pytorch-cuda和cudnn安装过程、pycharm用anaconda自带python库设置;pytorch gpu训练案例
cuda、cudnn安装设置
** cuda是gpu 使用的底层语言;cudnn相当于是cuda的上层封装的深度学习框架
1、[Scrapy安装]error:Microsoft Visual C++ 14.0问题
(37是表示python版本)
1. 下载Twisted适配当前系统版本的.whl文件
下载传送门:https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
2. 安装所下载的.whl文件
在下载的.whl文件的绝对路径下安装Twisted:
pip install D:\Tools007\Twisted-18.9.0-cp37-cp37m-win32.whl
2、pycharm用anaconda自带的python库设置
需要在pycharm的设置 project下的project interpreter选择python程序路径,这里选择acacnda下python.exe就行
3、cuda安装
可以先检查显卡版本,如果没有下载驱动可以先去下载安装驱动,正常都是安好了的新电脑
然后就是去官网一步步下载安装了
WIN10安装CUDA10
CUDA Toolkit 10.0 Download:https://developer.nvidia.com/cuda-downloads

最终“下一步”,然后“完成”就行。
配置系统环境变量,选择path:
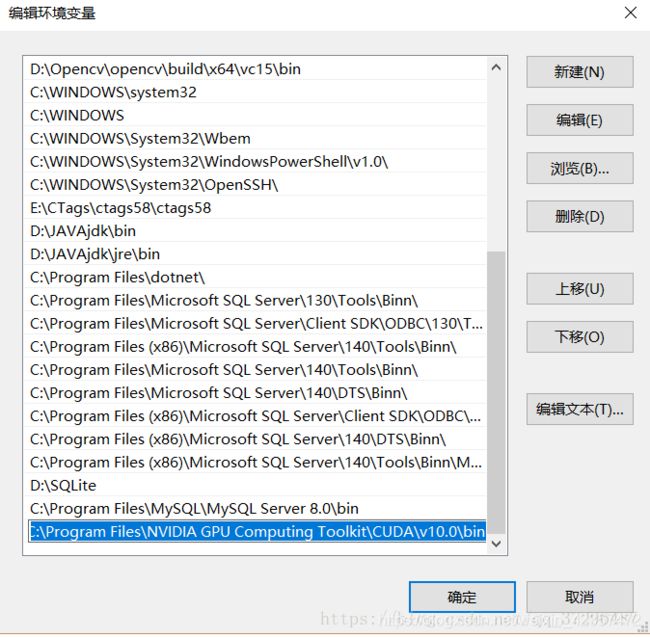
检查是否有下图中的两个环境变量

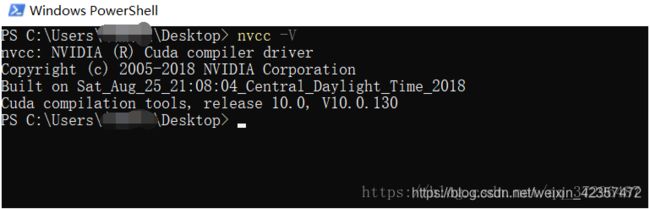
验证安装:nvcc -V
4、cudnn安装
cuDNN(CUDA Deep Neural Network library):是NVIDIA打造的针对深度神经网络的加速库,是一个用于深层神经网络的GPU加速库。如果你要用GPU训练模型,cuDNN不是必须的,但是一般会采用这个加速库。
WIN10安装cuDNN
cuDNN Download:https://developer.nvidia.com/rdp/cudnn-download
(进入网页下载当然要注册账号,如果有就不用了)
下载后最重要的是需要把下载的文件夹对应文件拷贝一份到对应的cuda文件目录下

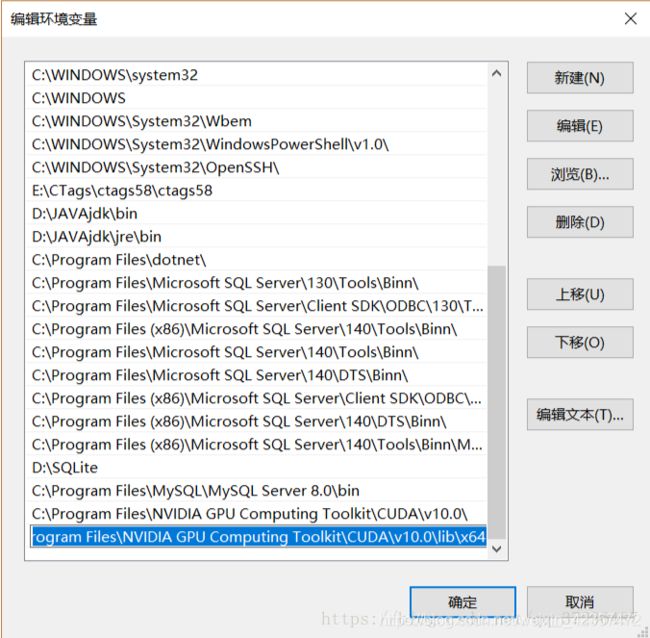
添加环境变量:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\lib\x64
5.安装pytorch和测试
pytorch官网选择对应cuda版本下载
pip3 install https://download.pytorch.org/whl/cu100/torch-1.0.1-cp37-cp37m-win_amd64.whl
pip3 install torchvision
返回为true就成功了
import torch
print(torch.cuda.is_available())
参考文章:https://blog.csdn.net/qq_37296487/article/details/83028394
pytorch gpu训练案例
***主要是数据,模型,损失加载到gpu
参考:
https://www.bilibili.com/video/BV1hE411t7RN
# -*- coding: utf-8 -*-
# 作者:小土堆
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
# from model import *
# 准备数据集
from torch import nn
from torch.utils.data import DataLoader
# 定义训练的设备
device = torch.device("cuda")
train_data = torchvision.datasets.CIFAR10(root="../data", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10, 训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
tudui = Tudui()
tudui = tudui.to(device)
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
# 优化器
# learning_rate = 0.01
# 1e-2=1 x (10)^(-2) = 1 /100 = 0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("../logs_train")
for i in range(epoch):
print("-------第 {} 轮训练开始-------".format(i+1))
# 训练步骤开始
tudui.train()
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{}, Loss: {}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
tudui.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(tudui, "tudui_{}.pth".format(i))
print("模型已保存")
writer.close()