作者
阿里云 EMR 开源大数据 OLAP 团队
StarRocks 社区分析湖团队
StarRocks 是一个强大的数据分析系统,主要宗旨是为用户提供极速、统一并且易用的数据分析能力,以帮助用户通过更低的使用成本来更快的洞察数据的价值。通过精简的架构、高效的向量化引擎以及全新设计的基于成本的优化器(CBO),StarRocks 的分析性能(尤其是多表 Join 查询)得以远超同类产品。
为了能够满足更多用户对于极速分析数据的需求,同时让 StarRocks 强大的分析能力应用在更加广泛的数据集上,阿里云开源大数据 OLAP 团队联合社区一起增强 StarRocks的数据湖分析能力。使其不仅能够分析存储在 StarRocks 本地的数据,还能够以同样出色的表现分析存储在 Apache Hive、Apache Iceberg 和 Apache Hudi 等开源数据湖或数据仓库的数据。
本文将重点介绍 StarRocks 极速数据湖分析能力背后的技术内幕,性能表现以及未来的规划。
整体架构
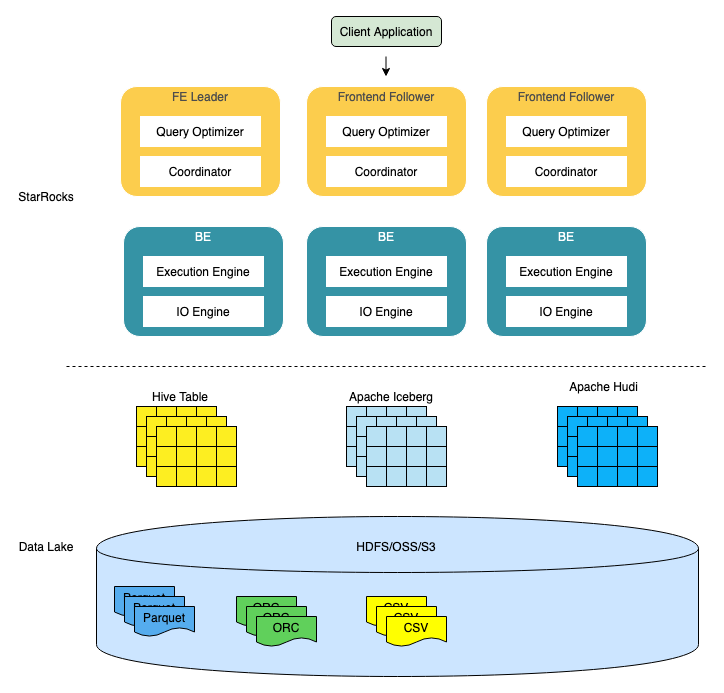
在数据湖分析的场景中,StarRocks 主要负责数据的计算分析,而数据湖则主要负责数据的存储、组织和维护。上图描绘了由 StarRocks 和数据湖所构成的完成的技术栈。
StarRocks 的架构非常简洁,整个系统的核心只有 FE(Frontend)、BE(Backend)两类进程,不依赖任何外部组件,方便部署与维护。其中 FE 主要负责解析查询语句(SQL),优化查询以及查询的调度,而 BE 则主要负责从数据湖中读取数据,并完成一系列的 Filter 和 Aggregate 等操作。
数据湖本身是一类技术概念的集合,常见的数据湖通常包含 Table Format、File Format 和 Storage 三大模块。其中 Table Format 是数据湖的“UI”,其主要作用是组织结构化、半结构化,甚至是非结构化的数据,使其得以存储在像 HDFS 这样的分布式文件系统或者像 OSS 和 S3 这样的对象存储中,并且对外暴露表结构的相关语义。Table Format 包含两大流派,一种是将元数据组织成一系列文件,并同实际数据一同存储在分布式文件系统或对象存储中,例如 Apache Iceberg、Apache Hudi 和 Delta Lake 都属于这种方式;还有一种是使用定制的 metadata service 来单独存放元数据,例如 StarRocks 本地表,Snowflake 和 Apache Hive 都是这种方式。
File Format 的主要作用是给数据单元提供一种便于高效检索和高效压缩的表达方式,目前常见的开源文件格式有列式的 Apache Parquet 和 Apache ORC,行式的 Apache Avro 等。
Storage 是数据湖存储数据的模块,目前数据湖最常使用的 Storage 主要是分布式文件系统 HDFS,对象存储 OSS 和 S3 等。
FE

FE 的主要作用将 SQL 语句转换成 BE 能够认识的 Fragment,如果把 BE 集群当成一个分布式的线程池的话,那么 Fragment 就是线程池中的 Task。从 SQL 文本到分布式物理执行计划,FE 的主要工作需要经过以下几个步骤:
- SQL Parse:将 SQL 文本转换成一个 AST(抽象语法树)
- SQL Analyze:基于 AST 进行语法和语义分析
- SQL Logical Plan:将 AST 转换成逻辑计划
- SQL Optimize:基于关系代数,统计信息,Cost 模型对 逻辑计划进行重写,转换,选择出 Cost “最低” 的物理执行计划
- 生成 Plan Fragment:将 Optimizer 选择的物理执行计划转换为 BE 可以直接执行的 Plan Fragment。
- 执行计划的调度
BE

Backend 是 StarRocks 的后端节点,负责数据存储以及 SQL 计算执行等工作。
StarRocks 的 BE 节点都是完全对等的,FE 按照一定策略将数据分配到对应的 BE 节点。在数据导入时,数据会直接写入到 BE 节点,不会通过FE中转,BE 负责将导入数据写成对应的格式以及生成相关索引。在执行 SQL 计算时,一条 SQL 语句首先会按照具体的语义规划成逻辑执行单元,然后再按照数据的分布情况拆分成具体的物理执行单元。物理执行单元会在数据存储的节点上进行执行,这样可以避免数据的传输与拷贝,从而能够得到极致的查询性能。
技术细节
StarRocks 为什么这么快?
CBO 优化器

一般 SQL 越复杂,Join 的表越多,数据量越大,查询优化器的意义就越大,因为不同执行方式的性能差别可能有成百上千倍。StarRocks 优化器主要基于 Cascades 和 ORCA 论文实现,并结合 StarRocks 执行器和调度器进行了深度定制,优化和创新。完整支持了 TPC-DS 99 条 SQL,实现了公共表达式复用,相关子查询重写,Lateral Join, CTE 复用,Join Rorder,Join 分布式执行策略选择,Runtime Filter 下推,低基数字典优化 等重要功能和优化。
CBO 优化器好坏的关键之一是 Cost 估计是否准确,而 Cost 估计是否准确的关键点之一是统计信息是否收集及时,准确。StarRocks 目前支持表级别和列级别的统计信息,支持自动收集和手动收集两种方式,无论自动还是手动,都支持全量和抽样收集两种方式。
MPP 执行
MPP (massively parallel processing) 是大规模并行计算的简称,核心做法是将查询 Plan 拆分成很多可以在单个节点上执行的计算实例,然后多个节点并行执行。每个节点不共享 CPU,内存, 磁盘资源。MPP 数据库的查询性能可以随着集群的水平扩展而不断提升。
如上图所示,StarRocks 会将一个查询在逻辑上切分为多个 Query Fragment(查询片段),每个 Query Fragment 可以有一个或者多个 Fragment 执行实例,每个Fragment 执行实例 会被调度到集群某个 BE 上执行。如上图所示,一个 Fragment 可以包括 一个 或者多个 Operator(执行算子),图中的 Fragment 包括了 Scan, Filter, Aggregate。如上图所示,每个 Fragment 可以有不同的并行度。
如上图所示,多个 Fragment 之间会以 Pipeline 的方式在内存中并行执行,而不是像批处理引擎那样 Stage By Stage 执行。
如上图所示,Shuffle (数据重分布)操作是 MPP 数据库查询性能可以随着集群的水平扩展而不断提升的关键,也是实现高基数聚合和大表 Join 的关键。
向量化执行引擎
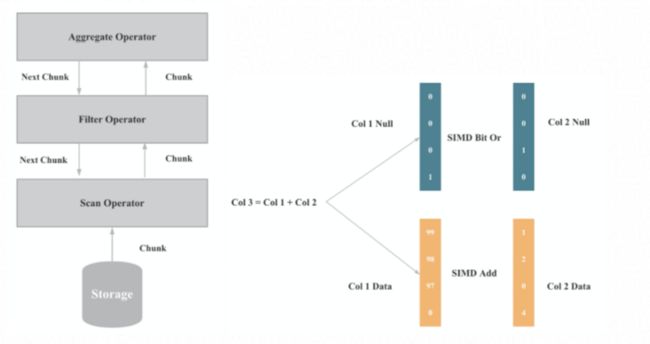
随着数据库执行的瓶颈逐渐从 IO 转移到 CPU,为了充分发挥 CPU 的执行性能,StarRocks 基于向量化技术重新实现了整个执行引擎。算子和表达式向量化执行的核心是批量按列执行,批量执行,相比与单行执行,可以有更少的虚函数调用,更少的分支判断;按列执行,相比于按行执行,对 CPU Cache 更友好,更易于 SIMD 优化。
向量化执行不仅仅是数据库所有算子的向量化和表达式的向量化,而是一项巨大和复杂的性能优化工程,包括数据在磁盘,内存,网络中的按列组织,数据结构和算法的重新设计,内存管理的重新设计,SIMD 指令优化,CPU Cache 优化,C++优化等。向量化执行相比之前的按行执行,整体性能提升了5到10倍。
StarRocks 如何优化数据湖分析?
大数据分析领域,数据除了存储在数仓之外,也会存储在数据湖当中,传统的数据湖实现方案包括 Hive/HDFS。近几年比较火热的是 LakeHouse 概念,常见的实现方案包括 Iceberg/Hudi/Delta。那么 StarRocks 能否帮助用户更好地挖掘数据湖中的数据价值呢?答案是肯定的。
在前面的内容中我们介绍了 StarRocks 如何实现极速分析,如果将这些能力用于数据湖肯定会带来更好地数据湖分析体验。在这部分内容中,我们会介绍 StarRocks 是如何实现极速数据湖分析的。
我们先看一下全局的架构,StarRocks 和数据湖分析相关的主要几个模块如下图所示。其中 Data Management 由数据湖提供,Data Storage 由对象存储 OSS/S3,或者是分布式文件系统 HDFS 提供。
目前,StarRocks 已经支持的数据湖分析能力可以归纳为下面几个部分:
- 支持 Iceberg v1 表查询
https://github.com/StarRocks/starrocks/issues/1030
- 支持 Hive 外表查询
外部表 @ External_table @ StarRocks Docs (dorisdb.com)
https://docs.dorisdb.com/zh-cn/main/using_starrocks/External_table
- 支持 Hudi COW 表查询
https://github.com/StarRocks/starrocks/issues/2772
接下来我们从查询优化和查询执行这几个方面来看一下,StarRocks 是如何实现将极速分析的能力赋予数据湖的。
查询优化
查询优化这部分主要是利用前面介绍的 CBO 优化器来实现,数据湖模块需要给优化器统计信息。基于这些统计信息,优化器会利用一系列策略来实现查询执行计划的最优化。接下来我们通过例子看一下几个常见的策略。
- 统计信息
我们看下面这个例子,生成的执行计划中,HdfsScanNode 包含了 cardunality、avgRowSize 等统计信息的展示。
MySQL [hive_test]> explain select l_quantity from lineitem;
+-----------------------------+
| Explain String |
+-----------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS:5: l_quantity |
| PARTITION: UNPARTITIONED |
| |
| RESULT SINK |
| |
| 1:EXCHANGE |
| |
| PLAN FRAGMENT 1 |
| OUTPUT EXPRS: |
| PARTITION: RANDOM |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 01 |
| UNPARTITIONED |
| |
| 0:HdfsScanNode |
| TABLE: lineitem |
| partitions=1/1 |
| cardinality=126059930 |
| avgRowSize=8.0 |
| numNodes=0 |
+-----------------------------+在正式进入到 CBO 优化器之前,这些统计信息都会计算好。比如针对 Hive 我们有 MetaData Cache 来缓存这些信息,针对 Iceberg 我们通过 Iceberg 的 manifest 信息来计算这些统计信息。获取到这些统计信息之后,对于后续的优化策略的效果有很大地提升。
- 分区裁剪
分区裁剪是只有当目标表为分区表时,才可以进行的一种优化方式。分区裁剪通过分析查询语句中的过滤条件,只选择可能满足条件的分区,不扫描匹配不上的分区,进而显著地减少计算的数据量。比如下面的例子,我们创建了一个以 ss_sold_date_sk 为分区列的外表。
create external table store_sales(
ss_sold_time_sk bigint
, ss_item_sk bigint
, ss_customer_sk bigint
, ss_coupon_amt decimal(7,2)
, ss_net_paid decimal(7,2)
, ss_net_paid_inc_tax decimal(7,2)
, ss_net_profit decimal(7,2)
, ss_sold_date_sk bigint
) ENGINE=HIVE
PROPERTIES (
"resource" = "hive_tpcds",
"database" = "tpcds",
"table" = "store_sales"
);在执行如下查询的时候,分区2451911和2451941之间的数据才会被读取,其他分区的数据会被过滤掉,这可以节约很大一部分的网络 IO 的消耗。
select ss_sold_time_sk from store_sales
where ss_sold_date_sk between 2451911 and 2451941
order ss_sold_time_sk;- Join Reorder
多个表的 Join 的查询效率和各个表参与 Join 的顺序有很大关系。如 select * from T0, T1, T2 where T0.a=T1.a and T2.a=T1.a,这个 SQL 中可能的执行顺序有下面两种情况: - T0 和 T1 先做 Join,然后再和 T2 做 Join
- T1 和 T2 先做 Join,然后再和 T0 做 Join
根据 T0 和 T2 的数据量及数据分布,这两种执行顺序会有不同的性能表现。针对这个情况,StarRocks 在优化器中实现了基于 DP 和贪心的 Join Reorder 机制。目前针对 Hive的数据分析,已经支持了 Join Reorder,其他的数据源的支持也正在开发中。下面是一个例子:
MySQL [hive_test]> explain select * from T0, T1, T2 where T2.str=T0.str and T1.str=T0.str;
+----------------------------------------------+
| Explain String |
+----------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS:1: str | 2: str | 3: str |
| PARTITION: UNPARTITIONED |
| RESULT SINK |
| 8:EXCHANGE |
| PLAN FRAGMENT 1 |
| OUTPUT EXPRS: |
| PARTITION: HASH_PARTITIONED: 2: str |
| STREAM DATA SINK |
| EXCHANGE ID: 08 |
| UNPARTITIONED |
| 7:HASH JOIN |
| | join op: INNER JOIN (BUCKET_SHUFFLE(S)) |
| | hash predicates: |
| | colocate: false, reason: |
| | equal join conjunct: 1: str = 3: str |
| |----6:EXCHANGE |
| 4:HASH JOIN |
| | join op: INNER JOIN (PARTITIONED) |
| | hash predicates: |
| | colocate: false, reason: |
| | equal join conjunct: 2: str = 1: str |
| |----3:EXCHANGE |
| 1:EXCHANGE |
| PLAN FRAGMENT 2 |
| OUTPUT EXPRS: |
| PARTITION: RANDOM |
| STREAM DATA SINK |
| EXCHANGE ID: 06 |
| HASH_PARTITIONED: 3: str |
| 5:HdfsScanNode |
| TABLE: T2 |
| partitions=1/1 |
| cardinality=1 |
| avgRowSize=16.0 |
| numNodes=0 |
| PLAN FRAGMENT 3 |
| OUTPUT EXPRS: |
| PARTITION: RANDOM |
| STREAM DATA SINK |
| EXCHANGE ID: 03 |
| HASH_PARTITIONED: 1: str |
| 2:HdfsScanNode |
| TABLE: T0 |
| partitions=1/1 |
| cardinality=1 |
| avgRowSize=16.0 |
| numNodes=0 |
| PLAN FRAGMENT 4 |
| OUTPUT EXPRS: |
| PARTITION: RANDOM |
| STREAM DATA SINK |
| EXCHANGE ID: 01 |
| HASH_PARTITIONED: 2: str |
| 0:HdfsScanNode |
| TABLE: T1 |
| partitions=1/1 |
| cardinality=1 |
| avgRowSize=16.0 |
| numNodes=0 |
+----------------------------------------------+- 谓词下推
谓词下推将查询语句中的过滤表达式计算尽可能下推到距离数据源最近的地方,从而减少数据传输或计算的开销。针对数据湖场景,我们实现了将 Min/Max 等过滤条件下推到 Parquet 中,在读取 Parquet 文件的时候,能够快速地过滤掉不用的 Row Group。
比如,对于下面的查询,l_discount=1对应条件会下推到 Parquet 侧。
MySQL [hive_test]> explain select l_quantity from lineitem where l_discount=1;
+----------------------------------------------------+
| Explain String |
+----------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS:5: l_quantity |
| PARTITION: UNPARTITIONED |
| |
| RESULT SINK |
| |
| 2:EXCHANGE |
| |
| PLAN FRAGMENT 1 |
| OUTPUT EXPRS: |
| PARTITION: RANDOM |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 02 |
| UNPARTITIONED |
| |
| 1:Project |
| | : 5: l_quantity |
| | |
| 0:HdfsScanNode |
| TABLE: lineitem |
| NON-PARTITION PREDICATES: 7: l_discount = 1.0 |
| partitions=1/1 |
| cardinality=63029965 |
| avgRowSize=16.0 |
| numNodes=0 |
+----------------------------------------------------+ - 其他策略
除了上面介绍的几种策略,针对数据湖分析,我们还适配了如 Limit 下推、TopN 下推、子查询优化等策略。能够进一步地优化查询性能。
查询执行
前面介绍了,StarRocks 的执行引擎是全向量化、MPP 架构的,这些无疑都会给我们分析数据湖的数据带来很大提升。接下来我们看一下 StarRocks 是如何调度和执行数据湖分析查询的。
- 查询调度
数据湖的数据一般都存储在如 HDFS、OSS 上,考虑到混部和非混部的情况。我们对 Fragment 的调度,实现了一套负载均衡的算法。 - 做完分区裁剪之后,得到要查询的所有 HDFS 文件 block
- 对每个 block 构造 THdfsScanRange,其中 hosts 包含 block 所有副本所在的 datanode 地址,最终得到 List
Coordinator 维护一个所有 be 当前已经分配的 scan range 数目的 map,每个 datanode 上磁盘已分配的要读取 block 的数目的 map>,及每个 be 平均分配的 scan range 数目 numScanRangePerBe
如果 block 副本所在的 datanode 有be(混部)
- 每个 scan range 优先分配给副本所在的 be 中 scan range 数目最少的 be。如果 be 已经分配的 scan range 数目大于 numScanRangePerBe,则从远程 be 中选择 scan range 数目最小的
- 如果有多个 be 上 scan range 数目一样小,则考虑 be 上磁盘的情况,选择副本所在磁盘上已分配的要读取 block 数目小的 be
如果 block 副本所在的 datanode 机器没有 be(单独部署或者可以远程读)
- 选择 scan range 数目最小的 be
- 查询执行
在调度到 BE 端进行执行之后,整个执行过程都是向量化的。具体看下面 Iceberg 的例子,IcebergScanNode 对应的 BE 端目前是 HdfsScanNode 的向量化实现,其他算子也是类似,在 BE 端都是向量化的实现。
MySQL [external_db_snappy_yuzhou]> explain select c_customer_id customer_id
-> ,c_first_name customer_first_name
-> ,c_last_name customer_last_name
-> ,c_preferred_cust_flag customer_preferred_cust_flag
-> ,c_birth_country customer_birth_country
-> ,c_login customer_login
-> ,c_email_address customer_email_address
-> ,d_year dyear
-> ,'s' sale_type
-> from customer, store_sales, date_dim
-> where c_customer_sk = ss_customer_sk
-> and ss_sold_date_sk = d_date_sk;
+------------------------------------------------
| PLAN FRAGMENT 0
| OUTPUT EXPRS:2: c_customer_id | 9: c_first_name | 10: c_last_name | 11: c_preferred_cust_flag | 15: c_birth_country | 16: c_login | 17: c_email_address | 48: d_year | 70: expr |
| PARTITION: UNPARTITIONED
| RESULT SINK
| 9:EXCHANGE
| PLAN FRAGMENT 1
| OUTPUT EXPRS:
| PARTITION: RANDOM
| STREAM DATA SINK
| EXCHANGE ID: 09
| UNPARTITIONED
| 8:Project
| | : 2: c_customer_id
| | : 9: c_first_name
| | : 10: c_last_name
| | : 11: c_preferred_cust_flag
| | : 15: c_birth_country
| | : 16: c_login
| | : 17: c_email_address
| | : 48: d_year
| | : 's'
| 7:HASH JOIN
| | join op: INNER JOIN (BROADCAST)
| | hash predicates:
| | colocate: false, reason:
| | equal join conjunct: 21: ss_customer_sk = 1: c_customer_sk
| 4:Project
| | : 21: ss_customer_sk
| | : 48: d_year
| 3:HASH JOIN
| | join op: INNER JOIN (BROADCAST)
| | hash predicates:
| | colocate: false, reason:
| | equal join conjunct: 41: ss_sold_date_sk = 42: d_date_sk
| 0:IcebergScanNode
| TABLE: store_sales
| cardinality=28800991
| avgRowSize=1.4884362
| numNodes=0
| PLAN FRAGMENT 2
| OUTPUT EXPRS:
| PARTITION: RANDOM
| STREAM DATA SINK
| EXCHANGE ID: 06
| UNPARTITIONED
| 5:IcebergScanNode
| TABLE: customer
| cardinality=500000
| avgRowSize=36.93911
| numNodes=0
| PLAN FRAGMENT 3
| OUTPUT EXPRS:
| PARTITION: RANDOM
| STREAM DATA SINK
| EXCHANGE ID: 02
| UNPARTITIONED
| 1:IcebergScanNode
| TABLE: date_dim
| cardinality=73049
| avgRowSize=4.026941
| numNodes=0 基准测试
TPC-H 是美国交易处理效能委员会TPC(Transaction Processing Performance Council)组织制定的用来模拟决策支持类应用的测试集。
It consists of a suite of business oriented ad-hoc queries and concurrent data modifications.
TPC-H 根据真实的生产运行环境来建模,模拟了一套销售系统的数据仓库。该测试共包含8张表,数据量可设定从1 GB~3 TB不等。其基准测试共包含了22个查询,主要评价指标为各个查询的响应时间,即从提交查询到结果返回所需时间。
测试结论
在 TPCH 100G规模的数据集上进行对比测试,共22个查询,结果如下:
StarRocks 使用本地存储查询和 Hive 外表查询两种方式进行测试。其中,StarRocks On Hive 和 Trino On Hive 查询的是同一份数据,数据采用 ORC 格式存储,采用 zlib 格式压缩。测试环境使用 阿里云 EMR 进行构建。
最终,StarRocks 本地存储查询总耗时为21s,StarRocks Hive 外表查询总耗时92s。Trino 查询总耗时307s。可以看到 StarRocks On Hive 在查询性能方面远远超过 Trino,但是对比本地存储查询还有不小的距离,主要的原因是访问远端存储增加了网络开销,以及远端存储的延时和 IOPS 通常都不如本地存储,后面的计划是通过 Cache 等机制弥补问题,进一步缩短 StarRocks 本地表和 StarRocks On Hive 的差距。
具体测试过程请参考:
StarRocks vs Trino TPCH 性能测试对比报告
https://www.starrocks.com/zh-CN/blog/tpch_2.1
未来规划
得益于全面向量化执行引擎,CBO 优化器以及 MPP 执行框架等核心技术,目前 StarRocks 已经实现了远超其他同类产品的极速数据湖分析能力。从长远来看, StarRocks 在数据湖分析方向的愿景是为用户提供极其简单、易用和高速的数据湖分析能力。为了能够实现这一目标,StarRocks 现在还有许多工作需要完成,其中包括:
- 集成 Pipeline 执行引擎,通过 Push Based 的流水线执行方式,进一步降低查询响应速度
- 自动的冷热数据分层存储,用户可以将频繁更新的热数据存储在 StarRocks 本地表上,StarRocks 会定期自动将冷数据从本地表迁移到数据湖
- 去掉显式建立外表的步骤,用户只需要建立数据湖对应的 resource 即可实现数据湖库表全自动同步
- 进一步完善 StarRocks 对于数据湖产品特性的支持,包括支持 Apache Hudi 的 MOR 表和 Apache Iceberg 的 v2 表;支持直接写数据湖;支持 Time Travel 查询,完善 Catalog 的支持度等
- 通过层级 Cache 来进一步提升数据湖分析的性能
更多信息
参考链接
[1] 阿里云 EMR StarRocks 官方文档
https://help.aliyun.com/document_detail/404790.html
[2] 阿里云 EMR 控制台
https://emr.console.aliyun.com/
[3] https://github.com/StarRocks/starrocks/issues/1030
[4] https://github.com/StarRocks/...
[5] StarRocks vs Trino TPCH 性能测试对比报告
https://www.starrocks.com/zh-CN/blog/tpch_2.1
活动推荐
今晚7点,国内首家互联网金融公司众安保险将与 StarRocks 举办一场联合直播。
众安保险科学数据应用中心高级总监施兴天、StarRocks 联合创始人&COO 叶谦将以 StarRocks 落地众安集智平台为例,分享如何用全新实时分析能力开启数字化经营新局面。
近年来,众安保险致力于加速数据价值向业务价值转化,服务用户超过 5 亿,业务全程在线完成,在金融科技的研发和落地上非常领先。
扫描下⽅海报⼆维码,锁定直播!
