使用深度学习模型U-Net进行训练基于哨兵2的作物分割数据集。PyTorch框架为例,如何构建和训练U-Net模型来完成基于哨兵2的作物分割检测
使用深度学习模型如U-Net进行训练基于哨兵2的作物分割。PyTorch框架为例,如何构建和训练U-Net模型来完成基于哨兵2的作物分割检测
基于哨兵2的作物分割,共18种作物类型(背景,草地,软冬小麦,玉米,冬季大麦,冬季油菜,春季大麦,向日葵,葡萄藤,甜菜,冬季小黑麦,冬季硬质小麦,水果、蔬菜、花卉,土豆,豆科饲料,大豆,果园,混合谷物,高粱),38到61个不同时间段同一位置10通道多光谱图像,2433张图像,128×128尺寸(38×10×128×128的矩阵存储)分辨率为10m,29GB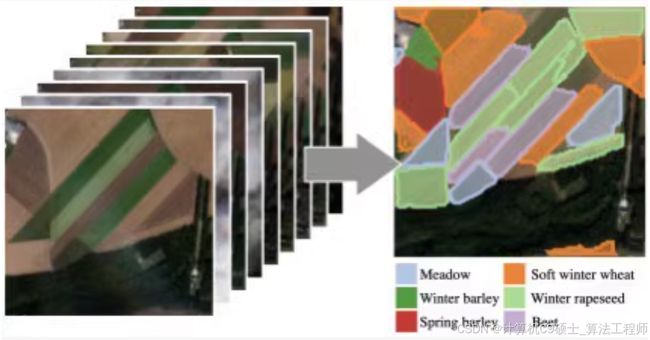
针对基于哨兵2号(Sentinel-2)多光谱图像的作物类型分割任务,因为数据集的特性(18种作物类型、38到61个不同时间段同一位置的10通道多光谱图像),使用深度学习模型如U-Net或DeepLab等进行训练。PyTorch框架为例,展示如何构建和训练一个U-Net模型来完成这个任务。

数据准备
首先需要定义一个自定义的数据集类来加载和预处理你的数据:
import torch
from torch.utils.data import Dataset, DataLoader
import numpy as np
from torchvision import transforms
class CropSegmentationDataset(Dataset):
def __init__(self, data_path, transform=None):
self.data = np.load(data_path) # 假设数据是以.npy格式存储
self.transform = transform
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
sample = self.data[idx]
image = sample['image'] # 获取图像部分
mask = sample['mask'] # 获取标签部分
if self.transform:
image = self.transform(image)
return image, mask
# 数据转换
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.5]*10, std=[0.5]*10), # 根据实际情况调整
])
dataset = CropSegmentationDataset('path_to_your_data.npy', transform=transform)
dataloader = DataLoader(dataset, batch_size=8, shuffle=True)
模型定义
接下来定义U-Net模型结构:
import torch.nn as nn
import torch.nn.functional as F
class UNet(nn.Module):
def __init__(self):
super(UNet, self).__init__()
# 定义U-Net各层
# 这里简化了U-Net的实现,实际应用中可以根据需求调整网络深度和每层的具体参数
self.enc1 = self.conv_block(10, 64)
self.enc2 = self.conv_block(64, 128)
self.enc3 = self.conv_block(128, 256)
self.enc4 = self.conv_block(256, 512)
self.pool = nn.MaxPool2d(2)
self.upconv3 = nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2)
self.dec3 = self.conv_block(512, 256)
self.upconv2 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2)
self.dec2 = self.conv_block(256, 128)
self.upconv1 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)
self.dec1 = self.conv_block(128, 64)
self.out_conv = nn.Conv2d(64, 18, kernel_size=1) # 输出层,假设18类作物
def conv_block(self, in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True)
)
def forward(self, x):
enc1 = self.enc1(x)
enc2 = self.enc2(self.pool(enc1))
enc3 = self.enc3(self.pool(enc2))
enc4 = self.enc4(self.pool(enc3))
dec3 = self.upconv3(enc4)
dec3 = torch.cat((dec3, enc3), dim=1)
dec3 = self.dec3(dec3)
dec2 = self.upconv2(dec3)
dec2 = torch.cat((dec2, enc2), dim=1)
dec2 = self.dec2(dec2)
dec1 = self.upconv1(dec2)
dec1 = torch.cat((dec1, enc1), dim=1)
dec1 = self.dec1(dec1)
return self.out_conv(dec1)
训练流程
定义训练循环:
model = UNet()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for images, masks in dataloader:
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, masks)
loss.backward()
optimizer.step()
running_loss += loss.item() * images.size(0)
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {running_loss/len(dataloader.dataset)}")
模型优化
可以考虑使用学习率调度器和早停策略来优化模型性能:
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', patience=5)
early_stopping = EarlyStopping(patience=10, verbose=True) # 需要自己实现EarlyStopping类
for epoch in range(num_epochs):
# ... 训练过程 ...
scheduler.step(val_loss) # 使用验证集损失调整学习率
early_stopping(val_loss, model)
if early_stopping.early_stop:
print("Early stopping")
break
推理及可视化
推理并可视化结果:
import matplotlib.pyplot as plt
def visualize_predictions(model, dataloader, num_images=5):
model.eval()
with torch.no_grad():
for i, (images, masks) in enumerate(dataloader):
if i >= num_images:
break
outputs = model(images)
_, preds = torch.max(outputs, 1)
fig, axarr = plt.subplots(1, 3)
axarr[0].imshow(images[0].permute(1, 2, 0).numpy()) # 显示原始图像
axarr[1].imshow(masks[0].numpy()) # 显示真实标签
axarr[2].imshow(preds[0].numpy()) # 显示预测结果
plt.show()
visualize_predictions(model, dataloader)
以上步骤提供了一个基本框架,从数据准备、模型定义、训练、优化到推理及可视化的全过程。请根据实际情况调整代码中的细节,比如数据路径、超参数设置等。