深度学习之医学影像分割与分类_Matlab完整开发流程
文章目录
- 前言
- 一、基本介绍
- 二、DeepLabV3+分割网络
-
- 1.语义分割网络数据集制备
- 2.加载数据集图像和标签
- 3.DeepLabV3+网络搭建
-
- 3.1用类加权平衡类
- 3.2创建网络
- 3.3数据增强
- 3.4设置超参数
- 3.5开始训练并保存
- 3.6网络评价
- 3.7测试训练结果
- 三、分类网络的构建
-
- 1.图像预处理
- 2.网络搭建
- 3.测试训练结果
- 四、APP设计
- 五、总结
前言
Python基本占据了深度学习领域,但是如果是新手玩家由于某个项目需要或者是想快速入门又不会Python,对训练过程及各种超参数不了解,就不妨先试试万能的Matlab,如果对Matlab语法熟悉,使用可视化工具、修改和分析学习架构,学习完Matlab的深度学习编程框架后能很快出成果,后续再深入学习,应该是一个比较好的学习过程。
注:
推荐Python关于分割网络开源代码汇总,转自github,感谢作者mrgloom的整理:
链接:awesome-semantic-segmentation
Matlab学习资源直接去Mathwork:
链接:Mathworks
一、基本介绍
本项目要实现对乳腺结节超声影像进行分割与分类,实现辅助医生诊断功能。本文将详细介绍Matlab的深度学习编程框架及相关可视化工具,是Matlab&深度学习的基础范例。
注:代码推荐使用实时脚本文件(.mlx)
本文讲述了:
1.训练集的制备
2.DeepLabV3+分割网络的构建、训练、评价
3.深度学习工具箱的使用与分类网络的构建
4.使用App Designer设计App
注:本文所有代码基于MatlabR2021a与Python3
二、DeepLabV3+分割网络
1.语义分割网络数据集制备
卷积神经网络输入图像,标签(输出结果)是根据任务而定的。对于分类任务,标签就是对应类别(如行人图像对应标签就是"行人"),对于目标检测,输出是4维向量(左上角x坐标,左上角y坐标,x方向长度,y方向长度)。而语义分割(semantic segmentation)是对图像中每一个像素进行分类,从而生成按类分割的图像,就是给每一个像素都打上标签(像素标签pixel label)再分类(如行人标“1”,背景标“0”),本质还是分类任务,如果自己标注可以用Matlab自带的标注工具,可以直接生成gTruth格式和PixelLabelData标签,具体过程参考官网对imagelabel的详细介绍imagelabel,工作量巨大,我拿到的数据集有乳腺超声影像包括良性结节,恶性结节和无结节三类以及标注好的掩模图像,需要对掩模图像进行预处理生成最终的Ground Truth,下图是原始图像和掩模图像。


本项目只需要分割结节和其他,只需要标"0"和"1",参考如下代码:
for n=1:623 %数据集样本数
I=imread(['SegImage_mask(',num2str(n),').png']);%循环读取
Img={I};
A=Img(1);
RGB=A{1,1};
B=RGB(:,:,1);
S=size(B);
for i=1:S(1)
for j=1:S(2)
if RGB(i,j,1)==0&&RGB(i,j,2)==0&&RGB(i,j,3)==0 %三通道均为0的是其他
B(i,j)=0;
else
B(i,j)=1; %否则是结节
end
end
end
imwrite(B,[num2str(n),'.png'])
end
图像中只有两个值0和1,这里的0,1只是像素标签,分别代表其他和结节,看起来像是全黑的。

再按7:3比例将数据集和标签图像分为训练集和测试集,一定要要将训练图像和标签一一对应,整理好的文件应包括:

2.加载数据集图像和标签
加载数据集:
clc,clear;
dataFolder = fullfile('G:\+1\Graduation_Project\ALL_file\Code\DeeplabV3+_Seg');%数据所在路径
imageFolderTrain = fullfile(dataFolder,'train_image');%训练图像路径
labelFolderTrain = fullfile(dataFolder,'train_label');%训练标签路径
imageFolderVal = fullfile(dataFolder,'val_image');%验证图像路径
labelFolderVal = fullfile(dataFolder,'val_label');%验证标签路径
imdsTrain = imageDatastore(imageFolderTrain);% 加载训练图像
imdsVal = imageDatastore(imageFolderVal);% 加载验证图像
使用类和标签 ID 创建pixelLabelDatastore,pixelLabelDatastore里的元素就相当于使用标注工具生成的gTruth格式,至此已完成数据集准备工作,下一步就可以搭建网络预训练模型了。
classNames = ["Back" "Tubercle"];%设置类别名称
labelIDs = [0 1];%设置类别相应的编号
pxdsTrain = pixelLabelDatastore(labelFolderTrain,classNames,labelIDs);%生成相应的类别标签
pxdsVal = pixelLabelDatastore(labelFolderVal,classNames,labelIDs);%生成相应的类别标签
3.DeepLabV3+网络搭建
DeepLabV3+是一种专为语义图像分割而设计的卷积神经网络 (CNN)。其他类型的语义分割网络包括全卷积网络(FCN)、SegNet、U-Net等,训练过程是一样的。
3.1用类加权平衡类
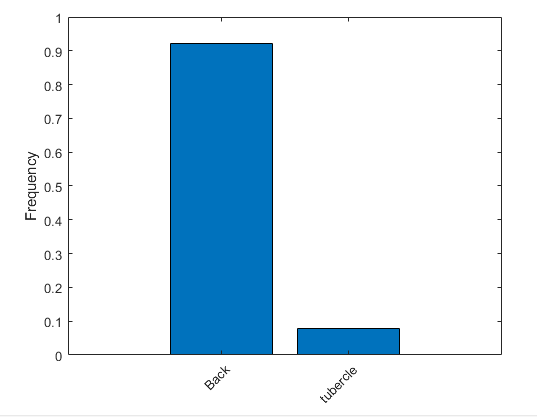
理想情况下,所有类都具有相等数量的观测值。但是超声影像中的类不平衡,有的结节占比很小,而学习偏向于主导部分,所以要计算类权重(即像素总个数和结节像素总个数之比)。
tbl = countEachLabel(pxdsTrain);%countEachLabel计算像素标签计数
frequency = tbl.PixelCount/sum(tbl.PixelCount);
bar(1:numel(classNames),frequency)
xticks(1:numel(classNames))
xticklabels(tbl.Name)
xtickangle(45)
ylabel('Frequency') %Frequency向量元素包含结节和其他的像素占比
% 设置类别权重
imageFreq = tbl.PixelCount ./ tbl.ImagePixelCount;
classWeights = median(imageFreq) ./ imageFreq;
% 修改输出层,使用像素分类图层(pixelClassificationLayer)指定类权重
pxLayer = pixelClassificationLayer('Name','labels','Classes',tbl.Name,'ClassWeights',classWeights);
lgraph = replaceLayer(lgraph,"classification",pxLayer);
其中计算出来权重是这样的,不加入权重会大大降低网络性能.
3.2创建网络
Deeplabv3+网络创建基于MobileNet v2 ,实际上是一个迁移学习的过程,最佳网络需要实证分析,这是超参数调优的另一个级别。除了MobileNet v2,还可以 ResNet-18 等,也可以尝试其他语义分割网络体系结构,如 SegNet、FCN 或 U-Net。
numClasses = numel(classNames);
lgraph = deeplabv3plusLayers(imageSize,numClasses,'mobilenetv2');
3.3数据增强
数据增强用于通过在训练期间随机转换原始数据来提高网络准确性。通过使用数据增强,可以向训练数据添加更多种类,而无需增加标记训练样本的数量,可以对数据集进行平移,翻转等变换实现数据增强,这里使用了沿X轴和Y轴翻转,此外还要将相同的随机变换应用于图像和像素标签数据。
augmenter = imageDataAugmenter('RandXTranslation',[-10 10],'RandYTranslation',[-10 10]);%翻转
pximds = pixelLabelImageDatastore(imdsTrain,pxdsTrain, ...'DataAugmentation',augmenter);
3.4设置超参数
使用 trainingOptions指定超参数,下面有对应简单注释,其中BatchSize与数据量大小和电脑性能有关,一般选取2的倍数,如果过大可能导致电脑内存不足,过小导致不收敛。学习率每 20个 epoch 降低 0.4倍,这使得网络能够以更高的初始学习速率快速学习,同时能够在学习速率下降时找到接近局部最优的解决方案。
%% 设置训练参数
options = trainingOptions('adam', ...%选取adam优化器
'LearnRateSchedule','piecewise',...
'LearnRateDropPeriod',20,...%学习率每20代降低一次
'LearnRateDropFactor',0.4,...%学习率每20代降低0.4倍
'InitialLearnRate',1e-4, ...%初始学习率
'L2Regularization',0.005, ...
'MaxEpochs',50, ... %最大迭代次数
'MiniBatchSize',8, ...%小批量尺寸,可根据显存更改
'Shuffle','every-epoch', ...
'VerboseFrequency',2,...
'Plots','training-progress');%绘制训练曲线
3.5开始训练并保存
使用 trainNetwork(深度学习工具箱)开始训练,尽量使用GPU,用CPU速度很慢。
[net,info] = trainNetwork(pximds,lgraph,options);
save('trainedNet.mat','net');
save('trainedInfo.mat','info');
训练过程曲线包括准确率和损失函数,效果还不错。

3.6网络评价
语义分割网络可以看作二分类网络,及当前类别和其他类别。而常用的评价指标是IoU(交化比),有相关公式计算,参考分类网络和分割网络的评估指标,而Matlab可以直接调用相关函数。
pxdsResults = semanticseg(imdsVal,net, ...
'MiniBatchSize',4, ...
'WriteLocation',tempdir, ...
'Verbose',false);
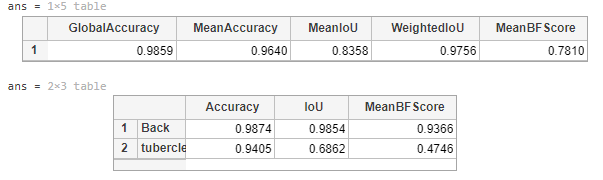
metrics = evaluateSemanticSegmentation(pxdsResults,pxdsVal,'Verbose',false);
metrics.DataSetMetrics %返回整个数据集、单个类和每个测试映像的各种指标
metrics.ClassMetrics %每个类的指标
在整个验证集上测试结果如下,其中平均IoU=83.58%
还可以在单张测试集图像上进行测试
expectedResult = readimage(pxdsVal,10);
actual = uint8(C);
expected = uint8(expectedResult);
imshowpair(actual, expected)
测试结果如下,其他颜色显示了与Ground Truth不同的区域。

3.7测试训练结果
直接上代码和最终语义分割结果
% 加载训练好的模型
clc,clear;
load trainedNet.mat
[file,path] = uigetfile('G:\+1\Graduation_Project\ALL_file\Code\DeeplabV3+_Seg\test_image');
filepath = fullfile(path,file);
I = imread(filepath);
imshow(I);
%Resize the test image size
I = imresize(I,[224,224]);
Segment the image.
C= semanticseg(I,net);
Display the results.
%展示分割结果
classNames = ["Back" "tubercle"]; %按顺序给出类别
cmap = camvidColorMap; %这里需要更改函数内参数,即指定分类区域颜色
B = labeloverlay(I,C,'ColorMap',cmap);
imshow(B),title("语义分割结果");
pixelLabelColorbar(cmap,classNames);
其中camvidColorMap函数需要自己编写,指定分类区域颜色。
function cmap = camvidColorMap()
cmap = [
0 0 255 % Back蓝
255 0 0 % Tubercle红
];
% Normalize between [0 1].
cmap = cmap ./ 255;
end


这样分割网络设计就告一段落。
三、分类网络的构建
分类网络我使用了Matlab深度网络设计器,非常便捷,不用写很多代码,利用可视化工具箱就可以实现模型训练。
1.图像预处理
Matlab大部分搭建好的预训练网络都是三通道并且统一大小,如果不会调整参数,最简单粗暴的方法就是对训练集图像进行预处理,这里提供用Python实现批量Resize和通道转化代码供参考:
统一大小:
from PIL import Image
import os.path
import glob
def convertjpg(jpgfile, outdir, width=227, height=227):
img = Image.open(jpgfile)
try:
new_img = img.resize((width, height), Image.BILINEAR)
if new_img.mode == 'P':
new_img = new_img.convert("RGB")
if new_img.mode == 'RGBA':
new_img = new_img.convert("RGB")
new_img.save(os.path.join(outdir, os.path.basename(jpgfile)))
except Exception as e:
print(e)
for jpgfile in glob.glob("G:/+1/Graduation_Project/ALL_image/Traindata/Decision_TrainData/normal/*.png"):
print(jpgfile)
convertjpg(jpgfile, "G:/+1/Graduation_Project/ALL_image/Traindata/Decision_TrainData/normal")
通道转化(单通道转三通道):
import PIL.Image as Image
import os
path = r"G:\+1\22\image\Traindata\Seg_Traindata\mask"
save_path = r"G:\+1\5"
for i in os.listdir(path):
img = Image.open(os.path.join(path, i)).convert('RGB')
img.save(os.path.join(save_path, i))
除了预处理之外,同上述分割网络一样,需要打上类别标签(benign,maligant,normal),并将数据集拆分为训练集和验证集(验证集可以自己拆分再导入,也可通过工具先按比例拆分)。
2.网络搭建
没有使用过于复杂的模型,我使用了Alexnet网络,搭建网络过程是下载导入预训练网络—>调整适应自己训练集—>导入训练集和验证集—>调整超参数—>开始训练—>训练结束保存Network,参见官网对使用深度学习工具箱搭建模型的详细介绍,非常简单。
注意:
要根据自己的分类数目调整全连接层参数,这三层删除重新添加,修改全连接层的OutputSize为自己的分类数目。对于输入层的InputSize如果调整后分析出错可以选择对训练集进行预处理来适应网络。

至于超参数,我最后设置的使用sgdm优化器,初始学习率0.0001%,BatchSize设置为8,其他默认参数。训练过程如下图,验证集准确率88.61%。 注:之前使用的网络过于复杂且数据增强不够,导致过拟合(训练集loss曲线下降至平缓,验证集loss曲线先下降后上升),图一为最终训练结果,图二结果有过拟合且测试集准确率不高。


训练结束从工作区保存训练好模型,包含以下三个文件和一个实时脚本(.mlx):

3.测试训练结果
加载好网络后用 classify函数就能计算出最终的categorical。
clc;clear
% 加载训练好的模型
load('trainedNetwork_1');
% 查看模型细节
%trainedNetwork_1.Layers
% 调整图像大小
[file,path] = uigetfile('*');
image = fullfile(path,file);
I = imresize(imread(image),[227,227]);
file
tic%计时
% 使用模型分类
label = classify(trainedNetwork_1, I)
imshow(I);
toc

这样简单的分类网络就做好了。
四、APP设计
使用Matlab自带的工具箱—APP Densigner设计APP。

打开界面后通过拖动控件对APP进行布局和装饰。再转到代码页面与要实现的功能完成映射。比如我需要一个按钮控制输入图像,然后构建一个函数返回输出的分割图像,准确率和诊断结果三个参量。
function [label,text,B] =Dec_Seg(I)
%调用模型返回三个参量
load trainedNetwork_1
load trainedNet
I = imresize(I,[227,227]);
[label,score] = classify(trainedNetwork_1, I);
%准确率
maxscore = max(score);
text= string(maxscore*100)+"%";
if label == 'benign'
label='发现良性结节,结节边界清晰,形态规则';
elseif label == 'malignant'
label='发现恶性结节,结节边界欠清晰,形态欠规则';
else
label='尚未发现结节,请进一步检查' ;
end
C= semanticseg(I,net);
cmap = camvidColorMap;
B = labeloverlay(I,C,'ColorMap',cmap);
end
接下来就是回调到按钮的控制函数,需要输入图像路径和调用上述函数返回值。


这样APP就完成了设计,展示一下红色的爱心乳腺结节。

设计好之后可以打包APP并发布。
安装在我的APP页面,下次可以直接打开,也可以将后缀mlappinstall文件发给其他人在Matlab上完成安装。

五、总结
限于时间篇幅更囿于水平,本文只是一篇分享个人学习用Matlab做深度学习的过程,并没有深入探讨其中各种模型和超参数,但学习一个新领域时我觉得首先把成果做出来再去研究是一个效率比较高的过程,更有成就感,能让晦涩的理论知识茅塞顿开。
本来打算分几篇发,为了不破坏完整性就肝了好长一篇,第一篇在CSDN上的博客很不容易,光个图像标题和GIF就花了好多时间,若发现问题欢迎探讨(ps:我也是小白),以后也要坚持写呀~