Python实验、Pandas数据处理与分析
Python实验、Pandas数据处理与分析
1、内容
1 、 程序题
现有如下表格数据,请对该数据进行以下操作:
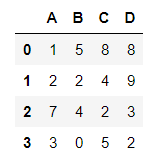
( 1 )创建一个结构如上图所示的 DataFrame 对象。
( 2 )将图中的 B 列数据按降序排序。
( 3 )将排序后的数据写入到 CSV 文件,取名为 write_data.csv 。
2 、 程序题
现有如下图所示的两组数据,其中 A 组中 B 列数据存在缺失值,并且该列
数据为 int 类型, B 组数据均为 str 类型。


( 1 )使用 DataFrame 创建这两组数据。
( 2 )使用 B 组的数据对 A 组中的缺失值进行填充,并保持数据类型一致。
( 3 )将合并后 A 组中索引名为 key 的索引重命名为 D 。
3 、北京租房数据统计分析
( 1 )读取链家北京租房数据;
删除数据中的重复值和缺失值;
将“户型”一列统一调整为“ x 室 x 厅”格式;
将“面积”一列调整为数值格式;
使用箱形图检查“面积”和“价格”列中是否存在异常数据;
使用“区域”和“小区名称”新增“位置”一列,形如“北京市 xx 区 xx ”;
( 2 )对“户型”、“面积”和“价格”以及每平米价格等信息进行简要的
统计分析,如每平米价格的最大值、最小值、平均值,“面积”的分箱区间统计,
“户型”的种类统计等
2、源代码清单
1、程序题
import pandas as pd
df_example=pd.DataFrame({'A':[1,2,7,3],
'B':[5,2,4,0],
'C':[8,4,2,5],
'D':[8,9,3,2]}) df_example=df_example.sort_values(by='B',ascending=False)
print(df_example)
df_example.to_csv(r'E:\实验数据\write_data.csv',index=False)2、程序题
import numpy as np
import pandas as pd
group_A=pd.DataFrame({'A':[2,3,5,2,3],
'B':[5,np.nan,2,3,6],
'C':[8,7,50,8,2],
'key':[3,4,5,2,5]},dtype=int)
group_B=pd.DataFrame({'A':[3,4,5],
'B':[3,4,5],
'C':[3,4,5]},dtype=str)
com=group_A.combine_first(group_B)
com.rename(columns={'key':'D'},inplace=True)
print(com)3、北京链家数据分析
( 1 )读取链家北京租房数据;
import pandas as pd
import numpy as np
import seaborn as sns
file = open(r'E:\实验数据\链家北京租房数据.csv')
data=pd.read_csv(file)
print(data)
#删除数据中的重复值和缺失值
data.drop_duplicates()
#将“户型”调整为“X室X厅”格式
data['户型']=data['户型'].str.replace('房间','室')
print(data['户型'])
#将“面积”一列调整为数值格式
data['面积(㎡)'] = data['面积(㎡)'].map(lambda x: str(x)[:-2])
data['面积(㎡)']=data['面积(㎡)'].apply(pd.to_numeric)
data['面积(㎡)']=data['面积(㎡)'].astype(dtype='int')
print(data['面积(㎡)'].dtypes)
#使用箱型图检查“面积”和“价格”列中是否存在异常数值
data.boxplot(column=['价格(元/月)','面积(㎡)'])
#使用“区域”和“小区名称”新增“位置”一列,形如“北京市 xx 区 xx”
data['位置'] = '北京市'+data['区域'].map(str)+'区'+data["小区名称"].map(str)
print(data) ( 2 )对“户型”、“面积”和“价格”以及每平米价格等信息进行简要的统计
分析,如每平米价格的最大值、最小值、平均值,“面积”的分箱区间统计,“户
型”的种类统计等。
price_static1=np.mean(data['价格(元/月)']/data['面积(㎡)'])
price_static2=np.max(data['价格(元/月)']/data['面积(㎡)'])
price_static3=np.min(data['价格(元/月)']/data['面积(㎡)'])
area_static=pd.cut(data['面积(㎡)'],bins=25).value_counts()
house_type_count=data.groupby('户型')
print('每平米价格平均值',price_static1)
print('每平米价格最大值',price_static2)
print('每平米价格最小值',price_static3)
print('面积的分箱区间统计结果:\n',area_static)
print('北京链家现有户型种类及数量为:',house_type_count['户型'].count())