聊聊服务灾备
2018年,有半年的时间在做服务灾备,由于当时对这一块的知识掌握得比较零碎,直接上手实践,没有较系统地学习,在后续的工作中,通过不断实践+学习补充这一块的知识,以及反思当时的实践,逐渐明白了要做灾备的原因和这么做的理由。在此写下自己的小小总结。
为什么要做灾备?
当时开始要做灾备的原因,是因为有一次机房A故障了,当时大部分的服务都不可以用:时长上涨、接口失败,原因是:
1、很多服务都部署到A机房了,导致大部分服务不可用
2、服务依赖的数据服务(MySQL、Redis)是单点
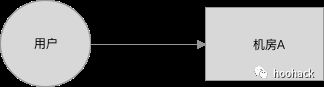
出现的问题表现是:时长上涨和接口失败,导致了页面不可用、服务受损。
这个问题的根本原因是出现服务单点的情况,没有备用的服务可以切换,导致请求/服务上游一直等待,等待一定时间后,就失败了。
知道问题的根本原因后,解决问题的核心方向就是解决单点问题,解决单点问题的方案有:服务冗余(多一份可用的服务),做灾备。
什么是灾备
灾备,简单点说,就是生产环境上部署的服务,假如有一个服务(集群)挂了,有另一个地方的同一个服务(集群)可以继续使用。
灾备分主备和双活两种部署。假设有两个机房A、B。
主备:大部分流量都会到主集群A上,当A挂了,备点B能承担主集群的角色;
双活:流量会平均分配到A、B两个机房,两个机房都能正常对外服务。v
如何做一个合理的灾备
怎么去做一个合理的灾备呢?
笔者结合自己的工作经历及理论知识,觉得做灾备主要是以下的几点,如果还有其他遗漏的,还望各位指正。
一、业务梳理
个人觉得,对于业务方来说,做一个应用的灾备最重要的一点就是业务梳理。理由如下:
1、达到需要做灾备的业务,通常都是存活了有一定时间的业务,这些业务都会由于各种因素而有一些在做灾备时觉得不合理的设计,简称历史原因。这些历史原因有:依赖的服务单点;依赖的数据存储系统单点;依赖的服务无法做灾备等等。这些原因,如果没有解决完,那么业务方也无法完成灾备。
2、不熟悉业务,对里面的逻辑不清楚,就不知道如果服务异常会导致什么问题发生,贸然去做灾备,等到真正有异常时,可能会发现没有达到预期的效果。
业务梳理,需要检查以下几个要点:
1、业务有多少个依赖服务?依赖服务是否还有其他的依赖?
2、依赖服务的灾备情况如何?双活还是单点?
3、依赖服务是否支持重试?重试失败怎么处理?
4、业务使用了什么数据存储系统?部署情况如何?纯DB还是有Redis?主从还是多主?是否支持自动切换主库?
5、业务用到的数据存储系统的灾备情况如何?是否满足灾备?是否支持分布式?
6、依赖的服务是否可降级?降级是否可以返回默认值?返回默认值对业务是否有损?
7、依赖服务多次重试依然失败,是否可以熔断?熔断对业务是否有损?
业务梳理完成之后,再根据对应不满足的点去完成,直到所有情况都考虑完成了或者使用折中的方案来解决。
二、负载均衡
负载均衡的意思是将流量负载分布到多台服务器,从而提高程序的性能和可靠性。通过负载均衡技术,可以分发集中的流量,可以解决两种情况:
1、流量暴涨,所有流量到一台机器,将应用拖垮
2、其中一个集群的所有应用挂了,可以将流量转发到另一个集群
注:在笔者实践负载均衡的经历中,使用到最多的就是nginx的负载均衡配置,将多个集群的机器添加到nginx配置的upstream中,nginx会根据配置文件中指定的策略来分发流量。
三、服务降级
服务降级:简单地说,就是如果服务异常,停掉不重要的服务,只返回部分数据。
比如说,一个用户信息接口,包含以下三个字段:
{
"id": 111,
"nickName": "hhq",
"userLogo": "https://www.test.com/test.jpg"
}如果头像暂时获取失败,如果返回默认头像用户可以接受,那么就降级返回默认的头像,这样既不会使得整个接口失败导致无法进行后续的操作,也不会影响用户体验。
四、服务熔断
熔断:这个概念参考电路的保险丝,如果电力负载过高,达到保险丝熔断,保险丝就会自身熔断切断电源,保护电路安全运行。而互联网中的服务熔断,是指依赖服务由于各种因素变得不可用或者响应过慢,业务方为了整个服务的稳定性,不再继续调用目标服务,直接返回,如果依赖服务恢复了,则恢复调用。
注意,熔断和降级看似很相似,但却是不一样的概念,应该理解为从属关系:
1、服务降级有多种降级方式,如限流降级、熔断降级
2、熔断是降级的其中一种方式
在熔断降级的实践中,笔者用到最多的是Hystrix。
五、服务发现
服务发现:自动检测一个计算机网络内的设备机器提供的服务。
服务发现有一个服务中间者维护服务与业务方之间的关系,服务将地址注册到服务中间者,业务方从服务中介中查找需要调用的服务的地址。
上面提到,最初开始做灾备是通过nginx的负载均衡来实现,这种方式在服务部署和扩容时需要修改配置文件,需要自己维护网络中的机器,一旦不小心配置错误,整个服务就崩了。如果使用服务发现,由服务发现的中介维护服务地址,配置时只需要知道服务发现的域名和服务名称即可,不需要关心具体的机器是哪一些。
实践过程中,用到的服务发现组件有:Zuul和spring-cloud。
六、演练
如果以上的步骤都完成了,那么就完成灾备了吗?并不是的。
现实情况下,很多时候是因为出现了单点故障,才会想到要去做灾备。或者其他服务出现了故障,自身的服务也要检查并完成灾备。那么怎么检查自己的服务已经完成灾备了呢?总不可能等待下次的故障到来才去验证。这种情况下,需要多做服务的灾备演练,根据已做的灾备要点,逐步演练,如果发现遗漏点,重新梳理,继续业务灾备,重新演练。不断循环,直到随时演练都能快速恢复并最小地影响业务或者业务完全无感知才算完成了灾备。
踩过的坑
以上的这些理论是多次反复实践得出的总结,以笔者自己做灾备的经历,给大家分享我遇到过的两个比较大的坑。
真的只是重试就完了吗?流量暴涨,拖垮服务
接口A,依赖服务B,B依赖服务C,部署情况如下:
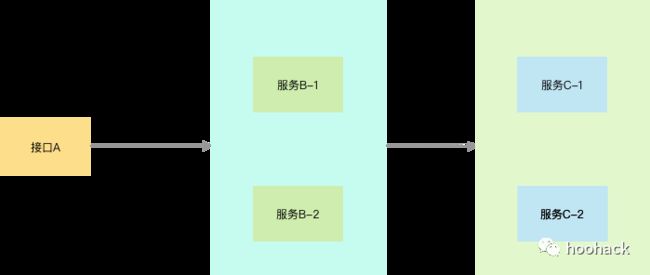
当时做了双活+网关重试+负载均衡的部署,出现的情况是B->C超时,导致A接口响应太慢,这里B->C有两次重试,A->B也有两次重试,接口超时时间太长,网关判断接口失败,于是也做了两次重试,最终的结果是,同一个接口,有2*2*2=8倍的流量,导致服务C的请求量暴涨,于是将服务C的进程池耗尽,服务499了,最终接口A一直都是失败,直到B->C之间的网络恢复才正常。
这次的故障得出的结论是:
1、重试不能单纯加上就完事了,需要看下游的依赖是否满足重试
2、重试多次失败后就需要加熔断降级
3、重要的接口,除了重试以外,还可以做部分数据降级提高接口高可用性
机房服务“孤岛”
有接口A,B、C两个服务,A-B之间通过外网相连,B-C之间通过内网相连。异常情况是B-C之间网络不通,外网流量通过接口A进入到B,B依赖C,但是B-C之间不通,B调用C会不断重试,直到全部重试都失败了,才会返回网络错误。这样一来,接口A并不知道B服务失败,用户侧体验是一直等待,然后显示失败。理想的做法是希望能在B-C网络不通的情况下将后续到来的流量拒绝掉,快速响应失败的结果。

要做到这一点,就需要让服务B“自杀”,如果应用侧发现B-C之间的网络出现异常,就让B返回失败错误码,不再进行重试。
需要注意的点
不能脱离业务
众所周知,开发大部分的时间都需要赶需求,一方面需求多到无法挤出时间完成灾备的任务,另一方面灾备工作如果不完成,出现故障之后就会影响业务了。因此通常会将这类需求当作技术需求来完成,业务开发人员没有时间完成灾备工作时,就会让一些负责技术需求的开发来直接完成灾备。上面提到,完成灾备最重要的一点就是需要梳理业务,如果由一个完成不懂该业务的开发去完成灾备,那么至少需要花1-2天去阅读代码,理清业务逻辑和列出可能出现的坑才能完成这份工作。但是笔者觉得这样做的效率是比较低的。首先,人无完人,虽然代码大家都能看懂,但是由一个未参与过业务的开发重新梳理,难免会有遗漏的地方(即使问相应的业务开发,也有可能会遗漏);其次,重新熟悉业务也需要投入一定的时间。
所以,做灾备是不能脱离业务的,应该给业务开发腾出相应的时间完成服务灾备,提高服务稳定性,这对业务而言,出现故障时不影响用户的使用,用户无感知,就是提高用户的体验。
自动化运维
在笔者的灾备经历中,如果机器出现故障/机房故障/流量暴涨,都需要运维和相应的业务开发人工介入判断是否需要扩容或摘除机器。但是人的判读是主观的,对是否需要扩容以及机器的选择可能会有判断出错的时候,灾备的工作,如果能结合现在较成熟k8s进行自动化运维,那么将达到事半功倍的效果。
总结
灾备,对于服务稳定性而言十分重要,但是也不是一朝一夕能完成的。个人觉得核心要点就是尽最大努力消除单点故障:服务单点、数据系统单点等等。
以上的文字理论仅仅是笔者经历过的小小总结,也许仍未做到最好的灾备级别,还需要日后不断实践来提升这部分的知识,如果有说错的地方,还望各位指正。
原创文章,文笔有限,才疏学浅,文中若有不正之处,万望告知。
如果本文对你有帮助,请点个赞吧,谢谢^_^
更多精彩内容,请关注个人公众号。
