基于MNIST手写体数字识别--含可直接使用代码【Python+Tensorflow+CNN+Keras】
基于MNIST手写体数字识别--【Python+Tensorflow+CNN+Keras】
- 1.任务
- 2.数据集分析
-
- 2.1 数据集总体分析
- 2.2 单个图片样本可视化
- 3. 数据处理
- 4. 搭建神经网络
-
- 4.1 定义模型
- 4.2 定义损失函数、优化函数、评测方法
- 4.3 模型训练
- 4.4 评估模型
- 4.5 可视化测试模型
- 5. 总代码
- 6. 撒花撒花撒花
- 可使用类
1.任务
利用数据集:MNIST http://yann.lecun.com/exdb/mnist/ 完成手写体数字识别
紫色yyds
2.数据集分析
2.1 数据集总体分析
使用keras.datasets库的mnist.py文件中的load_data方法加载数据
代码
import tensorflow as tf
mnist=tf.keras.datasets.mnist
#导入mnist数据集,确保网络畅通
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
#shape属性获取数据形状
print(X_train.shape,Y_train.shape,X_test.shape,Y_test.shape)
shape函数
import numpy as np
x = np.array([[1,2,5],[2,3,5],[3,4,5],[2,3,6]])
#输出数组的行和列数
print x.shape #结果: (4, 3)
#只输出行数
print x.shape[0] #结果: 4
#只输出列数
print x.shape[1] #结果: 3
结果(数据集分析结果)

分析
训练集共有60000个样本,测试集共有10000个样本,每个图片样本的像素大小是2828的单通道灰度图(单通道图每个像素点只能有有一个值表示颜色,每个像素取值范围是[0-255])。X_train(储存样本数量,样本像素行,样本像素列);Y_trainn 。对此X_train是60000张2828的数据,尺寸是600002828,Y_train是对应的数字,尺寸是60000*1,X_test和Y_test同理。在本报告后文将Y_train以及Y_test称为数字标准答案。
单通道灰度图
单通道图: 俗称灰度图,每个像素点只能有有一个值表示颜色,它的像素值在0到255之间,0是黑色,255是白色,中间值是一些不同等级的灰色。. (也有3通道的灰度图,3通道灰度图只有一个通道有值,其他两个通道的值都是零)
2.2 单个图片样本可视化
代码
# 导入可视化的包
import matplotlib.pyplot as plt
# 测试样本编号,取值范围[0-60000),此处随机采用406号样本
imgNum = 406
# cmap用于改变绘制风格,采用gray黑白
plt.imshow(X_train[imgNum],cmap='gray')
#设置图像标题【此处我们打印出该图像对应的数字作为标题,方便查看】
plt.title(Y_train[imgNum])
plt.show()
cmap常用于改变绘制风格,如黑白gray,翠绿色virdidis,使用plt.imshow时常用不同的颜色,如plt.imshow(images, cmap=plt.get_cmap(‘gray_r’))是白底黑字的
结果
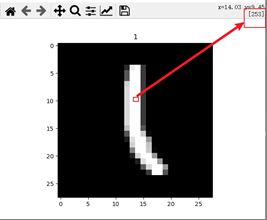
分析
红色箭头为对应像素点的值[0-255],图片标题为图像数字标准答案
3. 数据处理
目的在于将原始的特征矩阵做数据处理形成模型需要的数据。
代码
# 图像的尺寸
img_rows, img_cols = 28, 28
# 将图像像素转化为0-1的实数
X_train, X_test = X_train / 255.0, X_test / 255.0
# 将标准答案通过to_categorical函数将原向量变为one-hot编码转化为需要的格式
# 由于数字是0-9,所以数字类型是10个,对此令num_classes=10
Y_train = keras.utils.to_categorical(Y_train, num_classes=10)
#to_categorical函数
#作用:将原向量变为one-hot编码,用法
#调用to_categorical将vector按照num_classes个类别来进行转换
l = to_categorical(vector, num_classes)
print(Y_train)
Y_test = keras.utils.to_categorical(Y_test, num_classes=10)
# 将训练所用的图像调整尺寸,由于图像是黑白图像,所以最后一维的值是1
# reshape作用:将数组中数据重新划分,X_train、X_test将reshape(60000,28,28,1)
# print(X_train.shape[0])#60000
X_train = X_train.reshape(X_train.shape[0], img_rows, img_cols, 1)
# print(X_train)
X_test = X_test.reshape(X_test.shape[0], img_rows, img_cols, 1)
结果
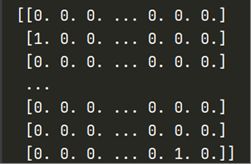
(one-hot编码结果)
one-hot编码又称为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。
自然编码:000,001,010,011,100,101
one-hot编码:000001,000010,000100,001000,010000,100000
(reshape结果)
4. 搭建神经网络
4.1 定义模型
代码
# 定义模型Sequential 序贯模型。序贯模型是线性、从头到尾的结构顺序,
不分叉,是多个网络层的线性堆叠
model = models.Sequential()
# # 向模型中添加层
# 【Conv2D】
# 构建卷积层。用于从输入的高维数组中提取特征。卷积层的每个过滤器就是一个特征映射,用于提取某一个特征,
# 过滤器的数量决定了卷积层输出特征个数,或者输出深度。
# 因此,图片等高维数据每经过一个卷积层,深度都会增加,并且等于过滤器的数量
model.add(layers.Conv2D(32, kernel_size=(5,5), # 添加卷积层,深度32,过滤器大小5*5
activation='relu', # 使用relu激活函数
input_shape=(img_rows, img_cols, 1))) # 输入的尺寸就是一张图片的尺寸(28,28,1)
model.add(layers.MaxPooling2D(pool_size=(2, 2))) # 添加池化层,过滤器大小是2*2
model.add(layers.Conv2D(64, (5,5), activation='relu')) # 添加卷积层,简单写法
model.add(layers.MaxPooling2D(pool_size=(2, 2))) # 添加池化层
model.add(layers.Flatten()) # 将池化层的输出拉直,然后作为全连接层的输入
model.add(layers.Dense(500, activation='relu')) # 添加有500个结点的全连接层,激活函数用relu
model.add(layers.Dense(10, activation='softmax')) # 输出最终结果,有10个,激活函数用softmax
# 打印模型
model.summary()
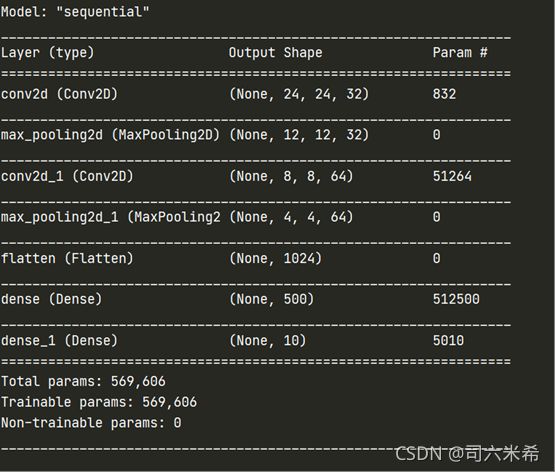
结果模型结构
4.2 定义损失函数、优化函数、评测方法
代码及解析
# 定义损失函数、优化函数、评测方法
# model.compile()方法用于在配置训练方法时,告知训练时用的优化器、损失函数和准确率评测标准
# model.compile(optimizer = 优化器,loss = 损失函数,metrics = ["准确率”])
# 多分类损失函数categorical_crossentropy
#注意:当使用categorical_crossentropy损失函数时,标签应为多类模式,
# 例如如果有10个类别,每一个样本的标签应该是一个10维的向量,该向量在对应有值的索引位置为1其余为0
model.compile(loss=keras.losses.categorical_crossentropy,
# 优化器采用SGD随机梯度下降算法
optimizer=keras.optimizers.SGD(),
metrics=['accuracy'])
4.3 模型训练
代码及解析
# 自动完成模型的训练过程
# model.fit()方法用于执行训练过程
# model.fit( 训练集的输入特征,训练集的标签,
# batch_size, #每一个batch的大小
# epochs, #迭代次数
# validation_data = (测试集的输入特征,测试集的标签),
# validation_split = 从测试集中划分多少比例给训练集,
# validation_freq = 测试的epoch间隔数)
model.fit(X_train, Y_train, # 训练集
batch_size=128, # batchsize
epochs=20, # 训练轮数
validation_data=(X_test, Y_test)) # 验证集
4.4 评估模型
测试准确率约为0.9865
代码
# 打印运行结果,即损失和准确度
# model.evaluate函数 输入数据和标签,输出损失和精确度.
score = model.evaluate(X_test, Y_test)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
结果

4.5 可视化测试模型
代码
定义draw函数画出单个数字
def draw(position, image, title, isTrue):
# 调用matplotlib.pyplot库的subplot方法指定子图位置
plt.subplot(*position)
# 调用matplotlib.pyplot库的imshow方法把数字矩阵绘制成图/
plt.imshow(image.reshape(-1, 28), cmap='Purples')
# 设置不显示坐标轴
plt.axis('off')
#做出判断,实际数字与预测数字是否相同,如果不相同则字体颜色为红色
if not isTrue:
plt.title(title, color='red')
else:
plt.title(title)
批量绘图
def batch(batch_size, test_X, test_y):
random.sample()
# random.sample可以从指定的序列中,随机的截取指定长度的片断,不作原地修改
selected_index = random.sample(range(len(test_y)), k=batch_size)
images = test_X[selected_index]
labels = test_y[selected_index]
# model.predict输入测试数据, 输出预测结果
predict_labels = model.predict(images)
image_number = images.shape[0]
# Math.ceil() “向上取整”, 即小数部分直接舍去,并向正数部分进1
row_number = math.ceil(image_number ** 0.5)
column_number = row_number
# figure( figsize=None)figsize: 指定figure的宽和高,单位为英寸;
plt.figure(figsize=(row_number + 8, column_number + 8))
for i in range(row_number):
for j in range(column_number):
index = i * column_number + j
if index < image_number:
position = (row_number, column_number, index + 1)
image = images[index]
# argmax(a, axis=None, out=None)返回axis维度的最大值的索引a :输入一个array类型的数组。
# axis:参数为None时默认比较整个数组,参数为0按列比较,参数为1按行比较
actual = np.argmax(labels[index])
predict = np.argmax(predict_labels[index])
isTrue = actual == predict
title = 'actual:%d\npredict:%d' % (actual, predict)
draw(position, image, title, isTrue)
batch(100, X_test, Y_test)
plt.show()
结果

5. 总代码
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras import models
import tensorflow as tf
import numpy as np
import random
import math
# 导入可视化的包
import matplotlib.pyplot as plt
mnist=tf.keras.datasets.mnist
#导入mnist数据集,确保网络畅通
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
#shape属性获取数据形状
# print(X_train.shape,Y_train.shape,X_test.shape,Y_test.shape)
# ********单个图片样本打印************
# # 测试样本编号,取值范围[0-60000),此处随机采用406号样本
# imgNum = 406
# # cmap用于改变绘制风格,采用gray黑白
# plt.imshow(X_train[imgNum],cmap='gray')
# #设置图像标题【此处我们打印出该图像对应的数字作为标题,方便查看】
# plt.title(Y_train[imgNum])
# plt.show()
# 图像的尺寸
img_rows, img_cols = 28, 28
# 将图像像素转化为0-1的实数
X_train, X_test = X_train / 255.0, X_test / 255.0
# 将标准答案通过to_categorical函数将原向量变为one-hot编码转化为需要的格式
# 由于数字是0-9,所以数字类型是10个,对此令num_classes=10
Y_train = keras.utils.to_categorical(Y_train, num_classes=10)
# print(Y_train)
Y_test = keras.utils.to_categorical(Y_test, num_classes=10)
# 将训练所用的图像调整尺寸,由于图像是黑白图像,所以最后一维的值是1
# reshape作用:将数组中数据重新划分,X_train、X_test将reshape(60000,28,28,1)
# print(X_train.shape[0])#60000
X_train = X_train.reshape(X_train.shape[0], img_rows, img_cols, 1)
# print(X_train)
X_test = X_test.reshape(X_test.shape[0], img_rows, img_cols, 1)
# ********模型*******
# 定义模型Sequential 序贯模型。序贯模型是线性、从头到尾的结构顺序,不分叉,是多个网络层的线性堆叠
model = models.Sequential()
# # 向模型中添加层
# 【Conv2D】
# 构建卷积层。用于从输入的高维数组中提取特征。卷积层的每个过滤器就是一个特征映射,用于提取某一个特征,
# 过滤器的数量决定了卷积层输出特征个数,或者输出深度。
# 因此,图片等高维数据每经过一个卷积层,深度都会增加,并且等于过滤器的数量
model.add(layers.Conv2D(32, kernel_size=(5,5), # 添加卷积层,深度32,过滤器大小5*5
activation='relu', # 使用relu激活函数
input_shape=(img_rows, img_cols, 1))) # 输入的尺寸就是一张图片的尺寸(28,28,1)
model.add(layers.MaxPooling2D(pool_size=(2, 2))) # 添加池化层,过滤器大小是2*2
model.add(layers.Conv2D(64, (5,5), activation='relu')) # 添加卷积层,简单写法
model.add(layers.MaxPooling2D(pool_size=(2, 2))) # 添加池化层
model.add(layers.Flatten()) # 将池化层的输出拉直,然后作为全连接层的输入
model.add(layers.Dense(500, activation='relu')) # 添加有500个结点的全连接层,激活函数用relu
model.add(layers.Dense(10, activation='softmax')) # 输出最终结果,有10个,激活函数用softmax
# 打印模型
# model.summary()
# 定义损失函数、优化函数、评测方法
# model.compile()方法用于在配置训练方法时,告知训练时用的优化器、损失函数和准确率评测标准
# model.compile(optimizer = 优化器,loss = 损失函数,metrics = ["准确率”])
# 多分类损失函数categorical_crossentropy
#注意:当使用categorical_crossentropy损失函数时,标签应为多类模式,
# 例如如果有10个类别,每一个样本的标签应该是一个10维的向量,该向量在对应有值的索引位置为1其余为0
model.compile(loss=keras.losses.categorical_crossentropy,
# 优化器采用SGD随机梯度下降算法
optimizer=keras.optimizers.SGD(),
metrics=['accuracy'])
# 自动完成模型的训练过程
# model.fit()方法用于执行训练过程
# model.fit( 训练集的输入特征,训练集的标签,
# batch_size, #每一个batch的大小
# epochs, #迭代次数
# validation_data = (测试集的输入特征,测试集的标签),
# validation_split = 从测试集中划分多少比例给训练集,
# validation_freq = 测试的epoch间隔数)
model.fit(X_train, Y_train, # 训练集
batch_size=128, # batchsize
epochs=20, # 训练轮数
validation_data=(X_test, Y_test)) # 验证集
# 打印运行结果,即损失和准确度
# model.evaluate函数 输入数据和标签,输出损失和精确度.
score = model.evaluate(X_test, Y_test)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
# 定义draw函数画出单个数字
def draw(position, image, title, isTrue):
# 调用matplotlib.pyplot库的subplot方法指定子图位置
plt.subplot(*position)
# 调用matplotlib.pyplot库的imshow方法把数字矩阵绘制成图/
plt.imshow(image.reshape(-1, 28), cmap='Purples')
# 设置不显示坐标轴
plt.axis('off')
#做出判断,实际数字与预测数字是否相同,如果不相同则字体颜色为红色
if not isTrue:
plt.title(title, color='red')
else:
plt.title(title)
# 批量绘图
def batch(batch_size, test_X, test_y):
random.sample()
# random.sample可以从指定的序列中,随机的截取指定长度的片断,不作原地修改
selected_index = random.sample(range(len(test_y)), k=batch_size)
images = test_X[selected_index]
labels = test_y[selected_index]
# model.predict输入测试数据, 输出预测结果
predict_labels = model.predict(images)
image_number = images.shape[0]
# Math.ceil() “向上取整”, 即小数部分直接舍去,并向正数部分进1
row_number = math.ceil(image_number ** 0.5)
column_number = row_number
# figure( figsize=None)figsize: 指定figure的宽和高,单位为英寸;
plt.figure(figsize=(row_number + 8, column_number + 8))
for i in range(row_number):
for j in range(column_number):
index = i * column_number + j
if index < image_number:
position = (row_number, column_number, index + 1)
image = images[index]
# argmax(a, axis=None, out=None)返回axis维度的最大值的索引a :输入一个array类型的数组。
# axis:参数为None时默认比较整个数组,参数为0按列比较,参数为1按行比较
actual = np.argmax(labels[index])
predict = np.argmax(predict_labels[index])
isTrue = actual == predict
title = 'actual:%d\npredict:%d' % (actual, predict)
draw(position, image, title, isTrue)
batch(100, X_test, Y_test)
plt.show()
6. 撒花撒花撒花
可使用类
注意: 我的输入测试图像是灰度图像(对此归一化时候,normalize = transforms.Normalize((0.1307,), (0.3081,))即是对两维数据进行归一) 并且此类无需考虑传入图像的大小,于函数中我已有对传入图像尺寸进行转换
若有其它问题一起debug~~
import cv2
img = cv2.imread('./picture.png', cv2.IMREAD_GRAYSCALE)# 灰度图像
print(img.shape)
cv2.imwrite('./one.png', img)
train2('./one.png')
def train2(sketch_src):
img_size = 28
# 标准正态分布变换,这种方法需要使用原始数据的均值(Mean)和标准差(Standard
# Deviation)来进行数据的标准化,在经过标准化变换之后,数据全部符合均值为0、标准差为1的标准正态分布
normalize = transforms.Normalize((0.1307,), (0.3081,))
transform = transforms.Compose([
# transforms.RandomHorizontalFlip(),
transforms.Resize((img_size, img_size)),
transforms.ToTensor(),
normalize
])
# 图片转化为rgb
# 三通道的归一化
img = Image.open(sketch_src).convert('L')
# 获取图片大小,后续数据重新划分使用
(x,y)=img.size
# print(img)
sketch_src2 = transform(img)
print(sketch_src2.shape)
# print("1")
# print(sketch_src2)
sketch = Variable(sketch_src2.unsqueeze(0))
global X_test
X_test=sketch
print(type(X_test))
if torch.cuda.is_available():
sketch2 = sketch.cuda()
# X_test = cv2.imread(sketch_src, cv2.IMREAD_GRAYSCALE)
# ********单个图片样本打印************
# # 测试样本编号,取值范围[0-60000),此处随机采用406号样本
# imgNum = 406
# # cmap用于改变绘制风格,采用gray黑白
# plt.imshow(X_train[imgNum],cmap='gray')
# #设置图像标题【此处我们打印出该图像对应的数字作为标题,方便查看】
# plt.title(Y_train[imgNum])
# plt.show()
mnist=tf.keras.datasets.mnist
#导入mnist数据集,确保网络畅通
(X_train, Y_train),(X_test2, Y_test2)= mnist.load_data()
# 图像的尺寸
img_rows, img_cols = x, y
img_rows2, img_cols2 = 28, 28
# 将图像像素转化为0-1的实数
X_train, X_test = X_train / 255.0, X_test / 255.0
# 将标准答案通过to_categorical函数将原向量变为one-hot编码转化为需要的格式
# 由于数字是0-9,所以数字类型是10个,对此令num_classes=10
Y_train = keras.utils.to_categorical(Y_train, num_classes=10)
# print(Y_train)
# Y_test = keras.utils.to_categorical(Y_test, num_classes=10)
# 将训练所用的图像调整尺寸,由于图像是黑白图像,所以最后一维的值是1
# reshape作用:将数组中数据重新划分,X_train、X_test将reshape(60000,28,28,1)
# print(X_train.shape[0])#60000
X_train = X_train.reshape(X_train.shape[0], img_rows2, img_cols2, 1)
# print(X_train)i
# print(type(X_train))
# print(type(X_test))
X_test=X_test.numpy()
X_test = X_test.reshape(X_test.shape[0], img_rows2, img_cols2, 1)
# shape属性获取数据形状
# print(X_train.shape,Y_train.shape,X_test.shape,Y_test.shape)
# ********模型*******
# 定义模型Sequential 序贯模型。序贯模型是线性、从头到尾的结构顺序,不分叉,是多个网络层的线性堆叠
print(type(X_train))
print(X_train[0].shape)
print(type(X_test))
print(X_test.shape)
model = models.Sequential()
# # 向模型中添加层
# 【Conv2D】
# 构建卷积层。用于从输入的高维数组中提取特征。卷积层的每个过滤器就是一个特征映射,用于提取某一个特征,
# 过滤器的数量决定了卷积层输出特征个数,或者输出深度。
# 因此,图片等高维数据每经过一个卷积层,深度都会增加,并且等于过滤器的数量
model.add(layers.Conv2D(32, kernel_size=(5,5), # 添加卷积层,深度32,过滤器大小5*5
activation='relu', # 使用relu激活函数
input_shape=(img_rows2, img_cols2, 1))) # 输入的尺寸就是一张图片的尺寸(28,28,1)
model.add(layers.MaxPooling2D(pool_size=(2, 2))) # 添加池化层,过滤器大小是2*2
model.add(layers.Conv2D(64, (5,5), activation='relu')) # 添加卷积层,简单写法
model.add(layers.MaxPooling2D(pool_size=(2, 2))) # 添加池化层
model.add(layers.Flatten()) # 将池化层的输出拉直,然后作为全连接层的输入
model.add(layers.Dense(500, activation='relu')) # 添加有500个结点的全连接层,激活函数用relu
model.add(layers.Dense(10, activation='softmax')) # 输出最终结果,有10个,激活函数用softmax
# 打印模型
# model.summary()
# 定义损失函数、优化函数、评测方法
# model.compile()方法用于在配置训练方法时,告知训练时用的优化器、损失函数和准确率评测标准
# model.compile(optimizer = 优化器,loss = 损失函数,metrics = ["准确率”])
# 多分类损失函数categorical_crossentropy
#注意:当使用categorical_crossentropy损失函数时,标签应为多类模式,
# 例如如果有10个类别,每一个样本的标签应该是一个10维的向量,该向量在对应有值的索引位置为1其余为0
model.compile(loss=keras.losses.categorical_crossentropy,
# 优化器采用SGD随机梯度下降算法
optimizer=keras.optimizers.SGD(),
metrics=['accuracy'])
# 自动完成模型的训练过程
# model.fit()方法用于执行训练过程
# model.fit( 训练集的输入特征,训练集的标签,
# batch_size, #每一个batch的大小
# epochs, #迭代次数
# validation_data = (测试集的输入特征,测试集的标签),
# validation_split = 从测试集中划分多少比例给训练集,
# validation_freq = 测试的epoch间隔数)
model.fit(X_train, Y_train, # 训练集
batch_size=128, # batchsize
epochs=2, # 训练轮数
) # 验证集
#预测测试集图像对应的数字
predict=[]
predict_test = model.predict(X_test)
predict = np.argmax(predict_test,1) #axis = 1是取行的最大值的索引,0是列的最大值的索引
#打印预测数据,检测其是否预测准确
print(predict)