CER--《A Deeper Look at Experience Replay》阅读笔记
CER–《A Deeper Look at Experience Replay》阅读笔记
文章目录
- CER--《A Deeper Look at Experience Replay》阅读笔记
-
- 前言:
- 参考链接:
- 一. 论文简介
-
- 1. 作者:
- 2. 期刊杂志:
- 3. 引用数:
- 4. 论文背景,领域
- 和PER相比
- 一句话描述研究背景:
- 实验分析:
-
- 格子世界-表格表征-效果拔群
- 格子世界-线性表征-效果不错
- 格子世界-非线性-效果有些提升
- 月球降落--非线性--效果不明显
- 乒乓球--非线性--效果略有下降
- 我的测试:
- 总结:
前言:
ps: 欢迎做强化的同学加群一起学习:
深度强化学习-DRL:799378128
最近一直沉迷强化里的经验回放,不知道在哪儿看到了,这个CER(combined experience replay)和PER并称。
内容不好评价,导致拖的太久了。
总体评价,技术思路非常简单,在随机采样的数据中,加一个当前transition(s,a,r,s_,d),一起训练,兼顾随机采样和当前有价值数据。
但是效果不是很好。
– 更新
我昨天晚上又看了一次。
因为对色彩不是特别敏感,对这几条线有点分不太清,导致只能不断放大,一条线一条线的标。
对比实验看完之后,发现,果然是现象模糊,性能诡异。
参考链接:
论文链接
一. 论文简介
1. 作者:
别的不说,作者咖位太大了。
就两位,一作是Shangtong Zhang,一位是Richard S. Sutton。
2. 期刊杂志:
NIPS 2017 Deep Reinforcement Learning Symposium。
3. 引用数:
92
4. 论文背景,领域
经验回放领域,讨论的人不多,下一次阅读20年,谷歌做的一篇文章。讨论的是经验回放率和数据新旧度。
和PER相比
是PER的极端情况,PER也是对最近的数据加了一个比较高的权重,但是呢,这并不能保证最新的数据一定会被立刻采集到。
其次PER的时间复杂度是 O ( n ) O(n) O(n)
而CER只是 O ( 1 ) O(1) O(1)
因此他们还是提出了CER的方法:

一句话描述研究背景:
作者的立论:
如果经验池过小,那么无法保证数据的独立同分布;
如果经验池过大,那么最新的数据(属于有价值的信息),无法被快速学习,导致学习速率下降。
因此要把最新的数据放到batch中。
那么接下来就要看,经验池的大小,是不是会有最小不行,最大也不行的问题。而加了cer的大池子仍然能保证稳定效果。
实验分析:
为了验证这个效果,作者实验了
三个任务-格子世界,月球登录,乒乓球;
三种模型——表格、线性、非线性;
三种算法——online-Q,buffer-Q, combined-Q。

格子世界-表格表征-效果拔群
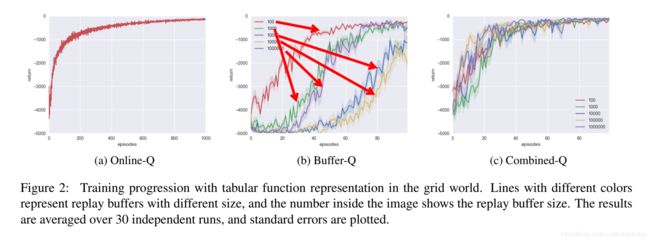
任务:格子世界;
表征方式:表格;
不同buffer-size性能对比:
在Buffer-Q中 1 0 2 > 1 0 3 > 1 0 6 > 1 0 4 > 1 0 5 10^{2}>10^{3}>10^{6}>10^{4}>10^{5} 102>103>106>104>105
除了这个10^6以外,大致可以看出,池子越大效果越差。
另外Online-Q学习都比Buffer-Q慢。
这表明Online-Q的数据利用率要差很多。
图c可以看出,用了cer之后,所有的都比较稳定了。
勉强可以说的过去。
看第二个实验:
格子世界-线性表征-效果不错
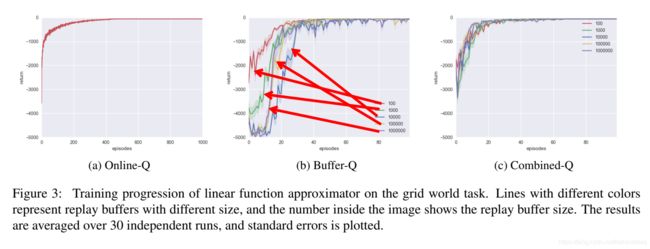
不同buffer-size性能对比:
在Buffer-Q中 1 0 2 > 1 0 3 > 1 0 5 ≈ 1 0 6 > 1 0 4 10^{2}>10^{3}>10^{5}≈10^{6}>10^{4} 102>103>105≈106>104
除了这个 1 0 5 10^5 105和 1 0 6 10^6 106以外,大致可以看出,池子越大效果越差(渐渐勉强)。
Online的效果和上面的一样;
图c加了CER的效果,也变得更快 更稳定。
格子世界-非线性-效果有些提升
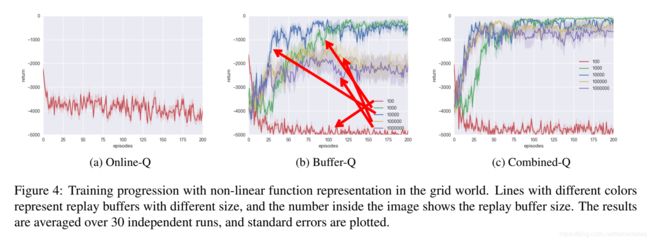
这里的结果就诡异了:
不同buffer-size性能对比:
在Buffer-Q中 1 0 4 > 1 0 3 > 1 0 5 > 1 0 6 > 1 0 2 10^{4}>10^{3}>10^{5}>10^{6}>10^{2} 104>103>105>106>102
文中单说56学不到最佳策略,我认了,那我看看加了CER的怎么样。
Online的效果很差,也没有和上面的实验一样的训练时间,只是训练了200个回合,没什么好说的;
图c加了CER的效果,56确实增加了速度也提高了性能!nice!除了10^2,可能这个本身池子太小,没必要。
月球降落–非线性–效果不明显

不同buffer-size性能对比:
在Buffer-Q中 1 0 3 > 1 0 2 > 1 0 4 > 1 0 6 > 1 0 5 10^{3}>10^{2}>10^{4}>10^{6}>10^{5} 103>102>104>106>105
大概的趋势324>56,应该这么看?
Online的效果最好,所以认为这个任务需要最新的数据?
最后看图c加了CER的效果,效果基本不变…
乒乓球–非线性–效果略有下降
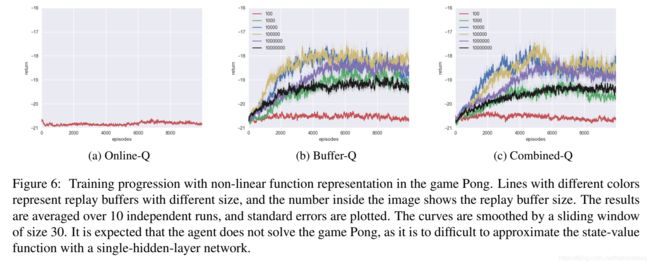
不同buffer-size性能对比:
在Buffer-Q中 1 0 5 > 1 0 4 > 1 0 6 > 1 0 3 > 1 0 7 > 1 0 2 10^{5}>10^{4}>10^{6}>10^{3}>10^{7}>10^{2} 105>104>106>103>107>102
我实在是不知道怎么描述了。
把原文贴上来吧:
Figure 6 shows the learning progression of the agents with various replay buffer sizes in the game Pong. We observed similar phenomena as the grid world task. However in this task CER does not provides much improvement.
Online的效果也不太好。
最后看图c加了CER的效果,效果甚至略有下降?
我的测试:
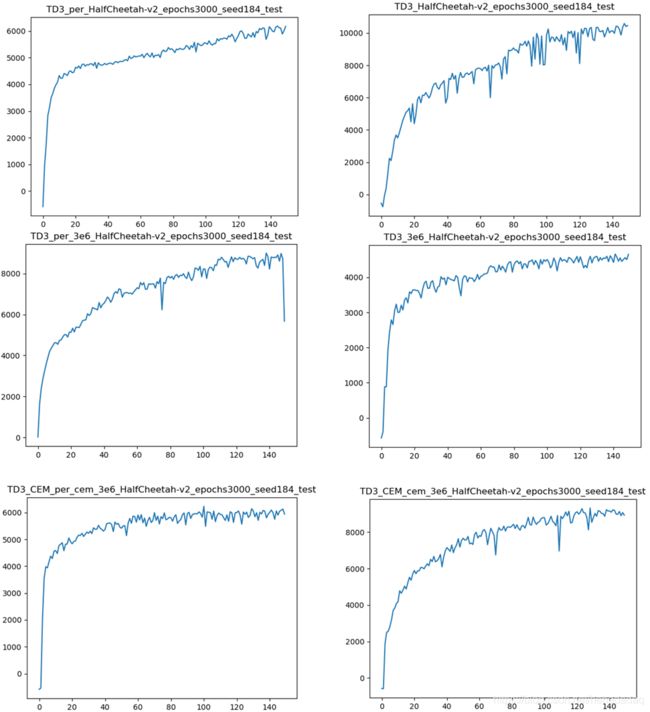
上图第一行为标准buffer-size:1e6,左边为加了优先经验回放,右边为正常的均匀采样。
第二行为大buffer-size:3e6,即在训练的过程中,size一直会填不满。
第三行为加了CER的大size。
由于计算资源有限,我只跑了一组随机种子。假设这个就能代表该算法的平均值,在此基础上,做的结果分析:
整张图划分为1a(per), 1b(normal), 2a, 2b, 3a,3b.
1b和2b看出来,均匀采样,size加大,性能下降,说明size增大,确实会降低性能?
2b和3b可以看出,加了cer之后,性能又上去了!简直不要太符合cer作者的要求好吧!!!
而且在per这边实验,也能说明一些问题。
1a和2a可以说明什么,随着size的增加,性能增加了,那么证明per也能处理好size过大带来的损害!
再看3a性能又下降了,那么说明cer和per有冲突,这个结果可以不放上去~
总结:
根据上面的结果可以看到,在这次实验中,格子世界的环境,是非常适合CER这个算法。
但是随着任务的切换(可能是提高了任务的难度),或者是非线性表征的原因,连大池子的损害都难以观察到,CER的作用也渐渐消失,这实在是太难受了。
为了凑齐三个任务适合,太难了,我的这篇文章也是卡在了这个环节。
作者在文章最后也是很无奈,提到了这样一句话:
However it is important to note that CER is only a workaround, the idea of experience replay itself is heavily flawed.
他说经验回放本身就有缺陷,但是目前只能说在格子世界这样简单的任务中,经验池才有会如此明显的差别。可能这个环境+算法+经验池不适合。并不是经验池不合适。
就好像之前看到一篇18年的文章,里面单actor网络,性能比actor-critic结构的DDPG都要好。所以得出了一个结论,单actor的性能就是比actor-critic的好。
这其实就有点问题,因为那时候稳定高效版本的TD3和SAC还没提出来,所以这个推论就有点局限性。
太不容易了~