NLP学习(十四)-NLP实战之文本分类-中文垃圾邮件分类-Python3
一、文本分类实现步骤:
定义阶段:定义数据以及分类体系,具体分为哪些类别,需要哪些数据
数据预处理:对文档做分词、去停用词等准备工作
数据提取特征:对文档矩阵进行降维、提取训练集中最有用的特征
模型训练阶段:选择具体的分类模型以及算法,训练出文本分类器
评测阶段:在测试集上测试并评价分类器的性能
应用阶段:应用性能最高的分类模型对待分类文档进行分类
二、特征提取的几种经典方法:
词袋法(BOW):bag of words,最原始的特征集,一个单词/分词就是一个特征。
往往会导致一个数据集有上万个特征,有一些的简单指标可以筛选掉一些对分类没帮助的词语,如去停用词、计算互信息熵等。
但总的来说,特征维度都很大,每个特征的信息量太小
统计特征:TF-IDF方法(term frequency词频–inverse document frequency逆文档频率)。主要是用词汇的统计特征来作为特征集,每个特征都有其物理意义,看起来会比 bag-of-word 好,实际效果差不多
N-gram:一种考虑词汇顺序的模型,也就是 N 阶 Markov(马尔可夫) 链,每个样本转移成转移概率矩阵,有不错的效果
三、分类器方法:
朴素贝叶斯(Naive Bayesian, NB)
对于给定的训练集,首先基于特征条件独立学习输入、输出的联合概率分布P(X,Y),然后基于此模型,对给定的输入x ,利用贝叶斯定理求出后验概率最大的输出 y yy
假设P(X,Y) 独立分布,通过训练集合学习联合概率分布P(X,Y)
P(X, Y)=P(Y|X)·P(X)=P(X|Y)·P(Y)
根据上面的等式可得贝叶斯理论的一般形式
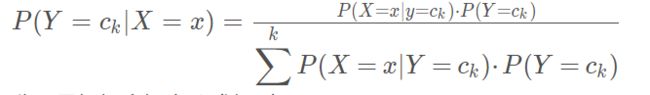
分母是根据全概率公式得到
因此,朴素贝叶斯可以表示为:
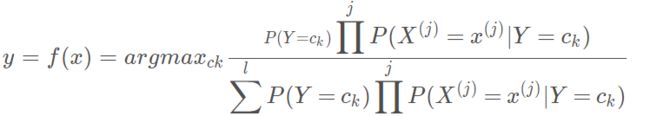
为了简化计算,可以将相同的分母去掉
优点:实现简单,学习与预测的效率都很高
缺点:分类的性能不一定很高
逻辑回归(Logistic Regression, lR)
一种对数线性模型,它的输出是一个概率,而不是一个确切的类别
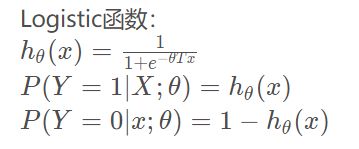
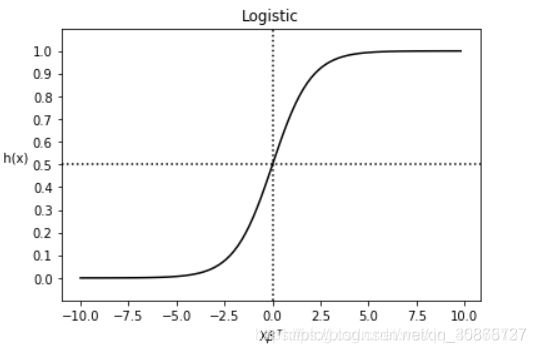
图像:
对于给定数据集,应用极大似然估计方法估计模型参数
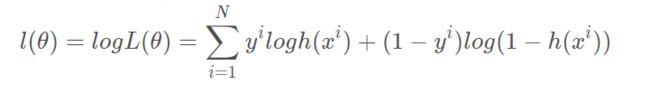
优点:实现简单、分类时计算量小、速度快、存储资源低等
缺点:容易欠拟合、准确率不高等
支持向量机(Support Vector Machine, SVM)
在特征空间中寻找到一个尽可能将两个数据集合分开的超平面(hyper-plane)
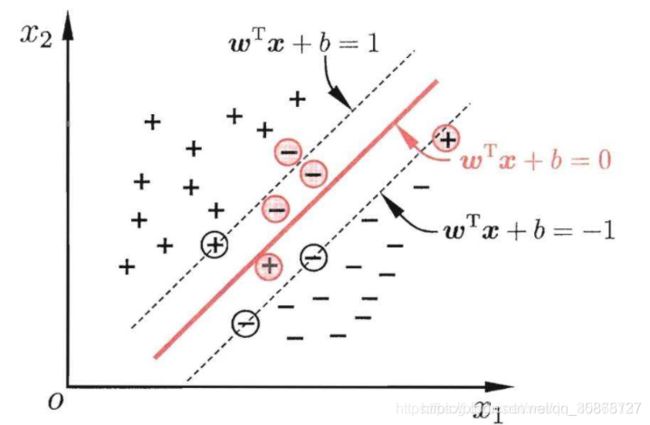
对于线性不可分的问题,需要引入核函数,将问题转换到高维空间中
优点:可用于线性/非线性分类,也可以用于回归;低泛化误差;容易解释;计算复杂度低;推导过程优美
缺点:对参数和核函数的选择敏感
四、中文垃圾邮件分类实战
数据集分为:ham_data.txt 和 Spam.data.txt , 对应为 正常邮件和垃圾邮件
数据集下载
其中每行代表着一个邮件
主要过程为:
数据提取,拆分
#获取数据
def get_data():
"""
获取数据
:return: 文本数据,对应的labels
"""
with open("../../testdata/ham_data.txt", encoding='utf-8') as ham_f, open("../../testdata/spam_data.txt",encoding='utf-8') as spam_f:
ham_data = ham_f.readlines()
spam_data = spam_f.readlines()
ham_label = np.ones(len(ham_data)).tolist() # tolist函数将矩阵类型转换为列表类型
spam_label = np.zeros(len(spam_data)).tolist()
corpus = ham_data + spam_data
labels = ham_label + spam_label
return corpus, labels
#拆分数据
def prepare_datasets(corpus, labels, test_data_proportion=0.3):
"""
:param corpus: 文本数据
:param labels: 文本标签
:param test_data_proportion: 测试集数据占比
:return: 训练数据, 测试数据, 训练labels, 测试labels
"""
x_train, x_test, y_train, y_test = train_test_split(corpus, labels, test_size=test_data_proportion,
random_state=42) # 固定random_state后,每次生成的数据相同(即模型相同)
return x_train, x_test, y_train, y_test
#删除空邮件
def remove_empty_docs(corpus, labels):
filtered_corpus = []
filtered_labels = []
for docs, label in zip(corpus, labels):
#移除字符串头尾指定的字符(默认为空格)
if docs.strip():
filtered_corpus.append(docs)
filtered_labels.append(label)
return filtered_corpus, filtered_labels
对数据进行归整化和预处理
# 加载停用词
with open("../../testdata/stop_words.utf8", encoding="utf8") as f:
stopword_list = f.readlines()
#jieba分词
def tokenize_text(text):
tokens = jieba.cut(text)
tokens = [token.strip() for token in tokens]
return tokens
#移除所有特殊字符和标点符号
def remove_special_characters(text):
# jieba分词
tokens = tokenize_text(text)
# compile 返回一个匹配对象 escape 忽视掉特殊字符含义(相当于转义,显示本身含义) string.punctuation 表示所有标点符号
pattern = re.compile('[{}]'.format(re.escape(string.punctuation)))
filtered_tokens = filter(None, [pattern.sub('', token) for token in tokens])
filtered_text = ' '.join(filtered_tokens)
return filtered_text
#去停用词
def remove_stopwords(text):
# jieba分词
tokens = tokenize_text(text)
filtered_tokens = [token for token in tokens if token not in stopword_list]
filtered_text = ''.join(filtered_tokens)
return filtered_text
#清洗数据并分词
def normalize_corpus(corpus, tokenize=False):
normalized_corpus = []
for text in corpus:
# 移除所有特殊字符和标点符号
text = remove_special_characters(text)
# 去停用词
text = remove_stopwords(text)
normalized_corpus.append(text)
if tokenize:
text = tokenize_text(text)
normalized_corpus.append(text)
return normalized_corpus
提取特征(tfidf 和 词袋模型)
# 词袋模型特征
bow_vectorizer, bow_train_features = bow_extractor(norm_train_corpus)
bow_test_features = bow_vectorizer.transform(norm_test_corpus)
# tfdf 特征
tfidf_vectorizer, tfidf_train_features = tfidf_extractor(norm_train_corpus)
tfidf_test_features = tfidf_vectorizer.transform(norm_test_corpus)
#词袋模型
def bow_extractor(corpus, ngram_range=(1, 1)):
vectorizer = CountVectorizer(min_df=1, ngram_range=ngram_range)
features = vectorizer.fit_transform(corpus)
return vectorizer, features
def tfidf_transformer(bow_matrix):
transformer = TfidfTransformer(norm='l2',
smooth_idf=True,
use_idf=True)
tfidf_matrix = transformer.fit_transform(bow_matrix)
return transformer, tfidf_matrix
# tfdf
def tfidf_extractor(corpus, ngram_range=(1, 1)):
vectorizer = TfidfVectorizer(min_df=1,
norm='l2',
smooth_idf=True,
use_idf=True,
ngram_range=ngram_range)
features = vectorizer.fit_transform(corpus)
return vectorizer, features
训练分类器
#训练模型
def train_predict_evaluate_model(classifier,
train_features, train_labels,
test_features, test_labels):
# build model
classifier.fit(train_features, train_labels)
# predict using model
predictions = classifier.predict(test_features)
# evaluate model prediction performance
get_metrics(true_labels=test_labels,
predicted_labels=predictions)
return predictions
基于词袋模型的多项式朴素贝叶斯
基于词袋模型的逻辑回归
基于词袋模型的支持向量机
基于 tfidf 的多项式朴素贝叶斯
基于 tfidf 的逻辑回归
基于 tfidf 的支持向量机
#朴素贝叶斯模型
mnb = MultinomialNB()
#支持向量机模型
svm = SGDClassifier(loss='hinge', n_iter_no_change=100)
#逻辑回归模型
lr = LogisticRegression()
# 基于词袋模型的多项朴素贝叶斯
print("基于词袋模型特征的贝叶斯分类器")
mnb_bow_predictions = train_predict_evaluate_model(classifier=mnb,
train_features=bow_train_features,
train_labels=train_labels,
test_features=bow_test_features,
test_labels=test_labels)
# 基于词袋模型特征的逻辑回归
print("基于词袋模型特征的逻辑回归")
lr_bow_predictions = train_predict_evaluate_model(classifier=lr,
train_features=bow_train_features,
train_labels=train_labels,
test_features=bow_test_features,
test_labels=test_labels)
# 基于词袋模型的支持向量机方法
print("基于词袋模型的支持向量机")
svm_bow_predictions = train_predict_evaluate_model(classifier=svm,
train_features=bow_train_features,
train_labels=train_labels,
test_features=bow_test_features,
test_labels=test_labels)
# 基于tfidf的多项式朴素贝叶斯模型
print("基于tfidf的贝叶斯模型")
mnb_tfidf_predictions = train_predict_evaluate_model(classifier=mnb,
train_features=tfidf_train_features,
train_labels=train_labels,
test_features=tfidf_test_features,
test_labels=test_labels)
# 基于tfidf的逻辑回归模型
print("基于tfidf的逻辑回归模型")
lr_tfidf_predictions = train_predict_evaluate_model(classifier=lr,
train_features=tfidf_train_features,
train_labels=train_labels,
test_features=tfidf_test_features,
test_labels=test_labels)
# 基于tfidf的支持向量机模型
print("基于tfidf的支持向量机模型")
svm_tfidf_predictions = train_predict_evaluate_model(classifier=svm,
train_features=tfidf_train_features,
train_labels=train_labels,
test_features=tfidf_test_features,
test_labels=test_labels)
用 准确率(Precision)、召回率(Recall)、F1测度 来评价模型
#预测值评估
def get_metrics(true_labels, predicted_labels):
print('准确率:', np.round(
metrics.accuracy_score(true_labels,
predicted_labels),
2))
print('精度:', np.round(
metrics.precision_score(true_labels,
predicted_labels,
average='weighted'),
2))
print('召回率:', np.round(
metrics.recall_score(true_labels,
predicted_labels,
average='weighted'),
2))
print('F1得分:', np.round(
metrics.f1_score(true_labels,
predicted_labels,
average='weighted'),
2))
5.完整代码
1.数据处理方法 normalization.py
# -*- coding: utf-8 -*-
import re # 实现正则表达式模块
import string
import jieba
# 加载停用词
with open("../../testdata/stop_words.utf8", encoding="utf8") as f:
stopword_list = f.readlines()
#jieba分词
def tokenize_text(text):
tokens = jieba.cut(text)
tokens = [token.strip() for token in tokens]
return tokens
#移除所有特殊字符和标点符号
def remove_special_characters(text):
# jieba分词
tokens = tokenize_text(text)
# compile 返回一个匹配对象 escape 忽视掉特殊字符含义(相当于转义,显示本身含义) string.punctuation 表示所有标点符号
pattern = re.compile('[{}]'.format(re.escape(string.punctuation)))
filtered_tokens = filter(None, [pattern.sub('', token) for token in tokens])
filtered_text = ' '.join(filtered_tokens)
return filtered_text
#去停用词
def remove_stopwords(text):
# jieba分词
tokens = tokenize_text(text)
filtered_tokens = [token for token in tokens if token not in stopword_list]
filtered_text = ''.join(filtered_tokens)
return filtered_text
#清洗数据并分词
def normalize_corpus(corpus, tokenize=False):
normalized_corpus = []
for text in corpus:
# 移除所有特殊字符和标点符号
text = remove_special_characters(text)
# 去停用词
text = remove_stopwords(text)
normalized_corpus.append(text)
if tokenize:
text = tokenize_text(text)
normalized_corpus.append(text)
return normalized_corpus
2.特征提取方法 feature_extractors.py
# -*- coding: utf-8 -*-
# CountVectorizer 考虑词汇在文本种出现的频数
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer, TfidfVectorizer
#词袋模型
def bow_extractor(corpus, ngram_range=(1, 1)):
vectorizer = CountVectorizer(min_df=1, ngram_range=ngram_range)
features = vectorizer.fit_transform(corpus)
return vectorizer, features
def tfidf_transformer(bow_matrix):
transformer = TfidfTransformer(norm='l2',
smooth_idf=True,
use_idf=True)
tfidf_matrix = transformer.fit_transform(bow_matrix)
return transformer, tfidf_matrix
# tfdf
def tfidf_extractor(corpus, ngram_range=(1, 1)):
vectorizer = TfidfVectorizer(min_df=1,
norm='l2',
smooth_idf=True,
use_idf=True,
ngram_range=ngram_range)
features = vectorizer.fit_transform(corpus)
return vectorizer, features
3.主体方法 classfier.py
# -*- coding: utf-8 -*-
# date: 09/22/2020
# coding: gbk
import numpy as np
from sklearn.model_selection import train_test_split
from nlpstudycode.垃圾邮件分类.normalization import normalize_corpus
from nlpstudycode.垃圾邮件分类.feature_extractors import bow_extractor, tfidf_extractor
import gensim
import jieba
from sklearn import metrics
from sklearn.naive_bayes import MultinomialNB
from sklearn.linear_model import SGDClassifier
from sklearn.linear_model import LogisticRegression
#获取数据
def get_data():
"""
获取数据
:return: 文本数据,对应的labels
"""
with open("../../testdata/ham_data.txt", encoding='utf-8') as ham_f, open("../../testdata/spam_data.txt",encoding='utf-8') as spam_f:
ham_data = ham_f.readlines()
spam_data = spam_f.readlines()
ham_label = np.ones(len(ham_data)).tolist() # tolist函数将矩阵类型转换为列表类型
spam_label = np.zeros(len(spam_data)).tolist()
corpus = ham_data + spam_data
labels = ham_label + spam_label
return corpus, labels
#拆分数据
def prepare_datasets(corpus, labels, test_data_proportion=0.3):
"""
:param corpus: 文本数据
:param labels: 文本标签
:param test_data_proportion: 测试集数据占比
:return: 训练数据, 测试数据, 训练labels, 测试labels
"""
x_train, x_test, y_train, y_test = train_test_split(corpus, labels, test_size=test_data_proportion,
random_state=42) # 固定random_state后,每次生成的数据相同(即模型相同)
return x_train, x_test, y_train, y_test
#删除空邮件
def remove_empty_docs(corpus, labels):
filtered_corpus = []
filtered_labels = []
for docs, label in zip(corpus, labels):
#移除字符串头尾指定的字符(默认为空格)
if docs.strip():
filtered_corpus.append(docs)
filtered_labels.append(label)
return filtered_corpus, filtered_labels
#预测值评估
def get_metrics(true_labels, predicted_labels):
print('准确率:', np.round(
metrics.accuracy_score(true_labels,
predicted_labels),
2))
print('精度:', np.round(
metrics.precision_score(true_labels,
predicted_labels,
average='weighted'),
2))
print('召回率:', np.round(
metrics.recall_score(true_labels,
predicted_labels,
average='weighted'),
2))
print('F1得分:', np.round(
metrics.f1_score(true_labels,
predicted_labels,
average='weighted'),
2))
#训练模型
def train_predict_evaluate_model(classifier,
train_features, train_labels,
test_features, test_labels):
# build model
classifier.fit(train_features, train_labels)
# predict using model
predictions = classifier.predict(test_features)
# evaluate model prediction performance
get_metrics(true_labels=test_labels,
predicted_labels=predictions)
return predictions
def main():
#获取数据
corpus, labels = get_data()
print("总的数据量:", len(labels))
#删除空邮件
corpus, labels = remove_empty_docs(corpus, labels)
print('样本之一:', corpus[10])
print('样本的label:', labels[10])
label_name_map = ['垃圾邮件', '正常邮件'] # 0 1
print('实际类型:', label_name_map[int(labels[10])], label_name_map[int(labels[5900])])
# 拆分数据
train_corpus, test_corpus, train_labels, test_labels = prepare_datasets(corpus,labels,test_data_proportion=0.3)
#清洗数据并分词
norm_train_corpus = normalize_corpus(train_corpus)
norm_test_corpus = normalize_corpus(test_corpus)
''.strip()
# 词袋模型特征
bow_vectorizer, bow_train_features = bow_extractor(norm_train_corpus)
bow_test_features = bow_vectorizer.transform(norm_test_corpus)
# tfdf 特征
tfidf_vectorizer, tfidf_train_features = tfidf_extractor(norm_train_corpus)
tfidf_test_features = tfidf_vectorizer.transform(norm_test_corpus)
# tokenize documents
tokenized_train = [jieba.lcut(text)
for text in norm_train_corpus]
print(tokenized_train[2:10])
tokenized_test = [jieba.lcut(text)
for text in norm_test_corpus]
# build word2vec 模型
# model = gensim.models.Word2Vec(tokenized_train,
# size=500,
# window=100,
# min_count=30,
# sample=1e-3)
#朴素贝叶斯模型
mnb = MultinomialNB()
#支持向量机模型
svm = SGDClassifier(loss='hinge', n_iter_no_change=100)
#逻辑回归模型
lr = LogisticRegression()
# 基于词袋模型的多项朴素贝叶斯
print("基于词袋模型特征的贝叶斯分类器")
mnb_bow_predictions = train_predict_evaluate_model(classifier=mnb,
train_features=bow_train_features,
train_labels=train_labels,
test_features=bow_test_features,
test_labels=test_labels)
# 基于词袋模型特征的逻辑回归
print("基于词袋模型特征的逻辑回归")
lr_bow_predictions = train_predict_evaluate_model(classifier=lr,
train_features=bow_train_features,
train_labels=train_labels,
test_features=bow_test_features,
test_labels=test_labels)
# 基于词袋模型的支持向量机方法
print("基于词袋模型的支持向量机")
svm_bow_predictions = train_predict_evaluate_model(classifier=svm,
train_features=bow_train_features,
train_labels=train_labels,
test_features=bow_test_features,
test_labels=test_labels)
# 基于tfidf的多项式朴素贝叶斯模型
print("基于tfidf的贝叶斯模型")
mnb_tfidf_predictions = train_predict_evaluate_model(classifier=mnb,
train_features=tfidf_train_features,
train_labels=train_labels,
test_features=tfidf_test_features,
test_labels=test_labels)
# 基于tfidf的逻辑回归模型
print("基于tfidf的逻辑回归模型")
lr_tfidf_predictions = train_predict_evaluate_model(classifier=lr,
train_features=tfidf_train_features,
train_labels=train_labels,
test_features=tfidf_test_features,
test_labels=test_labels)
# 基于tfidf的支持向量机模型
print("基于tfidf的支持向量机模型")
svm_tfidf_predictions = train_predict_evaluate_model(classifier=svm,
train_features=tfidf_train_features,
train_labels=train_labels,
test_features=tfidf_test_features,
test_labels=test_labels)
if __name__ == '__main__':
main()
4.结果
基于词袋模型特征的贝叶斯分类器
准确率: 0.79
精度: 0.85
召回率: 0.79
F1得分: 0.78
基于词袋模型特征的逻辑回归
准确率: 0.96
精度: 0.96
召回率: 0.96
F1得分: 0.96
基于词袋模型的支持向量机
准确率: 0.97
精度: 0.97
召回率: 0.97
F1得分: 0.97
基于tfidf的贝叶斯模型
准确率: 0.79
精度: 0.85
召回率: 0.79
F1得分: 0.78
基于tfidf的逻辑回归模型
准确率: 0.94
精度: 0.94
召回率: 0.94
F1得分: 0.94
基于tfidf的支持向量机模型
准确率: 0.97
精度: 0.97
召回率: 0.97
F1得分: 0.97