
图片来源:https://revolutionmotors.ca/b...
作者:原点、正超
一、冷启动问题介绍
1 什么是冷启动
在推荐系统中,存在着成千上万的用户,也存在着成千上万的物品,推荐系统的本质任务是为用户推荐其感兴趣的物品。在这里面,用户和物品都是不断更新的,如何给新用户推荐其感兴趣的物品,如何把新物品推荐给对其感兴趣的用户,就是推荐系统的冷启动问题。
所以,推荐系统的冷启动问题,主要包括用户冷启动、物品冷启动两大类。
2 冷启动的重要性
用户的流动、不确定性是客观存在的事实,物品的上架、更新、下架也是客观存在的事实,在当今信息过载的时代,用户的不确定性表现的更加明显,如何给这些不确定性的用户推荐好的物品,是推荐系统的主要职能之一。既然用户和物品都是不断产生的,在互联网上是一种常态,那么冷启动问题就会伴随产品的整个生命周期。
互联网上的每个产品都在关注MAU、DAU,在这个流量为王的时代,一个产品能否存活、能否很好的存活,用户起了至关重要的作用。新用户对产品是否满意,能否留存,直接关系到一个产品的用户增长和收益增长。在商业领域,顾客就是上帝,在互联网上,这句话依然适用,并把这句话表现的淋漓尽致。
另外,一个产品能否对其物品推陈出新,是吸引用户的关键所在,从某种意义上来讲,物品的好坏直接决定了一个产品的好坏。
所以,如何解决好新用户、新物品问题,即冷启动问题,对于推荐系统来说非常重要。
3 冷启动的方法
根据用户和物品的不同特点,将采取不同的冷启动方法,接下来分别阐述。
3.1 用户冷启动
非个性化推荐
热门推荐是一个不错的方法,虽然没有个性化,但是很多人都有从众心理,根据二八原则,把热门物品推荐给新用户,能否满足80%用户的需求。比如热门电影、热门歌曲、热门短视频的推荐。
利用注册信息推荐
现在很多app均要求用户注册之后才能使用,所以可以根据这些注册信息进行个性化推荐,比如婚恋网站,可以给男士推荐美女,为美女推荐帅哥等。
另外还可以根据注册的年龄、地域、职业、学历、收入等信息形成人物画像,然后根据这些人物画像进行个性化推荐。
根据兴趣点进行推荐
现在有些app要求用户在使用之前选择自己的兴趣点,以便推荐系统能够很好进行的推荐,比如新闻类app要求用户选择感兴趣的标签,游戏类app要求用户选择感兴趣的游戏种类,音乐类app要求用户选择感兴趣的曲风等等。
基于少量行为进行推荐
有些用户活跃度比较低,行为也比较少,但是可以根据这些少有的用户行为进行个性化推荐,比如用户看过某个短视频,则可以根据这个看过的短视频进行推荐。
采用试探的方法进行推荐
探测利用的方法是推荐系统常用的方法之一。首先随机给用户推荐几个物品,然后根据用户的反馈获取用户的兴趣。这种方法主要适用于较少消耗用户时间的app上,可以快速的定位用户的兴趣,比如新闻类,短视频类app。
根据兴趣迁移策略进行推荐
有些公司有比较成熟的app,或者一个app上有多类推荐,则可以借助其他的用户兴趣进行迁移推荐,比如有些app即推荐音乐,也推荐短视频,则可以根据用户对音乐的兴趣点推荐相关的短视频。
3.2 物品冷启动
基于side information进行推荐
物品天然具有某些属性信息,比如商品的商家、分类、价格等,再比如音乐的语种、风格、曲风、乐器等,推荐系统则可以根据这些基本信息推荐给相应感兴趣的用户。
基于少量行为进行推荐
有些物品具有少量的行为信息,则可以根据这些少量的行为信息进行个性化推荐,比如某个用户完整播放了某个短视频,则可以把这个短视频推荐给相似的用户。
采用试探的方法进行推荐
探测利用的方法同样也适用于物品的冷启动,首先把一个冷启动的物品随机分发给一批用户,根据用户的反馈推荐给相应感兴趣的用户。
4 冷启动方法的评价指标
评价一个冷启动方法的好坏,主要考虑以下三点:
覆盖度
第一个需要考虑的评价指标是覆盖度,覆盖度的大小直接决定了线上效果的好坏,如果覆盖度过低,线上覆盖范围内的效果再好,整体的效果也会大打折扣。对于前面叙述的方法,基于side information的物品冷启动方法和非个性化的用户冷启动方法覆盖度均很高,几乎可以覆盖100%。而基于少量行为的用户冷启动方法和根据兴趣迁移的用户冷启动方法要求就相对严苛一点,其覆盖度就没那么高了。
准确度
第二个需要考虑的评价指标是准确度,比如根据兴趣迁移的用户冷启动方法因为有较多的用户信息,其推荐的准确度就相对很高,而如基于side information的方法,虽然覆盖度很高,但其准确度就不那么高了。
可解释
推荐系统中的推荐可解释性,无论对于用户还是对于推荐系统来说都非常重要,现在很多推荐系统也越来越重视推荐的可解释性。同样,对于冷启动问题,好的可解释性,也有利于提升推荐的准确度。比如根据兴趣点进行的用户冷启动方法,就可以很好的为用户解释推荐的物品。
从上述几个评价指标来看,没有一个方法占据所有的优点,所以实践中的推荐系统,也是多种冷启动方法并存,以达到多种方法优点互补的效果。
上述我们简要介绍了冷启动问题的定义,解决两类冷启动问题的一般方法,以及评价冷启动方法的好坏标准。接下来将介绍在在音乐推荐系统中,我们对于解决歌曲冷启动问题的实践方案。
二、云音乐歌曲冷启动实践
1 业务背景
目前入驻网易云音乐的独立音乐人超40万,独立音乐人每天有大量优秀的新作品发布,如何快速精准的将这些优秀的新作品分发到目标听众的播放列表中,完成歌曲的冷启动进而进入歌曲成长体系是网易云音乐的推荐系统要解决的一个重要问题。
冷启动歌曲由于其特殊性,很难直接套用针对非冷启动歌曲建立的推荐模型,因此需要针对冷启动歌曲建立一套有效的歌曲推荐模型。
2 歌曲冷启动面临的问题
2.1 歌曲特征缺失
冷启动歌曲面临的根本难题是缺少用户对歌曲的历史交互数据,从而导致特征和样本的缺失。
缺少歌曲统计特征
包括歌曲的各类行为,如播放,下载,收藏,分享等行为的次数和转化率特征,这类特征通常是歌曲召回和排序模型中重要组成部分,冷启动歌曲由于不包含这些特征无法直接使用现有模型。
缺少样本来训练冷启动歌曲的embedding向量
推荐系统中召回和排序模型中的歌曲embedding通常是端到端训练得到的,而冷启动歌曲不存在于词表内,无法直接得到对应的歌曲embedding表示。
2.2 业务可解释性
歌曲冷启动系统的终极目标还是服务于业务,除了完成将冷启动歌曲成功分发出去这一目标外,还希望冷启动的过程尽量具备可解释性。一个具有可解释性的冷启动系统,将更好的帮助业务去解答诸如什么样的歌曲更容易冷启动成功这类问题,从而为后续冷启动歌曲提供成功经验。
3 解决方案
解决歌曲冷启动的核心思想还是尽量增加可用数据,应用最广泛的方法是利用side information的冷启动方法,这类方法通常实现简单且,对数据特征的要求低,同时具有良好的业务可解释性。
下面将从冷启动歌曲召回和冷启动歌曲的排序两个角度分别介绍基于内容标签的冷启动方案。
3.1 冷启动召回
由于无法收集到冷启动歌曲的用户交互行为记录,通常无法对冷启动歌曲使用常规的i2i或向量进行召回,但可以退而求其次,利用冷启动歌曲的内容标签进行召回,召回的过程如下图
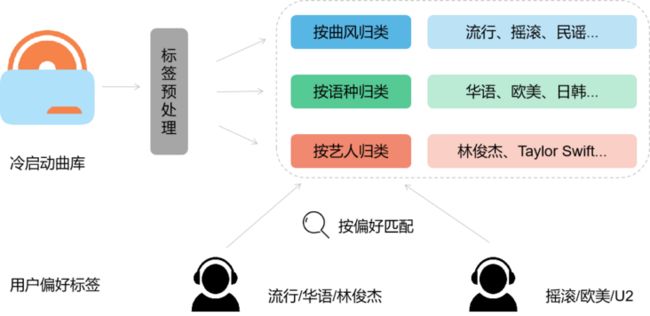
第一步,召回部分将冷启动歌曲对应的内容标签做预处理归一化,包括仅保留主曲风,小语种归一,专辑艺人和演唱艺人统一等。
第二步,冷启动的歌曲按照内容标签进行归类,每一类内部按照带时间衰减的转化率给予召回候选分,候选分的计算方式为:
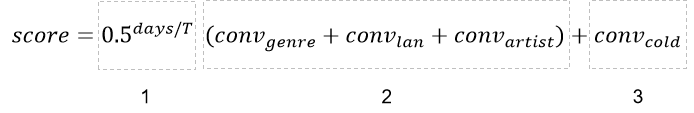
由三个部分组成
第1部分:时间衰减因子,days表示冷启动天数,T表示半衰期,这部分整体表示的意思是越是近期的新歌曲分数越高。
第2部分:平滑的标签转化率,具体的计算方式为
![]()
like7d和play7d分别表示最近7天歌曲在平台内的收藏人数和播放人数,k用于调节初始转化率。这部分表示使用冷启动歌曲的标签维度的转化率表示冷启动歌曲转化率。
第3部分:冷启动歌曲本身的平滑转化率,整体计算过程达到的效果是:1)使用平滑转化率作为召回候选分;2)冷启动初期无冷启动歌曲转化数据,则使用冷启动歌曲对应的内容标签转化率代替;3)随着冷启动分发时间推进,歌曲内容标签转化率作用减少,逐渐被实际歌曲的转化效果代替。
3.2 冷启动排序
与召回部分类似,排序时无法直接使用冷启动歌曲的特征,但可以退化为使用冷启动歌曲的标签特征,借用非冷启动歌曲推荐排序模型训练的曲风,语种和艺人的统计特征以及embedding向量来表示冷启动歌曲的缺失特征。
排序部分模型结构如下图
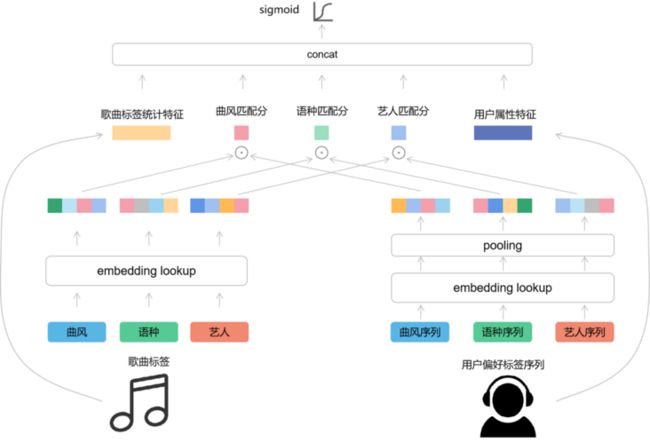
包含歌曲侧和用户侧特征构建,以及用户和冷启动歌曲的排序模型。
歌曲侧
将针对非冷启动歌曲训练的排序模型中的曲风,语种和艺人对应的embedding向量以及歌曲标签对应的统计特征导出。然后根据冷启动歌曲的曲风、语种和艺人标签分别查询embedding和统计特征。
用户侧
计算用户对非冷启动歌曲曲风、语种和艺人维度的偏好序列,查询embedding并做pooling后将用户的标签偏好表示为对应的偏好向量。
排序模型:该部分对用户曲风,语种和艺人三个维度的向量进行内积计算匹配分,然后加上歌曲标签维度统计特征以及用户维度属性特征输入逻辑回归模型预测用户是否。模型的训练时在用户对非冷启动歌曲的交互样本上进行,训练完成后得到每个的权重输出。
线上预测
由于用户侧偏好向量、用户属性特征和冷启动歌曲侧标签转化率和歌曲标签向量均可以在离线完成,线上预测时只需要根据歌曲标签查询embedding,然后分别与用户偏好标签进行匹配,最后分别乘以逻辑回归模型中每个维度权重输入sigmoid即可得到用户对冷启动歌曲的排序分。线上预测时计算量少,预测速度快。
最后,得到用户对候选的冷启动歌曲的打分后,取top歌曲插入现有歌曲推荐系统的分发流量中,完成对冷启动歌曲的分发。
4 业务效果
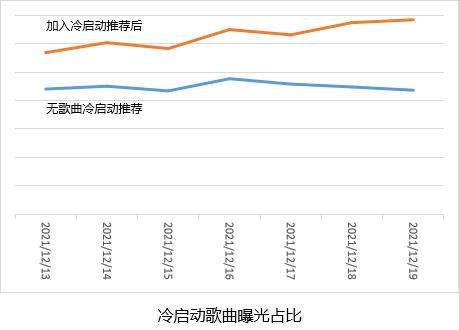
衡量冷启动歌曲是否成功分发出去最直接的指标即是冷启动歌曲的曝光覆盖率,即有过歌曲曝光的用户中有多少用户曾曝光过冷启动歌曲。但由于冷启动歌曲不一定全是高质量,给用户推荐了质量不高的歌曲可能影响用户播放体验,因此不能无限制的分发冷启动歌曲。一个好的歌曲冷启动系统应该是对现有歌曲推荐系统无影响或影响尽量小的基础上,让更多的冷启动歌曲被分发出去。
下图对比了线上实验情况,加入冷启动推荐的召回和排序作为实验组,无冷启动推荐作为基准组的实验效果。实验期间在不影响现有歌曲推荐系统用户体验指标前提下,加入歌曲冷启动系统的实验组相比基准组的冷启动歌曲曝光覆盖率取得了相对增加40%以上明显提升。
5 小结
本部分介绍了基于标签的歌曲冷启动推荐方法,该方法简单有效,是目前网易云音乐歌曲推荐系统中重要的组成部分,是构建健康的音乐分发生态系统的重要基石,为众多冷启动新歌的成长提供了第一步的助力。
在本系列的后续内容中,我们将继续分享云音乐在冷启动这一经典问题上的更多解决方法和实践经验,敬请期待。
本文发布自网易云音乐技术团队,文章未经授权禁止任何形式的转载。我们常年招收各类技术岗位,如果你准备换工作,又恰好喜欢云音乐,那就加入我们 [email protected]...