倒残差与线性瓶颈浅析 - MobileNetV2
文章目录
- 1 背景简介
- 2 MobileNetV2 要点
-
- 2.1 Inverted Residuals(倒残差结构)
- 2.2 Linear Bottlenecks(线性瓶颈结构)
- 3 代码实现 - pytorch
1 背景简介
提出 MobileNetV1 后,谷歌团队又于次年(2018 年)提出 MobileNetV2 网络。相较于 MobileNetV1, MobileNetV2 准确率更高,模型更小。关于 MobileNetV1 可参考本人先前博客(深度可分离卷积解析 - MobileNetV1),此处给出 MobileNetV2 论文相关信息:
论文:《MobileNetV2: Inverted Residuals and Linear Bottlenecks》
作者:Mark Sandler et al.
年份:2018
论文标题直接点明 MobileNetV2 网络的两大亮点:Inverted Residuals(倒残差结构)和 Linear Bottlenecks(线性瓶颈结构)。本文也将围绕这两大亮点展开讲解。
2 MobileNetV2 要点
 |
 |
 |
| Fig.1 残差结构 | Fig.2 倒残差结构 (with shortcut) |
Fig.3 倒残差结构 (no shortcut) |
为便于理解,对倒残差与残差进行对照讲解。上方给出的结构图分别是残差、跳跃连接的残差和非跳跃连接的残差。
2.1 Inverted Residuals(倒残差结构)
对于倒残差结构的理解,第一个要点在于对通道数变化(维度变化)的理解。在残差结构中,先使用 1x1 卷积实现降维,再通过 3x3 卷积提取特征,最后使用 1×1 卷积实现升维。这是一个两头大、中间小的沙漏型结构。但在倒残差结构中,先使用 1x1 卷积实现升维,再通过 3x3 的 DW 卷积(逐通道卷积)提取特征,最后使用 1×1 卷积实现降维。调换了降维和升维的顺序,并将 3×3 的标准卷积换为 DW 卷积,呈两头小、中间大的梭型结构。二者比较参见下图:
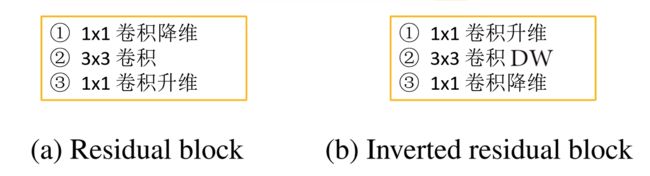
第二个要点在于卷积操作的变化。在倒残差结构中,用 DW 卷积将标准卷积替换。至于原因,自然是因为 DW 卷积是 MobileNet 网络的灵魂。
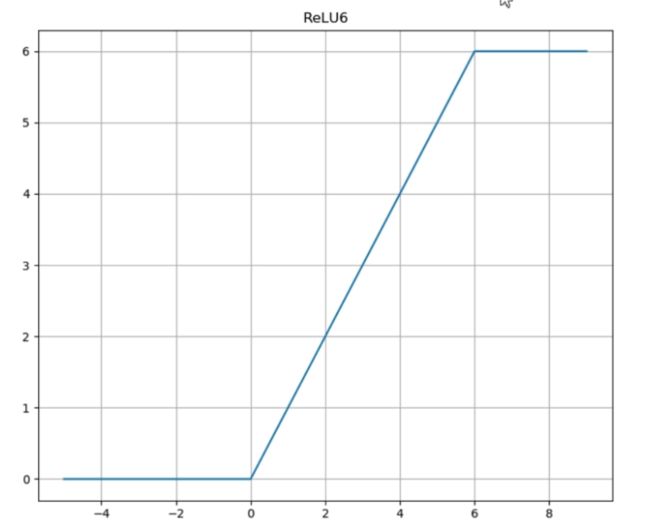
第三个要点在于所用激活函数的变化。残差结构中统一采用 ReLU 激活函数,而在倒残差结构中,前两个所用的为 ReLU6 激活函数,最后一个卷积使用的是线性激活函数。用 ReLU6 替换 ReLU,目的是为了保证在移动端低精度的 float16 时也能保有很好的数值分辨率。如果对 ReLU 的输出值不加限制,那么输出范围就是 0 到正无穷,而低精度的 float16 无法精确描述其数值,这将带来精度损失。最后一个卷积使用线性激活,则是线性瓶颈结构的内容,将在后文展开详细讲解。至于 ReLU6 和 ReLU 的异同,则可参见下图,直观明了,无需赘言。
 |
 |
比较倒残差结构和残差结构:
- 残差模块
(1) 整个过程为 “压缩 - 卷积 - 扩张”,呈沙漏型;
(2) 卷积操作为:卷积降维 (1×1) - 标准卷积提取特征 (3×3) - 卷积升维 (1×1);
(3) 统一使用 ReLU 激活函数;- 倒残差模块
(1) 整个过程为 “扩展- 卷积 - 压缩”,呈梭型;
(2) 卷积操作为:卷积升维 (1×1) - DW卷积提取特征 (3×3) - 卷积降维 (1×1);
(3) 使用 ReLU6 激活函数和线性激活函数。
此外,还有关于倒残差中第一个升维卷积操作的说明。该层在论文中又被称为扩展层 (expansion layer),目的是扩充通道数,扩充的倍数则由扩展因子控制 (论文中 factor=6),整个过程如下图所示。扩充通道的原因,是为了能够提取到更多的信息。DW 卷积无法改变通道数,所以先扩充通道数,在高维空间上进行 DW 卷积提取更多信息。

最后是有关跳跃连接 (shortcut) 的说明。shortcut 的作用是加总不同方式获取的特征图。当 stride=2 时,input 和 output 的的尺寸不一致,无法使用 shortcut。但 stride 参数并不直接控制跳跃连接,而是通过影响输出特征图的尺寸间接决定 shortcut 的使用。
2.2 Linear Bottlenecks(线性瓶颈结构)
瓶颈结构是指将高维空间映射到低维空间,缩减通道数;Expansion layer 则相反,其将低维空间映射到高维空间,增加通道数。沙漏型结构和梭型结构,都可看做是一个 Expansion layer 和一个 Bottleneck layer 的组合。Bottleneck layer 和 Expansion layer 本质上体现的都是1x1 卷积的妙用。至于线性瓶颈结构,就是末层卷积使用线性激活的瓶颈结构(将 ReLU 函数替换为线性函数)。
那么为什么要用线性函数替换 ReLU 呢?有人发现,在使用 MobileNetV1时,DW 部分的卷积核容易失效,即卷积核内数值大部分为零。作者认为这是 ReLU 引起的,在变换过程中,需要将低维信息映射到高维空间,再经 ReLU 重新映射回低维空间。若输出的维度相对较高,则变换过程中信息损失较小;若输出的维度相对较低,则变换过程中信息损失很大,如下图所示:

因此,作者认为在输出维度较低是使用 ReLU 函数,很容易造成信息的丢失,故而选择在末层使用线性激活。
3 代码实现 - pytorch
# _*_coding:utf-8_*_
import torch
import torch.nn as nn
class InvertedResidualsBlock(nn.Module):
def __init__(self, in_channels, out_channels, expansion, stride):
super(InvertedResidualsBlock, self).__init__()
channels = expansion * in_channels
self.stride = stride
self.basic_block = nn.Sequential(
nn.Conv2d(in_channels, channels, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(channels),
nn.ReLU6(inplace=True),
nn.Conv2d(channels, channels, kernel_size=3, stride=stride, padding=1, groups=channels, bias=False),
nn.BatchNorm2d(channels),
nn.ReLU6(inplace=True),
nn.Conv2d(channels, out_channels, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(out_channels)
)
# The shortcut operation does not affect the number of channels
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
out = self.basic_block(x)
if self.stride == 1:
print("With shortcut!")
out = out + self.shortcut(x)
else:
print("No shortcut!")
print(out.size())
return out
if __name__ == "__main__":
x = torch.randn(16, 3, 32, 32)
# no shortcut
net1 = InvertedResidualsBlock(3, 6, 6, 2)
# with shortcut
net2 = InvertedResidualsBlock(3, 6, 6, 1)
y1, y2 = net1(x), net2(x)
【参考】
- 深度学习之图像分类(十一)–MobileNetV2 网络结构;
- 迈微精选 | 轻量化CNN网络MobileNet系列详解;
- MobileNet系列;