目标分类、语义分割、目标检测中的深度学习算法阶段性总结
从博客https://blog.csdn.net/jiugeshao/article/details/112093981写完后,整了一段时间温故了这三个方面的算法知识,同时也找寻了相应的代码去实现这些算法,并在自己的数据集上进行测试。当前对这三个方面的知识点还记忆犹新,结合所看的论文博客归纳下自己的理解(不涉及细节,大方向的了解)。后面会把目标检测和目标分类中的常用算法实现一遍,然后就打算转战Linux下实现。
一.目标分类
1. 从经典的LetNet, AlexNet, VggNet,GooleNet, ZFNet, ResNet再到mobileNet。LetNet理解起来没有什么问题,就是卷积和池化,最后经过FC层来进行分类,还没有什么噱头和技巧性,AlexNet, VggNet本身网络结构好理解,其重要的是部分前向结构,往往会作为很多语义分割和目标检测网络的迁移网络。那这些个网络训练出来的模型来初始化下自己,毕竟站在巨人的肩膀上。这里面除了对卷积层,池化层有了解外,就是对BN层,Dropout层做些了解。
Batch Normalization层,称为批量标准化层。这是一种优化深度学习神经网络的方式,我们常将它夹杂在各层之间,对数据进行归一化处理,对数据标准化可以提高网络的训练速度。可以解决Internal Covariate Shift现象,让数据满足IID独立同分布,对训练中的每一批次的数据进行处理,使其平均值接近0,标准差接近1。
dropout层的作用是为了解决参数量过大带来的过拟合现象,所以的它的原理是,对每一个全连接层,按照一定的概率将其中的神经网络单元暂时从网络中随机丢弃。
2.MobileNet中最要理解的概念便是深度级可分离卷积(depthwise separable convolution),其和普通卷积的区别就是,其第一次卷积后,通道数等同于输入图像的通道数。第二次卷积就是让滤波器的大小变为1*1大小,然后卷积,使得通道数发生变化。

其不仅可以降低模型计算复杂度,而且可以大大降低模型大小,所以在移动端应用场景下,是持续研究的重点。
3.MobileNet v2的新想法包括Linear Bottleneck 和 Inverted Residuals, v3的主要改进如下:
(1)重新设计了耗时的层;
(2)使用h-wish而不是ReLU6;
(3)扩展层使用的滤波器数量不同(使用NetAdapt算法获得最佳数量)
(4)瓶颈层输出的通道数量不同(使用NetAdapt算法获得最佳数量)
(5)Squeeze-and-excitation模块(SE)将通道数仅缩减了3或4倍
(6)对于SE模块,不再使用sigmoid,而是采用ReLU6(x + 3) / 6作为近似(就像h-swish那样)
然后分类网络的改进都可以应用到目标检测、语义分割上,因为这些个网络的前向传播设计可以用最新的分类网络结构来代替,很灵活。好多后续目标检测、语义分割的最新算法就是这么拼凑出来的。
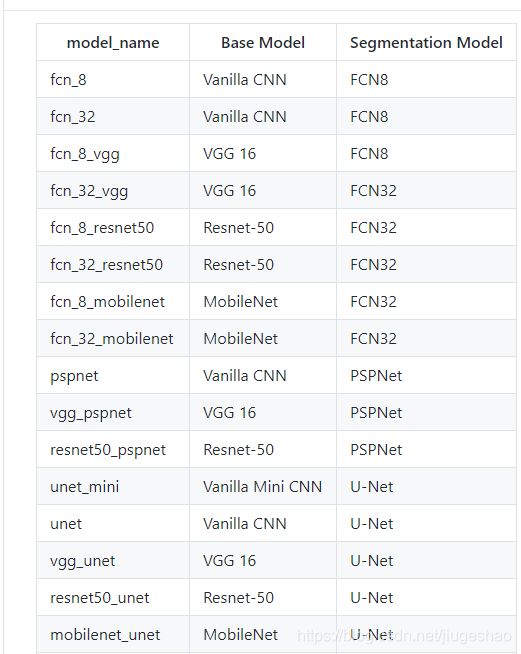
比如:https://github.com/divamgupta/image-segmentation-keras中所实现的语义分割网络,基础网络基本就是常见的分类网络结构。不同的结构的结合其实也可以算一种创新点。
二. 目标检测
这里我看了比较有代表性的RCNN、SPPNet、Fast RCNN、Faster RCNN、YOLO系列、SSD,对这些个算法都做了较细的分析
1. RCNN(2014年)
其实也算是一种在已有思维基础上考虑出来的算法,并不是天马行空,从无到有。RCNN说白了分类3个阶段,第一个阶段是通过Selective Search方法来产生候选区域,第二阶段是对每个候选区域提取固定长度的特征向量,第三阶段是使用SVM分类器进行分类。这里可以看到对比传统算法,还是有很大传统算法的身影,传统放大的想发一般就是遍历图像,运用搜索策略,将提取到的纹理或者几何特征向量输入到SVM进行分类,然后用相似性准则去看在哪个位置区域和我的目标最为接近。只不过这里特征提取是用的CNN。所以有图像处理算法的知识基础,理解这些并不难。相关特点说明再补充如下:R-CNN 采用 AlexNet,采用 Selective Search 技术生成 Region Proposal,在 ImageNet 上先进行预训练,然后利用成熟的权重参数在 PASCAL VOC 数据集上进行 fine-tune,用 CNN 抽取特征,然后用一系列的的 SVM 做类别预测,R-CNN 的 bbox 位置回归基于 DPM 的灵感,自己训练了一个线性回归模型。从ILSVRC 2012、2013表现结果来看,CNN在计算机视觉的特征表示能力要远高于传统的HOG、SIFT特征等,而且这种层次的、多阶段、逐步细化的特征计算方式也更加符合人类的认知习惯。目标检测区别于目标识别很重要的一点是其需要目标的具体位置,也就是BoundingBox。而产生BoundingBox最简单的方法就是滑窗,可以在卷积特征上滑窗。
算法缺点:时间代价太高了,网络训练是分阶段的,太麻烦。
主干网络AlexNet
2.SPPNet(2014)
主要是提出了一种网络结构,能够产生固定大小的表示(fixed-length representation),而不关心输入图像的尺寸或比例,SPP-net可普遍改进各种基于CNN的图像分类方法。在ImageNet-2012数据集上,SPP-net可将各种不同设计的CNN架构的精度都大幅提升。这也可以作为一个结合的创新点,一些网络结构中还没有用此思想的都可以去改进(之前流行的CNNs都需要输入的图像尺寸是固定的(比如224×224),这限制了输入图像的长宽比和缩放尺度。当遇到任意尺寸的图像时,都是先将图像适应成固定尺寸,方法包括裁剪(crop)和变形(wrap))。区别RCNN, SPPNet把整张待检测的图片,输入CNN中,进行一次性特征提取,得到特征图,然后在特征图中找到各个候选框的区域,再对各个候选框采用空间金字塔池化,提取出固定长度的特征向量。而R-CNN输入的是每个候选框,然后在进入使用多尺寸训练,为了在训练时解决不同图像尺寸的问题,考虑一些预设好的尺寸。现在考虑这两个尺寸:180×180,224×224。论文中选择了ZF-5、Convnet-5、Overfeat-5/7作为基础模型
贴上经典的多尺度特征计算图:

此外,记住除了在特征图上使用了不同尺度的,其在输入图像方面也应用了多尺度

单尺寸或多尺寸方法只用于训练阶段。在测试阶段,是直接对各种尺寸的图像应用SPP-net的。
3.Fast RCNN
综合了RCNN和SPPNet, 并在此基础上做了优化,做了创新工作。
区域提取还是在特征图上使用selective search去找到候选区域,类似SPPNet, 其提出了ROI Pooling层,其把图片上selective seach选出的候选框映射到特征图上对应的位置,这个映射是根据输入图片缩小的尺寸来的。将映射到feature map上面的roi region输出成统一大小的特征,因为这些框的特征区域大小不一样。该层输出N*5的矩阵,N表示ROI的数目,5中的第一列表示第几个ROI,其它四个参数(x,y,w,h)表征坐标,不再使用SVM分类器,将分类和回归放在一个网络中训练。将最后一个卷积层的SSP Layer改为RoI Pooling Layer;另外提出了多任务损失函数(Multi-task Loss),将边框回归直接加入到CNN网络中训练,同时包含了候选区域分类损失和位置回归损失。将提取到的特征输入全连接层,然后用Softmax进行分类,对候选区域的位置进行回归。
RoI Pooling Layer:实际上是SPP Layer的简化版,SPP Layer对每个候选区域使用了不同大小的金字塔映射,即SPP Layer采用多个尺度的池化层进行池化操作;而RoI Pooling Layer只需将不同尺度的特征图下采样到一个固定的尺度(例如7*7)。例如对于VGG16网络conv5_3有512个特征图,虽然输入图像的尺寸是任意的,但是通过RoI Pooling Layer后,均会产生一个7*7*512维度的特征向量作为全连接层的输入,即RoI Pooling Layer只采用单一尺度进行池化。两者对比如下图所示:
主干网络是vgg16
4.Faster RCNN
相对于Fast RCNN, 其使用了Region Proposal Networks(RPN网络)生成region proposals, 同时产生建议窗口的CNN和目标检测的CNN共享,其它的和Fast RCNN差不多。重点是RPN。
主要内容是:首先缩放至固定大小MxN,然后将MxN图像送入网络;而Conv layers中包含了13个conv层+13个relu层+4个pooling层;RPN网络首先经过3x3卷积,再分别生成positive anchors和对应bounding box regression偏移量,然后计算出proposals;而Roi Pooling层则利用proposals从feature maps中提取proposal feature送入后续全连接和softmax网络作classification(即分类proposal到底是什么object)。

技巧1:在Faster RCNN Conv layers中对所有的卷积都做了扩边处理( pad=1,即填充一圈0),导致原图变为 (M+2)x(N+2)大小,再做3x3卷积后输出MxN 。正是这种设置,导致Conv layers中的conv层不改变输入和输出矩阵大小
其实RPN最终就是在原图尺度上,每个像素都设置多个候选Anchor。然后用cnn去判断哪些Anchor是里面有目标的positive anchor,哪些是没目标的negative anchor。所以,仅仅是个二分类而已!
那么Anchor一共有多少个?原图800x600,VGG下采样16倍,feature map每个点设置9个Anchor,所以:
ceil(800/16) * ceil(600/16) *9 = 50*38*9=17100
其中ceil()表示向上取整,是因为VGG输出的feature map size= 50*38。这9个anchors相关操作可以看如下图:
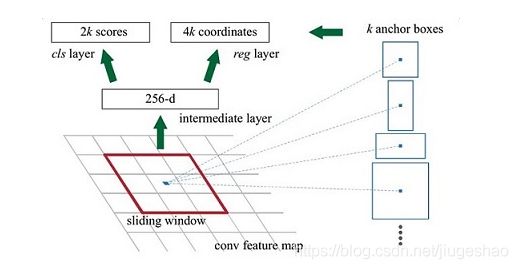
在原文中使用的是ZF model中,其Conv Layers中最后的conv5层num_output=256,对应生成256张特征图,所以相当于feature map每个点都是256-dimensions
在conv5之后,做了rpn_conv/3x3卷积且num_output=256,相当于每个点又融合了周围3x3的空间信息(猜测这样做也许更鲁棒?反正我没测试),同时256-d不变(如图4和图7中的红框)
假设在conv5 feature map中每个点上有k个anchor(默认k=9),而每个anhcor要分positive和negative,所以每个点由256d feature转化为cls=2k scores;而每个anchor都有(x, y, w, h)对应4个偏移量,所以reg=4k coordinates
补充一点,全部anchors拿去训练太多了,训练程序会在合适的anchors中随机选取128个postive anchors+128个negative anchors进行训练(什么是合适的anchors下文5.1有解释)
同时验证2k的设置,可以参见对应的caffe prototx
layer {
name: "rpn_cls_score"
type: "Convolution"
bottom: "rpn/output"
top: "rpn_cls_score"
convolution_param {
num_output: 18 # 2(positive/negative) * 9(anchors)
kernel_size: 1 pad: 0 stride: 1
}
}可以看到其num_output=18,也就是经过该卷积的输出图像为WxHx18大小(注意第二章开头提到的卷积计算方式)。这也就刚好对应了feature maps每一个点都有9个anchors,同时每个anchors又有可能是positive和negative,所有这些信息都保存WxHx(9*2)大小的矩阵。为何这样做?后面接softmax分类获得positive anchors,也就相当于初步提取了检测目标候选区域box(一般认为目标在positive anchors中)。
假设VGG的选用的特征图为50*38*512,则对应设置的anchors个数则为50*38*k, 而RPN输出50*38*2k的分类特征矩阵和50*38*4k的坐标回归特征矩阵
多尺度样本方面,上面可以看到有三种:
图像金字塔:通过将图像放缩到不同的尺寸,然后提取特征去做。有点类似于RCNN中的实现方式,显然这样需要为每一个尺寸重复提取卷积特征,成本很高。
卷积特征金字塔:先对于图像提取卷积特征,然后将卷积特征放缩到不同的尺寸。类似于SPP的实现方式。在SPP中我们也看到,这里面的图像也需要放缩到几种尺寸,产生多尺度结果。
anchor金字塔:通过不同尺度的anchor在卷积特征上滑窗相当于是anchor金字塔,不需要图像有多个尺寸,仅需要有多个尺寸的anchor就好了。文章使用了3种尺度以及3种比例。
5.YOLO
之前R-CNN系列的检测算法都是采用two-stage的方法,先提取proposal,再进行分类和回归,虽然这类方法检测的精度很高,但是检测的速度比较慢,因此本文提出了一个简洁的single-stage的方法来加快检测的速度,可以使用神经网络直接输出bounding box (bbox)的位置和所属类别。YOLO速度非常快,因为YOLO只需将图片输入到网络中即可得到最终的检测结果,所以YOLO也可以实现视频的实时检测。
YOLO的检测过程特别简单,主要包括三步:
Resize image:将图片resize成同样大小的,因为Detection需要图片的一些细粒度的信息,所以本文中使用高分辨率的输入:448*448
Run ConvNet:运行卷积神经网络,得到bbox的分类和回归结果。
NMS:用非极大值抑制来筛选出最终的框
YOLO的思想:
在进行检测时,YOLO会首先将输入图片分成SxS个小格子(grid cell),对于每个格子,YOLO都会预测出B个bounding box(bbox),在文中是预测2个bbox,如图中为红色的格子预测两个黄色的bbox,而对于每个bbox,YOLO都会预测出5个值,其中4个代表bbox的位置,还有一个代表bbox的confidence值.
假设一共有SXS个格子,每个格子预测B个bbox, 每个bbox预测5个值,此外,每个格子预测C个类别(注意不是每个bbox),所以检测器最终需要预测一个SxSx(B*5+C)的tensor。在文中S=7,B=2,C=20, 所以最终会得到一个7x7x(2x5+20) = 7x7x30的tensor
yolo的loss包括4个部分:位置误差,置信度误差(含object),置信度误差(不含object),分类误差
YOLO也存在一些缺点:
因为YOLO中每个cell只预测两个bbox和一个类别,这就限制了能预测重叠或邻近物体的数量,比如说两个物体的中心点都落在这个cell中,但是这个cell只能预测一个类别。
此外,不像Faster R-CNN一样预测offset,YOLO是直接预测bbox的位置的,这就增加了训练的难度。
YOLO是根据训练数据来预测bbox的,但是当测试数据中的物体出现了训练数据中的物体没有的长宽比时,YOLO的泛化能力就变弱了。
同时经过多次下采样,使得最终得到的feature的分辨率比较低,就是得到coarse feature,这可能会影响到物体的定位。
损失函数的设计存在缺陷,使得物体的定位误差有点儿大,尤其在不同尺寸大小的物体的处理上还有待加强。
YOLOv2主要做的改进如下:
第一:批归一化有助于解决反向传播过程中的梯度消失和梯度爆炸问题,降低对一些超参数(比如学习率、网络参数的大小范围、激活函数的选择)的敏感性,并且每个batch分别进行归一化的时候,起到了一定的正则化效果(YOLO2不再使用dropout),从而能够获得更好的收敛速度和收敛效果。第二:YOLO2在采用 224*224 图像进行分类模型预训练后,再采用 448*448 的高分辨率样本对分类模型进行微调(10个epoch),使网络特征逐渐适应 448*448 的分辨率。然后再使用 448*448 的检测样本进行训练,缓解了分辨率突然切换造成的影响。第三:YOLO2也尝试采用先验框(anchor),之前YOLO1并没有采用先验框,并且每个grid只预测两个bounding box,整个图像98个。YOLO2如果每个grid采用9个先验框,总共有13*13*9=1521个先验框。所以,相对YOLO1的81%的召回率,YOLO2的召回率大幅提升到88%。同时mAP有0.2%的轻微下降。之前先验框都是手工设定的,YOLO2尝试统计出更符合样本中对象尺寸的先验框,这样就可以减少网络微调先验框到实际位置的难度。YOLO2的做法是对训练集中标注的边框进行聚类分析,以寻找尽可能匹配样本的边框尺寸。这边有一个新概念叫passthroug层,就是提取的特征图可以拥有上一层特征部分信息。如下图:
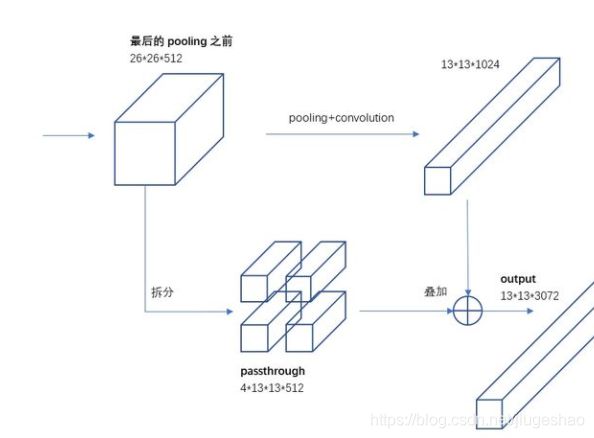
这是为了更好的检测出一些比较小的对象,最后输出的特征图保留一些更细节的信息。
同时丢掉了全连接层,YOLO2可以输入任何尺寸的图像。因为整个网络下采样倍数是32,作者采用了{320,352,...,608}等10种输入图像的尺寸,这些尺寸的输入图像对应输出的特征图宽和高是{10,11,...19}。训练时每10个batch就随机更换一种尺寸,使网络能够适应各种大小的对象检测。
第三:更改了基础网络,选用DarkNet-19, 为了进一步提升速度,YOLO2提出了Darknet-19(有19个卷积层和5个MaxPooling层)网络结构。DarkNet-19比VGG-16小一些,精度不弱于VGG-16,但浮点运算量减少到约1/5,以保证更快的运算速度。
YOLOv2的输入是416*416*3, 变换后大小为13*13*5*25(13是网格数,5是先验框个数,25维向量包含20个对象的分类概率,4个边框坐标,1个边框置信度)
YOLO9000将ImageNet和COCO两个数据集结合在了一起,YOLO2尝试利用ImageNet非常大量的分类样本,联合COCO的对象检测数据集一起训练,使得YOLO2即使没有学过很多对象的检测样本,也能检测出这些对象。,开创性的提出联合使用分类样本和检测样本的训练方法,使对象检测能够扩展到缺乏检测样本的对象。

YOLOv3没有太多的创新,主要是借鉴一些好的方案融合到YOLO里面。不过效果还是不错的,在保持速度优势的前提下,提升了预测精度,尤其是加强了对小物体的识别能力。YOLO3主要的改进有:调整了网络结构;利用多尺度特征进行对象检测;对象分类用Logistic取代了softmax。
基础网络改为Darknet-53, 它借鉴了残差网络residual network的做法,在一些层之间设置了快捷链路(shortcut connections)。
相对于YOLO2曾采用passthrough结构来检测细粒度特征,在YOLO3更进一步采用了3个不同尺度的特征图来进行对象检测,使用类似FPN的结构来实现多尺度检测。这也是一个创新点,用FPN思想去改进一些常见的基础网络,实现多尺度性。
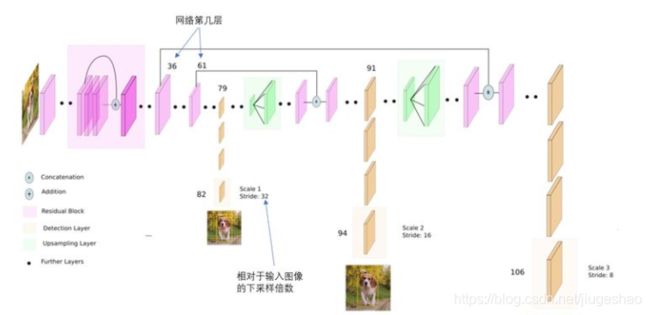
为了实现细粒度的检测,第79层的特征图又开始作上采样(从79层往右开始上采样卷积),然后与第61层特征图融合(Concatenation),这样得到第91层较细粒度的特征图,同样经过几个卷积层后得到相对输入图像16倍下采样的特征图。它具有中等尺度的感受野,适合检测中等尺度的对象。
最后,第91层特征图再次上采样,并与第36层特征图融合(Concatenation),最后得到相对输入图像8倍下采样的特征图。它的感受野最小,适合检测小尺寸的对象。3种不同的尺度的特征图上使用不同大小的先验框。
 、
、
如下的是特征图提取示意图
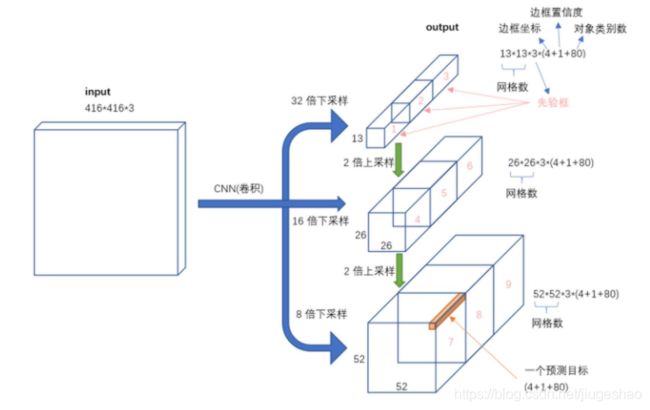
我们看一下YOLO3共进行了多少个预测。对于一个416*416的输入图像,在每个尺度的特征图的每个网格设置3个先验框,总共有 13*13*3 + 26*26*3 + 52*52*3 = 10647 个预测。每一个预测是一个(4+1+80)=85维向量,这个85维向量包含边框坐标(4个数值),边框置信度(1个数值),对象类别的概率(对于COCO数据集,有80种对象)。对比一下,YOLO2采用13*13*5 = 845个预测,YOLO3的尝试预测边框数量增加了10多倍,而且是在不同分辨率上进行,所以mAP以及对小物体的检测效果有一定的提升。对比SSD,为何YOLO V3小物体的检测效果这么好?不仅仅因为YOLO V3引入FPN结构,同时它的检测层由三级feature layers融合,而SSD的六个特征金字塔层全部来自于FCN的最后一层,其实也就是一级特征再做细化,明显一级feature map的特征容量肯定要弱于三级,尤其是浅层包含的大量小物体特征。
YOLOv3相比之前的版本确实精度提高了不少,但是相应的变慢了一些
6.FPN
前面已经提到FPN

FPN可以应用到Faster RCNN上
7.SSD
SSD借鉴了YOLO的one-stage的思想,直接对bbox进行回归和分类,同时也参考了Faster R-CNN中的anchor机制来提升准确率。通过将两种方法的优点结合,并加以改进,SSD保持了很快的检测速度,同时还提高了检测的准确率。使用多尺度的feature map来进行检测。在base network之后加了几层卷积,这些卷积层会逐渐减小feature map的size,然后在不同size的feature map上进行检测,进而实现了一个多尺度的检测。因为不同size的feature map的感受野不同,因此可以检测不同大小的物体,比较大的特征图,感受野较小,适合检测相对较小的物体,而较小的特征图,感受野较大,适合检测相对较大的物体。在YOLO中使用全连接层来进行分类和回归,但是在SSD中改为使用卷积层,我们之前分析过YOLO的缺陷,首先YOLO中每个cell只预测两个bbox和一个类别,这就限制了能预测重叠或邻近物体的数量,同时YOLO直接预测bbox的位置,这样会增加训练难度。因此在SSD中就借鉴Faster R-CNN中的anchor机制,为feature map中的每个点设置几个不同尺寸和宽高比的default boxes(anchors),然后以这些anchors为基准去拟合ground truth box,这样就减小了训练的难度。同时,在SSD中通过计算anchor和ground truth box的IoU来确定哪个anchor负责哪个物体,而不是像YOLO一样通过物体的中心点来确定,这样就能更好的预测那些重叠或近邻的物体。
基础网络结构是VGG16。
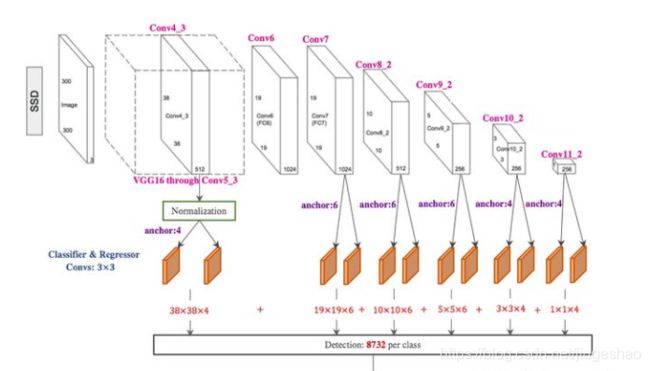
最终anchor的数量为:
38*38*4 + 19*19*6 + 10*10*6 + 5*5*6 + 3*3*4 + 1*1*4 = 8732
为了预测每个anchor的类别和位置offset,SSD将这6个的特征图分别输入到两个3*3的卷积,进行结果预测,其中classier的卷积输出维度为:anchor_num X 21, regressor的卷积输出维度为anchor_num X 4

里面用了Hole即空洞卷积
三. 语义分割
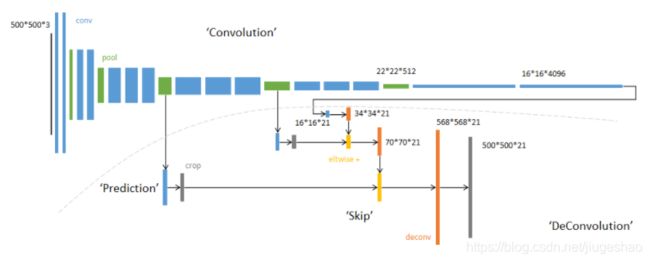
1.FCN
这种端到端的网络好理解,图中像素直接到标注图像素(FCN-8是由up上来的层和当前层做结合-相加,所以细节信息保留的更好)
(目标假设20类,那么背景也算1类,共21类)
2.SegNet
和FCN最大的不同在于decoder upsampling,
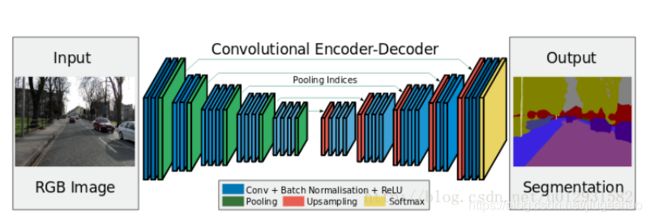
上图结构中,注意,前面encoder每一个pooling层都把pooling indices保存,并且传递到后面对称的upsampling层. 进行upsampling的过程具体如下:
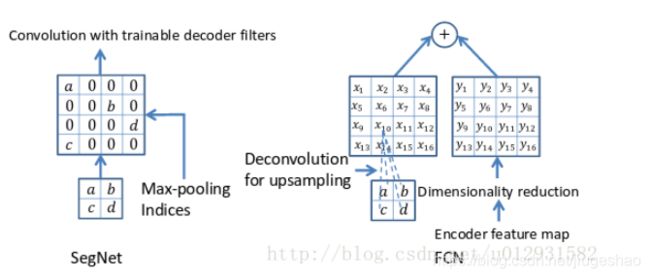
左边是SegNet的upsampling过程,就是把feature map的值 abcd, 通过之前保存的max-pooling的坐标映射到新的feature map中,其他的位置置零.
右边是FCN的upsampling过程,就是把feature map, abcd进行一个反卷积,得到的新的feature map和之前对应的encoder feature map 相加.
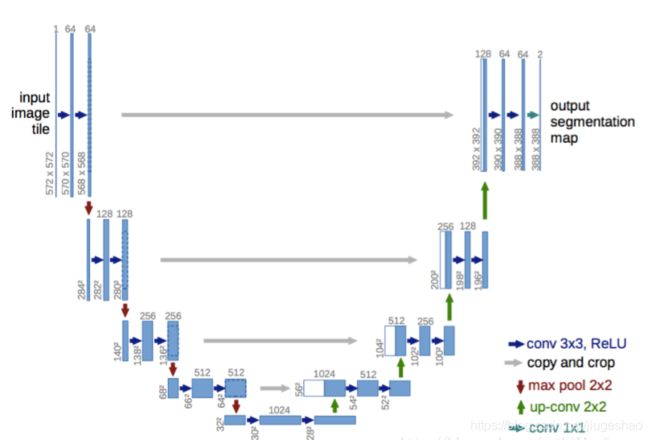
3.UNet
U-net采用了完全不同的特征融合方式:拼接,将特征在channel维度拼接在一起,而FCN融合时使用的对应点相加
参考文章:
https://zhuanlan.zhihu.com/p/31426458
https://zhuanlan.zhihu.com/p/47575929
https://zhuanlan.zhihu.com/p/64741514