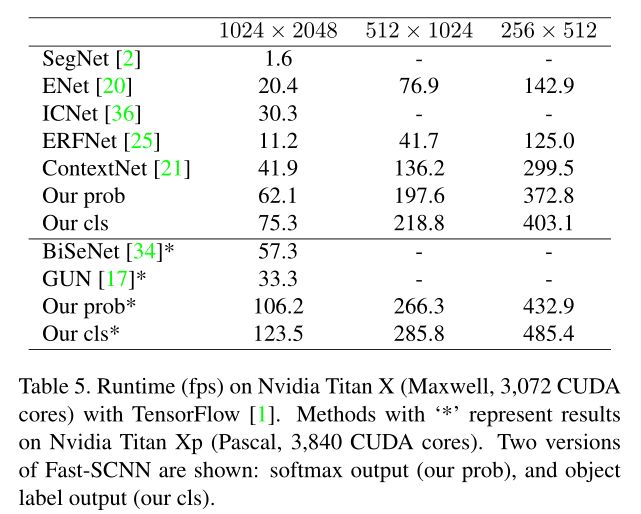
- 存在什么问题&有什么可以借鉴的:这个好像后续没看人用过
3.7 BiSeNetV2
- 相关资料:
- arxiv
- github
- 论文解读
- 论文基本信息
- 领域:图像分割
- 作者单位:华中科技
- 发表时间:2020.5
- 一句话总结:对原有BiSeNet进行改进(两路特征融合更为复杂,增强了训练策略)
- 要解决什么问题:
- 浅层信息(空间信息)和高层信息(语义信息)是语义分割的基础。
- 为了加快模型推理的速度,目前的方法几乎总是牺牲浅层信息,这导致了相当大的精度下降。
- 用了什么方法
- 将浅层信息(空间细节,细节分支)与高层信息(语义信息,语义分支)分开处理。(这个就是BiSeNet结构)
- 实现了 aggregation layer,实现了特征融合。
- 提出一种增强型训练策略,提高模型性能。
- 模型中其中每个模块都有很多细节,这里就不列了。总而言之,就是用了很多轻量化网络的技术,比如depthwise啥的。
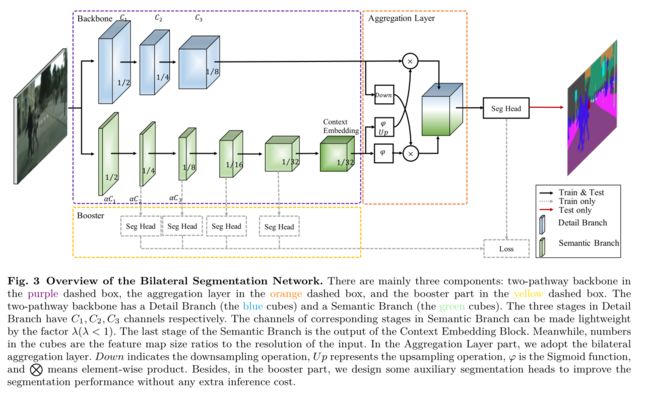
- 效果如何

- 存在什么问题&有什么可以借鉴的:这个应该恐怕可以尝试一下
3.8 HyperSeg
-
相关资料:
- arxiv
- github
- 论文解读
-
论文基本信息
- 领域:图像分割
- 作者单位:Facebook
- 发表时间:CVPR 2021
-
一句话总结:分割中引入元学习,设计了 dynamic patch convolution,在UNet的基础上进行改进,达到实时的效果(但速度不是特别快)。
-
要解决什么问题:主要是设计了一种新的用于decoder的组件,即meta block。
-
用了什么方法
- 整体就是使用了一个UNet结构,具体实现都用了各种轻量化组件,如depthwise或pointwise结构。
- 整体结构如下图
- 主要不同之处在于 Meta Block,这个结构中使用了 dynamic patch-wise convolution
- 其实我没细看具体内容,毕竟有源码,而且模型速度还是不够快,所以等真正需要的时候再研究了
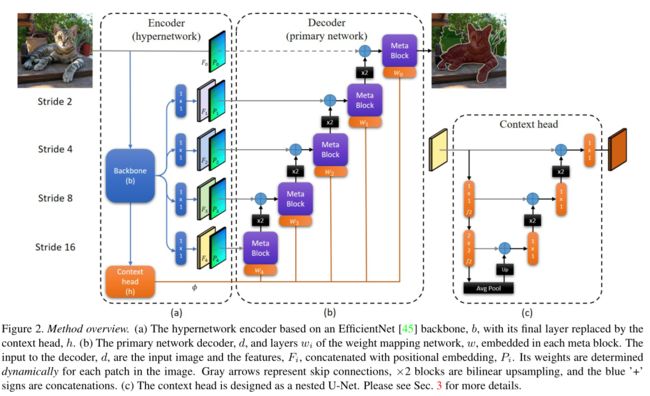

- 效果如何:

- 存在什么问题&有什么可以借鉴的:看起来速度不如BiSeNetV2,应该不能用在算力有限的情况
3.9 Rethinking BiSeNet For Real-time Semantic Segmentation
- 相关资料:
- arxiv
- github
- 论文解读
- 论文基本信息
- 领域:图像分割
- 作者单位:美团
- 发表时间:CVPR 2021
- 一句话总结
- 要解决什么问题
- BiSeNet结构中,空间信息的提取没有特殊设计,可能提取效率不高。
- 用了什么方法
- STDCNet 是 Short-Term Dense Concatenate network 的简称。
- 模型总体结构如下面第一张图
- 如果不考虑训练的话,只看a就行了。整体结构就是BiSeNet,改变的是 spatial 和 context 公用了卷基层和特征。
- 训练细节没细看,暂时不关心。
- 网络中每个stage的实现也与之前不一样,使用的就是Short-Term Dense Concatenate Module,如下面第二张图,感觉类似 DenseNet


- 效果如何:这看起来已经非常好了

- 存在什么问题&有什么可以借鉴的:第一个要尝试的模型应该就是这个了