基于OpenCv的人脸识别(Python完整代码)
实验环境:python 3.6 + opencv-python 3.4.14.51
建议使用 anaconda配置相同环境
背景
人脸识别步骤
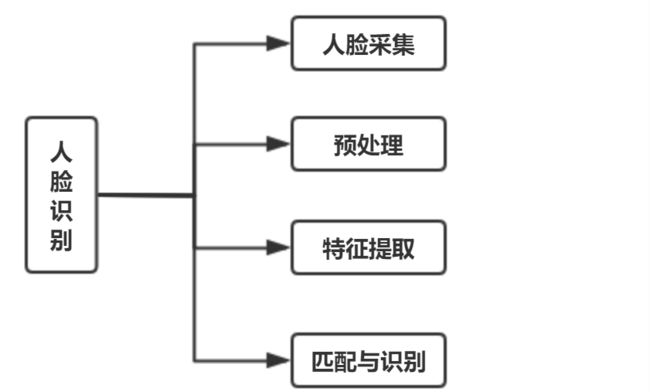
人脸采集
采集人脸图片的方法多种多样,可以直接从网上下载数据集,可以从视频中提取图片,还可以从摄像头实时的采集图片。
人脸检测方法
人脸检测在实际中主要用于人脸识别的预处理,即在图像中准确标定出人脸的位置和大小。人脸图像中包含的模式特征十分丰富,如直方图特征、颜色特征、模板特征、结构特征及Haar特征等。人脸检测就是把这其中有用的信息挑出来,并利用这些特征实现人脸检测。
人脸图像预处理
对于人脸的图像预处理是基于人脸检测结果,对图像进行处理并最终服务于特征提取的过程。系统获取的原始图像由于受到各种条件的限制和随机 干扰,往往不能直接使用,必须在图像处理的早期阶段对它进行灰度校正、噪声过滤等图像预处理。对于人脸图像而言,其预处理过程主要包括人脸图像的光线补 偿、灰度变换、直方图均衡化、归一化、几何校正、滤波以及锐化等。
人脸特征提取
人脸识别系统可使用的特征通常分为视觉特征、像素统计特征、人脸图像变换系数特征、人脸图像代数 特征等。人脸特征提取就是针对人脸的某些特征进行的。人脸特征提取,也称人脸表征,它是对人脸进行特征建模的过程。人脸特征提取的方法归纳起来分为两大 类:一种是基于知识的表征方法;另外一种是基于代数特征或统计学习的表征方法。
匹配与识别
提取的人脸图像的特征数据与数据库中存储的特征模板进行搜索匹配,通过设定一个阈值,当相似度超过这一阈值,则把匹配得到的结果输 出。人脸识别就是将待识别的人脸特征与已得到的人脸特征模板进行比较,根据相似程度对人脸的身份信息进行判断。这一过程又分为两类:一类是确认,是一对一 进行图像比较的过程,另一类是辨认,是一对多进行图像匹配对比的过程。
关于OpenCv
Opencv是一个开源的的跨平台计算机视觉库,内部实现了图像处理和计算机视觉方面的很多通用算法,对于python而言,在引用opencv库的时候需要写为import cv2。其中,cv2是opencv的C++命名空间名称,使用它来表示调用的是C++开发的opencv的接口
目前人脸识别有很多较为成熟的方法,这里调用OpenCv库,而OpenCV又提供了三种人脸识别方法,分别是LBPH方法、EigenFishfaces方法、Fisherfaces方法。本文采用的是LBPH(Local Binary Patterns Histogram,局部二值模式直方图)方法。在OpenCV中,可以用函数cv2.face.LBPHFaceRecognizer_create()生成LBPH识别器实例模型,然后应用cv2.face_FaceRecognizer.train()函数完成训练,最后用cv2.face_FaceRecognizer.predict()函数完成人脸识别。
CascadeClassifier,是Opencv中做人脸检测的时候的一个级联分类器。并且既可以使用Haar,也可以使用LBP特征。其中Haar特征是一种反映图像的灰度变化的,像素分模块求差值的一种特征。它分为三类:边缘特征、线性特征、中心特征和对角线特征。
程序设计
人脸识别算法:
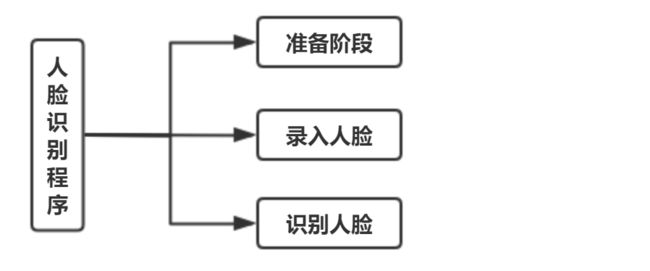
1.准备工作
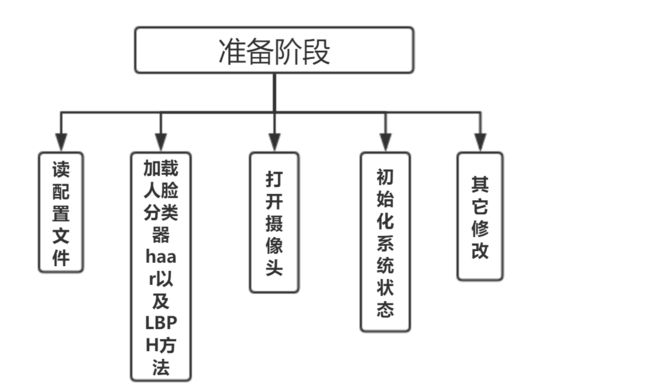
首先读取config文件,文件中第一行代表当前已经储存的人名个数,接下来每一行是二元组(id,name)即标签和对应的人名
读取结果存到以下两个全局变量中。
id_dict = {} # 字典里存的是id——name键值对
Total_face_num = 999 # 已经被识别有用户名的人脸个数,
def init(): # 将config文件内的信息读入到字典中
加载人脸检测分类器Haar,并准备好识别方法LBPH方法
# 加载OpenCV人脸检测分类器Haar
face_cascade = cv2.CascadeClassifier("haarcascade_frontalface_default.xml")
# 准备好识别方法LBPH方法
recognizer = cv2.face.LBPHFaceRecognizer_create()
然后打开标号为0的摄像头
camera = cv2.VideoCapture(0) # 摄像头
success, img = camera.read() # 从摄像头读取照片
2.录入新面容
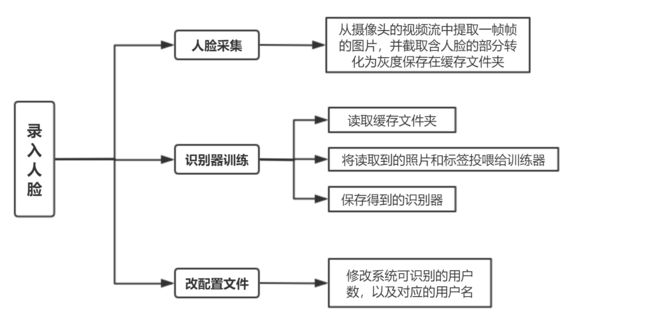
2.1采集面容
创建文件夹data用于储存本次从摄像头采集到的照片,每次调用前先清空这个目录。
然后是一个循环,循环次数为需要采集的样本数,摄像头拍摄取样的数量,越多效果越好,但获取以及训练的越慢。
循环内调用camera.read()返回值赋给全局变量success,和img 用于在GUI中实时显示。
然后调用cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)用于将采集到的图片转为灰度图片减少计算量。
然后利用加载好的人脸分类器将每一帧摄像头记录的数据带入OpenCv中,让Classifier判断人脸。
# 其中gray为要检测的灰度图像,1.3为每次图像尺寸减小的比例,5为minNeighbors
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
faces为在img图像中检测到的人脸,然后利用cv2.rectangle在人脸一圈画个矩形。并把含有人脸的区域储存进入data文件夹
注意这里写入时,每个图片的标签时Total_face_num即当前共有多少个可识别用户(在录入之前加一),亦即当前用户的编号
cv2.rectangle(img, (x, y), (x + w, y + w), (255, 0, 0))
cv2.imwrite("./data/User." + str(T) + '.' + str(sample_num) + '.jpg', gray[y:y + h, x:x + w])
然后在循环末尾最后打印一个进度条,用于提示采集图像的进度
主要原理就是每次输出不换行并且将光标移动到当前行的开头,输出内容根据进度不断变化即可,同时在控件的提示框也输出进度信息
print("\r" + "%{:.1f}".format(sample_num / pictur_num * 100) + "=" * l + "->" + "_" * r, end="")
var.set("%{:.1f}".format(sample_num / pictur_num * 100)) # 控件可视化进度信息
window.update() # 刷新控件以实时显示进度
2.2训练识别器
读取data文件夹,读取照片内的信息,得到两个数组,一个faces存的是所有脸部信息、一个ids存的是faces内每一个脸部对应的标签,然后将这两个数组传给 recog.train用于训练
# 训练模型 #将输入的所有图片转成四维数组
recog.train(faces, np.array(ids))
训练完毕后保存训练得到的识别器到.yml文件中,文件名为人脸编号+.yml
recog.save(str(Total_face_num) + ".yml")
2.3修改配置文件
每一次训练结束都要修改配置文件,具体要修改的地方是第一行和最后一行。
第一行有一个整数代表当前系统已经录入的人脸的总数,每次修改都加一。这里修改文件的方式是先读入内存,然后修改内存中的数据,最后写回文件。
f = open('config.txt', 'r+')
flist = f.readlines()
flist[0] = str(int(flist[0]) + 1) + " \n"
f.close()
f = open('config.txt', 'w+')
f.writelines(flist)
f.close()
还要在最后一行加入一个二元组用以标识用户。
格式为:标签+空格+用户名+空格,用户名默认为Userx(其中x标识用户编号)
f.write(str(T) + " User" + str(T) + " \n")
3.人脸识别(刷脸)
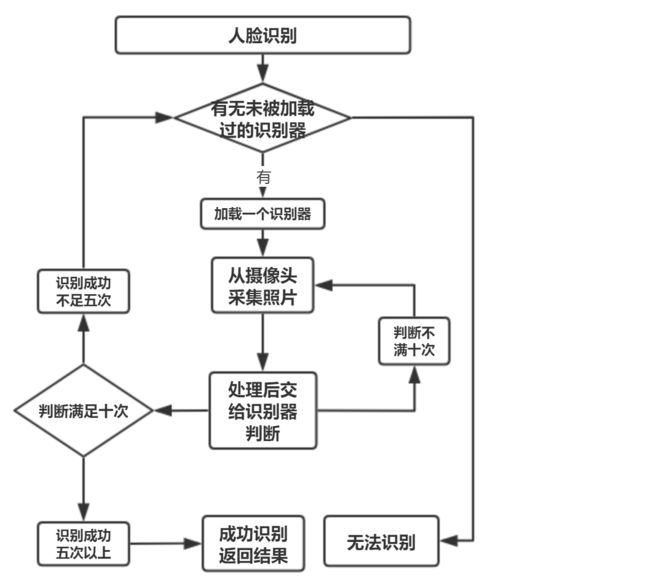
由于这里采用多个.yml文件来储存识别器(实际操作时储存在一个文件中识别出错所以采用这种方式),所以在识别时需要遍历所有的.yml文件,如果每一个都不能识别才得出无法识别的结果,相反只要有一个可以识别当前对象就返回可以识别的结果。而对于每一个文件都识别十次人脸,若成功五次以上则表示最终结果为可以识别,否则表示当前文件无法识别这个人脸。
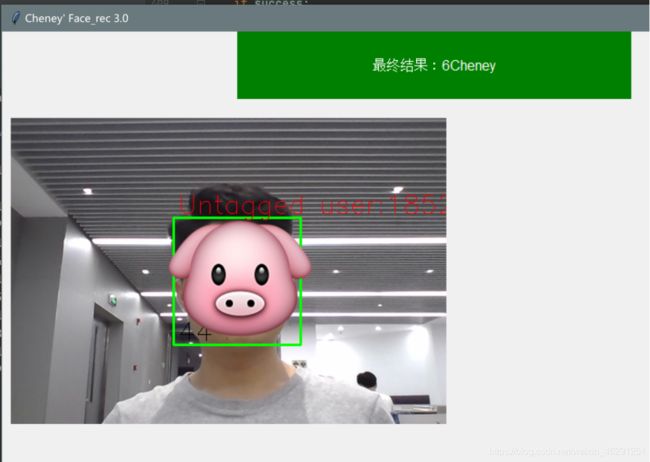
识别过程中在GUI的控件中实时显示拍摄到的内容,并在人脸周围画一个矩形框,并根据识别器返回的结果实时显示在矩形框附近。
idnum, confidence = recognizer.predict(gray[y:y + h, x:x + w])
# 加载一个字体用于输出识别对象的信息
font = cv2.FONT_HERSHEY_SIMPLEX
# 输出检验结果以及用户名
cv2.putText(img, str(user_name), (x + 5, y - 5), font, 1, (0, 0, 255), 1)
cv2.putText(img, str(confidence), (x + 5, y + h - 5), font, 1, (0, 0, 0), 1)
多线程:
程序的两个功能之间可以独立运行,就需要采用多线程的方法,但当遇到临界资源的使用时,多个进程/线程之间就要互斥的访问以免出错,本程序中具体的设计方法:
本程序采用多线程的方法实现并行。
程序的三个按钮对应着三个功能,分别是录入人脸、人脸检测、退出程序。
由于程序中的用户界面是利用python中的tkinter库做的,其按钮的响应函数用command指出,所以这里在每个command跳转到的函数中设置多线程,每敲击一次就用threading.Thread创建一个新的线程,然后在新的线程的处理函数target中实现按钮原本对应的功能。
p = threading.Thread(target=f_scan_face_thread)
在涉及到摄像头的访问时,线程之间需要互斥的访问,所以设置了一个全局的变量system_state_lock 来表示当前系统的状态,用以实现带有优先级的互斥锁的功能。
锁状态为0表示摄像头未被使用,1表示正在刷脸,2表示正在录入新面容。
程序在实际执行的过程中如果状态为0,则无论是刷脸还是录入都能顺利执行,如果状态为1表示正在刷脸,如果此时敲击刷脸按钮则,系统会提示正在刷脸并拒绝新的请求,如果此时敲击录入面容按钮,由于录入面容优先级比刷脸高,所以原刷脸线程会被阻塞,
global system_state_lock
while system_state_lock == 2: # 如果正在录入新面孔就阻塞
pass
新的录入面容进程开始执行并修改系统状态为2,录入完成后状态变为原状态,被阻塞的刷脸进程继续执行,录入人脸线程刚执行完录入阶段现在正在训练,此时有两个线程并行,以此来保证训练数据的同时不影响系统的使用。
对于退出的功能,直接在函数内调用exit(),但是python的线程会默认等待子线程全部结束再退出,所以用p.setDaemon(True)将线程设置为守护线程,这样在主线程退出之后其它线程也都退出从而实现退出整个程序的功能。
GUI设计:
程序采用python中的tkinter库做可视化,优点是占用资源小、轻量化、方便。
- 首先创建一个窗口命名为window然后设置其大小和标题等属性。
- 然后在界面上设定一个绿底的标签,类似于一个提示窗口的作用
- 然后分别创建三个按钮,并设置响应函数和提示字符,放置在window内部。
- 然后设置一个label类型的控件用于动态的展示摄像头的内容(将摄像头显示嵌入到控件中)。具体方法:创建video_loop()函数,在函数内访问全局的变量img,img是从摄像头读取到的图像数据。然后把img显示在label内。
使用window.after方法,在给定时间后调用函数一次,实现固定时间刷新控件,从而达到实时显示摄像头画面在GUI中的效果。
window.after(1, video_loop)
# 这句的意思是一秒以后执行video_loop函数
# 因为这一句是写在video_loop函数中的所以每过一秒函数执行一次。
运行测试
说明
测试环境:python 3.6 + opencv-python 3.4.14.51
需要的包:
录入人脸
从数据集录入
从摄像头录入

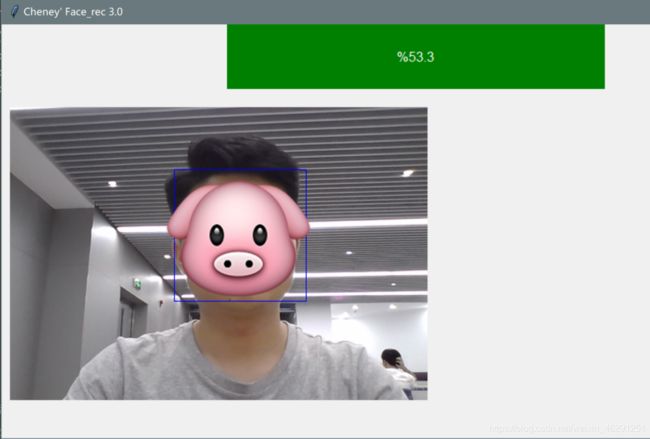
人脸识别
代码实现:
# 实验环境:python 3.6 + opencv-python 3.4.14.51
import cv2
import numpy as np
import os
import shutil
import threading
import tkinter as tk
from PIL import Image, ImageTk
# 首先读取config文件,第一行代表当前已经储存的人名个数,接下来每一行是(id,name)标签和对应的人名
id_dict = {} # 字典里存的是id——name键值对
Total_face_num = 999 # 已经被识别有用户名的人脸个数,
def init(): # 将config文件内的信息读入到字典中
f = open('config.txt')
global Total_face_num
Total_face_num = int(f.readline())
for i in range(int(Total_face_num)):
line = f.readline()
id_name = line.split(' ')
id_dict[int(id_name[0])] = id_name[1]
f.close()
init()
# 加载OpenCV人脸检测分类器Haar
face_cascade = cv2.CascadeClassifier("haarcascade_frontalface_default.xml")
# 准备好识别方法LBPH方法
recognizer = cv2.face.LBPHFaceRecognizer_create()
# 打开标号为0的摄像头
camera = cv2.VideoCapture(0) # 摄像头
success, img = camera.read() # 从摄像头读取照片
W_size = 0.1 * camera.get(3)
H_size = 0.1 * camera.get(4)
system_state_lock = 0 # 标志系统状态的量 0表示无子线程在运行 1表示正在刷脸 2表示正在录入新面孔。
# 相当于mutex锁,用于线程同步
'''
============================================================================================
以上是初始化
============================================================================================
'''
def Get_new_face():
print("正在从摄像头录入新人脸信息 \n")
# 存在目录data就清空,不存在就创建,确保最后存在空的data目录
filepath = "data"
if not os.path.exists(filepath):
os.mkdir(filepath)
else:
shutil.rmtree(filepath)
os.mkdir(filepath)
sample_num = 0 # 已经获得的样本数
while True: # 从摄像头读取图片
global success
global img # 因为要显示在可视化的控件内,所以要用全局的
success, img = camera.read()
# 转为灰度图片
if success is True:
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
else:
break
# 检测人脸,将每一帧摄像头记录的数据带入OpenCv中,让Classifier判断人脸
# 其中gray为要检测的灰度图像,1.3为每次图像尺寸减小的比例,5为minNeighbors
face_detector = face_cascade
faces = face_detector.detectMultiScale(gray, 1.3, 5)
# 框选人脸,for循环保证一个能检测的实时动态视频流
for (x, y, w, h) in faces:
# xy为左上角的坐标,w为宽,h为高,用rectangle为人脸标记画框
cv2.rectangle(img, (x, y), (x + w, y + w), (255, 0, 0))
# 样本数加1
sample_num += 1
# 保存图像,把灰度图片看成二维数组来检测人脸区域,这里是保存在data缓冲文件夹内
T = Total_face_num
cv2.imwrite("./data/User." + str(T) + '.' + str(sample_num) + '.jpg', gray[y:y + h, x:x + w])
pictur_num = 30 # 表示摄像头拍摄取样的数量,越多效果越好,但获取以及训练的越慢
cv2.waitKey(1)
if sample_num > pictur_num:
break
else: # 控制台内输出进度条
l = int(sample_num / pictur_num * 50)
r = int((pictur_num - sample_num) / pictur_num * 50)
print("\r" + "%{:.1f}".format(sample_num / pictur_num * 100) + "=" * l + "->" + "_" * r, end="")
var.set("%{:.1f}".format(sample_num / pictur_num * 100)) # 控件可视化进度信息
# tk.Tk().update()
window.update() # 刷新控件以实时显示进度
def Train_new_face():
print("\n正在训练")
# cv2.destroyAllWindows()
path = 'data'
# 初始化识别的方法
recog = cv2.face.LBPHFaceRecognizer_create()
# 调用函数并将数据喂给识别器训练
faces, ids = get_images_and_labels(path)
print('本次用于训练的识别码为:') # 调试信息
print(ids) # 输出识别码
# 训练模型 #将输入的所有图片转成四维数组
recog.train(faces, np.array(ids))
# 保存模型
yml = str(Total_face_num) + ".yml"
rec_f = open(yml, "w+")
rec_f.close()
recog.save(yml)
# recog.save('aaa.yml')
# 创建一个函数,用于从数据集文件夹中获取训练图片,并获取id
# 注意图片的命名格式为User.id.sampleNum
def get_images_and_labels(path):
image_paths = [os.path.join(path, f) for f in os.listdir(path)]
# 新建连个list用于存放
face_samples = []
ids = []
# 遍历图片路径,导入图片和id添加到list中
for image_path in image_paths:
# 通过图片路径将其转换为灰度图片
img = Image.open(image_path).convert('L')
# 将图片转化为数组
img_np = np.array(img, 'uint8')
if os.path.split(image_path)[-1].split(".")[-1] != 'jpg':
continue
# 为了获取id,将图片和路径分裂并获取
id = int(os.path.split(image_path)[-1].split(".")[1])
# 调用熟悉的人脸分类器
detector = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
faces = detector.detectMultiScale(img_np)
# 将获取的图片和id添加到list中
for (x, y, w, h) in faces:
face_samples.append(img_np[y:y + h, x:x + w])
ids.append(id)
return face_samples, ids
def write_config():
print("新人脸训练结束")
f = open('config.txt', "a")
T = Total_face_num
f.write(str(T) + " User" + str(T) + " \n")
f.close()
id_dict[T] = "User" + str(T)
# 这里修改文件的方式是先读入内存,然后修改内存中的数据,最后写回文件
f = open('config.txt', 'r+')
flist = f.readlines()
flist[0] = str(int(flist[0]) + 1) + " \n"
f.close()
f = open('config.txt', 'w+')
f.writelines(flist)
f.close()
'''
============================================================================================
以上是录入新人脸信息功能的实现
============================================================================================
'''
def scan_face():
# 使用之前训练好的模型
for i in range(Total_face_num): # 每个识别器都要用
i += 1
yml = str(i) + ".yml"
print("\n本次:" + yml) # 调试信息
recognizer.read(yml)
ave_poss = 0
for times in range(10): # 每个识别器扫描十遍
times += 1
cur_poss = 0
global success
global img
global system_state_lock
while system_state_lock == 2: # 如果正在录入新面孔就阻塞
print("\r刷脸被录入面容阻塞", end="")
pass
success, img = camera.read()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 识别人脸
faces = face_cascade.detectMultiScale(
gray,
scaleFactor=1.2,
minNeighbors=5,
minSize=(int(W_size), int(H_size))
)
# 进行校验
for (x, y, w, h) in faces:
# global system_state_lock
while system_state_lock == 2: # 如果正在录入新面孔就阻塞
print("\r刷脸被录入面容阻塞", end="")
pass
# 这里调用Cv2中的rectangle函数 在人脸周围画一个矩形
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
# 调用分类器的预测函数,接收返回值标签和置信度
idnum, confidence = recognizer.predict(gray[y:y + h, x:x + w])
conf = confidence
# 计算出一个检验结果
if confidence < 100: # 可以识别出已经训练的对象——直接输出姓名在屏幕上
if idnum in id_dict:
user_name = id_dict[idnum]
else:
# print("无法识别的ID:{}\t".format(idnum), end="")
user_name = "Untagged user:" + str(idnum)
confidence = "{0}%", format(round(100 - confidence))
else: # 无法识别此对象,那么就开始训练
user_name = "unknown"
# print("检测到陌生人脸\n")
# cv2.destroyAllWindows()
# global Total_face_num
# Total_face_num += 1
# Get_new_face() # 采集新人脸
# Train_new_face() # 训练采集到的新人脸
# write_config() # 修改配置文件
# recognizer.read('aaa.yml') # 读取新识别器
# 加载一个字体用于输出识别对象的信息
font = cv2.FONT_HERSHEY_SIMPLEX
# 输出检验结果以及用户名
cv2.putText(img, str(user_name), (x + 5, y - 5), font, 1, (0, 0, 255), 1)
cv2.putText(img, str(confidence), (x + 5, y + h - 5), font, 1, (0, 0, 0), 1)
# 展示结果
# cv2.imshow('camera', img)
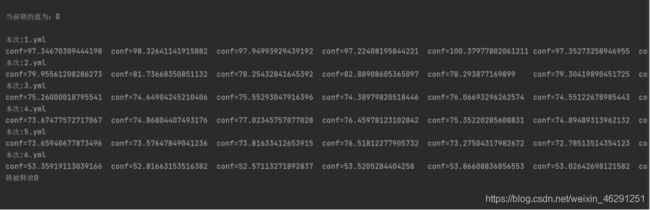
print("conf=" + str(conf), end="\t")
if 15 > conf > 0:
cur_poss = 1 # 表示可以识别
elif 60 > conf > 35:
cur_poss = 1 # 表示可以识别
else:
cur_poss = 0 # 表示不可以识别
k = cv2.waitKey(1)
if k == 27:
# cam.release() # 释放资源
cv2.destroyAllWindows()
break
ave_poss += cur_poss
if ave_poss >= 5: # 有一半以上识别说明可行则返回
return i
return 0 # 全部过一遍还没识别出说明无法识别
'''
============================================================================================
以上是关于刷脸功能的设计
============================================================================================
'''
def f_scan_face_thread():
# 使用之前训练好的模型
# recognizer.read('aaa.yml')
var.set('刷脸')
ans = scan_face()
if ans == 0:
print("最终结果:无法识别")
var.set("最终结果:无法识别")
else:
ans_name = "最终结果:" + str(ans) + id_dict[ans]
print(ans_name)
var.set(ans_name)
global system_state_lock
print("锁被释放0")
system_state_lock = 0 # 修改system_state_lock,释放资源
def f_scan_face():
global system_state_lock
print("\n当前锁的值为:" + str(system_state_lock))
if system_state_lock == 1:
print("阻塞,因为正在刷脸")
return 0
elif system_state_lock == 2: # 如果正在录入新面孔就阻塞
print("\n刷脸被录入面容阻塞\n"
"")
return 0
system_state_lock = 1
p = threading.Thread(target=f_scan_face_thread)
p.setDaemon(True) # 把线程P设置为守护线程 若主线程退出 P也跟着退出
p.start()
def f_rec_face_thread():
var.set('录入')
cv2.destroyAllWindows()
global Total_face_num
Total_face_num += 1
Get_new_face() # 采集新人脸
print("采集完毕,开始训练")
global system_state_lock # 采集完就可以解开锁
print("锁被释放0")
system_state_lock = 0
Train_new_face() # 训练采集到的新人脸
write_config() # 修改配置文件
# recognizer.read('aaa.yml') # 读取新识别器
# global system_state_lock
# print("锁被释放0")
# system_state_lock = 0 # 修改system_state_lock,释放资源
def f_rec_face():
global system_state_lock
print("当前锁的值为:" + str(system_state_lock))
if system_state_lock == 2:
print("阻塞,因为正在录入面容")
return 0
else:
system_state_lock = 2 # 修改system_state_lock
print("改为2", end="")
print("当前锁的值为:" + str(system_state_lock))
p = threading.Thread(target=f_rec_face_thread)
p.setDaemon(True) # 把线程P设置为守护线程 若主线程退出 P也跟着退出
p.start()
# tk.Tk().update()
# system_state_lock = 0 # 修改system_state_lock,释放资源
def f_exit(): # 退出按钮
exit()
'''
============================================================================================
以上是关于多线程的设计
============================================================================================
'''
window = tk.Tk()
window.title('Cheney\' Face_rec 3.0') # 窗口标题
window.geometry('1000x500') # 这里的乘是小x
# 在图形界面上设定标签,类似于一个提示窗口的作用
var = tk.StringVar()
l = tk.Label(window, textvariable=var, bg='green', fg='white', font=('Arial', 12), width=50, height=4)
# 说明: bg为背景,fg为字体颜色,font为字体,width为长,height为高,这里的长和高是字符的长和高,比如height=2,就是标签有2个字符这么高
l.pack() # 放置l控件
# 在窗口界面设置放置Button按键并绑定处理函数
button_a = tk.Button(window, text='开始刷脸', font=('Arial', 12), width=10, height=2, command=f_scan_face)
button_a.place(x=800, y=120)
button_b = tk.Button(window, text='录入人脸', font=('Arial', 12), width=10, height=2, command=f_rec_face)
button_b.place(x=800, y=220)
button_b = tk.Button(window, text='退出', font=('Arial', 12), width=10, height=2, command=f_exit)
button_b.place(x=800, y=320)
panel = tk.Label(window, width=500, height=350) # 摄像头模块大小
panel.place(x=10, y=100) # 摄像头模块的位置
window.config(cursor="arrow")
def video_loop(): # 用于在label内动态展示摄像头内容(摄像头嵌入控件)
# success, img = camera.read() # 从摄像头读取照片
global success
global img
if success:
cv2.waitKey(1)
cv2image = cv2.cvtColor(img, cv2.COLOR_BGR2RGBA) # 转换颜色从BGR到RGBA
current_image = Image.fromarray(cv2image) # 将图像转换成Image对象
imgtk = ImageTk.PhotoImage(image=current_image)
panel.imgtk = imgtk
panel.config(image=imgtk)
window.after(1, video_loop)
video_loop()
# 窗口循环,用于显示
window.mainloop()
'''
============================================================================================
以上是关于界面的设计
============================================================================================
'''