18. 图像分类、分割
文章目录
- 模型是如何将图像分类的?
- resnet18模型inference(推理)代码
- resnet18结构分析
-
- 图像分类经典模型
- resnet18结构分析
- 图像分割是什么?
- 模型是如何将图像分割的?
-
- PyTorch-Hub
- 图像分割的思考
- 深度学习图像分割模型简介
-
- FCN
- Unet
- DeepLab系列——V1
- DeepLab系列——V2
- DeepLab系列——V3
- DeepLab系列——V3+
- 综述
- 训练Unet完成人像抠图(Portrait Matting)
本课程来自深度之眼deepshare.net,部分截图来自课程视频。
模型是如何将图像分类的?

3-d张量>字符串过程(倒序来看)
1.类别名与标签的转换labelname={“ants”:0,“bees”:1}
2.取输出向量最大值的标号,predicted=torch.max(outputs.data,1)
3.复杂运算outptus=resnet18(img_tensor)#img_tensor就是3-d张量
模型实际上就是把3-d张量映射到一个向量。
模型如何完成图像分类?
答:图像分类由模型与人类配合完成
模型:将数据映射到特征

这里的模型是指nn.Module,不是广义上的模型。
人类:定义特征的物理意义,解决实际问题

resnet18模型inference(推理)代码
步骤:
1.获取数据与标签
2.选择模型,损失函数,优化器
3.写训练代码
4.写inference代码
Inference代码基本步骤:
1.获取数据与模型
2.数据变换,如RGB>4D-Tensor
3.前向传播
4.输出保存预测结果
代码注意事项:
1.inference的时候,模型要执行eval()状态而非training
2.使用torch.no_grad(),所有的运算不计算梯度,可以大大节省内存,提高运算速度。
3.数据预处理需保持一致,RGB or BGR?
模型将数据从图片转换到向量的代码可以分为如下几个步骤:
# step1/4: path-->img,读取图片,转换为PIL形式
img_rgb=Image.open(path_img).convert('RGB')
# step 2/4: img-->tensor,转换为tensor
img_tensor=img_transform(img_rgb, inference_transform)
img_tensor.unsqueeze_(0)
img_tensor=img_tensor.to(device)#这里注意tensor的to函数要用赋值语句,因为它不是inplace的
# step3/4: tensor-->vector
time_tic=time.time()
outputs=resnet18(img_tensor)
time_toc=time.time()
# step 4/4: visualization向量映射到具体的分类
_, pred_int=torch.max(outputs.data,1)
pred_str=classes[int(pred_int)]
resnet18结构分析
图像分类经典模型
最下面那个是vgg

上面画圈的属于经典的CNN模型,可以看做是一组
mobilenet.py、shufflenetv2.py、squeezenet.py这三个属于轻量化的CNN模型,可以看做一组
mnasnet.py是一种使用强化学习设计移动端模型的自动化神经架构搜索方法,最近很火,貌似最近出了第二版。
resnet18结构分析
论文:He K, Zhang X, Ren S, et al. Deep Residual Learning for Image Recognition
恒等映射,下面是resnet的一个block的图

模型的输入通常是224224的,经过conv1的时候,采用的stride=2,所以conv1的输出大小是112112,然后经过一个max pooling操作,该操作的stride也是2,所以得到的是5656的输出
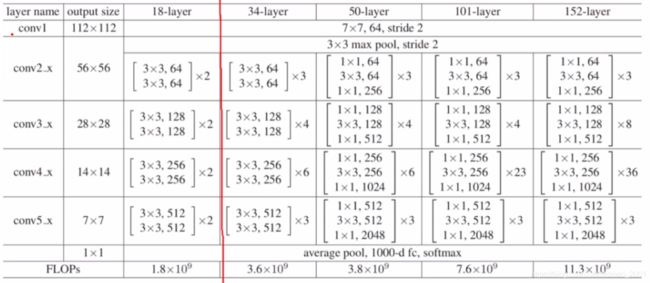
然后进入conv2_x(在pytorch中可以看做一个layer,编号为1,即layer1,下面的分别看做是layer2…)
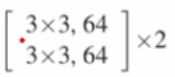
这里可以看到,卷积核大小是33,卷积核个数是64个。然后的2是代表2个block的堆叠。每个block的结构和上面的结构图一样,每个block都有两个卷积层,两个BN,两个relu。
在进入conv3_x(layer2)前,模型将特征图的size进行了减半,5656变成了2828.
依次类推,最后经过average pool,1000-d fc,softmax
resnet18中的18是根据带参数的层来命名的,conv1是1,然后中间的 是2层,然后2就有四层,
是2层,然后2就有四层,
layer1~ 4就是44共16层,然后加最后的fc,一共是18,所以叫resnet18.
同理resnet34咋出来的?1+32+42+62+3*2+1=34,以此类推
当然,后面的 部分就不叫block了,ng的课里面有讲,前后小,中间大,是叫bottleneck。
部分就不叫block了,ng的课里面有讲,前后小,中间大,是叫bottleneck。
下面是resnet中初始化resnet18和resnet34的代码
return _resnet('resnet34',BasicBlock,[2,2,2,2],pretrained,progress,**kwargs)
return _resnet('resnet34',BasicBlock,[3,4,6,3],pretrained,progress,**kwargs)
注意看里面的[2,2,2,2]和[3,4,6,3]对应的是模型结构分析中的竖下来的数字。
resnet50的代码
return _resnet('resnetse',Bottleneck,[3,4,6,3],pretrained,progress,**kwargs)
注意看是Bottleneck,不是BasicBlock。
下面看BasicBlock的forward代码对应的结构是不是一致(两个卷积层,两个BN,两个relu)
def forward(self,x):
identity=x
out=self.conv1(x) #第一个卷积
out=self.bn1(out)#第一个BN
out=self.relu(out)#第一个relu
out=self.conv2(out)#第二个卷积
out=self.bn2(out)#第二个bn
if self.downsample is not None:
identity=self.downsample(x)
out+=identity #第二个relu前先加原始输入(identity),进行残差
out=self.relu(out)#第二个relu
return out
用torchsummary查看resnet18的具体结构。

接上图:
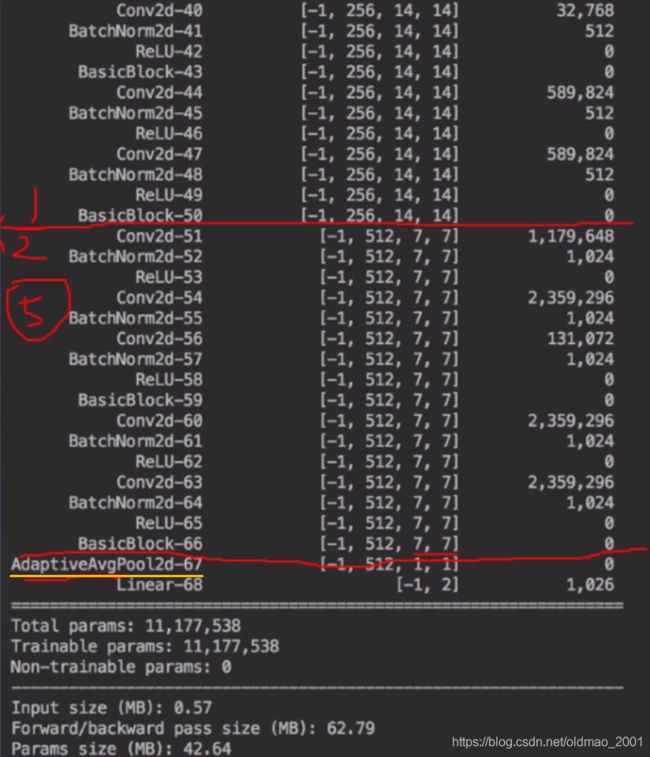
这里说一下,自适应池化操作,就是上面黄线部分,无论输入的维度是多少,输出的维度大小是1*1的,以便于接后面的linear层。
图像分割是什么?
图像分割:将图像每一个像素分类
黑色为背景,蓝色是猫咪

图像分割分类:
1.超像素分割:少量超像素代替大量像素,常用于图像预处理
2.语义分割:逐像素分类,无法区分个体,相同类别是一个颜色,例如人是一类,但是没有办法区分每一个人。
3.实例分割:对个体目标进行分割,像素级目标检测
4.全景分割:语义分割结合实例分割

模型是如何将图像分割的?
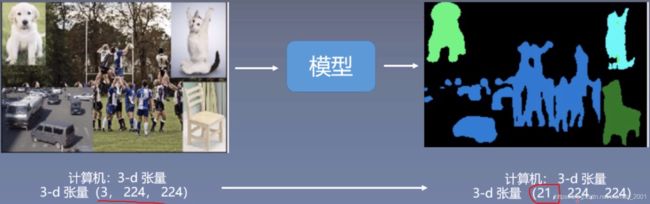
可以看到,分割后图像大小不变,21是代表要预测的类别数量。


狗头猫身识别为狗。
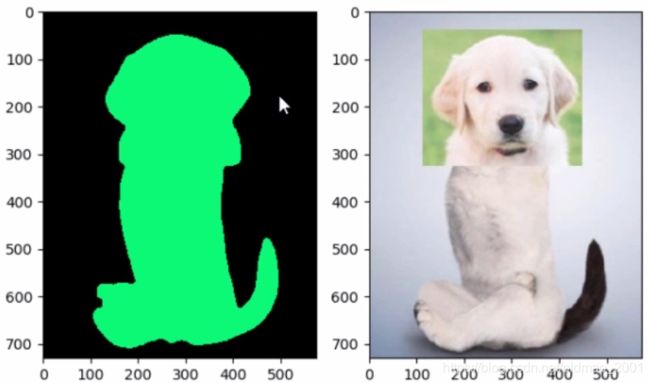
模型如何完成图像分割?
答:图像分割由模型与人类配合完成
模型:将数映射到特征
人类:定义特征的物理意义,解决实际问题
结合之前的图像分类来看,图像分割也是分类的一种,只不过是把图片上的每个像素做一个分类。


PyTorch-Hub
PyTorch-Hub—-PyTorch模型库,有大量模型供开发者调用,下面是Hub常用的三个函数。
1.torch.hub.load(“pytorch/vision”,‘deeplabv3_resnet101’,pretrained=True)
model=torch.hub.load(github,model,*args,**kwargs)
功能:加载模型
主要参数:
·github:str,项目名,eg:pytorch/vision,
·model:str,模型名
2.torch.hub.list(github,force_reload=False)列出当前github项目下有什么模型供我们调用。
3.torch.hub.help(github,model,force_reload=False)列出模型的参数
更多参见:https://pytorch.org/hub
图像分割的思考


上面例子中的图例颜色含义为:蓝色为小猫,绿色为小狗
可以看出,模型进行图像分割的依据主要是小动物的头部。
深度学习图像分割模型简介
FCN
文献:Fully Convolutional Networks for Semantic Segmentation
最主要贡献:
利用全卷积完成pixelwise prediction

Unet
最主要贡献:
奠定Unet系列分割模型的基本结构——编码器与解码器的特征融合
网友对Unet及改进做了合集:https://github.com/shawnbit/unet-family
文献:《U-Net:Convolutional Networks for Biomedical Image Segmentation》
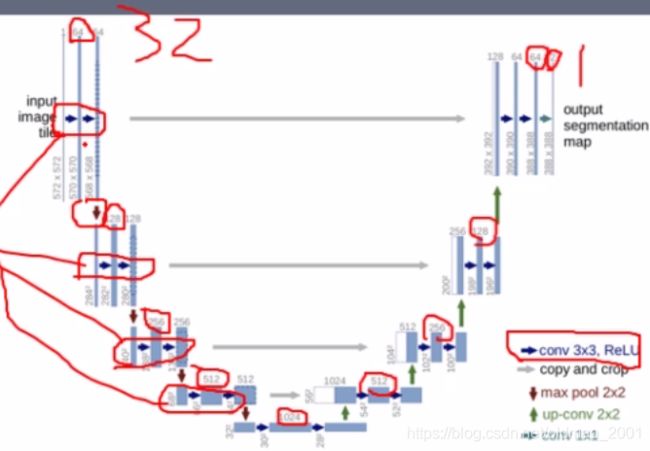
这个模型是针对医学图像分类用的,其特点是可以针对医学图像数据量较少的特点进行训练,由于模型(如下图)像一个U型,所以叫Unet,中中间分开,左右两边分别就是编码器与解码器

注意看上面的模型,输入shape是:572572,1个channel(灰度图,只有一个channel),输出是388388,2个channel(只做了2分类所以只有2个channel),为什么输入和输出不一样大呢,因为最早Unet是用来做细胞分割的,如下图所示:

其中,蓝色框是输入,黄色框是输出。注意看左图中,对黄框的边界一圈是做了镜像的padding。同时这个模型也说明了,做图像分割,输入和输出是可以不一样大的。
DeepLab系列——V1
DeepLab系列现在有4个:V1/V2/V3/V3+。这里看V1
主要特点:
1.孔洞卷积:借助孔洞卷积,增大感受野
2.CRF:采用CRF进行mask后处理
文献:《DeepLabv1 Semantic image segmentation with deep convolutional nets and fully connected CRFs》

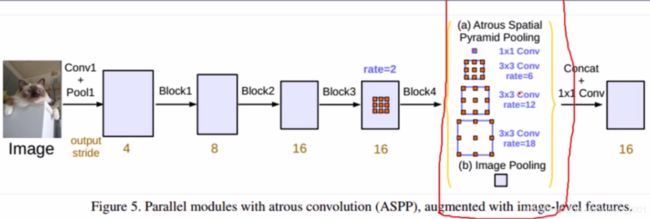
DeepLab系列——V2
主要特点:
ASPP(Atrous spatial pyramid pooling):解决多尺度问题
文献:DeepLab-Semantic Image Segmentation with Deep Convolutional Nets,Atrous Convolution,and Fully Connected CRFs
从图中可以看到,对于一个输入,采用了不同尺度(金字塔pyramid )的池化,4个池化的kernel都是3*3的,但是每个池化的感受野完全不同。注意看下面的颜色和上面的颜色是一一对应的。

DeepLab系列——V3
主要特点:
1.孔洞卷积的串行
2.ASPP的并行
以上两个特点相当于对V1和V2两个模型中的特点进行了改进。
文献:DeepLabv3-Rethinking Atrous Convolution for Semantic Image Segmentation
下面是四种方法,第一个是图像金字塔;第二个是Unet;第三个是DeepLabV1的空洞卷积,第四个是DeepLabV2的金字塔池化。DeepLabV3就是针对第三个和第四个进行的优化。

下面的图片的下半部分是孔洞卷积的串行示意图(画圈圈的那里),上半部分是传统的卷积,可以看出空洞卷积保持了输出的分辨率。

下面是ASPP的并行示意图,并行结果concat起来,然后经过1*1的卷积操作得到结果。
DeepLab系列——V3+
主要特点:deeplabv3基础上加上Encoder-Decoder思想
文献:《DeepLabv3-Rethinking Atrous Convolution for Semantic Image Segmentation》
模型结构如下图,上下分别是编码和解码器。解码器中的DCNN是V1中的空洞卷积,然后接V3中的并行ASPP,可以看到使用了不同rate的特征(注意颜色)得到结果后concat起来,经过11的卷积,得到一个输出的特征图(编码)。
解码器中将上面得到的绿色的东西(就是编码特征图,编码器得出的结果就叫这个)先进行4倍的上采样。然后和前面的结果进行concat,然后经过33的卷积,再进行4倍的上采样,得到最后的Prediction。

综述
综述文献:Deep Semantic Segmentation of Natural and Medical Images: A Review. 2019

github图像分割资源:
https://github.com/shawnbit/unet-family
https://github.com/yassouali/pytorch_segmentation
训练Unet完成人像抠图(Portrait Matting)
数据来源:https://github.com/PetroWu/AutoPortraitMatting


可以看到输入是三通道的rgb,输出是2通道的图片(或者说是1通道的mask,就是<0.5是背景,>0.5是人。)
代码中与原始Unet不一样的是,构建模型时,初始化特征数为32,原始模型是64(可以看上面的Unet的模型图),后面每一层的特征数都是以这个初始化特征数为基准进行计算的。
# step 2
net = UNet(in_channels=3, out_channels=1, init_features=32) # init_features is 64 in stander uent
用1通道的3d张量来进行图像分割代码,在可视化步骤中写:
mask_pred = outputs.ge(0.5).cpu().data.numpy().astype("uint8")#0.5是阈值
模型结构,具体代码看unet.py文件中的forward函数,这里只给图: