强化学习-随机策略梯度(Policy-Base)
比较懒,引用一下别人的图片
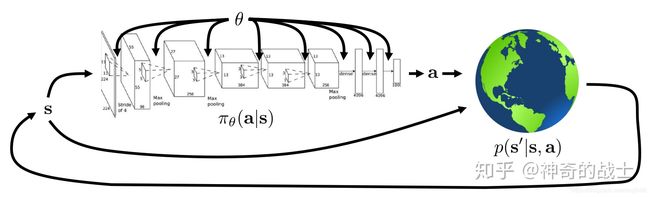 策略 π \pi π就是在状态 s s s下采取动作 a a a的概率分布,可以标示为以下形式:
策略 π \pi π就是在状态 s s s下采取动作 a a a的概率分布,可以标示为以下形式:
π θ ( a ∣ s ) = π ( a ∣ s , θ ) = P r { A t = a ∣ S t = s , θ t = θ } (1) \tag{1} \pi_{\theta}(a|s)=\pi(a|s,\theta)=P_r\{A_t=a|S_t=s,\theta_t=\theta\} πθ(a∣s)=π(a∣s,θ)=Pr{At=a∣St=s,θt=θ}(1)
其中时刻 t t t,环境状态为 s s s,参数为 θ \theta θ,输出动作 a a a的概率为 P r P_r Pr
智能体与环境做一次回合的动作轨迹:
τ = { s 1 , a 1 , s 2 , a 2 , . . . . . . , s t , a t , s t + 1 } (2) \tag{2} \tau=\{s_1,a_1,s_2,a_2,......,s_t,a_t,s_{t+1}\} τ={s1,a1,s2,a2,......,st,at,st+1}(2)
由 ( 2 ) (2) (2)式可以算出 τ \tau τ轨迹发生的概率为:
p ( τ ) = p { s 1 , a 1 , s 2 , a 2 , . . . . . . , s t , a t , s t + 1 } = p ( s 1 ) ∗ p ( a 1 ∣ s 1 ) ∗ p ( s 2 ∣ s 1 , a 1 ) ∗ p ( a 2 ∣ s 2 ) ∗ p ( s 3 ∣ s 2 , a 2 ) ∗ . . . ∗ p ( a t ∣ s t ) ∗ p ( s t + 1 ∣ s t , a t ) = p ( s 1 ) ∗ ∏ t = 1 T p ( a t ∣ s t ) ∗ p ( s t + 1 ∣ s t , a t ) (3) \tag{3} \begin{aligned} p(\tau)&=p\{s_1,a_1,s_2,a_2,......,s_t,a_t,s_{t+1}\} \\ &=p(s_1)*p(a_1|s_1)*p(s_2|s_1,a_1)*p(a_2|s_2)*p(s_3|s_2,a_2)*...*p(a_t|s_t)*p(s_{t+1}|s_t,a_t) \\ &=p(s_1)*\prod_{t=1}^Tp(a_t|s_t)*p(s_{t+1}|s_t,a_t) \end{aligned} p(τ)=p{s1,a1,s2,a2,......,st,at,st+1}=p(s1)∗p(a1∣s1)∗p(s2∣s1,a1)∗p(a2∣s2)∗p(s3∣s2,a2)∗...∗p(at∣st)∗p(st+1∣st,at)=p(s1)∗t=1∏Tp(at∣st)∗p(st+1∣st,at)(3)
由 ( 1 ) (1) (1)式可将 ( 3 ) (3) (3)式写成:
p θ ( τ ) = π θ ( τ ) = p ( s 1 ) ∗ ∏ t = 1 T π θ ( a t ∣ s t ) ∗ p ( s t + 1 ∣ s t , a t ) (4) \tag{4} p_\theta(\tau)=\pi_{\theta}(\tau)=p(s_1)*\prod_{t=1}^T\pi_\theta(a_t|s_t)*p(s_{t+1}|s_t,a_t) pθ(τ)=πθ(τ)=p(s1)∗t=1∏Tπθ(at∣st)∗p(st+1∣st,at)(4)
其中, p θ ( τ ) p_\theta(\tau) pθ(τ)标示在 π θ \pi_\theta πθ采用 θ \theta θ参数下,动作轨迹出现的概率,展开式中 p ( s 1 ) p(s_1) p(s1)和 p ( s t + 1 ∣ s t , a t ) t ∈ { 1 , 2 , 3 , . . . , T } p(s_{t+1}|s_t,a_t) \kern{1em} t \in \{1,2,3,...,T\} p(st+1∣st,at)t∈{1,2,3,...,T}都是环境所产生的,因此跟 θ \theta θ没有关系
智能体与环境做一次回合的总回报为:
R ( τ ) = r 1 + r 2 + . . . . . . = ∑ t = 1 T r t = ∑ t = 1 T r ( s t , a t ) (5) \tag{5} R(\tau)=r_1+r_2+......=\sum_{t=1}^Tr_t=\sum_{t=1}^Tr(s_t,a_t) R(τ)=r1+r2+......=t=1∑Trt=t=1∑Tr(st,at)(5)
其中 r t r_t rt或者 r ( a t ∣ s t ) r(a_t|s_t) r(at∣st)标示在 s t s_t st状态下,采取 a t a_t at动作所得到的即时回报
那么智能体在策略 π \pi π取参数 θ \theta θ的情况下,跟环境做一个回合得到的总回报的期望为:
R θ ‾ = ∑ τ π θ ( τ ) ∗ R ( τ ) = E τ ∼ π θ R ( τ ) (6) \tag{6} \begin{aligned} \overline{R_\theta}&=\sum_{\tau}\pi_\theta(\tau)*R(\tau) \\ &=E_{\tau \sim\pi_{\theta}}R(\tau) \end{aligned} Rθ=τ∑πθ(τ)∗R(τ)=Eτ∼πθR(τ)(6)
有些地方也将求和写出积分的形式,求和其实就是积分的一种特殊情况
R θ ‾ = ∫ π θ ( τ ) ∗ R ( τ ) d τ = E τ ∼ π θ R ( τ ) (6.1) \tag {6.1} \begin{aligned} \overline{R_\theta}&=\int \pi_\theta(\tau)*R(\tau) d\tau \\ &=E_{\tau \sim\pi_{\theta}}R(\tau) \end{aligned} Rθ=∫πθ(τ)∗R(τ)dτ=Eτ∼πθR(τ)(6.1)
其中 E τ ∼ π θ ( τ ) R ( τ ) E_{\tau \sim\pi_{\theta}(\tau)}R(\tau) Eτ∼πθ(τ)R(τ)对于每个行动轨迹 τ \tau τ在 π θ ( τ ) \pi_{\theta}(\tau) πθ(τ)概率分布下行动轨迹得到的总回报 R R R的期望
则我们的优化目标是,找到一组 θ \theta θ使得智能体跟环境进行一个回合的总回报期望值最大:
θ ∗ = a r g m a x θ R θ ‾ (7) \tag 7 \theta^*=\underset{\theta}{argmax} \kern{1em} {\overline{R_\theta}} θ∗=θargmaxRθ(7)
那么怎么求得这个最优的 θ \theta θ呢,就需要使用梯度下降的办法来求解,则先求 R θ ‾ \overline{R_\theta} Rθ对 θ \theta θ的偏导数,也就是参数 θ \theta θ的梯度(这里的 θ \theta θ是一组参数向量,不是一个标量)
▽ θ R θ ‾ = ▽ θ ∑ τ π θ ( τ ) ∗ R ( τ ) = ∑ τ ▽ θ π θ ( τ ) ∗ R ( τ ) (8) \tag 8 \begin{aligned} \triangledown_{\theta} {\overline{R_\theta}}&=\triangledown_{\theta} \sum_{\tau}\pi_\theta(\tau)*R(\tau) \\ &=\sum_{\tau}\triangledown_{\theta} \pi_\theta(\tau)*R(\tau) \end{aligned} ▽θRθ=▽θτ∑πθ(τ)∗R(τ)=τ∑▽θπθ(τ)∗R(τ)(8)
又,由复合函数求导可知
▽ θ l o g π θ ( τ ) = 1 π θ ( τ ) ∗ ▽ θ π θ ( τ ) ⇒ ▽ θ π θ ( τ ) = π θ ( τ ) ∗ ▽ θ l o g π θ ( τ ) (9) \tag 9 \triangledown_{\theta} log{\pi_{\theta}(\tau)} = {1 \over {\pi_\theta(\tau)}}*\triangledown_{\theta} \pi_{\theta}(\tau) \\ \kern{1em}\\ \rArr \triangledown_{\theta} \pi_{\theta}(\tau) = \pi_{\theta}(\tau)* \triangledown_{\theta} log{\pi_{\theta}(\tau)} ▽θlogπθ(τ)=πθ(τ)1∗▽θπθ(τ)⇒▽θπθ(τ)=πθ(τ)∗▽θlogπθ(τ)(9)
由 ( 8 ) ( 9 ) (8)(9) (8)(9)可得:
▽ θ R θ ‾ = ∑ τ ▽ θ π θ ( τ ) ∗ R ( τ ) = ∑ τ π θ ( τ ) ∗ ▽ θ l o g π θ ( τ ) ∗ R ( τ ) = E τ ∼ π θ ( τ ) ▽ θ l o g π θ ( τ ) ∗ R ( τ ) (10) \tag {10} \begin{aligned} \triangledown_{\theta} {\overline{R_\theta}}&=\sum_{\tau}\triangledown_{\theta} \pi_\theta(\tau)*R(\tau) \\ &=\sum_{\tau} \pi_{\theta}(\tau)* \triangledown_{\theta} log{\pi_{\theta}(\tau)}*R(\tau) \\ &=E_{\tau \sim \pi_{\theta}(\tau)} \triangledown_{\theta} log{\pi_{\theta}(\tau)}*R(\tau) \end{aligned} ▽θRθ=τ∑▽θπθ(τ)∗R(τ)=τ∑πθ(τ)∗▽θlogπθ(τ)∗R(τ)=Eτ∼πθ(τ)▽θlogπθ(τ)∗R(τ)(10)
从 ( 10 ) (10) (10)式可以看出,总回报的期望的梯度,其实就是每个轨迹 τ \tau τ在 π θ ( τ ) \pi_{\theta}(\tau) πθ(τ)概率分布下 ▽ θ l o g π θ ( τ ) \triangledown_{\theta} log{\pi_{\theta}(\tau)} ▽θlogπθ(τ)的期望
然后我们再来求解 ▽ l o g π θ ( τ ) \triangledown log{\pi_{\theta}(\tau)} ▽logπθ(τ)
l o g π θ ( τ ) = l o g [ p ( s 1 ) ∗ ∏ t = 1 T π θ ( a t ∣ s t ) ∗ p ( s t + 1 ∣ s t , a t ) ] = l o g [ p ( s 1 ) ] + ∑ t = 1 T l o g [ π θ ( a t ∣ s t ) ] + ∑ t = 1 T l o g [ p ( s t + 1 ∣ s t , a t ) ] (11) \tag{11} \begin{aligned} log{\pi_{\theta}(\tau)} &= log[p(s_1)*\prod_{t=1}^T\pi_\theta(a_t|s_t)*p(s_{t+1}|s_t,a_t)] \\ &=log[p(s_1)] + \sum_{t=1}^Tlog[\pi_{\theta}(a_t|s_t)] + \sum_{t=1}^Tlog[p(s_{t+1}|s_t,a_t)] \\ \end{aligned} logπθ(τ)=log[p(s1)∗t=1∏Tπθ(at∣st)∗p(st+1∣st,at)]=log[p(s1)]+t=1∑Tlog[πθ(at∣st)]+t=1∑Tlog[p(st+1∣st,at)](11)
由 ( 11 ) (11) (11)式可以看出,对参数 θ \theta θ求梯度, l o g [ p ( s 1 ) ] log[p(s_1)] log[p(s1)]和 ∑ t = 1 T l o g [ p ( s t + 1 ∣ s t , a t ) ] \sum_{t=1}^Tlog[p(s_{t+1}|s_t,a_t)] ∑t=1Tlog[p(st+1∣st,at)]都是跟参数 θ \theta θ没有关系的,因此求导为 0 0 0,因此得到如下式子:
▽ θ l o g π θ ( τ ) = l o g [ p ( s 1 ) ] + ∑ t = 1 T ▽ θ l o g [ π θ ( a t ∣ s t ) ] + ∑ t = 1 T l o g [ p ( s t + 1 ∣ s t , a t ) ] (12) \tag{12} \begin{aligned} \triangledown_{\theta} log{\pi_{\theta}(\tau)}=&\xcancel{log[p(s_1)]} + \sum_{t=1}^T\triangledown_{\theta}log[\pi_{\theta}(a_t|s_t)] + \xcancel{\sum_{t=1}^Tlog[p(s_{t+1}|s_t,a_t)]} \\ \end{aligned} ▽θlogπθ(τ)=log[p(s1)] +t=1∑T▽θlog[πθ(at∣st)]+t=1∑Tlog[p(st+1∣st,at)] (12)
由 ( 5 ) ( 10 ) ( 12 ) (5)(10)(12) (5)(10)(12)式可以得到最终目标函数的梯度为:
▽ θ J ( θ ) = ▽ θ R θ ‾ = E τ ∼ π θ ( τ ) { ∑ t = 1 T ▽ θ l o g [ π θ ( a t ∣ s t ) ] } ∗ { ∑ t = 1 T r ( s t , a t ) } (13) \tag{13} \triangledown_{\theta}J(\theta)=\triangledown_{\theta} \overline{R_{\theta}}=E_{\tau \sim \pi_{\theta}(\tau)}\{\sum_{t=1}^T \triangledown_{\theta}log[\pi_{\theta}(a_t|s_t)]\}*\{\sum_{t=1}^Tr(s_t,a_t)\} ▽θJ(θ)=▽θRθ=Eτ∼πθ(τ){t=1∑T▽θlog[πθ(at∣st)]}∗{t=1∑Tr(st,at)}(13)
其实 R θ ‾ \overline{R_{\theta}} Rθ就是我们的目标函数 J ( θ ) J(\theta) J(θ),由于 E τ ∼ π θ ( τ ) { ∑ t = 1 T ▽ θ l o g [ π θ ( a t ∣ s t ) ] } ∗ { ∑ t = 1 T r ( s t , a t ) } E_{\tau \sim \pi_{\theta}(\tau)}\{\sum_{t=1}^T \triangledown_{\theta}log[\pi_{\theta}(a_t|s_t)]\}*\{\sum_{t=1}^Tr(s_t,a_t)\} Eτ∼πθ(τ){∑t=1T▽θlog[πθ(at∣st)]}∗{∑t=1Tr(st,at)}是 { ∑ t = 1 T ▽ θ l o g [ π θ ( a t ∣ s t ) ] } ∗ { ∑ t = 1 T r ( s t , a t ) } \{\sum_{t=1}^T \triangledown_{\theta}log[\pi_{\theta}(a_t|s_t)]\}*\{\sum_{t=1}^Tr(s_t,a_t)\} {∑t=1T▽θlog[πθ(at∣st)]}∗{∑t=1Tr(st,at)}的期望值,则实际操作过程中需要采样多个策略轨迹 τ i \tau_i τi进行期望的计算,比如我们采样数量为n个,则上面 ( 13 ) (13) (13)式可以写为:
▽ θ J ( θ ) = ▽ θ R θ ‾ = E τ ∼ π θ ( τ ) { ∑ t = 1 T ▽ θ l o g [ π θ ( a t ∣ s t ) ] } ∗ { ∑ t = 1 T r ( s t , a t ) } = 1 n ∑ i = 1 n [ ( ∑ t = 1 T ▽ θ l o g [ π θ ( a i t ∣ s i t ) ] ) ∗ ( ∑ t = 1 T r ( s i t , a i t ) ) ] (14) \tag{14} \begin{aligned} \triangledown_{\theta}J(\theta)=\triangledown_{\theta} \overline{R_{\theta}}&=E_{\tau \sim \pi_{\theta}(\tau)}\{\sum_{t=1}^T \triangledown_{\theta}log[\pi_{\theta}(a_t|s_t)]\}*\{\sum_{t=1}^Tr(s_t,a_t)\} \\ &={1 \over n}\sum_{i=1}^n [(\sum_{t=1}^T \triangledown_{\theta}log[\pi_{\theta}(a_{it}|s_{it})])*(\sum_{t=1}^Tr(s_{it},a_{it}))] \end{aligned} ▽θJ(θ)=▽θRθ=Eτ∼πθ(τ){t=1∑T▽θlog[πθ(at∣st)]}∗{t=1∑Tr(st,at)}=n1i=1∑n[(t=1∑T▽θlog[πθ(ait∣sit)])∗(t=1∑Tr(sit,ait))](14)
那么我们就可以利用这个梯度对 θ \theta θ进行更新
θ ∗ ← θ + α ▽ θ J ( θ ) (15) \tag{15} \theta^* \larr \theta + \alpha \triangledown_{\theta}J(\theta) θ∗←θ+α▽θJ(θ)(15)
其中 α \alpha α为学习率
那么运用到深度学习当中应该怎么使用呢?我们可以搭建一个神经网络,输入为状态 s s s,输出为每个动作 a a a的可能概率,而我们的损失函数则可以直接取 − l o g [ π θ ( a t ∣ s t ) ] ∗ R ( τ ) -log[\pi_{\theta}(a_t|s_t)] * R(\tau) −log[πθ(at∣st)]∗R(τ),因为神经网络只能进行梯度递减,因此 l o g log log前面多了一个负号,另外,应为跟 R ( τ ) R(\tau) R(τ)有关,所以策略梯度求解,只能每个回合结束后进行参数更新,这个跟Value-base方法有区别。
L ( θ ) = − l o g [ π θ ( a t ∣ s t ) ] ∗ R ( τ ) (16) \tag{16} L(\theta)=-log[\pi_{\theta}(a_t|s_t)] * R(\tau) L(θ)=−log[πθ(at∣st)]∗R(τ)(16)
从公式来看,当 R ( τ ) R(\tau) R(τ)大的时候,因为 − l o g x -logx −logx是单调递减函数,则 π θ ( a t ∣ s t ) \pi_{\theta}(a_t|s_t) πθ(at∣st)需要增大才行能使总的 L ( θ ) L(\theta) L(θ)越小,同理,当 R ( τ ) R(\tau) R(τ)越小,则需要 π θ ( a t ∣ s t ) \pi_{\theta}(a_t|s_t) πθ(at∣st)越小,这样就可以增大有价值的动作概率,减小没有价值的动作概率。
代码实例:
手动实现一个迷宫探宝游戏,智能体(蓝色方块)随机出现在地图中的某个位置,并且在地图中放一个或者多个宝藏(红色方块),并且设置多个陷阱(黑色方块),智能体可以向周围8个方向移动,最终取得宝藏为目标。
代码和截图如下:
定义通用的游戏接口abstract_kernel.py
import abc
class AbstractPlayer(object):
"""
玩家
"""
def __init__(self):
"""
初始化
"""
pass
@abc.abstractmethod
def reinforce(self, observation, action, reward, done, info):
"""
经验增强
:param observation: 环境观测
:param action: 环境观测执行的动作
:param reward: 反馈
:param done:
:param info: 其他信息
:return:
"""
pass
@abc.abstractmethod
def decide(self, observation):
"""
观测到环境后,进行动作决策
:param observation: 观测到的环境
:return:
"""
pass
class AbstractGame(object):
"""
定义所有验证游戏平台的统一接口
"""
def __init__(self, rf=None, episodes=1):
"""
初始化
:param rf: 奖励函数
:param episodes: 尝试次数
"""
self._rf = rf
self._episodes = episodes
@abc.abstractmethod
def start(self):
"""
开始游戏
:return:
"""
pass
class AbstractGameUI(object):
"""
游戏的UI界面
"""
def __init__(self, game):
"""
于某个游戏绑定
:param game: 需要绑定的游戏
"""
self._game = game
@abc.abstractmethod
def show(self):
"""
开始展示
:return:
"""
pass
实现迷宫探宝游戏maze_kernel.py
import numpy as np
import sys
import pygame
from games.abstract_kernel import *
class Game(AbstractGame):
"""
迷宫
"""
def __init__(self, player, start_func, golds_func, traps_func=None,
scene_size=(10, 10), max_step=0, **kwargs):
"""
初始化
:param player: 玩家
:param start_func: 出生地生成函数
:param golds_func: 宝藏生成函数
:param traps_func: 陷阱生成函数
:param scene_size: 场地大小
:param max_step: 最大步数
:param kwargs:
"""
super().__init__(**kwargs)
# ************* 配置参数 ***************
self.__player = player
self.__golds_func = golds_func
self.__traps_func = traps_func
self.__start_func = start_func
self.__scene_size = scene_size
if max_step > 0:
self.__max_step = max_step
else:
self.__max_step = (self.__scene_size[0] + self.__scene_size[1])
# 设置默认的奖励函数
if self._rf is None:
self._rf = self.__default_reward_function
# ************* 常数定义 ***************
self.__actions = {
0: (-1, 0), # 上
1: (0, 1), # 右
2: (1, 0), # 下
3: (0, -1), # 左
4: (-1, -1), # 左上
5: (-1, 1), # 右上
6: (1, 1), # 右下
7: (1, -1) # 左下
}
# ************* 运行参数 ***************
# 初始化场景
self.__env = np.zeros(self.__scene_size)
# 当前尝试次数
self.__episode = 0
# 当前智能体位置
self.__p = [0, 0]
def start(self):
"""
开始游戏
:return:
"""
while self.__episode < self._episodes:
# 记录场次
self.__episode += 1
self.__env = np.zeros(self.__scene_size)
# 初始化场景,获取宝藏位置
golds_locations = self.__golds_func()
if golds_locations is None or len(golds_locations) == 0: return
for location in golds_locations:
self.__env[location[0], location[1]] = 1
# 初始化场景,获取陷阱位置
if self.__traps_func is not None:
trap_locations = self.__traps_func()
if trap_locations is not None and len(trap_locations) > 0:
for location in trap_locations:
if self.__env[location[0], location[1]] == 1: continue
self.__env[location[0], location[1]] = -1
# 初始化智能体的出生位置
self.__p = self.__start_func()
# 记录总步数
step = 0
while True:
# 步数加1
step += 1
# 取得一个决策
action = self.__player.decide([np.copy(self.__env), np.copy(self.__p)])
# 评价动作
reward, done, win = self._rf([np.copy(self.__env), np.copy(self.__p)], action, step)
# 反馈信息
self.__player.reinforce([np.copy(self.__env), np.copy(self.__p)], action, reward, done, win)
if done: break
# 执行动作
self.__p = self.__p + self.__actions.get(action)
def get_env(self):
"""
获取环境样式
:return:
"""
return [np.copy(self.__env), np.copy(self.__p)]
def __default_reward_function(self, s, a, step):
"""
默认的奖励函数
:param s: 环境
:param a: 动作
:param step: 总步数
:return:
"""
# 得到环境和智能体位置
env, p = s[0], s[1]
# 执行前的最短距离
d = self.__min_distance_for_gold(env, p)
# 模拟执行动作
n_p = p + self.__actions.get(a)
if n_p[0] < 0 or n_p[1] < 0 or n_p[0] > self.__scene_size[0] - 1 or n_p[1] > self.__scene_size[1] - 1 or step >= self.__max_step:
# 出界
reward, done, info = -100 - d, True, False
else:
# 判断是否拿到宝藏
if env[n_p[0], n_p[1]] == 1:
reward, done, info = 100, True, True
elif env[n_p[0], n_p[1]] == -1:
reward, done, info = -100 - d, True, False
else:
# 计算距离差值
n_d = self.__min_distance_for_gold(env, n_p)
reward, done, info = d - n_d, False, False
return reward, done, info
def __min_distance_for_gold(self, env, p):
"""
智能体距离宝藏最近的距离
:param s: 环境
:return:
"""
# 宝藏位置
golds = np.array(np.where(env == 1)).transpose()
min_distance = sys.maxsize
for g in golds:
# 计算距离
distance = ((p[0] - g[0]) ** 2 + (p[1] - g[1]) ** 2) ** 0.5
if distance < min_distance: min_distance = distance
return min_distance
class GameUI(AbstractGameUI):
"""
UI展示
"""
def __init__(self, game, cell_size=20):
"""
初始化UI
:param game: 游戏
:param cell_size: 单元格尺寸大小
"""
super().__init__(game)
self.__cell_size = cell_size
def show(self):
"""
显示
:return:
"""
pygame.init()
pygame.font.init()
# 创建一个窗口
size = self._game.get_env()[0].shape
size = [size[0] * self.__cell_size, size[1] * self.__cell_size]
screen = pygame.display.set_mode(size)
# 设置窗口标题
pygame.display.set_caption("Do Something")
while True:
# 处理事件监听
for event in pygame.event.get():
if event.type == pygame.QUIT:
print('exit game......')
pygame.quit()
# 清理历史图像
screen.fill((255, 255, 255))
env, p = self._game.get_env()
# 绘制游戏画面
for row in range(len(env)):
# 绘制行直线
pygame.draw.line(screen, (0, 0, 0), (0, self.__cell_size * row), (size[0], self.__cell_size * row), 1)
for column in range(len(env[row])):
# 绘制列
pygame.draw.line(screen, (0, 0, 0), (self.__cell_size * column, 0), (self.__cell_size * column, size[1]), 1)
# 绘制宝藏
if env[row, column] == 1:
pygame.draw.rect(screen, (220, 20, 60), [self.__cell_size * column, self.__cell_size * row, self.__cell_size, self.__cell_size], 0)
# 绘制陷阱
if env[row, column] == -1:
pygame.draw.rect(screen, (0, 0, 0), [self.__cell_size * column, self.__cell_size * row, self.__cell_size, self.__cell_size], 0)
# 绘制当前智能体位置
if row == p[0] and column == p[1]:
pygame.draw.rect(screen, (30, 144, 255), [self.__cell_size * column, self.__cell_size * row, self.__cell_size, self.__cell_size], 0)
# 设置当前的概率值
# to do
# 设置时钟
pygame.time.Clock().tick(24)
pygame.display.update()
采用随机策略梯度测试代码,pg.py:
"""
采用随机策略梯度进行最优解逼近
"""
import tensorflow as tf
import os
import time
import tensorflow.python.keras.backend as K
from rl.games.maze.maze_kernel import *
class Player(AbstractPlayer):
"""
采用随机策略梯度进行问题的求解
"""
def __init__(self, alpha=0.02, gamma=0.9, think_time=0.1, prob_file=None):
"""
初始化
:param alpha: 学习率
:param gamma: 反馈值衰减系数
:param think_time: 思考时间
:param prob_file: 模型保存文件
"""
super().__init__()
# ********** 配置参数 ********
self.alpha = alpha
self.gamma = gamma
self.think_time = think_time
self.prob_file = prob_file
# ********** 运行参数 ********
# 参数概率表
self.prob = None
if self.prob_file is not None and os.path.exists(self.prob_file):
self.prob = tf.Variable(tf.constant(np.load(self.prob_file, allow_pickle=False)))
# 得分记录
self.record = [0, 0]
# 轨迹记录
self.observations, self.actions, self.rewards = [], [], []
# 参数优化器
self.optimizer = tf.keras.optimizers.Adam(self.alpha)
def decide(self, observation):
"""
进行决策
:param observation:
:return:
"""
if self.prob is None:
self.prob = tf.constant(np.zeros(shape=(observation[0].shape[0], observation[0].shape[1], 8)))
self.prob = tf.Variable(self.prob)
time.sleep(self.think_time)
# 得到agent的位置信息
agent = observation[1]
# 得到得分值
vt = self.prob[agent[0], agent[1]]
# 通过softmax将概率归一化
p = K.softmax(vt, axis=0)
# 根据概率选择决策,随机策略梯度
action = np.random.choice([0, 1, 2, 3, 4, 5, 6, 7], size=1, p=p)[0]
return action
def reinforce(self, observation, action, reward, done, info):
"""
增强学习
:param observation:
:param action:
:param reward:
:param done:
:param info:
:return:
"""
self.observations.append(observation)
self.actions.append(action)
self.rewards.append(reward)
if done:
self.optimizer.minimize(self.loss, [self.prob])
# 记录一波Q值
if self.prob_file is not None:
np.save(self.prob_file, self.prob.numpy())
# 记录
if info:
self.record[0] += 1
else:
self.record[1] += 1
print(self.record)
def loss(self):
"""
更新策略
:return:
"""
# 计算每一个step的策略梯度
vt = np.zeros(self.prob.shape)
# 循环每一个step进行梯度计算
for step in range(len(self.observations)):
agent = self.observations[step][1]
action = self.actions[step]
R = 0
for i in range(step, len(self.rewards)):
R = R + self.rewards[i] * (self.gamma ** (i - step))
vt[agent[0], agent[1], action] += R
# 采用softmax进行概率归一化
prob = K.softmax(self.prob)
# 计算loss
loss = -K.log(prob)
# 乘以vt值
loss = loss * vt
loss = K.sum(loss)
self.observations, self.actions, self.rewards = [], [], []
return loss
def start_func():
return np.array([np.random.randint(0, 19), np.random.randint(0, 19)])
# def start_func():
# return np.array([0, 0])
def golds_func():
return np.array([
[19, 19]
])
def traps_func():
return np.array([
[6, 6],
[9, 12],
[4, 3],
[13, 14],
[17, 4],
[3, 14],
[6, 3],
[1, 12],
[14, 3],
[1, 4],
[17, 14],
[19, 18],
[10, 9],
[8, 3],
[6, 12],
[9, 11],
[11, 4],
[15, 14],
[17, 17],
])
import threading
if __name__ == '__main__':
# 创建玩家
player = Player(think_time=0.1, gamma=0.65, prob_file=os.path.sep.join([os.path.dirname(__file__), 'pg.npy']))
# 创建游戏
game = Game(player, episodes=sys.maxsize, scene_size=(20, 20), traps_func=traps_func, start_func=start_func,
golds_func=golds_func)
# 创建ui
ui = GameUI(game)
# 开始游戏
t = threading.Thread(target=ui.show, args=())
t.start()
game.start()
最终运行结果:
 控制台会打印成功和失败的尝试数量,刚开始的时候会很慢,可以将think_time设置成0.001或者去掉思考时间,大概总尝试次数达到5000次的时候,智能体的成功率会明显提升上来。
控制台会打印成功和失败的尝试数量,刚开始的时候会很慢,可以将think_time设置成0.001或者去掉思考时间,大概总尝试次数达到5000次的时候,智能体的成功率会明显提升上来。
实例中所有的陷阱和宝藏都是固定的,因此观测其实只需要参考agent的当前位置就可以得到最优解,如果宝藏和陷阱式动态的,那么则需要将整个迷宫的布局信息加入到优化函数中,我们可以采用一个神经网络来拟合,输入就是迷宫当前陷阱和宝藏位置,以及agent的当前位置,输出也是agent各个方向的概率,这样agent就可以在动态的迷宫中避开陷阱并最终拿到宝藏。