[十六]深度学习Pytorch-18种损失函数loss function
0. 往期内容
[一]深度学习Pytorch-张量定义与张量创建
[二]深度学习Pytorch-张量的操作:拼接、切分、索引和变换
[三]深度学习Pytorch-张量数学运算
[四]深度学习Pytorch-线性回归
[五]深度学习Pytorch-计算图与动态图机制
[六]深度学习Pytorch-autograd与逻辑回归
[七]深度学习Pytorch-DataLoader与Dataset(含人民币二分类实战)
[八]深度学习Pytorch-图像预处理transforms
[九]深度学习Pytorch-transforms图像增强(剪裁、翻转、旋转)
[十]深度学习Pytorch-transforms图像操作及自定义方法
[十一]深度学习Pytorch-模型创建与nn.Module
[十二]深度学习Pytorch-模型容器与AlexNet构建
[十三]深度学习Pytorch-卷积层(1D/2D/3D卷积、卷积nn.Conv2d、转置卷积nn.ConvTranspose)
[十四]深度学习Pytorch-池化层、线性层、激活函数层
[十五]深度学习Pytorch-权值初始化
[十六]深度学习Pytorch-18种损失函数loss function
深度学习Pytorch-损失函数loss
- 0. 往期内容
- 1. 损失函数概念
- 2. 18种损失函数
-
- 2.1 CrossEntropyLoss(weight=None, ignore_index=- 100, reduction='mean')
- 2.2 nn.NLLLoss(weight=None, ignore_index=- 100, reduction='mean')
- 2.3 nn.BCELoss(weight=None, reduction='mean')
- 2.4 nn.BCEWithLogitsLoss(weight=None, reduction='mean', pos_weight=None)
- 2.5 & 2.6 nn.L1Loss(reduction='mean') & nn.MSELoss(reduction='mean')
- 2.7 nn.SmoothL1Loss(reduction='mean')
- 2.8 nn.PoissonNLLLoss(log_input=True, full=False, eps=1e-08, reduction='mean')
- 2.9 nn.KLDivLoss(reduction='mean')
- 2.10 nn.MarginRankingLoss(margin=0.0, reduction='mean')
- 2.11 nn.MultiLabelMarginLoss(reduction='mean')
- 2.12 nn.SoftMarginLoss(reduction='mean')
- 2.13 nn.MultiLabelSoftMarginLoss(reduction='mean')
- 2.14 nn.MultiMarginLoss(p=1, margin=1.0, weight=None, reduction='mean')
- 2.15 nn.TripletMarginLoss(margin=1.0, p=2.0, eps=1e-06, reduction='mean')
- 2.16 nn.HingeEmbeddingLoss(margin=1.0, reduction='mean')
- 2.17 nn.CosineEmbeddingLoss(margin=0.0, reduction='mean')
- 2.18 nn.CTCLoss(blank=0, reduction='mean')
- 3. 完整代码
1. 损失函数概念
![[十六]深度学习Pytorch-18种损失函数loss function_第1张图片](http://img.e-com-net.com/image/info8/b1843897b347490f9aed41c0617e5c34.jpg)
regularization-正则化
![[十六]深度学习Pytorch-18种损失函数loss function_第2张图片](http://img.e-com-net.com/image/info8/805e8f154d79434dbb33add7d6a8acd8.jpg)
2. 18种损失函数
2.1 CrossEntropyLoss(weight=None, ignore_index=- 100, reduction=‘mean’)
CrossEntropyLoss(weight=None, size_average=None, ignore_index=- 100, reduce=None, reduction='mean', label_smoothing=0.0)
交叉熵损失函数并不是公式意义上的交叉熵计算,而是有不同之处。它采用softmax对数据进行了归一化,把数据值归一化到概率输出的形式。交叉熵损失函数常常用于分类任务中。交叉熵是衡量两个概率分布之间的差异,交叉熵值越低,表示两个概率分布越近。
![[十六]深度学习Pytorch-18种损失函数loss function_第3张图片](http://img.e-com-net.com/image/info8/56e8c899447240f78f0c2c5bd0dbf0d7.jpg)
(1)熵用来描述一个事件的不确定性,不确定性越大则熵越大.
(2)信息熵是自信息的期望,自信息用于衡量单个输出单个事件的不确定性.
(3)相对熵又叫做KL散度,用于衡量两个分布之间的差异,即两个分布之间的距离,但不是距离的函数,不具备对称性。P是真实的分布,Q是模型输出的分布,Q需要逼近、拟合P的分布.
(4)交叉熵用于衡量两个分布之间的相似度.
(5)P是真实的分布,即训练集中样本的分布。由于训练集是固定的,概率分布也是固定的,H(P)是个常数.
![[十六]深度学习Pytorch-18种损失函数loss function_第4张图片](http://img.e-com-net.com/image/info8/2566067dd3c44b39a47e48cd71dd956c.jpg)
p(xi)=1,则可以转换为如下:
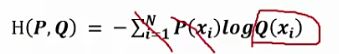
需要将Q(xi)概率值归一化:
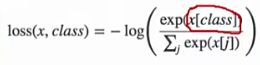
代码示例:
# fake data
#二分类任务,输出神经元2个,batchsize是3,即三个样本:[1,2] [1,3] [1,3]
inputs = torch.tensor([[1, 2], [1, 3], [1, 3]], dtype=torch.float)
#dtype必须是long,有多少个样本,tensor(1D)就有多长。
target = torch.tensor([0, 1, 1], dtype=torch.long)
# ----------------------------------- CrossEntropy loss: reduction -----------------------------------
flag = 0
# flag = 1
if flag:
# def loss function
loss_f_none = nn.CrossEntropyLoss(weight=None, reduction='none')
loss_f_sum = nn.CrossEntropyLoss(weight=None, reduction='sum')
loss_f_mean = nn.CrossEntropyLoss(weight=None, reduction='mean')
# forward
loss_none = loss_f_none(inputs, target)
loss_sum = loss_f_sum(inputs, target)
loss_mean = loss_f_mean(inputs, target)
# view
print("Cross Entropy Loss:\n ", loss_none, loss_sum, loss_mean)
#输出为[1.3133, 0.1269, 0.1269] 1.5671 0.5224
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
idx = 0
input_1 = inputs.detach().numpy()[idx] # [1, 2]
target_1 = target.numpy()[idx] # [0]
# 第一项
x_class = input_1[target_1]
# 第二项
sigma_exp_x = np.sum(list(map(np.exp, input_1)))
log_sigma_exp_x = np.log(sigma_exp_x)
# 输出loss
loss_1 = -x_class + log_sigma_exp_x
print("第一个样本loss为: ", loss_1)
# ----------------------------------- weight -----------------------------------
flag = 0
# flag = 1
if flag:
# def loss function
#有多少个类别weights这个向量就要设置多长
weights = torch.tensor([1, 2], dtype=torch.float)
# weights = torch.tensor([0.7, 0.3], dtype=torch.float)
loss_f_none_w = nn.CrossEntropyLoss(weight=weights, reduction='none')
loss_f_sum = nn.CrossEntropyLoss(weight=weights, reduction='sum')
loss_f_mean = nn.CrossEntropyLoss(weight=weights, reduction='mean')
# forward
loss_none_w = loss_f_none_w(inputs, target)
loss_sum = loss_f_sum(inputs, target)
loss_mean = loss_f_mean(inputs, target)
# view
print("\nweights: ", weights)
print(loss_none_w, loss_sum, loss_mean)
#权值为[1,2],则输出[1.3133, 0.2539, 0.2539] 1.8210 0.3642
# target=[0,1,1]所以对应0的需要乘以权值1,对应1的需要乘以权值2.
# 1.3133是1.3133*1=1.3133,0.2530是0.1269*2=0.2539,0.2530是0.1269*2=0.2539.
#0.3642是1.8210/(1+2+2)=0.3642,分母是权值的份数(5).
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
weights = torch.tensor([1, 2], dtype=torch.float)
#weights_all=5
weights_all = np.sum(list(map(lambda x: weights.numpy()[x], target.numpy()))) # [0, 1, 1] ---> # [1 2 2]
mean = 0
loss_sep = loss_none.detach().numpy()
for i in range(target.shape[0]):
x_class = target.numpy()[i]
tmp = loss_sep[i] * (weights.numpy()[x_class] / weights_all)
mean += tmp
print(mean)
官网示例:
![[十六]深度学习Pytorch-18种损失函数loss function_第5张图片](http://img.e-com-net.com/image/info8/70d1d352a99044bfb24d00546e699f4f.jpg)
# Example of target with class indices,此时target为1D,长度为batchsize的大小
loss = nn.CrossEntropyLoss()
input = torch.randn(3, 5, requires_grad=True)
target = torch.empty(3, dtype=torch.long).random_(5)
output = loss(input, target)
output.backward()
# Example of target with class probabilities,此时target的形状与input一致
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5).softmax(dim=1)
output = loss(input, target)
output.backward()
2.2 nn.NLLLoss(weight=None, ignore_index=- 100, reduction=‘mean’)
nn.NLLLoss(weight=None, size_average=None, ignore_index=- 100, reduce=None, reduction='mean')
![[十六]深度学习Pytorch-18种损失函数loss function_第6张图片](http://img.e-com-net.com/image/info8/25b2ccceebe54c8d845f04bc08e7fdca.jpg)
代码示例:
# fake data
#二分类任务,输出神经元2个,batchsize是3,即三个样本:[1,2] [1,3] [1,3]
inputs = torch.tensor([[1, 2], [1, 3], [1, 3]], dtype=torch.float)
#dtype必须是long,有多少个样本,tensor(1D)就有多长。
target = torch.tensor([0, 1, 1], dtype=torch.long)
# ----------------------------------- 2 NLLLoss -----------------------------------
flag = 0
# flag = 1
if flag:
weights = torch.tensor([1, 1], dtype=torch.float)
loss_f_none_w = nn.NLLLoss(weight=weights, reduction='none')
loss_f_sum = nn.NLLLoss(weight=weights, reduction='sum')
loss_f_mean = nn.NLLLoss(weight=weights, reduction='mean')
# forward
loss_none_w = loss_f_none_w(inputs, target)
loss_sum = loss_f_sum(inputs, target)
loss_mean = loss_f_mean(inputs, target)
# view
print("\nweights: ", weights)
print("NLL Loss", loss_none_w, loss_sum, loss_mean)
#输出[-1,-3,-3] -7 -2.3333
# target[0, 1, 1]
#-1是因为第一个样本[1,2]是第0类,因此只对第一个神经元输出操作:-1*1。
#-3是因为第二个样本[1,3]是第1类,因此只对第二个神经元输出操作:-1*3。
#-3是因为第三个样本[1,3]是第1类,因此只对第二个神经元输出操作:-1*3。
#求mean时的分母是权重weight的和。
官方示例:
![[十六]深度学习Pytorch-18种损失函数loss function_第7张图片](http://img.e-com-net.com/image/info8/a694e9fcc06d4ee49b44f417e6420851.jpg)
m = nn.LogSoftmax(dim=1)
loss = nn.NLLLoss()
# input is of size N x C = 3 x 5
input = torch.randn(3, 5, requires_grad=True)
# each element in target has to have 0 <= value < C
target = torch.tensor([1, 0, 4])
output = loss(m(input), target)
output.backward()
# 2D loss example (used, for example, with image inputs)
N, C = 5, 4
loss = nn.NLLLoss()
# input is of size N x C x height x width
data = torch.randn(N, 16, 10, 10)
conv = nn.Conv2d(16, C, (3, 3))
m = nn.LogSoftmax(dim=1)
# each element in target has to have 0 <= value < C
target = torch.empty(N, 8, 8, dtype=torch.long).random_(0, C)
output = loss(m(conv(data)), target)
output.backward()
2.3 nn.BCELoss(weight=None, reduction=‘mean’)
nn.BCELoss(weight=None, size_average=None, reduce=None, reduction='mean')
![[十六]深度学习Pytorch-18种损失函数loss function_第8张图片](http://img.e-com-net.com/image/info8/b122673f927e4baaa2239040f0f28bc3.jpg)
注意事项:输入值取值在[0,1]
xn是模型输出的概率取值,yn是标签(二分类中对应0或1)。
代码示例:
# ----------------------------------- 3 BCE Loss -----------------------------------
flag = 0
# flag = 1
if flag:
inputs = torch.tensor([[1, 2], [2, 2], [3, 4], [4, 5]], dtype=torch.float) #4个样本
target = torch.tensor([[1, 0], [1, 0], [0, 1], [0, 1]], dtype=torch.float) #float类型,每个神经元一一对应去计算loss
target_bce = target
# itarget
#一定要加上sigmoid,将输入值取值在[0,1]区间
inputs = torch.sigmoid(inputs)
weights = torch.tensor([1, 1], dtype=torch.float)
loss_f_none_w = nn.BCELoss(weight=weights, reduction='none')
loss_f_sum = nn.BCELoss(weight=weights, reduction='sum')
loss_f_mean = nn.BCELoss(weight=weights, reduction='mean')
# forward
loss_none_w = loss_f_none_w(inputs, target_bce)
loss_sum = loss_f_sum(inputs, target_bce)
loss_mean = loss_f_mean(inputs, target_bce)
# view
print("\nweights: ", weights)
print("BCE Loss", loss_none_w, loss_sum, loss_mean)
#输出[[0.3133, 2.1269], [0.1269, 2.1269], [3.0486, 0.0181], [4.0181, 0.0067]] 11.7856 1.4732
#每个神经元一一对应去计算loss,因此loss个数是2*4=8个
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
idx = 0
x_i = inputs.detach().numpy()[idx, idx]
y_i = target.numpy()[idx, idx] #
# loss
# l_i = -[ y_i * np.log(x_i) + (1-y_i) * np.log(1-y_i) ] # np.log(0) = nan
l_i = -y_i * np.log(x_i) if y_i else -(1-y_i) * np.log(1-x_i)
# 输出loss
print("BCE inputs: ", inputs)
print("第一个loss为: ", l_i) #0.3133
一定要加上sigmoid,将输入值取值在[0,1]区间。
官网示例:
![[十六]深度学习Pytorch-18种损失函数loss function_第9张图片](http://img.e-com-net.com/image/info8/c098731f2cbb4f69a474d3d98553d2e4.jpg)
m = nn.Sigmoid()
loss = nn.BCELoss()
input = torch.randn(3, requires_grad=True)
target = torch.empty(3).random_(2)
output = loss(m(input), target)
output.backward()
2.4 nn.BCEWithLogitsLoss(weight=None, reduction=‘mean’, pos_weight=None)
nn.BCEWithLogitsLoss(weight=None, size_average=None, reduce=None, reduction='mean', pos_weight=None)
![[十六]深度学习Pytorch-18种损失函数loss function_第10张图片](http://img.e-com-net.com/image/info8/eda2f58a4fcf4ad7aa8207f4910b1541.jpg) (1)pos_weight用于均衡正负样本,正样本的loss需要乘以pos_weight。
(1)pos_weight用于均衡正负样本,正样本的loss需要乘以pos_weight。
(2)比如正样本100个,负样本300个,此时可以将pos_weight设置为3,就可以实现正负样本均衡。
(3)pos_weight里是一个tensor列表,需要和标签个数相同,比如现在有一个多标签分类,类别有200个,那么 pos_weight 就是为每个类别赋予的权重值,长度为200
(4)如果现在是二分类,只需要将正样本loss的权重写上即可,比如我们有正负两类样本,正样本数量为100个,负样本为400个,我们想要对正负样本的loss进行加权处理,将正样本的loss权重放大4倍,通过这样的方式缓解样本不均衡问题:
criterion = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([4]))
代码示例:
# ----------------------------------- 4 BCE with Logis Loss -----------------------------------
# flag = 0
flag = 1
if flag:
inputs = torch.tensor([[1, 2], [2, 2], [3, 4], [4, 5]], dtype=torch.float)
target = torch.tensor([[1, 0], [1, 0], [0, 1], [0, 1]], dtype=torch.float)
target_bce = target
# inputs = torch.sigmoid(inputs) 不能加sigmoid!!!
weights = torch.tensor([1, 1], dtype=torch.float)
loss_f_none_w = nn.BCEWithLogitsLoss(weight=weights, reduction='none')
loss_f_sum = nn.BCEWithLogitsLoss(weight=weights, reduction='sum')
loss_f_mean = nn.BCEWithLogitsLoss(weight=weights, reduction='mean')
# forward
loss_none_w = loss_f_none_w(inputs, target_bce)
loss_sum = loss_f_sum(inputs, target_bce)
loss_mean = loss_f_mean(inputs, target_bce)
# view
print("\nweights: ", weights)
print(loss_none_w, loss_sum, loss_mean)
#输出[[0.3133, 2.1269], [0.1269, 2.1269], [3.0486, 0.0181], [4.0181, 0.0067]] 11.7856 1.4732
# --------------------------------- pos weight
# flag = 0
flag = 1
if flag:
inputs = torch.tensor([[1, 2], [2, 2], [3, 4], [4, 5]], dtype=torch.float)
target = torch.tensor([[1, 0], [1, 0], [0, 1], [0, 1]], dtype=torch.float)
target_bce = target
# itarget
# inputs = torch.sigmoid(inputs)
weights = torch.tensor([1], dtype=torch.float)
#pos_w = torch.tensor([1], dtype=torch.float) #设置为1时,loss输出与原先一致。
pos_w = torch.tensor([3], dtype=torch.float) # 3
#设置为3时会对正样本的loss乘以3,即标签是1对应的loss。
#输出[[0.3133*3, 2.1269], [0.1269*3, 2.1269], [3.0486, 0.0181*3], [4.0181, 0.0067*3]]
loss_f_none_w = nn.BCEWithLogitsLoss(weight=weights, reduction='none', pos_weight=pos_w)
loss_f_sum = nn.BCEWithLogitsLoss(weight=weights, reduction='sum', pos_weight=pos_w)
loss_f_mean = nn.BCEWithLogitsLoss(weight=weights, reduction='mean', pos_weight=pos_w)
# forward
loss_none_w = loss_f_none_w(inputs, target_bce)
loss_sum = loss_f_sum(inputs, target_bce)
loss_mean = loss_f_mean(inputs, target_bce)
# view
print("\npos_weights: ", pos_w)
print(loss_none_w, loss_sum, loss_mean)
不能加sigmoid!!!
官网示例:
![[十六]深度学习Pytorch-18种损失函数loss function_第11张图片](http://img.e-com-net.com/image/info8/4e84af76ae3b4748af34c1e10f997891.jpg)
target = torch.ones([10, 64], dtype=torch.float32) # 64 classes, batch size = 10
output = torch.full([10, 64], 1.5) # A prediction (logit)
pos_weight = torch.ones([64]) # All weights are equal to 1
criterion = torch.nn.BCEWithLogitsLoss(pos_weight=pos_weight)
criterion(output, target) # -log(sigmoid(1.5))
loss = nn.BCEWithLogitsLoss()
input = torch.randn(3, requires_grad=True)
target = torch.empty(3).random_(2)
output = loss(input, target)
output.backward()
2.5 & 2.6 nn.L1Loss(reduction=‘mean’) & nn.MSELoss(reduction=‘mean’)
nn.L1Loss(size_average=None, reduce=None, reduction='mean')
nn.MSELoss(size_average=None, reduce=None, reduction='mean')
![[十六]深度学习Pytorch-18种损失函数loss function_第12张图片](http://img.e-com-net.com/image/info8/609b4f08ef4f4d9eabe109c2e8a8763a.jpg) 代码示例:
代码示例:
![[十六]深度学习Pytorch-18种损失函数loss function_第13张图片](http://img.e-com-net.com/image/info8/c0172ab534ea4508be9d1c54ecb5d611.jpg)
# ------------------------------------------------- 5 L1 loss ----------------------------------------------
flag = 0
# flag = 1
if flag:
inputs = torch.ones((2, 2)) #2*2,数值为1
target = torch.ones((2, 2)) * 3 #2*2,数值为3
loss_f = nn.L1Loss(reduction='none')
loss = loss_f(inputs, target)
print("input:{}\ntarget:{}\nL1 loss:{}".format(inputs, target, loss))
#输出为[[2,2],[2,2]]
# ------------------------------------------------- 6 MSE loss ----------------------------------------------
loss_f_mse = nn.MSELoss(reduction='none')
loss_mse = loss_f_mse(inputs, target)
print("MSE loss:{}".format(loss_mse))
#输出为[[4,4],[4,4]]
2.7 nn.SmoothL1Loss(reduction=‘mean’)
nn.SmoothL1Loss(size_average=None, reduce=None, reduction='mean')
![[十六]深度学习Pytorch-18种损失函数loss function_第14张图片](http://img.e-com-net.com/image/info8/2e145b30249d4bbf8c47b8b12bd28ddc.jpg) 代码示例:
代码示例:
![[十六]深度学习Pytorch-18种损失函数loss function_第15张图片](http://img.e-com-net.com/image/info8/4c88069e438041b597d88b8ff980d922.jpg)
# ------------------------------------------------- 7 Smooth L1 loss ----------------------------------------------
flag = 0
# flag = 1
if flag:
inputs = torch.linspace(-3, 3, steps=500) #-3到3区间取500个数据点
target = torch.zeros_like(inputs) #数值为0,维度与inputs一致
loss_f = nn.SmoothL1Loss(reduction='none')
loss_smooth = loss_f(inputs, target)
loss_l1 = np.abs(inputs.numpy()-target.numpy())
plt.plot(inputs.numpy(), loss_smooth.numpy(), label='Smooth L1 Loss')
plt.plot(inputs.numpy(), loss_l1, label='L1 loss')
plt.xlabel('x_i - y_i')
plt.ylabel('loss value')
plt.legend()
plt.grid()
plt.show()
![[十六]深度学习Pytorch-18种损失函数loss function_第16张图片](http://img.e-com-net.com/image/info8/dc9e38adc7fe4a6e8a494dcf7a643e9d.jpg)
2.8 nn.PoissonNLLLoss(log_input=True, full=False, eps=1e-08, reduction=‘mean’)
nn.PoissonNLLLoss(log_input=True, full=False, size_average=None, eps=1e-08, reduce=None, reduction='mean')
![[十六]深度学习Pytorch-18种损失函数loss function_第17张图片](http://img.e-com-net.com/image/info8/78f5c0f9b7c641a48b168c3740edb8cf.jpg)
eps是为了避免输入取0时,log函数出现nan。
代码示例:
![[十六]深度学习Pytorch-18种损失函数loss function_第18张图片](http://img.e-com-net.com/image/info8/ba104eb8f3f24bd3954c98cabfde2dd0.jpg)
# ------------------------------------------------- 8 Poisson NLL Loss ----------------------------------------------
flag = 0
# flag = 1
if flag:
inputs = torch.randn((2, 2)) #2*2,标准正态分布
target = torch.randn((2, 2)) #2*2,标准正态分布
loss_f = nn.PoissonNLLLoss(log_input=True, full=False, reduction='none')
loss = loss_f(inputs, target)
print("input:{}\ntarget:{}\nPoisson NLL loss:{}".format(inputs, target, loss))
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
idx = 0
loss_1 = torch.exp(inputs[idx, idx]) - target[idx, idx]*inputs[idx, idx] #计算第一个元素,即inputs[0,0]
print("第一个元素loss:", loss_1)
2.9 nn.KLDivLoss(reduction=‘mean’)
nn.KLDivLoss(size_average=None, reduce=None, reduction='mean', log_target=False)
![[十六]深度学习Pytorch-18种损失函数loss function_第19张图片](http://img.e-com-net.com/image/info8/b84115397060491aa7e55b606ff68cdf.jpg) (1)P是真实的分布,Q是模型输出的分布(拟合的分布)。
(1)P是真实的分布,Q是模型输出的分布(拟合的分布)。
(2)P(xi)是样本在真实分布中的概率,即标签。
(3)yn是标签,xn是输入的数据。
代码示例:
# ------------------------------------------------- 9 KL Divergence Loss ----------------------------------------------
flag = 0
# flag = 1
if flag:
# 3个神经元,第一批样本中第一个神经元输出为0.5,第二个0.3,第三个0.2
# 第二批样本中第一个0.2,第二个0.3,第三个0.5
inputs = torch.tensor([[0.5, 0.3, 0.2], [0.2, 0.3, 0.5]]) #2*3,2批样本,3个神经元
inputs_log = torch.log(inputs)
target = torch.tensor([[0.9, 0.05, 0.05], [0.1, 0.7, 0.2]], dtype=torch.float)
loss_f_none = nn.KLDivLoss(reduction='none')
loss_f_mean = nn.KLDivLoss(reduction='mean')
loss_f_bs_mean = nn.KLDivLoss(reduction='batchmean')
loss_none = loss_f_none(inputs, target)
loss_mean = loss_f_mean(inputs, target) #所有元素相加/6,6是所有元素的个数
loss_bs_mean = loss_f_bs_mean(inputs, target) #所有元素相加/2,2是batchsize一共是两批次,即两批样本
print("loss_none:\n{}\nloss_mean:\n{}\nloss_bs_mean:\n{}".format(loss_none, loss_mean, loss_bs_mean))
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
idx = 0
loss_1 = target[idx, idx] * (torch.log(target[idx, idx]) - inputs[idx, idx])
print("第一个元素loss:", loss_1)
官网示例:
![[十六]深度学习Pytorch-18种损失函数loss function_第20张图片](http://img.e-com-net.com/image/info8/4deadff5490d4e52badf34f3e735f770.jpg)
kl_loss = nn.KLDivLoss(reduction="batchmean")
# input should be a distribution in the log space
input = F.log_softmax(torch.randn(3, 5, requires_grad=True))
# Sample a batch of distributions. Usually this would come from the dataset
target = F.softmax(torch.rand(3, 5))
output = kl_loss(input, target)
log_target = F.log_softmax(torch.rand(3, 5))
output = kl_loss(input, log_target, log_target=True)
2.10 nn.MarginRankingLoss(margin=0.0, reduction=‘mean’)
nn.MarginRankingLoss(margin=0.0, size_average=None, reduce=None, reduction='mean')
![[十六]深度学习Pytorch-18种损失函数loss function_第21张图片](http://img.e-com-net.com/image/info8/fde4168da8ab488da65ccb0759d1d70e.jpg)
(1)y是标签,取值只能是1或者-1。
(2)x1、x2是两个向量的每一个元素。
(3)x1=x2时,loss都会0。
示例代码:
![[十六]深度学习Pytorch-18种损失函数loss function_第22张图片](http://img.e-com-net.com/image/info8/944eba172d5f412ea44ef6a90adc6df3.jpg)
# ---------------------------------------------- 10 Margin Ranking Loss --------------------------------------------
flag = 0
# flag = 1
if flag:
x1 = torch.tensor([[1], [2], [3]], dtype=torch.float) #3*1
x2 = torch.tensor([[2], [2], [2]], dtype=torch.float) #3*1
target = torch.tensor([1, 1, -1], dtype=torch.float) #向量,也是1*3
loss_f_none = nn.MarginRankingLoss(margin=0, reduction='none')
loss = loss_f_none(x1, x2, target)
print(loss) #输出为[[1,1,0], [0,0,0], [0,0,1]]
# loss中第一行第一列的元素1是用x1的第1个元素[1]与x2的第1个元素[2]比较,此时y=1,loss=1
# loss中第一行第二列的元素1是用x1的第1个元素[2]与x2的第2个元素[2]比较,此时y=1,loss=1
# loss中第一行第三列的元素0是用x1的第1个元素[3]与x2的第3个元素[2]比较,此时y=-1,loss=0
# loss中第二行第一列的元素0是用x1的第2个元素[2]与x2的第1个元素[2]比较,此时y=1,loss=0,当两个值相等时,不论y是多少,loss=0
# 后面计算同理,y的值与x2是第几个有关,比如x2取第1个值,则y取第一个值;x2取第3个值,则y取第三个值。
2.11 nn.MultiLabelMarginLoss(reduction=‘mean’)
nn.MultiLabelMarginLoss(size_average=None, reduce=None, reduction='mean')
![[十六]深度学习Pytorch-18种损失函数loss function_第23张图片](http://img.e-com-net.com/image/info8/18a90864787346529b65030decaafb51.jpg) (1)分母是神经元的个数。
(1)分母是神经元的个数。
(2)x[y[j]]-x[i]=标签所在的神经元-不是标签所在的神经元。
![[十六]深度学习Pytorch-18种损失函数loss function_第24张图片](http://img.e-com-net.com/image/info8/0984b413000843b9b7b9f336145cd520.jpg)
目的是为了使标签所在的神经元的输出比非标签所在的神经元的输出越来越大,这样loss才会等于0。
代码示例:
# ---------------------------------------------- 11 Multi Label Margin Loss -----------------------------------------
flag = 0
# flag = 1
if flag:
x = torch.tensor([[0.1, 0.2, 0.4, 0.8]]) #1*4,1是一批样本,四分类,分别对应第0类、第1类、第2类、第3类
y = torch.tensor([[0, 3, -1, -1]], dtype=torch.long) #标签,设置第0类第3类,不足的地方用-1填充
loss_f = nn.MultiLabelMarginLoss(reduction='none')
loss = loss_f(x, y)
print(loss) # 输出0.8500
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
#标签所在的神经元是第0类和第3类,所以要计算第0类神经元的loss和第3类神经元的loss,需要各自减去不是标签的神经元
x = x[0] #取出第1批样本
#第0类神经元需要减去第1类、第2类神经元
item_1 = (1-(x[0] - x[1])) + (1 - (x[0] - x[2])) # [0]
#第3类神经元需要减去第1类、第2类神经元
item_2 = (1-(x[3] - x[1])) + (1 - (x[3] - x[2])) # [3]
loss_h = (item_1 + item_2) / x.shape[0] #x.shape[0]=4
print(loss_h)
标签所在的神经元是第0类和第3类,所以要计算第0类神经元的loss和第3类神经元的loss,需要各自减去不是标签的神经元。
官网示例:
![[十六]深度学习Pytorch-18种损失函数loss function_第25张图片](http://img.e-com-net.com/image/info8/ac659bc9202649bca770822dcc54df89.jpg)
loss = nn.MultiLabelMarginLoss()
x = torch.FloatTensor([[0.1, 0.2, 0.4, 0.8]])
# for target y, only consider labels 3 and 0, not after label -1
y = torch.LongTensor([[3, 0, -1, -1]])
loss(x, y)
# 0.25 * ((1-(0.8-0.2)) + (1-(0.8-0.4)) + (1-(0.1-0.2)) + (1-(0.1-0.4)))
2.12 nn.SoftMarginLoss(reduction=‘mean’)
nn.SoftMarginLoss(size_average=None, reduce=None, reduction='mean')
![[十六]深度学习Pytorch-18种损失函数loss function_第26张图片](http://img.e-com-net.com/image/info8/88ce4bddac754de6b9560c2aaa57867f.jpg)
(1)y只能取1或-1.
(2)nelement() 可以统计 tensor (张量) 中元素的个数。
代码示例:
![[十六]深度学习Pytorch-18种损失函数loss function_第27张图片](http://img.e-com-net.com/image/info8/71005dc4e6a04eeda6836b3cb4f2f035.jpg)
# ---------------------------------------------- 12 SoftMargin Loss -----------------------------------------
flag = 0
# flag = 1
if flag:
inputs = torch.tensor([[0.3, 0.7], [0.5, 0.5]]) # 2*2
target = torch.tensor([[-1, 1], [1, -1]], dtype=torch.float) # 2*2
loss_f = nn.SoftMarginLoss(reduction='none')
loss = loss_f(inputs, target)
print("SoftMargin: ", loss) # 2*2
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
idx = 0
inputs_i = inputs[idx, idx]
target_i = target[idx, idx]
loss_h = np.log(1 + np.exp(-target_i * inputs_i))
print(loss_h)
2.13 nn.MultiLabelSoftMarginLoss(reduction=‘mean’)
nn.MultiLabelSoftMarginLoss(weight=None, size_average=None, reduce=None, reduction='mean')
![[十六]深度学习Pytorch-18种损失函数loss function_第28张图片](http://img.e-com-net.com/image/info8/5e484faa9f2e4f2899011687494132aa.jpg)
(1)C是个数,取平均。
(2)标签只能是0,1。
(3)当i是标签神经元时,y[i]=1,只需要计算前一项,因为后一项1-y[i]=0。反之,当i不是标签神经元时,y[i]=0,只需要计算后一项,因为前一项为0。
代码示例:
![[十六]深度学习Pytorch-18种损失函数loss function_第29张图片](http://img.e-com-net.com/image/info8/813129c415044d2ca172175d58a460b3.jpg)
# ---------------------------------------------- 13 MultiLabel SoftMargin Loss -----------------------------------------
flag = 0
# flag = 1
if flag:
inputs = torch.tensor([[0.3, 0.7, 0.8]]) #三分类任务
target = torch.tensor([[0, 1, 1]], dtype=torch.float)
loss_f = nn.MultiLabelSoftMarginLoss(reduction='none')
loss = loss_f(inputs, target)
print("MultiLabel SoftMargin: ", loss) #输出0.5429
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
#第1个元素的标签为0,只需要计算后一项。
i_0 = torch.log(torch.exp(-inputs[0, 0]) / (1 + torch.exp(-inputs[0, 0])))
#第2个元素的标签为1,只需要计算前一项。
i_1 = torch.log(1 / (1 + torch.exp(-inputs[0, 1])))
#第3个元素的标签为1,只需要计算前一项。
i_2 = torch.log(1 / (1 + torch.exp(-inputs[0, 2])))
loss_h = (i_0 + i_1 + i_2) / -3
print(loss_h) #输出0.5429
2.14 nn.MultiMarginLoss(p=1, margin=1.0, weight=None, reduction=‘mean’)
nn.MultiMarginLoss(p=1, margin=1.0, weight=None, size_average=None, reduce=None, reduction='mean')
![[十六]深度学习Pytorch-18种损失函数loss function_第30张图片](http://img.e-com-net.com/image/info8/04a3ed7fcee548e999939f63d205fc1d.jpg)
x[y]是标签所在神经元的输出值,x[i]是非标签所在神经元的输出值。
代码示例:
# ---------------------------------------------- 14 Multi Margin Loss -----------------------------------------
flag = 0
# flag = 1
if flag:
x = torch.tensor([[0.1, 0.2, 0.7], [0.2, 0.5, 0.3]])
#第一个标签1对应x中第一个样本第1个元素(从第0个元素开始数)0.2
#第二个标签2对应x中第二个样本第2个元素(从第0个元素开始数)0.3
y = torch.tensor([1, 2], dtype=torch.long)
loss_f = nn.MultiMarginLoss(reduction='none')
loss = loss_f(x, y)
print("Multi Margin Loss: ", loss) #输出[0.8000, 0.7000]
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
x = x[0] #取出第一个样本
margin = 1
i_0 = margin - (x[1] - x[0])
# i_1 = margin - (x[1] - x[1])
i_2 = margin - (x[1] - x[2])
loss_h = (i_0 + i_2) / x.shape[0] #shape类别数=3
print(loss_h) #输出0.8000
官方示例:
![[十六]深度学习Pytorch-18种损失函数loss function_第31张图片](http://img.e-com-net.com/image/info8/0d600f2f85914077b8ed0db53ff7fd5b.jpg)
loss = nn.MultiMarginLoss()
x = torch.tensor([[0.1, 0.2, 0.4, 0.8]])
y = torch.tensor([3])
loss(x, y)
# 0.25 * ((1-(0.8-0.1)) + (1-(0.8-0.2)) + (1-(0.8-0.4)))
2.15 nn.TripletMarginLoss(margin=1.0, p=2.0, eps=1e-06, reduction=‘mean’)
nn.TripletMarginLoss(margin=1.0, p=2.0, eps=1e-06, swap=False, size_average=None, reduce=None, reduction='mean')
![[十六]深度学习Pytorch-18种损失函数loss function_第32张图片](http://img.e-com-net.com/image/info8/df20c5aff7e642e59ba96924ef2c4324.jpg) 学习的目的是:使positive与anchor之间的距离小于negative与anchor之间的距离。
学习的目的是:使positive与anchor之间的距离小于negative与anchor之间的距离。
代码示例:
# ---------------------------------------------- 15 Triplet Margin Loss -----------------------------------------
flag = 0
# flag = 1
if flag:
anchor = torch.tensor([[1.]])
pos = torch.tensor([[2.]])
neg = torch.tensor([[0.5]])
loss_f = nn.TripletMarginLoss(margin=1.0, p=1)
loss = loss_f(anchor, pos, neg)
print("Triplet Margin Loss", loss) #(2-1)-(1-0.5)+1 = 1.5
#输出1.5000
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
margin = 1
a, p, n = anchor[0], pos[0], neg[0]
d_ap = torch.abs(a-p)
d_an = torch.abs(a-n)
loss = d_ap - d_an + margin
print(loss)
官方示例:
![[十六]深度学习Pytorch-18种损失函数loss function_第33张图片](http://img.e-com-net.com/image/info8/27736038a11c432da3ffd7b402863166.jpg)
triplet_loss = nn.TripletMarginLoss(margin=1.0, p=2)
anchor = torch.randn(100, 128, requires_grad=True)
positive = torch.randn(100, 128, requires_grad=True)
negative = torch.randn(100, 128, requires_grad=True)
output = triplet_loss(anchor, positive, negative)
output.backward()
2.16 nn.HingeEmbeddingLoss(margin=1.0, reduction=‘mean’)
nn.HingeEmbeddingLoss(margin=1.0, size_average=None, reduce=None, reduction='mean')
![[十六]深度学习Pytorch-18种损失函数loss function_第34张图片](http://img.e-com-net.com/image/info8/a8582580dd5a4afdbd994ce5d9fc73e6.jpg)
▲表示margin。
代码示例:
![[十六]深度学习Pytorch-18种损失函数loss function_第35张图片](http://img.e-com-net.com/image/info8/a45a1c31f5994598ad788cf88d416ca8.jpg)
# ---------------------------------------------- 16 Hinge Embedding Loss -----------------------------------------
flag = 0
# flag = 1
if flag:
inputs = torch.tensor([[1., 0.8, 0.5]])
target = torch.tensor([[1, 1, -1]])
loss_f = nn.HingeEmbeddingLoss(margin=1, reduction='none')
loss = loss_f(inputs, target)
print("Hinge Embedding Loss", loss)
#输出[1.0000, 0.8000, 0.5000]
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
margin = 1.
loss = max(0, margin - inputs.numpy()[0, 2])
print(loss)
2.17 nn.CosineEmbeddingLoss(margin=0.0, reduction=‘mean’)
nn.CosineEmbeddingLoss(margin=0.0, size_average=None, reduce=None, reduction='mean')
![[十六]深度学习Pytorch-18种损失函数loss function_第36张图片](http://img.e-com-net.com/image/info8/5ff8532425874c43a6ba0d9d8cfe8c67.jpg)
重点关注两个输入在方向上的差异。
代码示例:
![[十六]深度学习Pytorch-18种损失函数loss function_第37张图片](http://img.e-com-net.com/image/info8/56554d65a2014059a0cd460412ec9aad.jpg)
# ---------------------------------------------- 17 Cosine Embedding Loss -----------------------------------------
flag = 0
# flag = 1
if flag:
x1 = torch.tensor([[0.3, 0.5, 0.7], [0.3, 0.5, 0.7]])
x2 = torch.tensor([[0.1, 0.3, 0.5], [0.1, 0.3, 0.5]])
target = torch.tensor([[1, -1]], dtype=torch.float)
loss_f = nn.CosineEmbeddingLoss(margin=0., reduction='none')
loss = loss_f(x1, x2, target)
print("Cosine Embedding Loss", loss)
# 输出[0.0167, 0.9833]
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
margin = 0.
def cosine(a, b):
numerator = torch.dot(a, b) # 分子是点积
denominator = torch.norm(a, 2) * torch.norm(b, 2) #分母是模长相乘
return float(numerator/denominator)
l_1 = 1 - (cosine(x1[0], x2[0]))
l_2 = max(0, cosine(x1[0], x2[0]))
print(l_1, l_2)
# 输出0.0167 0.9833
2.18 nn.CTCLoss(blank=0, reduction=‘mean’)
nn.CTCLoss(blank=0, reduction='mean', zero_infinity=False)
![[十六]深度学习Pytorch-18种损失函数loss function_第38张图片](http://img.e-com-net.com/image/info8/8038b8b71d45456b8205fa357a05fb32.jpg) 代码示例:
代码示例:
![[十六]深度学习Pytorch-18种损失函数loss function_第39张图片](http://img.e-com-net.com/image/info8/4a41e8781c6d403eb742cce2738b8cc6.jpg)
# ---------------------------------------------- 18 CTC Loss -----------------------------------------
# flag = 0
flag = 1
if flag:
T = 50 # Input sequence length
C = 20 # Number of classes (including blank)
N = 16 # Batch size
S = 30 # Target sequence length of longest target in batch
S_min = 10 # Minimum target length, for demonstration purposes
# Initialize random batch of input vectors, for *size = (T,N,C)
inputs = torch.randn(T, N, C).log_softmax(2).detach().requires_grad_()
# Initialize random batch of targets (0 = blank, 1:C = classes)
target = torch.randint(low=1, high=C, size=(N, S), dtype=torch.long)
input_lengths = torch.full(size=(N,), fill_value=T, dtype=torch.long)
target_lengths = torch.randint(low=S_min, high=S, size=(N,), dtype=torch.long)
ctc_loss = nn.CTCLoss()
loss = ctc_loss(inputs, target, input_lengths, target_lengths)
print("CTC loss: ", loss) #输出7.5385
3. 完整代码
ce_loss.py
# -*- coding: utf-8 -*-
"""
# @file name : ce_loss.py
# @brief : 人民币分类模型训练
"""
import os
import random
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torch.optim as optim
from PIL import Image
from matplotlib import pyplot as plt
from model.lenet import LeNet
from tools.my_dataset import RMBDataset
from tools.common_tools import transform_invert, set_seed
set_seed(1) # 设置随机种子
rmb_label = {"1": 0, "100": 1}
# 参数设置
MAX_EPOCH = 10
BATCH_SIZE = 16
LR = 0.01
log_interval = 10
val_interval = 1
# ============================ step 1/5 数据 ============================
split_dir = os.path.join("..", "..", "data", "rmb_split")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomCrop(32, padding=4),
transforms.RandomGrayscale(p=0.8),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
valid_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
# ============================ step 2/5 模型 ============================
net = LeNet(classes=2)
net.initialize_weights()
# ============================ step 3/5 损失函数 ============================
loss_functoin = nn.CrossEntropyLoss() # 选择损失函数(交叉熵)
# ============================ step 4/5 优化器 ============================
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1) # 设置学习率下降策略
# ============================ step 5/5 训练 ============================
train_curve = list()
valid_curve = list()
for epoch in range(MAX_EPOCH):
loss_mean = 0.
correct = 0.
total = 0.
net.train()
for i, data in enumerate(train_loader):
# forward
inputs, labels = data
outputs = net(inputs)
# backward
optimizer.zero_grad()
loss = loss_functoin(outputs, labels)
loss.backward()
# update weights
optimizer.step()
# 统计分类情况
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).squeeze().sum().numpy()
# 打印训练信息
loss_mean += loss.item()
train_curve.append(loss.item())
if (i+1) % log_interval == 0:
loss_mean = loss_mean / log_interval
print("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, i+1, len(train_loader), loss_mean, correct / total))
loss_mean = 0.
scheduler.step() # 更新学习率
# validate the model
if (epoch+1) % val_interval == 0:
correct_val = 0.
total_val = 0.
loss_val = 0.
net.eval()
with torch.no_grad():
for j, data in enumerate(valid_loader):
inputs, labels = data
outputs = net(inputs)
loss = loss_functoin(outputs, labels)
_, predicted = torch.max(outputs.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).squeeze().sum().numpy()
loss_val += loss.item()
valid_curve.append(loss_val)
print("Valid:\t Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, j+1, len(valid_loader), loss_val, correct / total))
train_x = range(len(train_curve))
train_y = train_curve
train_iters = len(train_loader)
valid_x = np.arange(1, len(valid_curve)+1) * train_iters*val_interval # 由于valid中记录的是epochloss,需要对记录点进行转换到iterations
valid_y = valid_curve
plt.plot(train_x, train_y, label='Train')
plt.plot(valid_x, valid_y, label='Valid')
plt.legend(loc='upper right')
plt.ylabel('loss value')
plt.xlabel('Iteration')
plt.show()
# ============================ inference ============================
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
test_dir = os.path.join(BASE_DIR, "test_data")
test_data = RMBDataset(data_dir=test_dir, transform=valid_transform)
valid_loader = DataLoader(dataset=test_data, batch_size=1)
for i, data in enumerate(valid_loader):
# forward
inputs, labels = data
outputs = net(inputs)
_, predicted = torch.max(outputs.data, 1)
rmb = 1 if predicted.numpy()[0] == 0 else 100
img_tensor = inputs[0, ...] # C H W
img = transform_invert(img_tensor, train_transform)
plt.imshow(img)
plt.title("LeNet got {} Yuan".format(rmb))
plt.show()
plt.pause(0.5)
plt.close()
loss_function_1.py
# -*- coding: utf-8 -*-
"""
# @file name : loss_function_1.py
# @brief : 1. nn.CrossEntropyLoss
2. nn.NLLLoss
3. BCELoss
4. BCEWithLogitsLoss
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
# fake data
#二分类任务,输出神经元2个,batchsize是3,即三个样本:[1,2] [1,3] [1,3]
inputs = torch.tensor([[1, 2], [1, 3], [1, 3]], dtype=torch.float)
#dtype必须是long,有多少个样本,tensor(1D)就有多长。
target = torch.tensor([0, 1, 1], dtype=torch.long)
# ----------------------------------- CrossEntropy loss: reduction -----------------------------------
flag = 0
# flag = 1
if flag:
# def loss function
loss_f_none = nn.CrossEntropyLoss(weight=None, reduction='none')
loss_f_sum = nn.CrossEntropyLoss(weight=None, reduction='sum')
loss_f_mean = nn.CrossEntropyLoss(weight=None, reduction='mean')
# forward
loss_none = loss_f_none(inputs, target)
loss_sum = loss_f_sum(inputs, target)
loss_mean = loss_f_mean(inputs, target)
# view
print("Cross Entropy Loss:\n ", loss_none, loss_sum, loss_mean)
#输出为[1.3133, 0.1269, 0.1269] 1.5671 0.5224
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
idx = 0
input_1 = inputs.detach().numpy()[idx] # [1, 2]
target_1 = target.numpy()[idx] # [0]
# 第一项
x_class = input_1[target_1]
# 第二项
sigma_exp_x = np.sum(list(map(np.exp, input_1)))
log_sigma_exp_x = np.log(sigma_exp_x)
# 输出loss
loss_1 = -x_class + log_sigma_exp_x
print("第一个样本loss为: ", loss_1)
# ----------------------------------- weight -----------------------------------
flag = 0
# flag = 1
if flag:
# def loss function
#有多少个类别weights这个向量就要设置多长
weights = torch.tensor([1, 2], dtype=torch.float)
# weights = torch.tensor([0.7, 0.3], dtype=torch.float)
loss_f_none_w = nn.CrossEntropyLoss(weight=weights, reduction='none')
loss_f_sum = nn.CrossEntropyLoss(weight=weights, reduction='sum')
loss_f_mean = nn.CrossEntropyLoss(weight=weights, reduction='mean')
# forward
loss_none_w = loss_f_none_w(inputs, target)
loss_sum = loss_f_sum(inputs, target)
loss_mean = loss_f_mean(inputs, target)
# view
print("\nweights: ", weights)
print(loss_none_w, loss_sum, loss_mean)
#权值为[1,2],则输出[1.3133, 0.2539, 0.2539] 1.8210 0.3642
# target=[0,1,1]所以对应0的需要乘以权值1,对应1的需要乘以权值2.
# 1.3133是1.3133*1=1.3133,0.2530是0.1269*2=0.2539,0.2530是0.1269*2=0.2539.
#0.3642是1.8210/(1+2+2)=0.3642,分母是权值的份数(5).
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
weights = torch.tensor([1, 2], dtype=torch.float)
#weights_all=5
weights_all = np.sum(list(map(lambda x: weights.numpy()[x], target.numpy()))) # [0, 1, 1] ---> # [1 2 2]
mean = 0
loss_sep = loss_none.detach().numpy()
for i in range(target.shape[0]):
x_class = target.numpy()[i]
tmp = loss_sep[i] * (weights.numpy()[x_class] / weights_all)
mean += tmp
print(mean)
# ----------------------------------- 2 NLLLoss -----------------------------------
flag = 0
# flag = 1
if flag:
weights = torch.tensor([1, 1], dtype=torch.float)
loss_f_none_w = nn.NLLLoss(weight=weights, reduction='none')
loss_f_sum = nn.NLLLoss(weight=weights, reduction='sum')
loss_f_mean = nn.NLLLoss(weight=weights, reduction='mean')
# forward
loss_none_w = loss_f_none_w(inputs, target)
loss_sum = loss_f_sum(inputs, target)
loss_mean = loss_f_mean(inputs, target)
# view
print("\nweights: ", weights)
print("NLL Loss", loss_none_w, loss_sum, loss_mean)
#输出[-1,-3,-3] -7 -2.3333
# target[0, 1, 1]
#-1是因为第一个样本[1,2]是第0类,因此只对第一个神经元输出操作:-1*1。
#-3是因为第二个样本[1,3]是第1类,因此只对第二个神经元输出操作:-1*3。
#-3是因为第三个样本[1,3]是第1类,因此只对第二个神经元输出操作:-1*3。
#求mean时的分母是权重weight的和。
# ----------------------------------- 3 BCE Loss -----------------------------------
flag = 0
# flag = 1
if flag:
inputs = torch.tensor([[1, 2], [2, 2], [3, 4], [4, 5]], dtype=torch.float) #4个样本
target = torch.tensor([[1, 0], [1, 0], [0, 1], [0, 1]], dtype=torch.float) #float类型,每个神经元一一对应去计算loss
target_bce = target
# itarget
#一定要加上sigmoid,将输入值取值在[0,1]区间
inputs = torch.sigmoid(inputs)
weights = torch.tensor([1, 1], dtype=torch.float)
loss_f_none_w = nn.BCELoss(weight=weights, reduction='none')
loss_f_sum = nn.BCELoss(weight=weights, reduction='sum')
loss_f_mean = nn.BCELoss(weight=weights, reduction='mean')
# forward
loss_none_w = loss_f_none_w(inputs, target_bce)
loss_sum = loss_f_sum(inputs, target_bce)
loss_mean = loss_f_mean(inputs, target_bce)
# view
print("\nweights: ", weights)
print("BCE Loss", loss_none_w, loss_sum, loss_mean)
#输出[[0.3133, 2.1269], [0.1269, 2.1269], [3.0486, 0.0181], [4.0181, 0.0067]] 11.7856 1.4732
#每个神经元一一对应去计算loss,因此loss个数是2*4=8个
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
idx = 0
x_i = inputs.detach().numpy()[idx, idx]
y_i = target.numpy()[idx, idx] #
# loss
# l_i = -[ y_i * np.log(x_i) + (1-y_i) * np.log(1-y_i) ] # np.log(0) = nan
l_i = -y_i * np.log(x_i) if y_i else -(1-y_i) * np.log(1-x_i)
# 输出loss
print("BCE inputs: ", inputs)
print("第一个loss为: ", l_i) #0.3133
# ----------------------------------- 4 BCE with Logis Loss -----------------------------------
# flag = 0
flag = 1
if flag:
inputs = torch.tensor([[1, 2], [2, 2], [3, 4], [4, 5]], dtype=torch.float)
target = torch.tensor([[1, 0], [1, 0], [0, 1], [0, 1]], dtype=torch.float)
target_bce = target
# inputs = torch.sigmoid(inputs) 不能加sigmoid!!!
weights = torch.tensor([1, 1], dtype=torch.float)
loss_f_none_w = nn.BCEWithLogitsLoss(weight=weights, reduction='none')
loss_f_sum = nn.BCEWithLogitsLoss(weight=weights, reduction='sum')
loss_f_mean = nn.BCEWithLogitsLoss(weight=weights, reduction='mean')
# forward
loss_none_w = loss_f_none_w(inputs, target_bce)
loss_sum = loss_f_sum(inputs, target_bce)
loss_mean = loss_f_mean(inputs, target_bce)
# view
print("\nweights: ", weights)
print(loss_none_w, loss_sum, loss_mean)
#输出[[0.3133, 2.1269], [0.1269, 2.1269], [3.0486, 0.0181], [4.0181, 0.0067]] 11.7856 1.4732
# --------------------------------- pos weight
# flag = 0
flag = 1
if flag:
inputs = torch.tensor([[1, 2], [2, 2], [3, 4], [4, 5]], dtype=torch.float)
target = torch.tensor([[1, 0], [1, 0], [0, 1], [0, 1]], dtype=torch.float)
target_bce = target
# itarget
# inputs = torch.sigmoid(inputs)
weights = torch.tensor([1], dtype=torch.float)
#pos_w = torch.tensor([1], dtype=torch.float) #设置为1时,loss输出与原先一致。
pos_w = torch.tensor([3], dtype=torch.float) # 3
#设置为3时会对正样本的loss乘以3,即标签是1对应的loss。
#输出[[0.3133*3, 2.1269], [0.1269*3, 2.1269], [3.0486, 0.0181*3], [4.0181, 0.0067*3]]
loss_f_none_w = nn.BCEWithLogitsLoss(weight=weights, reduction='none', pos_weight=pos_w)
loss_f_sum = nn.BCEWithLogitsLoss(weight=weights, reduction='sum', pos_weight=pos_w)
loss_f_mean = nn.BCEWithLogitsLoss(weight=weights, reduction='mean', pos_weight=pos_w)
# forward
loss_none_w = loss_f_none_w(inputs, target_bce)
loss_sum = loss_f_sum(inputs, target_bce)
loss_mean = loss_f_mean(inputs, target_bce)
# view
print("\npos_weights: ", pos_w)
print(loss_none_w, loss_sum, loss_mean)
loss_function_2.py
# -*- coding: utf-8 -*-
"""
# @file name : loss_function_2.py
# @brief :
5. nn.L1Loss
6. nn.MSELoss
7. nn.SmoothL1Loss
8. nn.PoissonNLLLoss
9. nn.KLDivLoss
10. nn.MarginRankingLoss
11. nn.MultiLabelMarginLoss
12. nn.SoftMarginLoss
13. nn.MultiLabelSoftMarginLoss
14. nn.MultiMarginLoss
15. nn.TripletMarginLoss
16. nn.HingeEmbeddingLoss
17. nn.CosineEmbeddingLoss
18. nn.CTCLoss
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
import numpy as np
from tools.common_tools import set_seed
set_seed(1) # 设置随机种子
# ------------------------------------------------- 5 L1 loss ----------------------------------------------
flag = 0
# flag = 1
if flag:
inputs = torch.ones((2, 2)) #2*2,数值为1
target = torch.ones((2, 2)) * 3 #2*2,数值为3
loss_f = nn.L1Loss(reduction='none')
loss = loss_f(inputs, target)
print("input:{}\ntarget:{}\nL1 loss:{}".format(inputs, target, loss))
#输出为[[2,2],[2,2]]
# ------------------------------------------------- 6 MSE loss ----------------------------------------------
loss_f_mse = nn.MSELoss(reduction='none')
loss_mse = loss_f_mse(inputs, target)
print("MSE loss:{}".format(loss_mse))
#输出为[[4,4],[4,4]]
# ------------------------------------------------- 7 Smooth L1 loss ----------------------------------------------
flag = 0
# flag = 1
if flag:
inputs = torch.linspace(-3, 3, steps=500) #-3到3区间取500个数据点
target = torch.zeros_like(inputs) #数值为0,维度与inputs一致
loss_f = nn.SmoothL1Loss(reduction='none')
loss_smooth = loss_f(inputs, target)
loss_l1 = np.abs(inputs.numpy()-target.numpy())
plt.plot(inputs.numpy(), loss_smooth.numpy(), label='Smooth L1 Loss')
plt.plot(inputs.numpy(), loss_l1, label='L1 loss')
plt.xlabel('x_i - y_i')
plt.ylabel('loss value')
plt.legend()
plt.grid()
plt.show()
# ------------------------------------------------- 8 Poisson NLL Loss ----------------------------------------------
flag = 0
# flag = 1
if flag:
inputs = torch.randn((2, 2)) #2*2,标准正态分布
target = torch.randn((2, 2)) #2*2,标准正态分布
loss_f = nn.PoissonNLLLoss(log_input=True, full=False, reduction='none')
loss = loss_f(inputs, target)
print("input:{}\ntarget:{}\nPoisson NLL loss:{}".format(inputs, target, loss))
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
idx = 0
loss_1 = torch.exp(inputs[idx, idx]) - target[idx, idx]*inputs[idx, idx] #计算第一个元素,即inputs[0,0]
print("第一个元素loss:", loss_1)
# ------------------------------------------------- 9 KL Divergence Loss ----------------------------------------------
flag = 0
# flag = 1
if flag:
# 3个神经元,第一批样本中第一个神经元输出为0.5,第二个0.3,第三个0.2
# 第二批样本中第一个0.2,第二个0.3,第三个0.5
inputs = torch.tensor([[0.5, 0.3, 0.2], [0.2, 0.3, 0.5]]) #2*3,2批样本,3个神经元
inputs_log = torch.log(inputs)
target = torch.tensor([[0.9, 0.05, 0.05], [0.1, 0.7, 0.2]], dtype=torch.float)
loss_f_none = nn.KLDivLoss(reduction='none')
loss_f_mean = nn.KLDivLoss(reduction='mean')
loss_f_bs_mean = nn.KLDivLoss(reduction='batchmean')
loss_none = loss_f_none(inputs, target)
loss_mean = loss_f_mean(inputs, target) #所有元素相加/6,6是所有元素的个数
loss_bs_mean = loss_f_bs_mean(inputs, target) #所有元素相加/2,2是batchsize一共是两批次,即两批样本
print("loss_none:\n{}\nloss_mean:\n{}\nloss_bs_mean:\n{}".format(loss_none, loss_mean, loss_bs_mean))
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
idx = 0
loss_1 = target[idx, idx] * (torch.log(target[idx, idx]) - inputs[idx, idx])
print("第一个元素loss:", loss_1)
# ---------------------------------------------- 10 Margin Ranking Loss --------------------------------------------
flag = 0
# flag = 1
if flag:
x1 = torch.tensor([[1], [2], [3]], dtype=torch.float) #3*1
x2 = torch.tensor([[2], [2], [2]], dtype=torch.float) #3*1
target = torch.tensor([1, 1, -1], dtype=torch.float) #向量,也是1*3
loss_f_none = nn.MarginRankingLoss(margin=0, reduction='none')
loss = loss_f_none(x1, x2, target)
print(loss) #输出为[[1,1,0], [0,0,0], [0,0,1]]
# loss中第一行第一列的元素1是用x1的第1个元素[1]与x2的第1个元素[2]比较,此时y=1,loss=1
# loss中第一行第二列的元素1是用x1的第1个元素[2]与x2的第2个元素[2]比较,此时y=1,loss=1
# loss中第一行第三列的元素0是用x1的第1个元素[3]与x2的第3个元素[2]比较,此时y=-1,loss=0
# loss中第二行第一列的元素0是用x1的第2个元素[2]与x2的第1个元素[2]比较,此时y=1,loss=0,当两个值相等时,不论y是多少,loss=0
# 后面计算同理,y的值与x2是第几个有关,比如x2取第1个值,则y取第一个值;x2取第3个值,则y取第三个值。
# ---------------------------------------------- 11 Multi Label Margin Loss -----------------------------------------
flag = 0
# flag = 1
if flag:
x = torch.tensor([[0.1, 0.2, 0.4, 0.8]]) #1*4,1是一批样本,四分类,分别对应第0类、第1类、第2类、第3类
y = torch.tensor([[0, 3, -1, -1]], dtype=torch.long) #标签,设置第0类第3类,不足的地方用-1填充
loss_f = nn.MultiLabelMarginLoss(reduction='none')
loss = loss_f(x, y)
print(loss) # 输出0.8500
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
#标签所在的神经元是第0类和第3类,所以要计算第0类神经元的loss和第3类神经元的loss,需要各自减去不是标签的神经元
x = x[0] #取出第1批样本
#第0类神经元需要减去第1类、第2类神经元
item_1 = (1-(x[0] - x[1])) + (1 - (x[0] - x[2])) # [0]
#第3类神经元需要减去第1类、第2类神经元
item_2 = (1-(x[3] - x[1])) + (1 - (x[3] - x[2])) # [3]
loss_h = (item_1 + item_2) / x.shape[0] #x.shape[0]=4
print(loss_h)
# ---------------------------------------------- 12 SoftMargin Loss -----------------------------------------
flag = 0
# flag = 1
if flag:
inputs = torch.tensor([[0.3, 0.7], [0.5, 0.5]]) # 2*2
target = torch.tensor([[-1, 1], [1, -1]], dtype=torch.float) # 2*2
loss_f = nn.SoftMarginLoss(reduction='none')
loss = loss_f(inputs, target)
print("SoftMargin: ", loss) # 2*2
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
idx = 0
inputs_i = inputs[idx, idx]
target_i = target[idx, idx]
loss_h = np.log(1 + np.exp(-target_i * inputs_i))
print(loss_h)
# ---------------------------------------------- 13 MultiLabel SoftMargin Loss -----------------------------------------
flag = 0
# flag = 1
if flag:
inputs = torch.tensor([[0.3, 0.7, 0.8]]) #三分类任务
target = torch.tensor([[0, 1, 1]], dtype=torch.float)
loss_f = nn.MultiLabelSoftMarginLoss(reduction='none')
loss = loss_f(inputs, target)
print("MultiLabel SoftMargin: ", loss) #输出0.5429
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
#第1个元素的标签为0,只需要计算后一项。
i_0 = torch.log(torch.exp(-inputs[0, 0]) / (1 + torch.exp(-inputs[0, 0])))
#第2个元素的标签为1,只需要计算前一项。
i_1 = torch.log(1 / (1 + torch.exp(-inputs[0, 1])))
#第3个元素的标签为1,只需要计算前一项。
i_2 = torch.log(1 / (1 + torch.exp(-inputs[0, 2])))
loss_h = (i_0 + i_1 + i_2) / -3
print(loss_h) #输出0.5429
# ---------------------------------------------- 14 Multi Margin Loss -----------------------------------------
flag = 0
# flag = 1
if flag:
x = torch.tensor([[0.1, 0.2, 0.7], [0.2, 0.5, 0.3]])
#第一个标签1对应x中第一个样本第1个元素(从第0个元素开始数)0.2
#第二个标签2对应x中第二个样本第2个元素(从第0个元素开始数)0.3
y = torch.tensor([1, 2], dtype=torch.long)
loss_f = nn.MultiMarginLoss(reduction='none')
loss = loss_f(x, y)
print("Multi Margin Loss: ", loss) #输出[0.8000, 0.7000]
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
x = x[0] #取出第一个样本
margin = 1
i_0 = margin - (x[1] - x[0])
# i_1 = margin - (x[1] - x[1])
i_2 = margin - (x[1] - x[2])
loss_h = (i_0 + i_2) / x.shape[0] #shape类别数=3
print(loss_h) #输出0.8000
# ---------------------------------------------- 15 Triplet Margin Loss -----------------------------------------
flag = 0
# flag = 1
if flag:
anchor = torch.tensor([[1.]])
pos = torch.tensor([[2.]])
neg = torch.tensor([[0.5]])
loss_f = nn.TripletMarginLoss(margin=1.0, p=1)
loss = loss_f(anchor, pos, neg)
print("Triplet Margin Loss", loss) #(2-1)-(1-0.5)+1 = 1.5
#输出1.5000
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
margin = 1
a, p, n = anchor[0], pos[0], neg[0]
d_ap = torch.abs(a-p)
d_an = torch.abs(a-n)
loss = d_ap - d_an + margin
print(loss)
# ---------------------------------------------- 16 Hinge Embedding Loss -----------------------------------------
flag = 0
# flag = 1
if flag:
inputs = torch.tensor([[1., 0.8, 0.5]])
target = torch.tensor([[1, 1, -1]])
loss_f = nn.HingeEmbeddingLoss(margin=1, reduction='none')
loss = loss_f(inputs, target)
print("Hinge Embedding Loss", loss)
#输出[1.0000, 0.8000, 0.5000]
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
margin = 1.
loss = max(0, margin - inputs.numpy()[0, 2])
print(loss)
# ---------------------------------------------- 17 Cosine Embedding Loss -----------------------------------------
flag = 0
# flag = 1
if flag:
x1 = torch.tensor([[0.3, 0.5, 0.7], [0.3, 0.5, 0.7]])
x2 = torch.tensor([[0.1, 0.3, 0.5], [0.1, 0.3, 0.5]])
target = torch.tensor([[1, -1]], dtype=torch.float)
loss_f = nn.CosineEmbeddingLoss(margin=0., reduction='none')
loss = loss_f(x1, x2, target)
print("Cosine Embedding Loss", loss)
# 输出[0.0167, 0.9833]
# --------------------------------- compute by hand
flag = 0
# flag = 1
if flag:
margin = 0.
def cosine(a, b):
numerator = torch.dot(a, b) # 分子是点积
denominator = torch.norm(a, 2) * torch.norm(b, 2) #分母是模长相乘
return float(numerator/denominator)
l_1 = 1 - (cosine(x1[0], x2[0]))
l_2 = max(0, cosine(x1[0], x2[0]))
print(l_1, l_2)
# 输出0.0167 0.9833
# ---------------------------------------------- 18 CTC Loss -----------------------------------------
# flag = 0
flag = 1
if flag:
T = 50 # Input sequence length
C = 20 # Number of classes (including blank)
N = 16 # Batch size
S = 30 # Target sequence length of longest target in batch
S_min = 10 # Minimum target length, for demonstration purposes
# Initialize random batch of input vectors, for *size = (T,N,C)
inputs = torch.randn(T, N, C).log_softmax(2).detach().requires_grad_()
# Initialize random batch of targets (0 = blank, 1:C = classes)
target = torch.randint(low=1, high=C, size=(N, S), dtype=torch.long)
input_lengths = torch.full(size=(N,), fill_value=T, dtype=torch.long)
target_lengths = torch.randint(low=S_min, high=S, size=(N,), dtype=torch.long)
ctc_loss = nn.CTCLoss()
loss = ctc_loss(inputs, target, input_lengths, target_lengths)
print("CTC loss: ", loss) #输出7.538