AWS学习笔记-DB小结
正确选择数据库:
-
工作负载平衡?还是读量大?写量大?
-
吞吐量,是无序波动还是可预测?
-
要存储多少数据,需要多长时间?平均对象大小
-
数据持久性要求
-
延迟要求
-
数据模型
-
强模式或灵活模式,SQL或NoSQL
-
许可证费用
Database types which are supported by AWS:
Relational Database
RDS
Postgres
MySQL
MariaDB
Oracle
Microsoft SQL Server
Aurora (* AWS Proprietary database)
NoSQL
DynamoDB (~ JSON)
ElastiCache (key-value pairs)
Neptune (graphs) - no joins, no SQL
Object Store (“sort of”)
S3
Glacier
Data Warehouse
Redshift
Athena (query data in S3 using SQL, so “sort of”)
数据库服务
| 数据库类型 | 使用案例 | AWS 服务 |
|---|---|---|
| 关系 | 传统应用程序、ERP、CRM 、电子商务 | Amazon Aurora、 Amazon-RDS、 Amazon Redshift |
| 键值 | 高流量 Web 应用、电子商务系统、游戏应用程序 | Amazon DynamoDB |
| 内存中 | 缓存、会话管理、游戏排行榜、地理空间应用程序 | Amazon ElastiCache for Memcached 、Amazon ElastiCache for Redis |
| 文档 | 内容管理、目录、用户配置文件 | DocumentDB(兼容 MongoDB) |
| 宽列 | 用于设备维护、队列管理和路线优化的大规模工业应用程序 | Amazon Keyspaces (for Apache Cassandra) |
| 图形 | 欺诈检测、社交网络、建议引擎 | Amazon Neptune |
| 时间序列 | IoT 应用、开发运营和工业遥测 | Amazon Timestream |
| 分类账 | 系统记录、供应链、注册、银行事务 | Amazon QLDB |
RDS概述
• RDS是一种托管服务:
• 自动资源调配、操作系统修补
• 连续备份和还原到特定时间戳(时间点还原)
• 监控仪表板
• 只读副本以提高读取性能
• 用于灾难恢复的多AZ设置
• 升级的维护窗口
• 扩展能力(垂直和水平)
• 由EBS(gp2或io1)支持的存储
但是,不能SSH到RDS的实例中
RDS有两个重要特性
• 多AZ:这是用于“灾难恢复”
• 只读副本:这是为了“提高性能”
OLTP与OLAP
联机事务处理OLTP(on-line transaction processing)、联机分析处理OLAP(On-Line Analytical Processing)
-
OLTP 系统强调数据库内存效率,强调内存各种指标的命令率,强调绑定变量,强调并发操作;
-
OLAP 系统则强调数据分析,强调SQL执行市场,强调磁盘I/O,强调分区等。
-
OLAP用于AWS上的数据仓库(从数据库角度和基础设施层来看,这是一种不同类型的体系结构)
关系数据库
• RDS在虚拟机上运行,但无法通过ssh连接到虚拟机
• RDS不是无服务器的,但Aurora serverless是无服务器的
RDS—备份、多AZ和只读副本
Backup
RDS有两种备份类型
• 自动备份
• 数据库快照
Automated Backups自动备份
• 它允许用户将数据库恢复到“保留期”内的任何时间点,即大约7~35天。
• 自动备份默认启用,备份数据存储在S3中,同时您的RDS大小等于S3的大小
Tips–自动备份:
• 数据库的每日完整备份(在维护窗口期间)
• RDS每5分钟备份一次事务日志Transaction logs
• 这使您能够恢复到任何时间点(从最早的备份到5分钟前)
数据库快照
• 即使删除了原始RDS实例,也会有存储了的数据库快照
• 但它是由用户手动触发的,并可保留备份,保留时间随您的需要而定
多AZ
• 它只有一个DNS名称,自动将应用程序故障时待机状态的实例进行切换,无需手动干预应用程序
• 在另一个AZ中生成数据库的精确副本
• 在生产数据库写入时自动同步
• 副本生效在下列情况下:
○ 有计划的数据库维护
○ 数据库实例失败
○ AZ故障
○ 网络故障
这仅用于灾难恢复DR、提高可用性
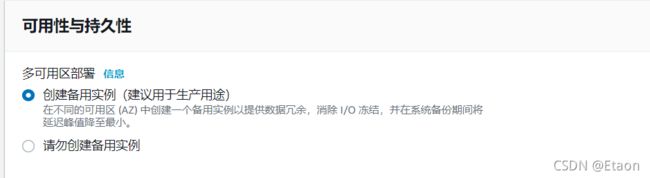
以上是在配置RDS的时候选择多AZ的部分,用于提供冗余,增加可用性和持久性。
只读副本Read Replicas
允许用户拥有生产数据库的只读副本。
这是通过使用从主RDS实例到只读副本的异步复制来实现的。对于那些读取工作量大的数据库来说,它显然更好。
只读副本用于SELECT唯一类型的任务,而不是插入Insert、删除delete或更新update
Tips:请注意只读副本和以前的数据库备份方法之间的差异
• 只读副本用于扩展,以提高性能
• 要使用只读副本,应打开“自动备份Automated Backups”设置
• 任何数据库最多可以有5个只读副本
• 您甚至可以拥有只读副本的只读副本
• 每个只读副本都有其端点endpoint
• 可以提示读取副本作为其数据库,但复制无法工作
- 单AZ只读副本-网络成本
在AWS中,当数据从一个AZ传输到另一个AZ时,存在网络成本,因此为了降低成本,您可以在同一AZ中拥有只读副本
RDS安全
加密
这是通过使用AWS KMS(密钥管理服务)实现的,一旦启用加密,以下内容将被加密:
• 数据底层存储
• 自动备份
• 只读副本
• 数据库快照
无论何时恢复自动备份或数据库快照,数据库的恢复版本都将是具有新DNS端点的新RDS实例,另做一个!
静止加密和传输中加密
静态加密
我们可以使用AWS KMS-AES-256加密来加密主数据库和只读副本,这必须在启动时定义。
如果主数据库未加密,则无法加密只读副本
Tips:或者,
未加密的数据库->快照->将快照复制为加密的->从加密的快照创建新的数据库
另:Transparent Data Encryption (TDE) 支持Oracle和SQL Server
传输中加密
这允许使用SSL证书将到传输中的RDS数据进行加密,在连接到数据库时,必须提供带有信任证书trust certificate的SSL选项
网络与IAM
网络安全
• RDS数据库通常部署在私有子网中,而不是在公用子网中
• RDS安全通过利用安全组工作,它控制哪个IP/安全组可以与RDS通信
访问管理
• IAM策略有助于控制谁可以通过RDS API管理AWS RDS,如“谁可以创建读取副本?”?等等……”
• 传统用户名/密码可用于登录数据库
• 基于IAM的身份验证可用于登录RDS MySQL和PostgreSQL
IAM身份验证
• 支持MySQL和PostgreSQL
• 无需密码,只需通过IAM和RDS API调用获得令牌即可
• 令牌的生存期为15分钟
IAM身份验证具有以下好处:
• 必须使用SSL对网络输入/输出进行加密
• IAM将集中管理用户而不是数据库
• 可以利用IAM角色和EC2实例配置文件轻松集成
Aurora
-
Aurora is the MySQL and PostgreSQL compatible, AWS solution to Relational Database
Aurora HA and Scalability -
速度最高可以达到标准 MySQL 数据库的五倍、标准 PostgreSQL 数据库的三倍
-
可以把每个数据库实例扩展到最高 128TB。
-
最多 15 个低延迟读取副本、时间点恢复、持续备份到 Amazon S3,还支持跨三个可用区 (AZ) 复制。
-
Support Cross Region Replication
Aurora always maintains 2 copies of your data in each AZ, with a minimum of 3 AZ => which leads to 6 copies of data
Among these 6 copies of your data across 3 AZ:
• 4 copies out of 6 needed for writes
• 3 copies out of 6 needed for reads
• self-healing with peer-to-peer replication
• storage is striped across 100s of volumes
There is a primary-secondary architecture, one Aurora instance will take writes (primary)
If there is a failover happened, the automated failover for primary DB will take effect in less than 30 seconds
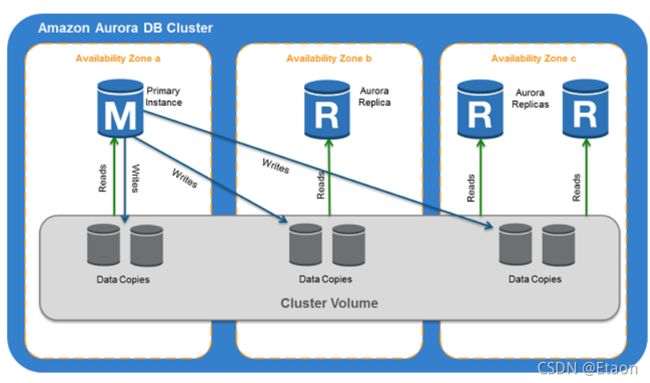
Aurora Replicas
Aurora Replicas 有两种类型:
• Aurora Replicas
• MySQL Read Replicas
- Automated failover is only available with Aurora Replicas
Backups for Aurora
also 2 types:
• Automated Backups
• Data Snapshots
Migrate
To migrate data from MySQL to Aurora, you can do the following things
1. take a data snapshot and restore in Aurora
2. create an Aurora Read replica and then promote the Read Replica as a "database service"
也可以使用DMS:AWS Database Migration Service
由于源数据库和目标数据库的架构结构、数据类型和数据库代码都是兼容的,此类迁移只需一个步骤即可完成。
1. 可以创建与源数据库和目标数据库相连的迁移任务,然后单击一个按钮开始迁移
2. AWS Database Migration Service 将负责完成其余的工作。
Aurora DB Cluster

load balancing happens during connection
Aurora Serverless
• 基于实际使用情况的自动数据库实例化和自动缩放
• 适用于不频繁、间歇或不可预测的工作负载
• 无需容量规划
• 按每秒支付,可以更具成本效益
Aurora Serverless将创建Aurora实例,客户端将使用proxy fleet连接到Aurora,并启用自动缩放功能,这意味着:如果QPS较大,则将创建更多Aurora实例,否则将删除
Global Aurora
Ø Aurora跨区域读取副本
○ 对灾难恢复有用
○ 易于安装
Ø Aurora Global数据库(推荐)
-
1个主区域(读/写)
-
最多5个辅助secondary (只读)区域,复制延迟小于1秒
-
每个辅助secondary 区域最多16个只读副本,有助于减少延迟
-
DR时启用另一个区域(用于灾难恢复)的RTO(恢复时间目标)小于1分钟
ElasticCache
这是基于内存缓存的web服务的AWS解决方案
ElasticCache概述
-
与RDS获取托管关系数据库的方法是一样的
-
ElastiCache用于管理Redis或Memcached
-
有助于减少读取密集型工作负载的数据库负载
-
使无状态应用程序
-
使用分片写入缩放
-
使用只读副本进行读取扩展
-
具有故障切换功能的多个AZ部署
-
AWS负责操作系统维护/修补、优化、设置、配置、监控、故障恢复和备份
应用场景
DB Cache

应用程序首先查询ElastiCache,如果数据不可用(缓存未命中),则从RDS等数据库获取数据并存储在ElastiCache中,以便在以后的查询中达到缓存命中
User Session Store

Ø User login to any of the application
Ø The application writes the session data into ElastiCache
Ø The user hits another instance of our application
Ø The instance retrieves the data and the user is already logged in
机器学习与实时分析
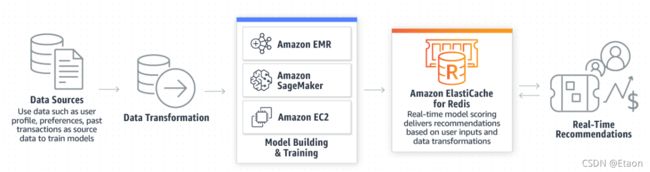
利用ElastiCache提供的快速内存中数据存储,以帮助快速构建和部署机器学习模型,并可用于实时分析。
ElastiCache - Redis or Memcached
| Redis | Memcached |
|---|---|
| Multi-AZ with Auto-Failover | Multi-node for the partitioning of data (sharding) |
| Read Replicas to scale reads and have high availability | Nonpersistent |
| Data Durability using AOF persistence | No backup and restore |
| Backup and restore feature | Multi-threaded architecture |
- If you need scale horizontally, you need to choose Memcached
- If you need Multi-AZ, Backups, and Restores, you need to choose Redis
Tips:
Right now, we have two methods of improving performance
ElasticCache -> Cache layer to speed up
Read Replicas -> Improved read/write on the database layer
ElastiCache - Cache Security
All caches in ElastiCache:
• support SSL in-flight encryption
• Do not support IAM authentication
• IAM policies on ElastiCache are only used for AWS API-level security
Redis AUTH
建Redis Cluster 的时候配置“password/token”
This is an extra level of security for your cache (on top of **Security Group**)
Memcached AUTH
Supports SASL-based authentication
ElastiCache for Solutions Architects
- 延迟加载Lazy Loading:所有读取的数据都被缓存,缓存中的数据可能会过时
- 直写Write Through:写入数据库时,在缓存中添加或更新数据(无过时数据)
- 会话存储Session Store:在缓存中存储临时会话数据(使用TTL功能)
DynamoDB
DynamoDB现在可以做事务transactions了
DynamoDB是针对无服务器Severless NoSQL数据库的AWS解决方案,它支持文档和键值对数据模型
- 数据存储在SSD存储器中
- 高可用性,可跨3个AZ(地理位置不同的数据中心)进行复制
- 可以恢复到先前的 35 天内的任何时间点,而无需停机
- 最终一致读取(默认)
- 强一致读取
**最终一致读取**
- 所有数据拷贝的一致性通常在一秒钟内达到。短时间后重复读取应返回更新的数据。
- 这是为了“最佳读取性能”,默认情况下启用此设置
**强一致读取**
强一致性读取返回的结果反映了在读取之前收到成功响应的所有写入
DynamoDB-基础
• DynamoDB是由tables组成的
• 每个表都有一个主键primary key(必须在创建时确定)
• 每个表可以有无限多的项(=行rows)
• 每个项目都有属性attributes(可以随时间添加-可以为空)
• item的最大大小为400 KB
DynamoDB-提供的Throughput
Ø 表必须已预先设置读写容量单位
Ø 读取容量单位(RCU):读取的吞吐量
○ 1个RCU:1个每秒4 KB的强一致性读取
○ 1个RCU:2个每秒4 KB的最终一致读取
Ø 写入容量单位(WCU):写入的吞吐量
○ 1个WCU:每秒写入1 KB
Ø 设置吞吐量自动缩放以满足需求的选项
Ø 可以使用“突发信用burst credit”暂时超过吞吐量
Ø 如果burst credit为空,将获得“ProvisionedThroughputException”
Ø 然后建议执行指数退避重试
DynamoDB-DAX
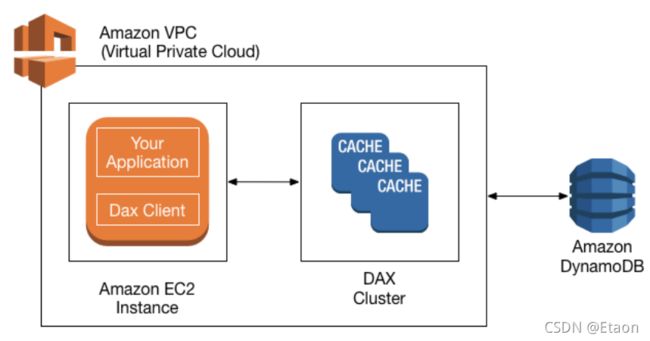
DAX是DynamoDB加速器,它为DynamoDB提供无缝seamless缓存,无需应用程序重写。写入操作通过DAX,然后到达DynamoDB。
支持多个AZ,建议至少生产3个节点
DynamoDB流

Ø DynamoDB中的变化将以DynamoDB流结束
Ø AWS Lambda可以读取该流,因此我们可以进行分析工作
Ø 可以使用流实现跨区域复制
Ø 它有24小时的数据保留时间
DynamoDB-安全
Ø VPC端点无需互联网即可访问DynamoDB
Ø 访问完全由IAM控制
Ø 加密:KMS和SSL/TLS
DynamoDB-其他功能
全球表格Global Tables:
Ø 多regions的Active-Active复制
Ø 必须启用DynamoDB流
Ø 它具有低延迟,用于灾难恢复
能力规划:
Ø 计划容量:配置WCU和RCU可启用自动缩放
Ø 按需容量:获得无限的WCU和RCU,无上限,更昂贵
工作负载—按需容量,个别情况
可自动扩展的可预测工作负载-计划容量
其他功能,如备份和恢复、迁移,甚至可以设置本地DynamoDB进行开发
RedShift
这是AWS自己的数据仓库服务解决方案,它支持大规模并行处理Massively Parallel Processing(MPP)
Redshift备份
Ø 这是默认启用的,保留期为1天,最长为35天
Ø 始终尝试维护至少3个数据副本,即计算节点上的原始或副本,备份在AWS S3上
但它只在一个AZ中提供
Neptune
用户完全管理的图形数据库
Ø 高关系数据
Ø 社交网络
Ø 知识图
跨3个AZ高度可用,最多15个读取副本,具有时间点恢复功能,可连续备份到Amazon S3。
支持REST+HTTPS时的KMS加密。