27000字,103天,16篇:深入浅出Pandas数据分析
深入浅出Pandas数据分析
大家好,我是Peter~
《深入浅出Pandas数据分析》第一版本终于可以和大家见面咯!文末有资料领取方式
从4月24号的第一篇Pandas文章:《一切从爆炸函数开始》,到昨天8月5号的《图解Pandas的轴旋转函数:stack和unstack》,总共历时103天,让Pandas来见证吧:

两行代码告诉你两个日期之间的时间差,这就是Pandas
什么是Pandas
什么是Pandas?引用一段来自Pandas中文官网的解释:
Pandas 是 Python的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。Pandas 的目标是成为 Python 数据分析实践与实战的必备高级工具,其长远目标是成为最强大、最灵活、可以支持任何语言的开源数据分析工具
简单解释:Pandas是Python的第三库中数据处理和分析最厉害的一个库!
Pandas能处理什么数据
Pandas是一个强大的数据分析库,那它能够处理哪些类型的数据?
- 类似SQL和Excel的表格型数据
- 有序和无序的时间序列数据,常用在金融领域
- 带行列标签的矩阵数据,因为Pandas本身也是基于Numpy开发
103天我写了什么
这103天总共更新了16篇关于Pandas的文章:

第一篇:一切从爆炸函数开始
这篇文章主要讲解的是Pandas中一个函数的使用:explode
它实现的是类似hive中explode函数的功能:从左边的信息统计出右边的信息

第二篇:Series类型数据
Pandas中有两种数据类型,其中一种就是Series。

Series 是一维数组结构,它仅由index(索引)和value(值)构成的。
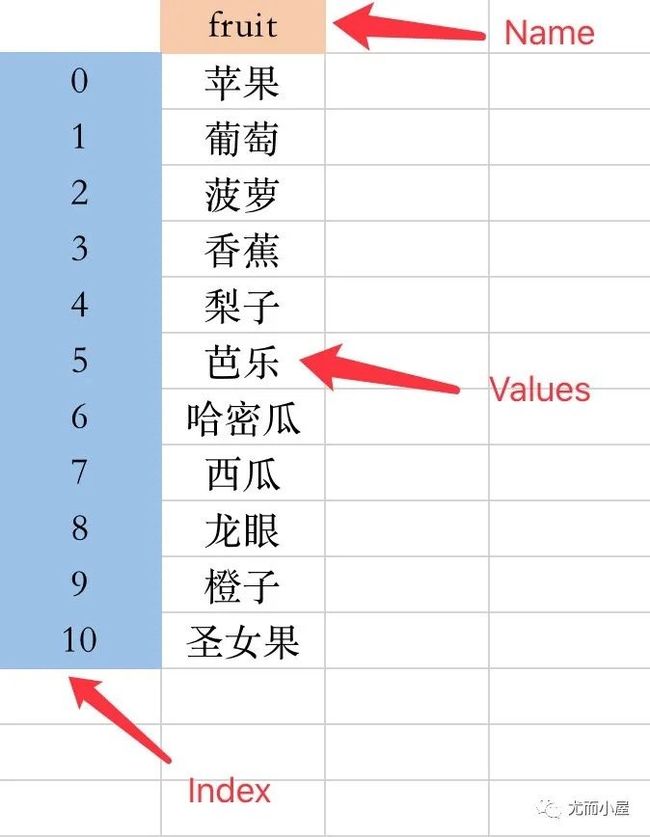
第三篇:创建DataFrame:10种方式任你选
第三篇文章介绍的是Pandas中最常用的一种数据结构:DataFrame 的10种创建方式。
DataFrame 是将数个 Series 按列合并而成的二维数据结构,每一列单独取出来是一个 Series ;除了拥有index和value之外,还有column

写完之后才想起来,漏了一种方式:通过剪贴板直接创建。当我们在剪贴板中准备好了数据,运行下面的语句就可以直接创建:
df = pd.read_clipboard()
df

第四篇:各种骚气的Pandas取数操作
前两篇文章介绍了Series和DataFrame两种数据结构的创建,那么接下来介绍的是:如何从中取数我们想要的数据。
Pandas中取数的方式真的是五花八门,所以总共花了3篇文章。第四篇文章中的方法主要是:

第五篇:赞!五花八门的Pandas筛选数据
也是关于Pandas中取数的文章,主要介绍的是:

第六篇:最后一篇:玩转Pandas取数
最后一篇介绍如何在Pandas中取数,重点介绍了3对函数:它们使用的时候有细微的区别

第七篇:数据处理的基石:数据探索
在我们拿到数据导入到Pandas,进行后续的处理之前,我们需要先查看下数据的基本信息,对这份数据有一个初步的了解,一般包含如下信息:

第八篇:Pandas数据类型操作
Pandas在处理数据的时候,保证数据类型的准确非常重要,第八篇文章主要是介绍了3种常见的数据类型转换方法+数据类型筛选的方法:
- 使用astype()函数进行强制类型转换
- 通过自定义函数来进行数据类型转换
- 使用Pandas提供的函数如to_numeric()、to_datetime()等进行转化
- select_dtypes函数的使用
第九篇:图解Pandas的groupby机制
groupby分组统计是工作和数据处理工程中常见的一种方法。这篇文章详解了groupby的内部机制。

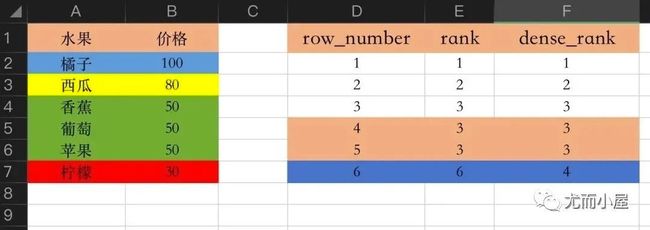
第十篇:图解Pandas的排名rank机制
本篇文章主要是类比SQL中的排名和窗口函数,介绍了如何利用Pandas的rank函数来实现:
- row_number:顺序排名,rank函数的中的method=first
- rank:跳跃排名,rank函数的中的method=min
- dense_rank:密集排名,rank函数的中的method=dense
第十一篇:图解Pandas的排序机制sort_values
有了排名,必然也要来实现一下排序。排序sort_values函数在平时使用的频率是非常高的,经常需要对销售数据做TopN分析,就需要分组统计数据之后再进行一下排序。
第十二篇:图解Pandas的缺失值处理
一般情况下,数据都不是完美的。需要我们进行前期的各种处理操作,对缺失值的处理就是其中之一。
本篇文章主要是介绍了利用Pandas处理缺失值,包含:对缺失值的判断、删除缺失值、填充缺失值:
- df.isnull()、df.notnull():两个函数互为取反
- df.isna():等同于df.isnull()
- df.dropna():删除缺失值
- df.fillna():填充缺失值
第十三篇:图解Pandas重复值处理
数据中存在重复值也是常有的情况,本篇文章中主要是介绍了重复值处理的两种方式:
- duplicated():判断是否有重复值
- drop_duplicates() :删除重复值
第十四篇:挑战SQL:图解Pandas的数据合并merge
在实际的业务需求中,我们的数据可能存在于不同的库表中,SQL可以通过各种join来实现,Pandas中主要是通过merge函数来实现的。
在这篇文章中详细介绍了merge的各个参数如何使用:
pd.merge(left, # 待合并的2个数据框
right,
how='inner', # ‘left’, ‘right’, ‘outer’, ‘inner’, ‘cross’
on=None, # 连接的键,默认是相同的键
left_on=None, # 指定不同的连接字段:键不同,但是键的取值有相同的内容
right_on=None,
left_index=False, # 根据索引来连接
right_index=False,
sort=False, # 是否排序
suffixes=('_x', '_y'), # 改变后缀
copy=True,
indicator=False, # 显示字段来源
validate=None)



第十五篇:图解Pandas数据合并:concat、join、append
Pandas中除了常用的merge函数来实现数据合并,还有3个函数也能实现部分的合并功能:concat、join、append;尤其是concat,其实也挺常用的。
concat参数:
pandas.concat(objs, # 合并对象
axis=0, # 合并方向,默认是0纵轴方向
join='outer', # 合并取的是交集inner还是并集outer
ignore_index=False, # 合并之后索引是否重新
keys=None, # 在行索引的方向上带上原来数据的名字;主要是用于层次化索引,可以是任意的列表或者数组、元组数据或者列表数组
levels=None, # 指定用作层次化索引各级别上的索引,如果是设置了keys
names=None, # 行索引的名字,列表形式
verify_integrity=False, # 检查行索引是否重复;有则报错
sort=False, # 对非连接的轴进行排序
copy=True # 是否进行深拷贝
)
join参数:
dataframe.join(other, # 待合并的另一个数据框
on=None, # 连接的键
how='left', # 连接方式:‘left’, ‘right’, ‘outer’, ‘inner’ 默认是left
lsuffix='', # 左边(第一个)数据框相同键的后缀
rsuffix='', # 第二个数据框的键的后缀
sort=False) # 是否根据连接的键进行排序;默认False
append主要参数:
DataFrame.append(
other, # 追加对象
ignore_index=False, # 是否保留原索引
verify_integrity=False, # 检查行索引是否重复;有则报错
sort=False)
第十六篇:图解Pandas的轴旋转函数stack和unstack
stack和unstack也是一对互为逆操作的函数,它们二者的作用的是对Pandas的数据轴进行旋转,二者特点为:
- stack: 将数据的列columns转旋转成行index
- unstack:将数据的行index旋转成列columns
- 二者默认操作的都是最内层
来自官网的两张图来解释二者的用法:


文章有什么特色
在写作的过程中,参考了官网和很多资料,也有自己平时使用的一些心得,同时也模拟了很多数据,总结下几个特色:
- 案例丰富:每篇文章都是通过模拟来进行说明
- 图文并茂:文章使用了大量的图形来解释函数的使用,更加直观,加深印象
- 贴近现实:很多模拟数据都是可以直接套用在真实的业务场景中
后续工作
目前写的内容真的仅仅是Pandas库的冰山一角,还有很多的内容没有展开。但是如果读者能够认真看完,并且自己实际去运行和理解代码,相信还是会有很大的收获,入门pandas必定是问(听)题(你)不(吹)大(牛)!
后续Pandas的文章会持续更新,这将是一个长期的过程。以后会带来更多高级使用技巧和案例,帮助读者掌握Pandas的使用。
领取方式:关注公众号[尤而小屋],回复Pandas即可领取