运用Edge Impulse实现MCU机器学习,试试吧~

作者 | Andrea Garrapa(意大利)
译者 | 禾沐
将AI应用带到边缘终端设备(智能手机、可穿戴、汽车和物联网设备等)可以降低功耗,并减少数据中心资源的负载,其中在MCU上实现机器学习是这种愿景中最为活跃的领域之一,tinyML是一个致力于该领域的新的研究方向。本文讲述了使用Edge Impulse训练验证模型、模型转换、生成代码并部署的过程。Edge Impulse是一个在边缘设备上进行机器学习的在线开发平台,正在获得嵌入式系统产业界的广泛支持。
业界对机器学习 的兴趣近来大增,已经有许多云应用帮助我们进行机器学习的开发。但是,如果应用缺乏互联网连接,需要处理敏感数据,或者要求低延迟,在小型微控制器上运行机器学习会更为合理。本文通过一个样例项目演示使用Edge Impulse在小型、低功耗、低成本微控制器上进行机器学习的开发。
在应用端运行机器学习(ML)算法被称为边缘计算, 比如在工业园区的一个厂房内。在工业4.0和物联网中通过边缘计算使用ML意味着数据不会离开现场,基于ML的决策也可以被快速采用。模型的训练需要大量的计算,但是我们可以在小型、高性价比的微控制器上运行这些计算。基于非对称的ML的大量研究是tinyML基金会的成立的前奏。在嵌入式设备上运行机器学习模型的主要原因有三个:
•本地处理:避免传输传感器收集的数据。不需要互联网连接的话,设备部署的限制就会更少。
•低能耗:微控制器的能耗非常低。一个电池驱动的微控制器可以持续运行图像辨识算法一年。
•成本和部署:微控制器普适而且低成本,方便ML模型的部署。通过简单的软件升级,它们可以很快部署新的或者升级后的模型,而不需要替换硬件。
tinyML依然是一个比较新的研究方向,但是其应用非常广泛,包括农业、医疗和预测性维护等。
Edge Impluse
Edge Impluse(tinyML即服务)通过一个开源的设备软件开发套件(SDK)为开发者提供机器学习的支持,包括简单的传感器数据收集、实时信号处理、测试和在任意目标设备上部署的能力,用户还可以扩展和贡献你的算法以及对设备的支持。所有设备软件:SDK、客户端和生成的代码,都以Apache 2.0协议授权。Edge Impluse与TensorFlow Lite Micro项目的协作意味着Edge Impulse可以使用的ML架构、操作和目标更广泛。Edge Impulse SDK面向个人开发者免费,针对在产品中使用SDK的团队则有企业版订阅付费模式。
创建账户并登录之后,你就可以创建你的第一个tinyML项目了,如图1所示,SDK的界面简洁、直观。

图1 Edge Impulse SDK仪表盘
登录之后,仪表盘(Dashboard)显示项目的概况,以及如何启动你的第一个项目,或者继续一个现有项目的指南。界面左侧,在仪表盘下方是其他的主菜单选项,它们的顺序反映了开发的不同阶段,比如设备(Devices)页显示已连接的设备列表,数据获取(Data acquisition)则显示已经收集好的测试和训练数据。Impulse设计(Impulse design)创建一个Impulse,Impulse是一个接收原始数据、运用信号处理提取特性和通过学习块对新数据进行分类的过程。
连接设备时,需要参照仪表盘画面中间的指示,也可以前往设备栏点击连接新设备(Connect a new device)。开发环境支持下列设备:
•ST IoT Discovery Kit:即B-L745E-IOT01A,开发板上搭载使用Cortex-M4处理器的微控制器、MEMS动作传感器、麦克风和WiFi。
•Arduino Nano 33 BLE Sense:一个小尺寸的开发板,上面搭载基于Cortex-M4的微控制器、动作传感器、麦克风和BLE。
•AI ECM3532 Eta Compute Sensor:一个小尺寸的开发板,上面的TENSAI ECM3532 SoC搭载基于Cortex-M3的微控制器和一个单独的CoolFlux DSP用于机器学习的加速。开发板上有两个麦克风,一个6轴加速度计/陀螺仪和一个气压/温度传感器。ECM3532 SoC支持连续电压频率缩放,这允许系统在运行时通过缩放时钟频率和电压调整到最佳的电源效率,从而支持超低功耗机器学习。
•智能手机:Edge Impulse支持能够运行现代浏览器的任何智能手机,过程和方法和其他设备一样。最终,任何数据/模型都可以部署到嵌入式设备上。
上述设备可以用于原始数据取样、构建模型和部署已经训练好的机器学习模型。连接一个或多个设备后,在设备页(见图2)的列表中可以看到它们。我们可以训练模型解析多个设备的历史数据,然后用于分类新的数据,或者识别异常的传感器数据。
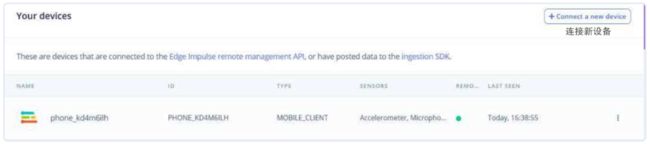
图2 设备页显示已连接的设备
仪表盘的指南部分有两个教程:一个是音频,另一个是手势识别,本文接下来将讨论音频教程。
声音识别
在本教程中,机器学习被用来开发识别特定声音的系统,即音频分类。开发完成时,这一系统能够过滤背景噪音,辨识水龙头开启时的声音。教程引导你从麦克风收集音频数据,运用信号处理提取重要的特征和训练深度神经网络辨别音频片段中是否有流水的声音。最终,模型会被部署到嵌入式系统上进行验证。
收集数据
首先,需要收集用于训练机器学习模型的音频数据。为了检测到水从水龙头流出的声音,我们需要收集一些流水的声音,以及典型的背景噪声(没有流水)的声音样本,这样模型就能够学习两者间的区别。这两类样本代表着我们模型中的两个类型:背景噪声和水龙头开启。在SDK的数据获取(Data acquisition)页可以收集设备传感器数据,这里是存储原始数据的地方。如果设备已经连接到远程管理API,就可以从数据获取页开始新的数据采样。
现在让我们先收录一段水龙头没有打开时的背景噪声,在收录新数据(Record new data)部分选择数据,设置标签(Label)为噪声,定义样本长度(Sample length)为1000,传感器(Sensor)选择内建麦克风。这意味着我们将收录一秒的声音,并将其标记为噪声,标签之后还可以再修改。点击开始采样(Start sampling),设备会录音一秒,并将数据传输到Edge Impulse。数据载入之后,已收集的数据(Collected data)下会出现新的一行记录,可以在界面上分析信号波形或者重播音频(见图3)。

图3 数据收集页收录和回放音频数据的部分
构建数据集
接下来,开始创建一个数据集。对于一个比较简单的音频分类模型,我们应该收集大约10分钟的数据。两个类型的样本应该基本均衡,所以我们需要收集:五分钟的背景噪声,标记为“噪声”;五分钟水龙头开启时的声音,标记为“水龙头”。
在真实世界中,我们感兴趣的声音往往会和其他声音混杂在一起,比如水龙头的流水声往往会伴随着洗碗的声音或者厨房的交谈声,背景噪声还可能有电视、小孩玩耍或者车辆从附近经过的声音。训练用的数据必须包含这些实际环境的声音,如果模型没有接触到它们,准确度会降低。在本文中将收录下面的样本:
•背景噪声:
o没有其他声音:两分钟
o同时有电视/音乐的声音:一分钟
o同时有偶尔的讲话/谈话:一分钟
o同时有做家务的声音:一分钟
•水龙头开启的声音:
o水龙头开启流水的声音:一分钟
o另一个不同的水龙头开启流水的声音:一分钟
o同时有电视/音乐的声音:一分钟
o同时有偶尔的聊天/对话:一分钟
o同时有做家务的声音:一分钟
即使无法取得全部的样本,也不必担心。我们的目标是每个分类都有五分钟的真实世界数据,在具有代表性的数据集上训练出的模型会更加准确有效。无法保证模型能准确分辨数据集以外的声音,所以我们必须尽可能地贴近真实世界,在数据集中包括多种声音。另一个选项是从Edge Impulse下载现成的十分钟样本 ,解压到本地后,在数据获取页点击上传数据(Upload data)图标(见图4),然后上传下载的文件,并添加标签。
图4 数据获取页,用于上传预先准备好的数据集
一次性可以收录的音频长度取决于特定硬件的存储大小,ST B-L745E-IOT01A板的存储容量允许一次性录音60秒,Arduino Nano 33 BLE Sense则只能录音16秒。录音60秒意味着需要将样本长度设置为60 000。从开发板上传输数据往往很慢,在Edge Impulse中采集60秒的样本大约需要7分钟。取得需要的10分钟数据后,就可以开始设计Impulse了。
设计Impulse
Impulse读取原始数据,将其分割为多个更小的窗口,然后通过信号处理块提取特征,通过学习块分类新的数据。信号处理块的作用是简化原始数据的处理,针对同样的输入同一个信号处理块总会返回一致的数值,因此学习块可从之前的经验中学习。在本文使用MFCC信号处理块,MFCC指梅尔频率倒谱系数[ ],这听上去很复杂,实际上就是从声音数据中移除大量的冗余信息。接下来,我们会将简化后的音频数据送到一个神经网络块(学习块)中,学习块将会学习如何区分两个音频类别(水龙头开启和噪声)。现在,打开创建Impulse(Create impulse)页面,你会看到原始数据(Raw data)部分。
同之前提过的一样,Edge Impulse在训练时将样本分割为小的窗口,然后将数据发送到机器学习模型中。窗口大小(Window size)参数控制每个数据段的长度(单位毫秒),一秒长的音频样本足够确定水龙头是否开启,所以设置为1000毫秒。每一个原始样本被分为多个窗口,窗口间距(Window increase)的大小决定下一个窗口和上一个窗口的间距,1000毫秒的窗口间距意味着每个窗口在上一个窗口开始的一秒后开始。
如果窗口间距的数值小于窗口大小,则可创建互相重叠的窗口。虽然窗口间会包括一部分相似的数据,每一个样本依然是独特的。互相重叠的窗口帮助我们高效地利用训练数据,比如1000毫秒的窗口大小和100毫秒的窗口间距意味着可以从两秒的数据中提取十个独特的窗口。本文中设置窗口大小为1000毫秒,窗口间距为300毫秒。点击添加处理块(Add a processing block),选择MFCC块,然后点击添加学习块(Add a learning block),选择Keras神经网络块(Neural Network - Keras),最后点击保存。创建Impulse的页面如图5所示。
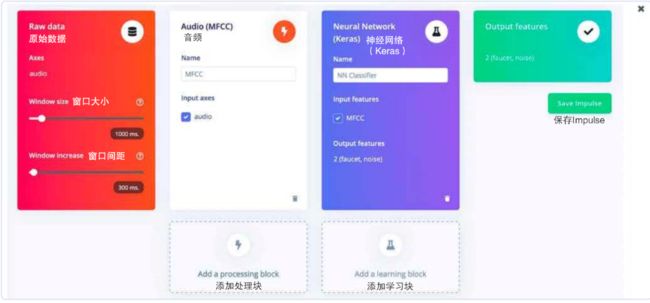
图5 创建Impulse
MFCC块配置
目前已经凑齐了Impulse所需要的基本组成模块,现在可以单独配置每个部分了。在左侧的导航菜单中点击MFCC标签进入块配置页,界面上可以预览数据将如何被转换。在右侧可以看到一个频谱图上显示了MFCC处理音频输入后的输出结果。MFCC块将一个音频样本转换为一个数据表格,每一行是一个频率范围,每一列是本时间区段内频率范围内声音的强度。频谱图用颜色填充每个单元格,颜色的深浅表示振幅的高低。图6中对比了噪声和水龙头声音的频谱图。

图6 噪声(上)和水龙头声音(下)的频谱图
我们的双眼很难分辨出两张图的区别,但对于一个神经网络而言,它们间的差别足够用来学习两个类别的不同。在参数(Parameter)框中可以配置MFCC块,Edge Impulse的默认数值适用于多数情形,这里不做修改。MFCC块产生的频谱图会被发送到神经网络中,神经网络的特性意味着它特别适合学习此类列表数据背后的模式。
在训练神经网络之前,需要从采集的所有音频窗口中产生MFCC特征。点击页面上方的产生特征(Generate feature),然后点击绿色的同名按钮,分析十分钟的样本需要几分钟的时间,这一过程结束后,特征浏览器(Features explorer)会以可视化的形式显示数据集,你可以检查不同类型间的区别是否明显,并查找错误的数据标签。为了能在三维空间内显示所有的特性,这里用到了降维手段。
神经网络配置
神经网络借鉴人脑的工作方式,能够学习辨识训练数据中的模式。我们训练的神经网络从MFCC中取得数据,然后决定输入数据属于噪声类别还是水龙头类别。点击左侧菜单的神经网络分类器(NN Classifier)进入块配置窗口。一个神经网络由多层虚拟的神经元组成,在页面的左侧可以看到当前的状态。输入数据(来自MFCC的频谱图)首先进入第一层神经元,这些神经元有着各自独特的内部状态,会对输入进行过滤和转换。第一层神经元的输出会被送到第二层神经元,以此类推,神经网络会一点点转变原始输入,最终变成完全不同的输出。在本例中,频谱图经过4个中间层后变成两个数字,分别是输入数据代表噪声和水龙头开启的可能性。
在训练中,为了让神经网络能够正确地转换输入并输出我们想要的结果,每个神经元的内部状态都会逐渐转变。当输入一个样本时,根据网络输出结果和正确的响应(标签)间的距离,神经元的内部状态会被调整,这样下次网络给出正确响应的可能性就会更大。重复这一过程几千次,就会得到经过训练的网络。
对于神经网络而言,神经元层的安排被称为“结构”,不同的结构适用于不同的任务。虽然Edge Impulse中默认的神经网络结构很适合当前的项目,但也可以定义你自己的结构。在开始训练模型前,需要更改配置中的一些数值。首先将训练周期数(Number of training cycles)设为300,这意味着整个数据集在训练中会被处理300次。如果周期数太少,网络无法从训练数据中充分学习,但是如果周期数太多,网络可能会过度切合训练数据,无法正确处理新数据,这一问题被称为“过拟合”。
接下来,将最低置信度(Minimum confidence rating)设为0.7,这意味着当神经网络作出预测时,除非声音是水龙头流水声的概率为0.7以上(比如0.8),Edge Impulse将会忽略这一预测。现在我们可以点击开始训练(Start training),训练将会花上几分钟时间,结束后会在页面下方看到上次训练表现面板(见图7)。
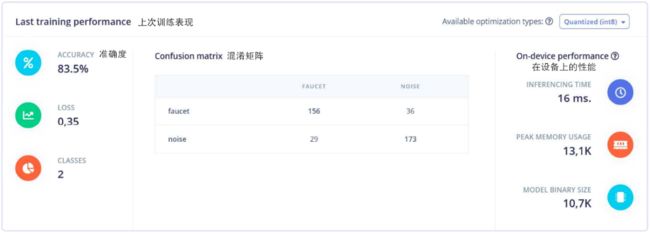
图7 训练后网络的表现
虽然完成了Edge Impulse中神经网络的训练,但是结果中这些数字都意味着什么?在训练开始前,20%的数据被预设为验证数据,它们被用来验证模型的性能,而不是用做训练数据。上次训练表现(Last training performance)面板上显示验证的结果,从而提供关于模型性能的信息,你看到的数字可能会和这里的不同。准确度(Accuracy)指被正确分类的音频样本的百分比,数字越高越好,不过一般不太可能接近100%,极高的准确度往往也意味着过拟合。就许多应用而言,高于80%的准确度已经很好了。面板中央的混淆矩阵 显示正确和错误分类的数目。
分类新的数据
虽然上一步中的性能数据说明模型在训练数据上的表现很好,但在部署前用新数据测试它依然是非常重要的,这能帮助我们确认模型没有过拟合。Edge Impulse内建了一些测试工具,帮助从设备上实时抓取数据并立即进行分类。点击左侧菜单上的实时分类(Live classification)按钮,你的设备应该出现在分类新数据(Classify new data)面板上,点击开始采样(Start sampling)将会收集5秒的背景噪声数据。
测试模型
通过实时分类(Live classification)标签页可以快速测试你的模型,了解模型的行为。不过,如果想要确保你的模型的正确性,需要更加严格地测试你的模型。模型测试(Model testing)标签页正是为此而存在的。理想状况下,你的测试数据集大小应该至少是训练数据集的25%,假设训练数据是10分钟,测试数据至少需要2分30秒。此外,还需要确保测试数据能够反映大量的真实情形,这样能够以不同的输入测试模型的性能。
比如说,收集若干不同水龙头的声音是一个很好的主意,可以从数据获取(Data acquisition)标签页管理你的测试数据。打开标签页,点击上方的测试数据(Test data),使用上传(Upload)功能导入数据,过程同之前上传训练数据一样。确保数据的标签是正确的,结束后返回模型测试(Model testing)标签页,选择全部样本,然后点击分类选中的数据(Classify selected)。
图8是分类的结果,面板显示模型的准确率是73.42%。针对每个样本,面板上会显示其准确率,比如其中一个样本的分类准确度为67%。有很多误分类的样本非常宝贵,这样的样本中有许多模型目前不拟合的音频类型,通常需要将此类样本加入到训练数据中。

图8 测试数据分类的结果
在硬件设备上部署模型
设计、训练并验证了我们的impulse之后,就可以在硬件设备上部署了,这意味着模型可以在没有互联网的情况下以最小的延迟和最低的功耗运行。Edge Impulse可以将整个impulse包装为一个C++代码库以供编程使用,包括MFCC算法、神经网络和分类代码。点击菜单中的部署(Deployment)开始模型的导出过程,接下来在构建固件(Build firmware)下选择正确的开发选项,然后点击构建(Build),就会针对特定的开发板将impulse输出为二进制可执行文件。构建过程完成后程序会提供二进制文件下载,将文件保存到本地。点击构建(Build)按钮时,程序会弹出窗口、提供关于部署的说明,指导你在构建后进行测试。可以在命令行上运行如下命令以打开连接硬件固件的串行接口:$ edge-impulse-run-impulse
这一命令会打开麦克风收录声音,在数据上运行MFCC代码,并对产生的频谱图进行分类。
结 语
在微控制器上运行机器学习是一个比较新的领域,对于不熟悉人工智能的开发者而言很难上手。Edge Impulse简化了数据的收集和分析、神经网络的训练和构建,以及在微控制器上部署的过程。这类模型有着诸多应用,从监控工业机械到辨识语音命令都可以适用。Edge Impulse易于使用,界面直观,而且免费,这意味着可以立即开始探索在嵌入式设备上运行tinyML。(本文首先在Elettronica Open Source 上以意大利文发表。)
相关参考链接:
https://www.expert.ai/blog/machine-learning-definition/.
https://www.tinyml.org/.
https://www.tinyml.org/.
https://cdn.edgeimpulse.com/datasets/faucet.zip.
https://www.tinyml.org/.
https://www.dataschool.io/simple-guide-to-confusion-matrix-terminology/.
https://it.emcelettronica.com/.
![]()
1.杨福宇专栏|TESLA MODEL 3的CAN网络弱点
2.物联网安全的发展现状与展望
3.学习RTOS操作系统,有必要阅读内核源码吧?
4.用全套隔离方案安全控制大功率设备,MPS说这个容易!
5.一种可用于单片机的中断高效处理与事件机制方法
6.hex文件、bin文件、axf文件的区别?
