python series转置储存到excel_P9:pythonpandas玩转excel文件
Python中pandas库的数据结构主要有两种:一个是Series ,一个是DataFrame。
DataFrame是一种数据结构,类似excel,是一种二维表;
series是一个一维数组,是基于NumPy的ndarray结构。Pandas会默然用0到n-1来作为series的index,但也可以自己指定index(可以把index理解为dict里面的key)。
一、先安装pandas、xlrd
pip3 install pandas
pip3 install xlrd
二、pandas-DataFrame()函数
1、新建excel文件:直接使用pandas的DataFrame函数创建
# -*- coding: utf-8 -*-import pandas as pd
df = pd.DataFrame({'id':[1,2,3],'name':['刘备','关羽','张飞']})
df.to_excel("D:/用python写代码/output.xlsx")
print("Done!")
结果:
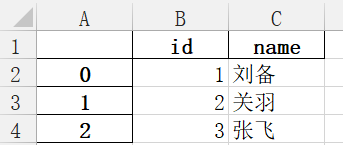
2、创建excel时将索引设置成id
# -*- coding: utf-8 -*-import pandas as pd
df = pd.DataFrame({'id':[1,2,3],'name':['刘备','关羽','张飞']})
df = df.set_index('id')
df.to_excel("D:/用python写代码/output1.xlsx")
print("Done!")
结果:
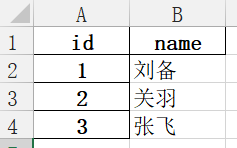
3、读取excel文件
# -*- coding: utf-8 -*-import pandas as pd
renyuan = pd.read_excel('D:/用python写代码/test1/Day1-7/ryb.xlsx')
print(renyuan.shape) #行数、列数
结果:(20, 7)
print(renyuan.columns) #列名
结果:Index(['id', 'name', 'sex', 'sfz', 'birth_date', 'zhicheng', 'zcsj'], dtype='object')
print(renyuan.head(2)) #前两行
结果:
id name sex sfz birth_date zhicheng zcsj
0 1 刘备 男 58829919701006**** 1970.10 高级工程师 2008.08
1 2 曹操 男 21079819880119**** 1988.01 工程师 2015.12
print(renyuan.tail(1)) #最后一行
结果:
id name sex sfz birth_date zhicheng zcsj
19 20 貂蝉 女 11826119901008**** 1990.1 工程师 2009.11
# -*- coding: utf-8 -*-import pandas as pd
renyuan = pd.read_excel('D:/用python写代码/test1/Day1-7/ryb.xlsx',header=1)print(renyuan.columns) #列名
结果:
Index(['001', '刘备', '男', '58829919701006****', '1970.10', '高级工程师', '2008.08'], dtype='object')
注:
1)在read_excel方法中,header默认值为0(索引),我们可根据需要修改参数。
2)header为默认值时,如果首行为空,print(xx.columns)可自动跳过空行至首行标题行。
3)renyuan = pd.read_excel("D:/用python写代码/test1/Day1-7/ryb.xlsx",skiprows=3,usecols="C:F“),其中,skiprows=3代表跳过前三行空行,usecols="C:F“代表仅使用C:F列,即跳过A-B列。
4、给无首行标题栏的表格添加标题栏
# -*- coding: utf-8 -*-import pandas as pd
renyuan = pd.read_excel('D:/用python写代码/test1/Day1-7/ryb.xlsx',header=None)
renyuan.columns = ['id','name','sex','sfz','birth_date','zhicheng','zcsj']print(renyuan.columns) #列名renyuan.to_excel("D:/用python写代码/test1/Day1-7/ryb.xlsx")print("Done!")
结果:
Index(['id', 'name', 'sex', 'sfz', 'birth_date', 'zhicheng', 'zcsj'], dtype='object')
Done!
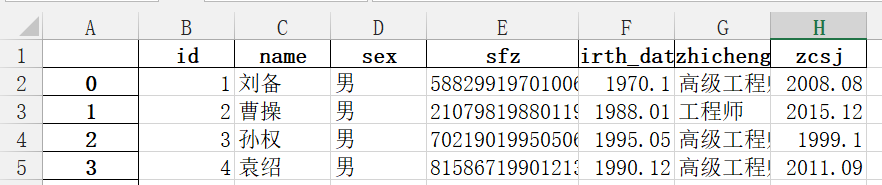
可将序号设置成id,从1开始,完善如下:
# -*- coding: utf-8 -*-import pandas as pd
renyuan = pd.read_excel('D:/用python写代码/test1/Day1-7/ryb.xlsx',header=None)
renyuan.columns = ['id','name','sex','sfz','birth_date','zhicheng','zcsj']
renyuan.set_index('id',inplace=True)print(renyuan.columns) #列名renyuan.to_excel("D:/用python写代码/test1/Day1-7/ryb.xlsx")print("Done!")
结果:
Index(['name', 'sex', 'sfz', 'birth_date', 'zhicheng', 'zcsj'], dtype='object')
Done!

注:
1)修改后,print(renyun.columns)看不到id了,只看到index。而读取时,又将id当作普通的列名,自动新增了索引号。
2)pandas 中 inplace 参数在很多函数中都会有,作用:是否在原对象基础上进行修改。inplace = True:不创建新的对象,直接对原始对象进行修改;inplace = False:对数据进行修改,创建并返回新的对象承载其修改结果。默认是False。
# -*- coding: utf-8 -*-import pandas as pd
renyuan = pd.read_excel('D:/用python写代码/test1/Day1-7/ryb.xlsx')print(renyuan.columns) #列名print(renyuan.head(2))
结果:
Index(['id', 'name', 'sex', 'sfz', 'birth_date', 'zhicheng', 'zcsj'], dtype='object')
id name sex sfz birth_date zhicheng zcsj
0 1 刘备 男 58829919701006**** 1970.10 高级工程师 2008.08
1 2 曹操 男 21079819880119**** 1988.01 工程师 2015.12
三、pandas-Series()函数
1、利用列表创建序列Series
# -*- coding: utf-8 -*-import pandas as pd
l1 = [100,200,300]
l2 = ['x','y','z']
s1 = pd.Series(l1,index=l2)
或者:s1 = pd.Series([100,200,300],index=['x','y','z'])print(s1)
结果:
x 100
y 200
z 300
dtype: int64
2、将序列Series转化成Dataframe
# -*- coding: utf-8 -*-import pandas as pd
s1 = pd.Series([1,2,3],index=[1,2,3],name='A')
s2 = pd.Series([10,20,30],index=[1,2,3],name='B')
s3 = pd.Series([100,200,300],index=[1,2,3],name='C')
df = pd.DataFrame({s1.name:s1,s2.name:s2,s3.name:s3})print(df)
结果:
A B C
1 1 10 100
2 2 20 200
3 3 30 300
# -*- coding: utf-8 -*-import pandas as pd
s1 = pd.Series([1,2,3],index=[1,2,3],name='A')
s2 = pd.Series([10,20,30],index=[1,2,3],name='B')
s3 = pd.Series([100,200,300],index=[1,2,3],name='C')
df = pd.DataFrame([s1,s2,s3])print(df)
结果:
1 2 3
A 1 2 3
B 10 20 30
C 100 200 300
四、示例
1)字符串拼接、转换
读取excel,并将str型字段“birth_date”(如:1988.08)转换成日期格式yyyy-mm-dd.
原表格式如下:
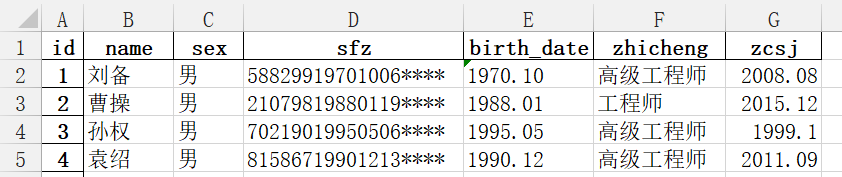
代码1:
import pandas as pd
df = pd.read_excel("D:/用python写代码/test1/Day1-7/ryb.xlsx",index_col='id',dtype={'birth_date':str,'sfz':str})
birth1 = df['birth_date'].str[:4]
birth2 = df['birth_date'].str[-2:]
sfz = df['sfz'].str[12:14]print(birth1+"-"+birth2+"-"+sfz)
五、补充:
1、time模块--计算当前日期
import time
p_time = time.strftime('%Y-%m-%d',time.localtime(time.time()))print(p_time)
结果:
2020-09-01
2、datetime模块 --strptime和strftime的区别 strptime: p表示parse,表示分析的意思,所以strptime是给定一个时间字符串和分析模式,返回一个时间对象。 strftime:f表示format,表示格式化,和strptime正好相反,要求给一个时间对象和输出格式,返回一个时间字符串 将str转换成datetime
import timeimport datetimep_time = time.strftime('%Y-%m-%d',time.localtime(time.time()))
pp_time = datetime.datetime.strptime(p_time,'%Y-%m-%d').date()print(pp_time)import pandas as pdimport timeimport datetime
df = pd.read_excel("D:/用python写代码/test1/Day1-7/ryb.xlsx",index_col='id',dtype={'birth_date':str,'sfz':str})
birth1 = df['birth_date'].str[:4]
birth2 = df['birth_date'].str[-2:]
sfz = df['sfz'].str[12:14]
bir = (birth1+"-"+birth2+"-"+sfz).str[0:11]
p_time = time.strftime('%Y-%m-%d',time.localtime(time.time())) #计算当前日期(元组)
p2_time = datetime.datetime.strptime(p_time,'%Y-%m-%d').date() #将p_time转换成日期格式for i in range(1,20):
p1_time = datetime.datetime.strptime(bir[i],'%Y-%m-%d').date()
p = (p2_time-p1_time).daysprint(round(p/365,1))