分布式缓存系统是三高架构中不可或缺的部分,极大地提高了整个项目的并发量、响应速度,但它也带来了新的需要解决的问题,分别是: 缓存穿透、缓存击穿、缓存雪崩和缓存一致性问题。
缓存穿透
第一个比较大的问题就是缓存穿透。这个概念比较好理解,和命中率有关。如果命中率很低,那么压力就会集中在数据库持久层。
假如能找到相关数据,我们就可以把它缓存起来。但问题是,本次请求,在缓存和持久层都没有命中,这种情况就叫缓存的穿透。
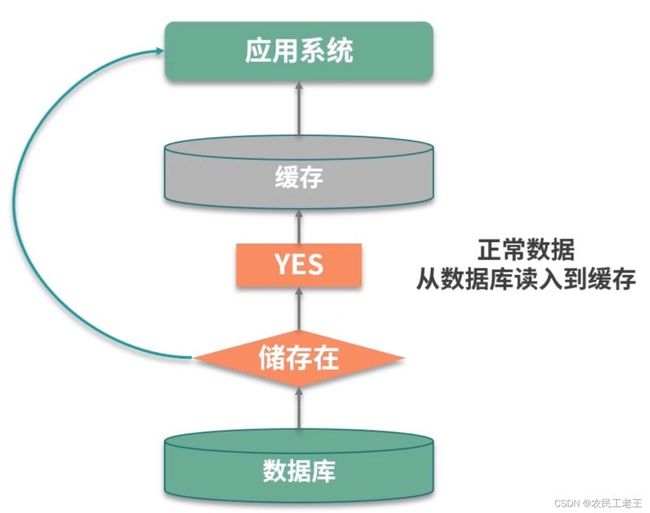
举个例子,如上图,在一个登录系统中,有外部攻击,一直尝试使用不存在的用户进行登录,这些用户都是虚拟的,不能有效地被缓存起来,每次都会到数据库中查询一次,最后就会造成服务的性能故障。
解决这个问题有多种方案,我们来简单介绍一下。
第一种就是把空对象缓存起来。不是持久层查不到数据吗?那么我们就可以把本次请求的结果设置为 null,然后放入到缓存中。通过设置合理的过期时间,就可以保证后端数据库的安全。
缓存空对象会占用额外的缓存空间,还会有数据不一致的时间窗口,所以第二种方法就是针对大数据量的、有规律的键值,使用布隆过滤器进行处理。
一条记录存在与不存在,是一个 Bool 值,只需要使用 1 比特就可存储。布隆过滤器就可以把这种是、否操作,压缩到一个数据结构中。比如手机号,用户性别这种数据,就非常适合使用布隆过滤器。
缓存击穿
缓存击穿,指的也是用户请求落在数据库上的情况,大多数情况,是由于缓存时间批量过期引起的。
我们一般会对缓存中的数据,设置一个过期时间。如果在某个时刻从数据库获取了大量数据,并设置了同样的过期时间,它们将会在同一时刻失效,造成和缓存的击穿。
对于比较热点的数据,我们就可以设置它不过期;或者在访问的时候,更新它的过期时间;批量入库的缓存项,也尽量分配一个比较平均的过期时间,避免同一时间失效。
缓存雪崩
雪崩这个词看着可怕,实际情况也确实比较严重。缓存是用来对系统加速的,后端的数据库只是数据的备份,而不是作为高可用的备选方案。
当缓存系统出现故障,流量会瞬间转移到后端的数据库。过不了多久,数据库将会被大流量压垮挂掉,这种级联式的服务故障,可以形象地称为雪崩。
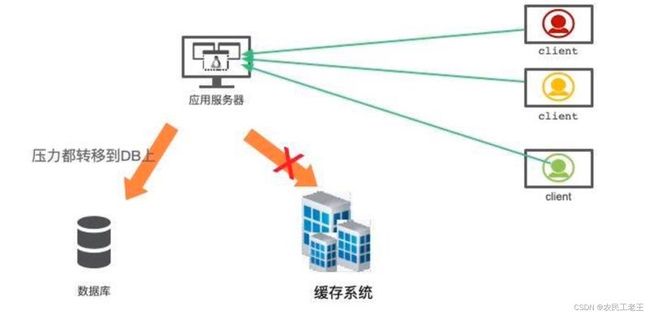
缓存的高可用建设是非常重要的。Redis 提供了主从和 Cluster 的模式,其中 Cluster 模式使用简单,每个分片也能单独做主从,可以保证极高的可用性。
另外,我们对数据库的性能瓶颈有一个大体的评估。如果缓存系统当掉,那么流向数据库的请求,就可以使用限流组件,将请求拦截在外面。
缓存一致性
引入缓存组件后,另外一个老大难的问题,就是缓存的一致性。
我们首先来看问题是怎么发生的。对于一个缓存项来说,常用的操作有四个:写入、更新、读取、删除。
- 写入:缓存和数据库是两个不同的组件,只要涉及双写,就存在只有一个写成功的可能性,造成数据不一致。
- 更新:更新的情况类似,需要更新两个不同的组件。
- 读取:读取要保证从缓存中读到的信息是最新的,是和数据库中的是一致的。
- 删除:当删除数据库记录的时候,如何把缓存中的数据也删掉?
由于业务逻辑大多数情况下,是比较复杂的。其中的更新操作,就非常昂贵,比如一个用户的余额,就是通过计算一系列的资产算出来的一个数。如果这些关联的资产,每个地方改动的时候,都去刷新缓存,那代码结构就会非常混乱,以至于无法维护。
我推荐使用触发式的缓存一致性方式,使用懒加载的方式,可以让缓存的同步变得非常简单:
- 当读取缓存的时候,如果缓存里没有相关数据,则执行相关的业务逻辑,构造缓存数据存入到缓存系统;
- 当与缓存项相关的资源有变动,则先删除相应的缓存项,然后在数据库中对资源进行更新,最后再删除相应的缓存项。
这种操作,除了编程模型简单,有一个明显的好处。我只有在用到这个缓存的时候,才把它加载到缓存系统中。如果每次修改 都创建、更新资源,那缓存系统中就会存在非常多的冷数据。这实际上是实现了边缘缓存模式(Cache-Aside Pattern),即按需将数据从数据存储加载到缓存中,最大的作用就是提高性能减少不必要的查询。
但这样还是有问题。接下来介绍的场景,也是面试中经常提及的问题。
我们上面提到的数据库的更新动作,和缓存删除动作,明显是不在一个事务里的。可能造成数据库的内容和缓存里的内容在更新的过程有不一致。
在面试中,只要你把这个问题给点出来,面试官都会跷起大拇指。
可以使用分布式锁来解决这个问题,将数据库操作和缓存操作,与其他的缓存读操作,使用锁进行资源隔离即可。一般来说,读操作是不需要加锁的,它会在遇到锁的时候,重试等待,直到超时。
到此这篇关于详解Java分布式缓存系统中必须解决的四大问题的文章就介绍到这了,更多相关Java分布式缓存系统内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!