爬虫从入门到入狱(1)——正则表达式
文章内容均出自《python爬虫开发》
文章目录
- 1.1正则表达式
- 1.2正则表达式的基本符号
-
- 1.2.1 点号 “ . ”
- 1.2.2 星号 “ * ”
- 1.2.3 点号+星号 “ .* ”
- 1.2.4 问号“ ? ”
- 1.2.5 点号+星号+问号“ .*?” (最常用)
- 1.2.6 小括号“()”
- 1.2.7 反斜杠 “ \ ”
- 1.2.8 数字 “ \d”
- 1.3 使用正则表达式
-
- 1.3.1 findall 方法
- 1.3.2 search 方法
- 1.3.3 compile 方法
- 1.4 正则表达式的提取技巧
-
- 1.4.1 先抓大后抓小:二次提取
- 1.4.2 括号里括号外
1.1正则表达式
正则表达式(Regular Expression)是一段字符串,它可以表示一段有规律的信息。Python自带一个正则表达式模块,通过这个模块可以查找、提取、替换一段有规律的信息。在一万个人里面找一个人很困难,但是在一万个人里面找一个非常“有特点”的人却很容易。假设有一个人,皮肤是绿色的,身高三米,那么即使这个人混在一万人中,其他人也能一眼找到他。这个“寻找”的过程,在正则表达式中叫作“匹配”。在程序开发中,要让计算机程序从一大段文本中找到需要的内容,就可以使用正则表达式来实现。使用正则表达式有如下步骤。
(1)寻找规律。
(2)使用正则符号表示规律。
(3)提取信息。
1.2正则表达式的基本符号
1.2.1 点号 “ . ”
一个点号可以代替除了换行符以外的任何一个字符,包括但不限于英文字母、数字、汉字、英文标点符号和中文标点符号。
1.2.2 星号 “ * ”
一个星号可以表示它前面的一个子表达式(普通字符、另一个或几个正则表达式符号)0次到无限次。

如上均可以:(星号表示的是前面的一个表达式)

1.2.3 点号+星号 “ .* ”
点号表示任意非换行符的字符,星号表示匹配它前面的字符0次或者任意多次。所以“.*”表示匹配一串任意长度的字符串任意次。

如上均可以:
它表示在“如”和“哈”中间出现“任意多个除了换行符以外的任意字符”。

1.2.4 问号“ ? ”
问号表示它前面的子表达式0次或者1次。注意,这里的问号是英文问号
如上均可以:![]()
1.2.5 点号+星号+问号“ .*?” (最常用)
结合后用法:

如上均可以:

注:“ .*?” 与“ .* ”的区别
.*?的意思就是匹配一个能满足要求的最短字符串。
一句话总结如下。
①“.*”:贪婪模式,获取最长的满足条件的字符串。
②“.*? ”:非贪婪模式,获取最短的能满足条件的字符串。
1.2.6 小括号“()”
从一段字符串中“提取”出一部分的内容.
有如下一个字符串:

可以看出,这里的密码左边有一个英文冒号,右边有一个汉字“你”。当构造一个正则表达式:.*?你时,得到的结果将会是:
![]()
然而,冒号和汉字“你”并不是密码的一部分,如果只想要“12345abcde”,就需要使用括号:
![]()
得到:
![]()
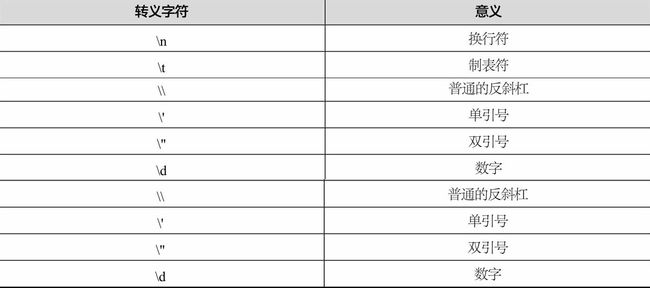
1.2.7 反斜杠 “ \ ”
在正则表达式里面,很多符号都是有特殊意义的,例如问号、星号、大括号、中括号和小括号。反斜杠需要和其他的字符配合使用来把特殊符号变成普通符号,把普通符号变成特殊符号。
1.2.8 数字 “ \d”
正则表达式里面使用“\d”来表示一位数字。
如果要提取两个数字,可以使用\d\d;如果要提取3个数字,可以使用\d\d\d。但是如果不知道这个数有多少位怎么办呢?就需要用*号来表示一个任意位数的数字。

全部都可以使用下面这个正则表达式来表示:

1.3 使用正则表达式
Python的正则表达式模块名字为“re”,也就是“regular expression”的首字母缩写。在Python中需要首先导入这个模块再进行使用。导入的语句为:
import re
1.3.1 findall 方法
Python的正则表达式模块包含一个findall方法,它能够以列表的形式返回所有满足要求的字符串。
findall的函数原型为:
re.findall(pattern,string,flags=0)
pattern表示正则表达式,string表示原来的字符串,flags表示一些特殊功能的标志。findall的结果是一个列表,包含了所有的匹配到的结果。如果没有匹配到结果,就会返回空列表。
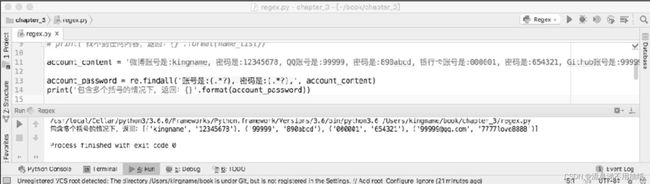
当需要提取某些内容的时候,使用小括号将这些内容括起来,这样才不会得到不相干的信息。如果包含多个“(.*? )”怎么返回呢?如图3-2所示,返回的仍然是一个列表,但是列表里面的元素变为了元组,元组里面的第1个元素是账号,第2个元素为密码。
函数原型中有一个flags参数。这个参数是可以省略的。当不省略的时候,具有一些辅助功能,例如忽略大小写、忽略换行符等。
这里以忽略换行符为例来进行说明要忽略换行符,就需要使用到“re.S”这个flag。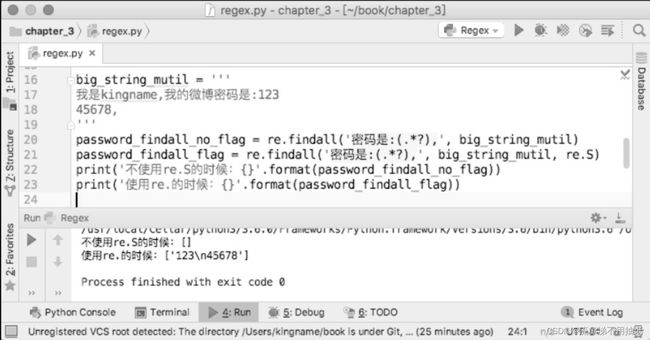
虽然说匹配到的结果中出现了“\n”这个符号,不过总比什么都得不到强。内容里面的换行符在后期清洗数据的时候把它替换掉即可。
1.3.2 search 方法
search()的用法和findall()的用法一样,但是search()只会返回第1个满足要求的字符串。一旦找到符合要求的内容,它就会停止查找。对于从超级大的文本里面只找第1个数据特别有用,可以大大提高程序的运行效率。
search()的函数原型为:
对于结果,如果匹配成功,则是一个正则表达式的对象;如果没有匹配到任何数据,就是None。
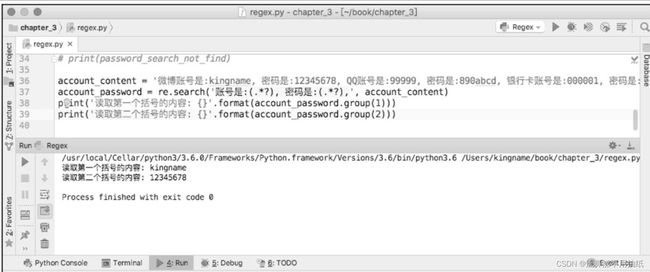
如果需要得到匹配到的结果,则需要通过.group()这个方法来获取里面的值。

只有在.group()里面的参数为1的时候,才会把正则表达式里面的括号中的结果打印出来。
.group()的参数最大不能超过正则表达式里面括号的个数。参数为1表示读取第1个括号中的内容,参数为2表示读取第2个括号中的内容,以此类推。
(注意图里的不是findall)
1.3.3 compile 方法
re.findall()自带re.compile()的功能,所以没有必要使用re.compile()。
1.4 正则表达式的提取技巧
1.4.1 先抓大后抓小:二次提取

1.4.2 括号里括号外
括号内可以有其他字符。
具体影响见下图。
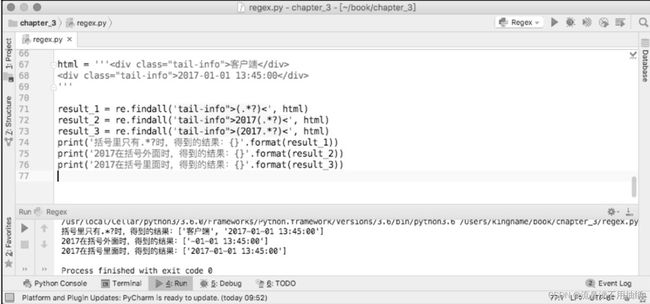
如果括号里面有其他普通字符,那么这些普通字符就会出现在获取的结果里面。