Feature Pyramid Networks for Object Detection (FPN) 阅读笔记
Feature Pyramid Networks for Object Detection (FPN) 阅读笔记
目录—————————–
- Feature Pyramid Networks for Object Detection (FPN) 阅读笔记
- 目录—————————–
- 一. 文章主要内容:
- 二、了解该论文需要的基础知识(扩展阅读)
- 三、作者要解决的问题
- 3.1 与以前的特征金字塔形式对比
- 四、关键技术点,关键思想
- 4.1 本文核心思想:
- 4.2 本文FPN结构的核心设计
- 4.3 FPN输出与RPN
- 4.4 FPN输出与Fast RCNN
- 五、实验考察
- 5.1 实验配置
- 5.2 打磨实验对RPN
- 5.3 打磨实验Detector
- 5.4 与COCO竞赛其他模型对比
- 5.4 用于语义分割实验
- 六、总结(自己的理解)
说明:笔记主要总结论文关键技术点;
一. 文章主要内容:
本文的一些思想值得深究
论文作者:Tsung-Yi Lin (first),Kaiming He(forth),* CVPR 2017* paper。
该论文主要利用卷积神经网络中固有的特征金字塔形式,通过一个侧面链接,将高层(后层)语义与底层(前层)语义进行融合,实现更好的特征学习。
二、了解该论文需要的基础知识(扩展阅读)
【人工特征标注:】DPM,HOG等知识需要了解
【语义分割:】DeepMask, SharpMask,InstanceFCN等模型需要阅读了解其思想。
三、作者要解决的问题
3.1 与以前的特征金字塔形式对比
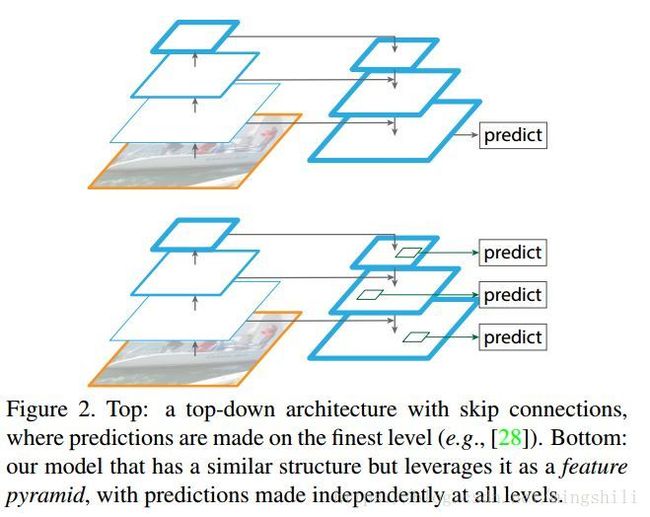
如下图所示,对比不同的金字塔特征模式

1) 第一种:(图a) 根据输入的不同尺度,产生不同尺度的特征表示,然后在根据不同的特征表示尺度进行预测;(输入尺度的金字塔模式)这种模式主要用于人工特征标注时期。DPM模型的主要使用方式。
2)第二种: (图b)由于第一种方式特耗内存和计算,所以一般Fast, Faster RCNN采用第二种非金字塔模式(单一尺寸输入)。
3)第三种:(图c)由于卷积神经网络内含金字塔模式(也就是网络逐层缩减,形成反向金字塔模式),所以像SSD这种物体检测模型使用了神经网络中不同分辨率层作为特征表征,然而因为卷积神经网络不同层语义等级不同,如果使用多种不同分辨率的层,会导致很大的语义gaps,前层高分辨率的特征图一般具有低级语义特征,如果用于预测则会损伤精度。 (SSD在每个分辨率层后又添加新网络层,可能没有用到足够低层的特征)
4)最后一种是本文主要的结构: (图d) 将前层高分辨率低级语义与后面层的同等分辨率的高级语义层进行融合,因此,有一个从顶层逆向的反卷积的旁路。通过旁路链接,将同分辨率等级的特征图进行add (not concat)。
虽然网络前层的高分辨率特征图的特征语义低级,但是这种特征对于小物体的识别有益
本文的目标就是:
很自然的利用ConvNet的特征金字塔分层形式,并且使用不同分辨率特征图都有很强的语义,消除语义gap问题(图c结构引入的问题)
*本文通过从顶层逆向上采样,实现一个旁路,通过旁路链接,将前层低级的特征图与同等分辨率的旁路层进行add,消除语义gaps,且这种方式充分重用了以前的特征图,并且输入只需要单一尺寸就可以。
*在用于语义分割任务的FCN系列中常用的类似结构,不过他们的旁路是反卷积操作,而不是上采样,他们只用旁路的最后一层预测,而FPN结构是利用每一层独立地进行预测输出。
四、关键技术点,关键思想
4.1 本文核心思想:
充分利用ConvNet中金字塔式的特征分层结构(这种分层结构特征语义从低级到高级),建立一种具有统一高语义的特征金字塔。
4.2 本文FPN结构的核心设计
1) 该论文针对Faster RCNN结构进行更改,该结构的基础网络为ResNet,我们知道ResNet分5个stage,每个stage的输入和输出相同且每个stage包含多个conv-bn-relu的组合层。作者利用每一个stage的最后一个输出,作为将要与逆向上采样的高语义特征图融合的对象,因为每个stage的最后一层都是该stage的最强特征表征。,又因为第一个stage输出太大,所以从第二个stage开始计算。
2)自顶向下以及旁路链接如下图所示:
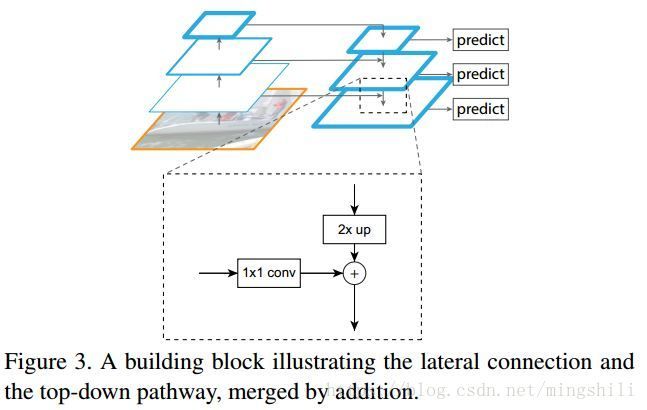
a. 根据上面的图我们可以看到,前层低级语义特征图如何与顶层上采样出来等分辨率的高语义特征图进链接的。低级语义的特征图对对象位置的预测更有利(因为被pool(sub-sample)的次数更少,更能保持位置信息)。
b. 注意该论文使用的上采样方式是:最邻近上采样。
c. 在融合“+”后,又用3x3的卷积进行操作产生最终的fmaps,这样做的作用是:减小上采样带来的混淆影响
d.每个旁路层的通道数都是256。
e. 从底层到上层, C2,C3,C4,C5 C 2 , C 3 , C 4 , C 5 ,从顶层到底层的上采样, P5,P4,P3,P2 P 5 , P 4 , P 3 , P 2 .。一一对应。每一等级的fmaps都可以作为RPN的输入。
4.3 FPN输出与RPN
a.由于FPN每个输出具有不同的scale,所以在利用anchor的时候,FPN每个scale输出对应一个anchor scale,如 P2 P 2 对应着anchor scale=32,anchor ratio依然为{1:2,1:1,2:1}。
b. FPN与RPN链接分为共享参数方式和不共享参数方式;两个方式差别不大,说明所有不同分辨率的层具有相同语义。共享方式是FPN的6个输出都经过一个RPN;而非共享方式是FPN经过6个RPN。
4.4 FPN输出与Fast RCNN
和原始的Faster RCNN不同,我们不用stage5去将RoI产生的14x14的特征图–> 7x7的特征图,而是直接将ROI pool出的7x7特征图直接连接两个全连接用于类别和位置预测。
五、实验考察
5.1 实验配置
5.2 打磨实验对RPN

1)与基本线对比:看表(a),(b),(c)三行,FPN分别与两个baseline进行对比,FPN有高8个百分点;说明在单一个fmaps上使用多个anchor不如在多个尺度的fmaps使用anchor——这种强语义与粗分辨率之间的权衡。
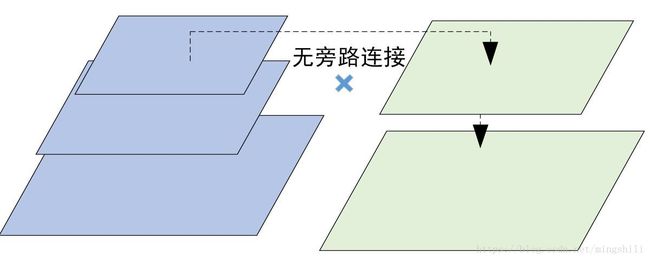
2)top-down旁路的重要程度:(d)对比实验仅仅用旁路链接,没有顶层的上采样,因此仍然存在不同尺度fmaps有语义差距的问题。所以提升的结果不明想。如下图所示:

3)旁路连接1x1卷积的重要性: (e)与(c)对比能检验到旁路链接的重要性,e的结果低于c,说明通过旁路连接,能将低层次但位置信息保留更好的信息得到。对预测位置有帮助。具体如下图所示:
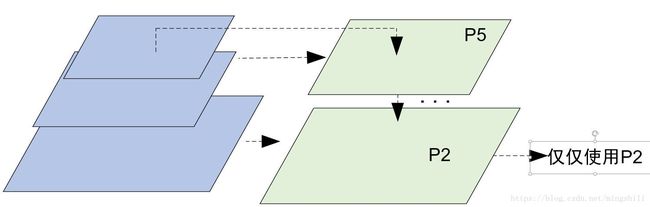
4)仅仅使用一个P2层,而不是整个金字塔所有fmaps的对比::(f)所示,仅仅在P2上使用所有anchor类型,尽管P2的anchor数目很多,但是不如FPN的精度提升高。这个暗示更多的anchor也不将很好的提升精度。
5.3 打磨实验Detector
如下图为Fast RCNN处的打磨实验,(a)为基准线是Faster RCNN上的连接模式14x14–>stage5–>fc,从多个Ck层选取推荐区域,推荐区域仅在C4上产生ROI。
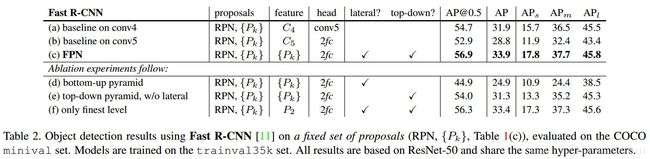
1)将stage5换成2-fc(两个全连接): (b) 将在stage4(P5)处连接两个全连接层,进行类别和位置预测,区域的推荐根据多个层,根据推荐的ROI从C5层选取特征(b所示),而(c)是FPN的模式,ROI根据不同的Ck层选取特征;(b)结果说明,2-fc模式导致性能降低。而FPN模式,就可以使用2-fc模式产生很好的结果。
2)旁路和top-down链接的重要性考察: (d)是没有top-down上采样的模式,仅仅选取不同的fmaps,该模式的性能下降很大,说明低级语义的fmaps对性能精度影响很大。
3)仅仅使用P2层: 注意仅仅使用P2层是在选取ROI特征时,仅仅用在P2层上,而ROI的区域推荐RPN是来自于不同的层。这一模式结果仅次于FPN,说明ROI pooling对于区域尺度不是很敏感。
如下图,与原始Faster RCNN的对比

4) 超参数设置不同:下表为个参数设置对比图
| 超参数设置 | baseline from He.et.al | baseline on conv4 |
|---|---|---|
| min_side | 600 | 800 |
| number of ROIs | 64 | 512 |
| anchor的数目 | 3/4个scale * 3个ratio=9/12 | 5个scale*3ratio=15 |
| 测试时proposal个数 | 300 | 1000 |
5) FPN是否共享参数:也就是( P2,P3,P4,P5,P6 P 2 , P 3 , P 4 , P 5 , P 6 )是否公用一个RPN网络。如下表所示:影响不大

5.4 与COCO竞赛其他模型对比
如下图所示为与其他COCO模型的比较, 可以了解一下其他模型的思想,另外观察可以发现,这种FPN结构,联合了前面位置信息保留较好的层,使得对小物体的识别很有优势很明显。17.5 vs 14.7

5.4 用于语义分割实验
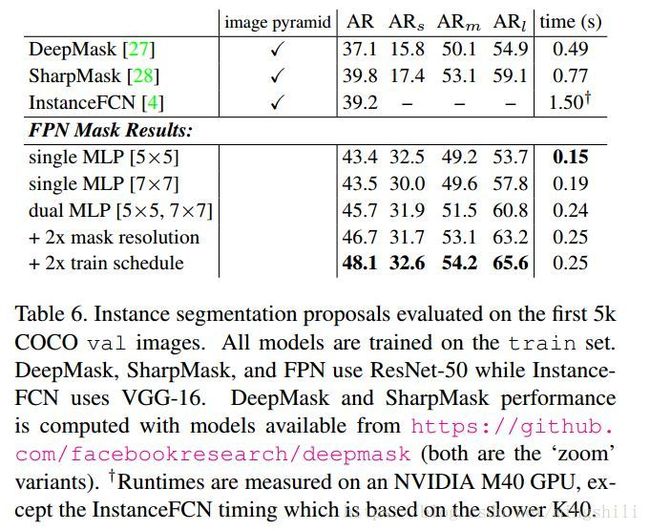
下面的图为用于语义分割的链接图,能很好的转化,分别链接一个FCN结构输出mask即可用于语义分割。

下面为与其他语义分割模型的对比:需要了解一下其他模型的思想
六、总结(自己的理解)
本论文,通过权衡低级语义高分辨率层与高级语义低分辨率层的优劣,联合它们,提高对象检测性能。
1)网络前层具有低级语义,直接使用会导致识别精度下降,但是它又保留着很好的位置信息,对于对象检测很有好处,所以为了使用它,需要与强语义的后层进行连接使用。(本文核心思想)
2)高级语义层有很低的分辨率,对于对象的检测具有很好的类别贡献,但是位置信息由于前面多层的下采样被丢失;
3)top-down的旁路连接是用上采样,而不是反卷积操作。(需要注意的点)可以考察一下,利用反卷积操作会怎样。
4)本文的网络结构和FCN系列的Unet很像。具体区别如下图所示,FPN利用了整个金字塔,而FCN系列仅仅利用了金字塔低端。