保姆级Hadoop集群部署
程序员小王的博客:程序员小王的博客
欢迎点赞 收藏 ⭐留言
如有编辑错误联系作者,如果有比较好的文章欢迎分享给我,我会取其精华去其糟粕
目录
一、准备三台linux并实现三台机器机器免密码登录
1、三台机器生成公钥与私钥
2、拷贝公钥到同一台机器
3、复制第一台机器的认证到其他机器
二、三台机器时钟同步
三、hadoop集群搭建
1、解压
2、修改配置文件
3、创建数据和临时文件夹
4、分发安装包到其它机器
5、在每个节点配置环境变量
6、格式化HDFS
7、启动集群
8、访问
一、准备三台linux并实现三台机器机器免密码登录
-
为什么要免密登录
-
Hadoop 节点众多, 所以一般在主节点启动从节点, 这个时候就需要程序自动在主节点登录到从节点中, 如果不能免密就每次都要输入密码, 非常麻烦
-
-
免密 SSH 登录的原理
-
需要先在 B节点 配置 A节点 的公钥
-
A节点 请求 B节点 要求登录
-
B节点 使用 A节点 的公钥, 加密一段随机文本
-
A节点 使用私钥解密, 并发回给 B节点
-
B节点 验证文本是否正确
-
1、三台机器生成公钥与私钥
-
在三台机器执行以下命令,生成公钥与私钥
ssh-keygen -t rsa
执行该命令之后,按下三个回车即可

2、拷贝公钥到同一台机器
三台机器将拷贝公钥到第一台机器
-
三台机器执行命令:
ssh-copy-id node1

-
如果报错及解决办法
/usr/bin/ssh-copy-id: ERROR: ssh: Could not resolve hostname node1:
Name or service not known
-
解决办法:在集群上的所有机器上执行vi /etc/hosts
192.168.43.129 node1
192.168.43.130 node2
192.168.43.131 node3
3、复制第一台机器的认证到其他机器
将第一台机器的公钥拷贝到其他机器上
在第一台机器上面指向以下命令
scp /root/.ssh/authorized_keys node2:/root/.ssh
scp /root/.ssh/authorized_keys node3:/root/.ssh

二、三台机器时钟同步
-
为什么需要时间同步
-
因为很多分布式系统是有状态的, 比如说存储一个数据, A节点 记录的时间是 1, B节点 记录的时间是 2, 就会出问题
-
## 安装
yum install -y ntp
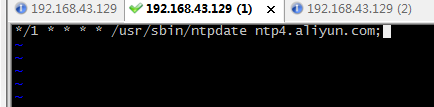
## 启动定时任务
crontab -e
随后在输入界面键入
*/1 * * * * /usr/sbin/ntpdate ntp4.aliyun.com;
三、hadoop集群搭建
-
如果需要单机部署参考博客:单机部署hadoop2.7.3_程序员小王java的博客-CSDN博客
| 服务器IP | 192.168.43.129 | 192.168.43.130 | 192.168.43.131 |
|---|---|---|---|
| 主机名 | node1 | node2 | node3 |
| NameNode | 是 | 否 | 否 |
| SecondaryNameNode | 是 | 否 | 否 |
| dataNode | 是 | 是 | 是 |
| ResourceManager | 是 | 否 | 否 |
| NodeManager | 是 | 是 | 是 |
-
怎么将ip地址设置主机名参考我的博客:http://t.csdn.cn/3wpT6
1、解压
tar xzvf hadoop-3.1.1.tar.gz
#修改名字
mv hadoop-3.1.1 hadoop
2、修改配置文件
配置文件的位置在 hadoop/etc/hadoop
-
core-site.xmlll
fs.defaultFS
hdfs://node1:8020
hadoop.tmp.dir
/usr/apps/hadoop/tmp
io.file.buffer.size
8192
fs.trash.interval
10080
-
hadoop-env.sh[2]
#java,自己的java地址
export JAVA_HOME=/usr/java/jdk1.8.0_171-amd64/
-
hdfs-site.xml
dfs.namenode.name.dir
file:///usr/apps/hadoop/datas/datanode/datanodeDatas
dfs.blocksize
134217728
dfs.namenode.handler.count
10
dfs.datanode.data.dir
file:///usr/apps/hadoop/datas/datanode/datanodeDatas
dfs.namenode.http-address
node1:50070
dfs.replication
3
dfs.permissions.enabled
false
dfs.namenode.checkpoint.edits.dir
file:///usr/apps/hadoop/datas/dfs/nn/snn/edits
dfs.namenode.secondary.http-address
node1.hadoop.com:50090
dfs.namenode.edits.dir
file:///usr/apps/hadoop/datas/dfs/nn/edits
dfs.namenode.checkpoint.dir
file:///usr/apps/hadoop/datas/dfs/snn/name
-
mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.map.memory.mb
1024
mapreduce.map.java.opts
-Xmx512M
mapreduce.reduce.memory.mb
1024
mapreduce.reduce.java.opts
-Xmx512M
mapreduce.task.io.sort.mb
256
mapreduce.task.io.sort.factor
100
mapreduce.reduce.shuffle.parallelcopies
25
mapreduce.jobhistory.address
node1.hadoop.com:10020
mapreduce.jobhistory.webapp.address
node1.hadoop.com:19888
mapreduce.jobhistory.intermediate-done-dir
/usr/apps/hadoop/datas/jobhsitory/intermediateDoneDatas
mapreduce.jobhistory.done-dir
/usr/apps/hadoop/datas/jobhsitory/DoneDatas
yarn.app.mapreduce.am.env
HADOOP_MAPRED_HOME=/usr/apps/hadoop
mapreduce.map.env
HADOOP_MAPRED_HOME=/usr/apps/hadoop/
mapreduce.reduce.env
HADOOP_MAPRED_HOME=/usr/apps/hadoop
-
yarn-site.xml
dfs.namenode.handler.count
100
yarn.log-aggregation-enable
true
yarn.resourcemanager.address
node1:8032
yarn.resourcemanager.scheduler.address
node1:8030
yarn.resourcemanager.resource-tracker.address
node1:8031
yarn.resourcemanager.admin.address
node1:8033
yarn.resourcemanager.webapp.address
node1:8088
yarn.resourcemanager.hostname
node1
yarn.scheduler.minimum-allocation-mb
1024
yarn.scheduler.maximum-allocation-mb
2048
yarn.nodemanager.vmem-pmem-ratio
2.1
yarn.nodemanager.vmem-check-enabled
false
yarn.nodemanager.resource.memory-mb
1024
yarn.nodemanager.resource.detect-hardware-capabilities
true
yarn.nodemanager.local-dirs
file:///usr/apps/hadoop/datas/nodemanage/nodemanagerLogs
yarn.nodemanager.log-dirs
file:///usr/apps/hadoop/datas/nodemanage/nodemanagerLogs
yarn.nodemanager.log.retain-seconds
10800
yarn.nodemanager.remote-app-log-dir
/usr/apps/hadoop/datas/remoteAppLog/remoteAppLogs
yarn.nodemanager.remote-app-log-dir-suffix
logs
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.log-aggregation.retain-seconds
18144000
yarn.log-aggregation.retain-check-interval-seconds
86400
yarn.app.mapreduce.am.resource.mb
1024
-
worker
node1
node2
node3

3、创建数据和临时文件夹
mkdir -p /usr/apps/hadoop/datas/tmp
mkdir -p /usr/apps/hadoop/datas/dfs/nn/snn/edits
mkdir -p /usr/apps/hadoop/datas/namenode/namenodedatas
mkdir -p /usr/apps/hadoop/datas/datanode/datanodeDatas
mkdir -p /usr/apps/hadoop/datas/dfs/nn/edits
mkdir -p /usr/apps/hadoop/datas/dfs/snn/name
mkdir -p /usr/apps/hadoop/datas/jobhsitory/intermediateDoneDatas
mkdir -p /usr/apps/hadoop/datas/jobhsitory/DoneDatas
mkdir -p /usr/apps/hadoop/datas/nodemanager/nodemanagerDatas
mkdir -p /usr/apps/hadoop/datas/nodemanager/nodemanagerLogs
mkdir -p /usr/apps/hadoop/datas/remoteAppLog/remoteAppLogs
4、分发安装包到其它机器
scp -r /usr/apps/hadoop node2:/usr/apps/hadoop
scp -r /usr/apps/hadoop node3:/usr/apps/hadoop
5、在每个节点配置环境变量
-
vi /etc/profile
#hadoop
export HADOOP_HOME=/usr/apps/hadoop/
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
6、格式化HDFS
-
为什么要格式化HDFS
-
HDFS需要一个格式化的过程来创建存放元数据(image, editlog)的目录
-
bin/hdfs namenode -format
7、启动集群
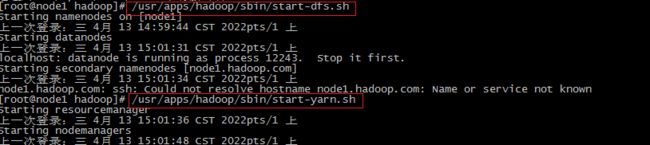
# 会登录进所有的worker启动相关进行, 也可以手动进行, 但是没必要
/usr/apps/hadoop/sbin/start-dfs.sh
/usr/apps/hadoop/sbin/start-yarn.sh mapred --daemon start historyserver
8、访问
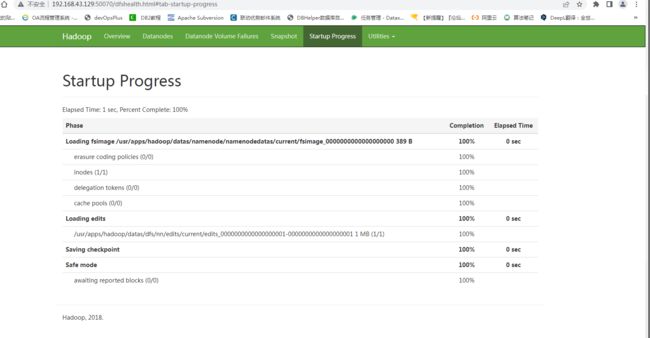
此时便可以通过如下三个URL访问Hadoop了
-
HDFS: http://192.168.43.129:50070/dfshealth.html#tab-startup-progress
-
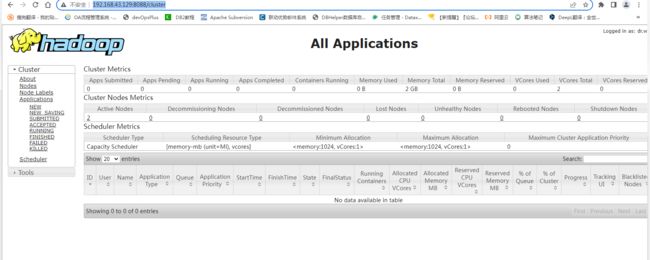
Yarn: http://192.168.43.129:8088/cluster
-
报错:设置hadoop-env.sh
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_SECONDARYNAMENODE_USER="root"
export YARN_RESOURCEMANAGER_USER="root"
export YARN_NODEMANAGER_USER="root"