【学习笔记】李宏毅2021春机器学习课程第二节:机器学习任务攻略
文章目录
-
-
-
- 如何做的更好?
- Model bias
- Optimization Issue
- Start from shallower networks
- Overfitting
- Cross Validation
- Mismatch
-
-
如何做的更好?

如果在Kaggle上的结果不满意的话,第一件事情就是检查你的training data的loss。如果你发现你的模型在training data的loss很大,说明它在训练集上面也没有训练好,这边有两个可能的原因,第一个是model的bias。
Model bias
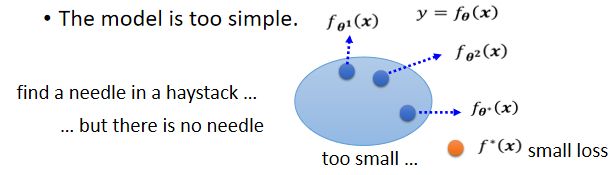
问题原因:你的model太过简单,function的set太小了,这个function的set中没有包含任何一个function,可以让我们的loss变低,即可以让loss变低的function,不在你的model可以描述的范围内。
用个比喻来说:这就好像是我们想大海捞针,但针根本就不在海里,所以任何努力都是徒劳。

解决方法:重新设计一个model,给你的model更大的弹性,举例来说,你可以增加你输入的features,也可以使用Deep Learning,增加网络的层数和复杂度。
但是并不是training的时候,loss大就代表一定是model bias,你可能会遇到另外一个问题,还有可能是optimization做得不好。
Optimization Issue
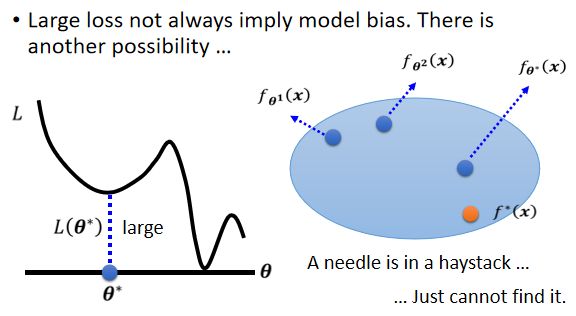
问题原因:你可能会卡在local minima的地方,没有办法找到一个真的可以让loss很低的参数就停下了。
用个比喻来说:这就好像是我们想大海捞针,针确实在海里,但是我们却没有办法把针捞起来。
那么training data的loss不够低的时候,到底是model bias,还是optimization的问题呢?
一个建议判断的方法,就是你可以通过比较不同的模型,来得知你的model现在到底够不够大:

举一个例子,这一个实验是从residual network那篇paper里面摘录出来的 (http://arxiv.org/abs/1512.03385)。
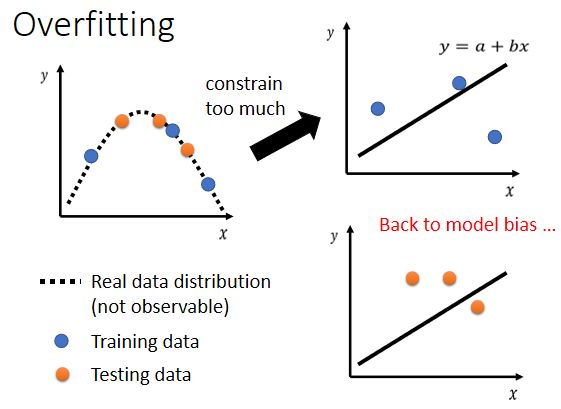
这里想测2个networks,一个20层,一个56层,训练之后发现20层的loss比较低,56层的loss反而比较高,但这个不是overfitting,并不是所有的结果不好,都叫做overfitting。
你要检查一下训练集上面的结果,发现在训练集上,56层的network loss就比20层的network loss高了,这代表56层的network,它的optimization没有做好。之所以能下这个结论,是因为理论上56层的network一定可以做到20层的network能做到的事情(它只要前20层的参数,跟这个20层的network一样,剩下36层什么事都不做)。
Start from shallower networks
一个小建议:看到一个你从来没有做过的问,也许你可以先跑一些比较小的,比较浅的network,甚至用一些不是deep learning的方法,比如说 linear model,比如说support vector machine,它们可能是比较容易做Optimize的,比较不会有optimization失败的问题。先有个概念说,这些简单的model,到底可以得到什么样的loss,这样也就有了一个参考的基准点。
If deeper networks do not obtain smaller loss on training data, then there is optimization issue.
解决方法:更换Optimization的策略,在SGD上加momentum,改用其他策略等等,下节课会具体讲到。
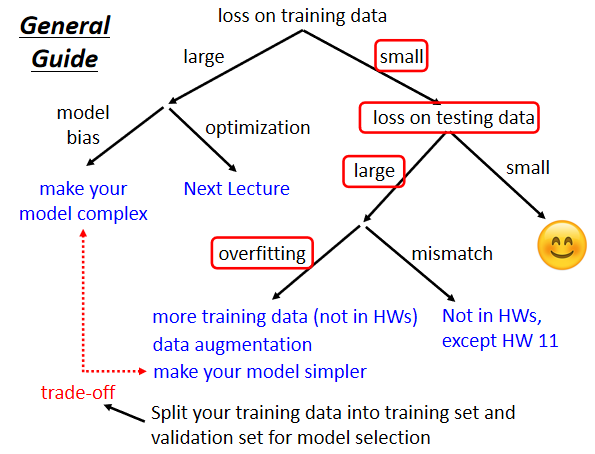
假设你现在经过一番努力,已经可以让你的training data的loss很小了,那接下来就可以看看testing data loss的情况,如果是training的loss小,testing的loss大,这个有可能是真的遇到overfitting问题了。
Overfitting

**问题描述:**举一个比较极端的例子,假如我们有一个一无是处的function:如果今天x当做输入的时候,我们就去比对这个x有没有出现在训练集里面,如果x出现在训练集里面,就把它对应的ŷ当做输出,如果x没有出现在训练集里面,就输出一个随机的值。
那你可以想像这个function啥事也没有干,但是在training的data上,它的loss可是0呢!可是在testing data上面,它的loss会变得很大,因为它其实什么都没有预测。
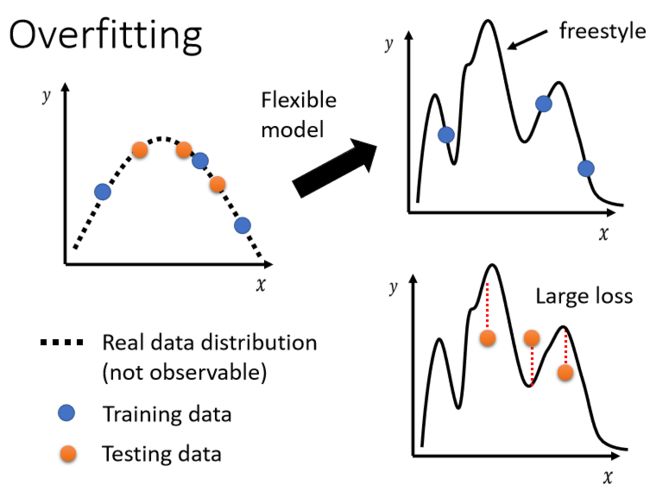
如果你的model它的自由度很大的话,它可以产生非常奇怪的曲线,导致训练集上的结果好,但是测试集上的loss很大。
解决方法:
-
第一个方向是,往往也是最有效的方向,那就是增加你的训练集。但是人工搜集训练集往往成本很高,可以使用data augmentation技术,注意很少看到有人把影像上下颠倒当作augmentation,也就是说你使用这个技术必须要是reasonable的,并不是随意的。

-
第二个方向是,对你的模型进行一定的限制,让其不要有那么大的弹性。那你可能会问我怎么会知道要用多constrain的model才会好呢,这就取决与你对这个问题的理解,对于数据产生背后原理的理解。
那么又有哪些方法可以给model制造限制呢?

- 给它比较少的参数,如果是deep learning的话,就给它比较少的神经元的数目。或者是你可以让model共用参数,你可以让一些参数有一样的数值。我们之前讲的network的架构,叫做fully-connected network,那fully-connected network其实是一个比较有弹性的架构,而CNN是一个比较有限制的架构,它是针对影像的特性,来限制模型的弹性,就是因为CNN给了比较大的限制,所以CNN在影像上反而会做得比较好。
- 用比较少的features,本来给三天的资料,改成用给两天的资料,其实结果就好了一些。
- 采用Early stopping,(17条消息) 深度学习技巧之Early Stopping(早停法)_df19900725的博客-CSDN博客_early stopping,基本含义是在训练中计算模型在验证集上的表现,当模型在验证集上的表现开始下降的时候,停止训练,这样就能避免继续训练导致过拟合的问题。
- Regularization,机器学习之正则化(Regularization) - Acjx - 博客园 (cnblogs.com),在代价函数中加入惩罚项,对于太过复杂的模型进行惩罚。
- Dropout,(17条消息) 深度学习中Dropout原理解析_Microstrong-CSDN博客_dropout,Dropout说的简单一点就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征。
但是我们也不要给模型太多的限制,不然我们又会回到model bias的问题。
所以要选择既不简单也不复杂的模型:

Cross Validation
把Training的资料分成两半,一部分叫作Training Set,另一部分用作Validation Set,在Training Set上训练出来的模型,在Validation Set上面去衡量它们的分数,最后根据Validation Set上面的分数,去挑选结果,这样就可以很大程度上避免在public上面结果很好,但是在private上面结果很差的情况。

但是这边会有一个问题,就是怎么分Training Set和Validation Set呢,一般就是随机分的,但是如果担心分到很奇怪的Validation Set导致结果很差,那么推荐使用N-fold Cross Validation的方法。
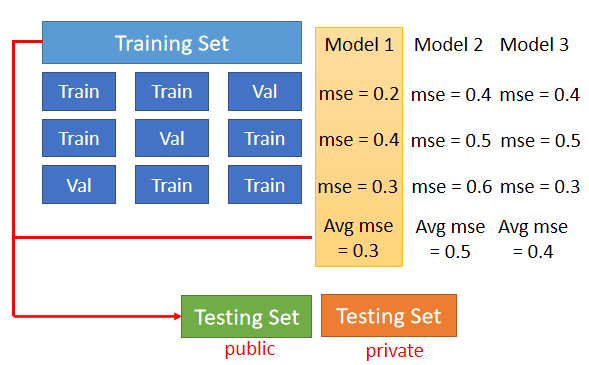
N-fold Cross Validation:[深度概念]·K-Fold 交叉验证 (Cross-Validation)的理解与应用 - 小宋是呢 - 博客园 (cnblogs.com) 就是你先把你的训练集切成N等份,在这个例子里面我们切成三等份,切完以后,你拿其中一份当作Validation Set,另外两份当Training Set,然后这件事情你要重复三次。
然后接下来你有三个模型,你不知道哪一个是好的,你就把这三个模型在这三个setting下,在这三个Training跟Validation的data set上面,通通跑过一次,然后把这三个模型,在这三种状况的结果都平均起来,再看看谁的结果最好。
Mismatch

mismatch的原因跟overfitting其实不一样,一般的overfitting,你可以用搜集更多的资料来克服,但是mismatch意思是说,你今天的训练集跟测试集,它们的分布是不一样的。就比如HW11中的情况:
