在自定义数据集上训练YOLOX

随着下一款模型:YOLOX的推出,YOLO系列将继续发展壮大。在这篇文章中,我们将介绍如何训练YOLOX识别自定义用例的对象检测数据。
在本教程中,我们使用公共血细胞对象检测数据集。但是,你可以将自己的数据导入Roboflow并将其导出,以训练此模型以满足你自己的需要。本教程使用的YOLOX笔记本可在此处下载。
https://colab.research.google.com/drive/1_xkARB35307P0-BTnqMy0flmYrfoYi5T#scrollTo=igwruhYxE_a7
感谢Megvii团队发布了基础库,这为我们的笔记本奠定了基础。
在本教程中,我们采取以下步骤:
安装YOLOX依赖项
通过Roboflow下载自定义YOLOX对象检测数据
下载YOLOX的预训练权重
运行训练
评估YOLOX性能
在测试图像上运行YOLOX推断
导出保存的YOLOX权重以供推断
YouTube视频:
https://youtu.be/q3RbFbaQQGw
YOLOX有什么新功能?
YOLOX是YOLO的最新版本,在速度和准确性方面突破了极限。YOLOX最近赢得了流媒体感知挑战赛(CVPR 2021自动驾驶研讨会)。
相对于其他YOLO检测网络的YOLOX评估:

最大的变化包括移除盒锚(提高模型到边缘设备的可移植性)和将YOLO检测头解耦到单独的特征通道中,用于盒分类和盒回归(提高训练收敛时间和模型精度)。
YOLOX中的解耦头:

在YOLOX中,训练时间加快。但我们认为YOLOv5更快(我们还没有进行任何直接的正面测试)
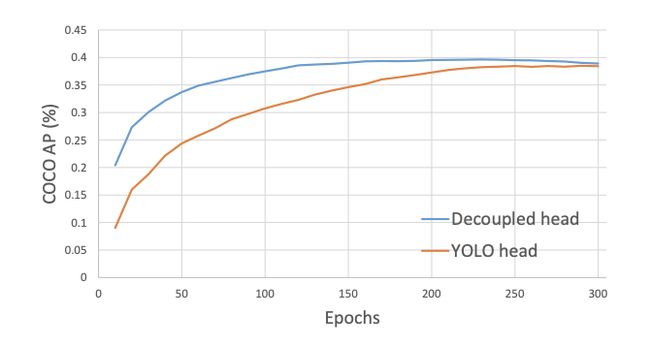
你可以在YOLOX论文或本视频中深入了解。
https://youtu.be/n1-bzMQeMgI
安装YOLOX依赖项
为了设置我们的开发环境,我们将首先克隆基本YOLOX存储库并下载必要的依赖:
!git clone https://github.com/roboflow-ai/YOLOX.git %cd YOLOX !pip3 install -U pip && pip3 install -r requirements.txt !pip3 install -v -e . !pip uninstall -y torch torchvision torchaudio # May need to change in the future if Colab no longer uses CUDA 11.0 !pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html我们还将安装NVIDIA Apex和PyCocoTools,以使该存储库按预期工作:
%cd /content/ !git clone https://github.com/NVIDIA/apex %cd apex !pip install -v --disable-pip-version-check --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./ !pip3 install cython; pip3 install 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'下载自定义YOLOX对象检测数据
在我们开始之前,你需要创建一个Roboflow帐户。我们将使用血细胞数据集,但欢迎你使用任何数据集,无论是加载到Roboflow中的你自己的数据集还是其他公共数据集。
对于本笔记本,我们需要应用一些预处理步骤,以确保数据与YOLOX一起工作。若要开始,请创建一个Roboflow帐户(如果尚未创建),然后分叉数据集:
分叉数据集后,你需要添加一个预处理步骤,将所有图像的大小调整为640 x 640:

然后简单地生成数据集的新版本,并使用“Pascal VOC”导出。你将收到一个Jupyter notebook命令,该命令如下所示:

复制命令,并用Roboflow提供的命令替换笔记本中的以下行:
!curl -L "[YOUR LINK HERE]" > roboflow.zip; unzip roboflow.zip; rm roboflow.zip标记数据
如果你带着自己的数据集,你可以在Roboflow中为图像添加注释。
下载YOLOX的预训练权重
YOLOX附带了一些预训练权重,以允许模型更快地训练并获得更高的精度。权重大小有很多种,但我们使用的权重大小将基于小型YOLOX模型(YOLOX_S)。下载如下:
%cd /content/ !wget https://github.com/Megvii-BaseDetection/storage/releases/download/0.0.1/yolox_s.pth %cd /content/YOLOX/YOLOX训练
要训练模型,我们可以运行tools/train.py文件:
!python tools/train.py -f exps/example/yolox_voc/yolox_voc_s.py -d 1 -b 16 --fp16 -o -c /content/yolox_s.pth运行此命令的参数包括:
经验文件:该文件允许我们更改基础模型的某些方面,以便在训练时应用
设备:我们的模型将使用1,由Colab提供
批次大小:每个批次中的图像数
预训练权重:指定要使用的权重的路径-可以是我们下载的权重,也可以是模型的早期检查点
经过大约90个epoch的训练,我们获得了以下AP。

评估YOLOX性能
要评估YOLOX性能,我们可以使用以下命令:
MODEL_PATH = "/content/YOLOX/YOLOX_outputs/yolox_voc_s/latest_ckpt.pth.tar" !python3 tools/eval.py -n yolox-s -c {MODEL_PATH} -b 64 -d 1 --conf 0.001 -f exps/example/yolox_voc/yolox_voc_s.py运行评估后,我们得到以下结果:
YOLOX模型的评价

性能看起来不错!
在测试图像上运行YOLOX推断
我们现在可以在测试图像上运行YOLOX,并将预测可视化。要在测试映像上运行YOLOX,请执行以下操作:
TEST_IMAGE_PATH = "/content/valid/BloodImage_00057_jpg.rf.1ee93e9ec4d76cfaddaa7df70456c376.jpg" !python tools/demo.py image -f /content/YOLOX/exps/example/yolox_voc/yolox_voc_s.py -c {MODEL_PATH} --path {TEST_IMAGE_PATH} --conf 0.25 --nms 0.45 --tsize 640 --save_result --device gpu要在图像上可视化预测,请执行以下操作:
from PIL import Image OUTPUT_IMAGE_PATH = "/content/YOLOX/YOLOX_outputs/yolox_voc_s/vis_res/2021_07_31_00_31_01/BloodImage_00057_jpg.rf.1ee93e9ec4d76cfaddaa7df70456c376.jpg" Image.open(OUTPUT_IMAGE_PATH)
看起来该模型可以按预期工作!
导出保存的YOLOX权重以供将来推断
最后,我们可以将模型导出到我们的Google Drive中,如下所示:
from google.colab import drive drive.mount('/content/gdrive') %cp {MODEL_PATH} /content/gdrive/My\ Drive结论
YOLOX是一种功能强大、最先进的目标检测模型。在本教程中,你可以学习如何:
准备YOLOX环境
使用Roboflow下载自定义对象检测数据
运行YOLOX训练流程
使用经过训练的YOLOX模型进行推理
将你的模型导出到Google Drive
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓
