BilSTM 实体识别_“万创杯”中医药天池大数据竞赛——中药说明书实体识别挑战的一点感受...
一. 比赛介绍
疫情催化下,人工智能正在持续助力中医药传承创新加速发展,其中中医用药知识体系沉淀挖掘是一个基础工作。通过挖掘中药说明书构建中药合理用药的知识图谱,将为为中医规范诊疗奠定较好基础。挑战旨在通过抽取中药药品说明书中的关键信息 ,中医药药品知识库的目标。
二. 赛题任务
命名实体识别(NER)的任务是识别 mention 命名实体的文本范围,并将其分类为预定义的类别,例如人,位置,组织等。NER 是各种自然语言应用(例如问题解答,文本摘要和机器翻译) 的基础。该赛题主要针对中药药品说明书实体识别,用于中医药药品知识库的构建。主要包括药品、药品成分、疾病等13类实体进行识别。
三. 数据介绍
1.实体类型共定义了13类,具体类别定义如下:
药品(DRUG)、药物成分(DRUG_INGREDIENT)、疾病(DISEASE)症状(SYMPTOM)、证候(SYNDROME)、疾病分组(DISEASE_GROUP)食物(FOOD)、食物分组(FOOD_GROUP)、人群(PERSON_GROUP)药品分组(DRUG_GROUP)、药物剂型(DRUG_DOSAGE)、药物性味(DRUG_TASTE)、中药功效(DRUG_EFFICACY)2.数据下载
本次标注数据源来自中药药品说明书,共包含1997份去重后的药品说明书,其中1000份用于训练数据,500份用作初赛测试数据,剩余的497份用作复赛的测试数据。本次复赛测试数据不对外开放,不可下载且不可见,选手需要在天池平台通过镜像方式提交。
下载地址:
https://tianchi.aliyun.com/competition/entrance/531824/information
三. 环境搭建
1. 硬件环境
操作系统:Ubuntu18.04 均可。硬件配置:内存64G,1080Ti 11G,1个GPU卡或以上即可。2. 软件环境
使用虚拟环境: conda create –n tf1.x python==3.6进入虚拟环境:1.source .bashrc 2.source activate tf1.x安装依赖包:tensorflow-gpu==1.10 (conda install tensorflow-gpu==1.10)cudatoolkit==9.0 (conda install cudatoolkit==9.2)cudnn=7.0 (conda install cudnn==7.6.4)tqdm (pip install tqdm)pandas==0.25.3 (pip install pandas==0.25.3)numpy==1.14.5 (pip install numpy==1.14.5)四. 赛题分析
1. 任务本质
实体识别任务。
2. 数据分析
针对赛题数据集,笔者进行了较为详细的统计和分析。数据集中的文本长度分布如图所示,文本长度250的数据最多。大部分数据文本长度不是很长。可以看出,数据集存在文本过长的不是很多,但是发现有标签错误的样本。
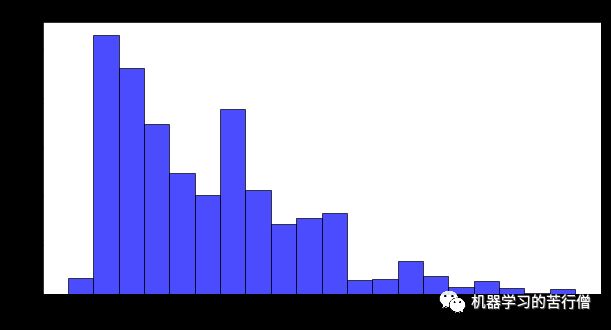
具体数据分布如下,数据最长为3036,最小17,中位数436,数据长度还是相差很大的。

五.预训练模型
1.预训练模型种类
预训练模型:
BERT、ALBERT、XLNET、BERT-WWM、Roberta。
都是基于 transformer 结构的预训练语言模型,包括了 Bert 及其后继者 Bert-WWM、
Roberta、XLNet、Albert 等,统称为 BERT 家族。它们不仅在结构上很相似,而且在使
用方法上更是高度一致。
2.输入截断方式
常用的截断的策略有三种:
pre-truncate
post-truncate
middle-truncate (head + tail)
3.预训练模型
3.1 Bert-WWM
模型结构与 Bert 完全一样,只是在 MLM 训练任务上做了一个小的改进。Bert 在做 MLM 采用
的是 token 级别的 mask,而 Bert-WWM 则采用了词级别的mask,更加合理一些。
3.2Roberta
Bert 的优化版,模型结构与 Bert 完全一样,只是在数据量和训练方法上做了改进。简单说就
是更大的数据量,更好的训练方式,训练得更久一些。
相比原生 Bert 的16G训练数据,RoBerta 训练数据量达到了161G;
去除了 NSP 任务,研究表明 NSP 任务太过简单,不仅不能提升反倒有损模型性能;
MLM 换成 Dynamic Masking LM;
更大的 batch size 以及其他超参数的调优。
3.3XLNet
XLNet 对 Bert 做了较大的改动,二者在模型结构和训练方式上都有不小的差异。
Bert 的 MLM 在预训练时有 MASK 标签,但在使用时却没有,导致训练和使用时出现不一致;
并且 MLM 不属于 Autoregressive LM,不能做生成类任务。XLNet 采用 PML(Permutation
Language Model) 避免了 MASK 标签的使用,且属于 Autoregressive LM,可以做生成任务。
Bert 使用的 Transformer 结构对文本的长度有限制,为更好地处理长文本,XLNet 采用升级
版的 Transformer-XL。
3.4Albert
Albert(Bert 瘦身版本),希望用更简单的模型,更少的数据,得到更好的结果。它主要从以下两个方面减少模型的参数量:
对 Vocabulary Embedding 进行矩阵分解,将原来的矩阵VxE分解成两个矩阵VxH和HxE(H<
跨层参数共享,可以避免参数量随着网络深度的增加而增加。
3.5 各个预训练模型差异
这些模型的性能在不同的数据集上有差异,需要试了才知道哪个表现更好,但总体而言 XLNet、
Roberta、Bert-WWM 会比 Bert 效果略好,large 会比 base 略好。ALbert也有多个版本,large版本训
练时间其实也没有降低,tiny版本会好很多。更多情况下,它们会被一起使用,最后做 模型融合。
五.代码结构
├── README.txt├── bert│ ├── CONTRIBUTING.md│ ├── LICENSE│ ├── README.md│ ├── __init__.py│ ├── __pycache__│ │ ├── __init__.cpython-35.pyc│ │ ├── __init__.cpython-36.pyc│ │ ├── modeling.cpython-35.pyc│ │ ├── modeling.cpython-36.pyc│ │ ├── modeling_v2.cpython-35.pyc│ │ ├── modeling_v2.cpython-36.pyc│ │ ├── modeling_v3.cpython-35.pyc│ │ ├── modeling_v3.cpython-36.pyc│ │ ├── tokenization.cpython-35.pyc│ │ └── tokenization.cpython-36.pyc│ ├── bert-master.zip│ ├── create_pretraining_data.py│ ├── extract_features.py│ ├── modeling.py│ ├── modeling_test.py│ ├── modeling_v1.py│ ├── multilingual.md│ ├── optimization.py│ ├── optimization_test.py│ ├── predicting_movie_reviews_with_bert_on_tf_hub.ipynb│ ├── requirements.txt│ ├── run_classifier.py│ ├── run_classifier_with_tfhub.py│ ├── run_pretraining.py│ ├── run_squad.py│ ├── sample_text.txt│ ├── tokenization.py│ └── tokenization_test.py├── cache│ ├── category2id.json│ └── random_order_train_dev.json├── conf.py├── data│ └── chinese_roberta_wwm_ext_L-12_H-768_A-12├── data_utils.py├── eval_metrics.py├── infer.py├── label2json.py├── model.py├── model_saved│ └── right├── optimization.py├── tf_utils│ ├── __pycache__│ │ ├── bert_modeling.cpython-35.pyc│ │ ├── bert_modeling.cpython-36.pyc│ │ └── rnncell.cpython-36.pyc│ ├── bert_modeling.py│ ├── ops.py│ └── rnncell.py├── train-cv.py└── utils.py代码开源
https://github.com/myboyliu/chinese_drug_ner
六.一些trick
1. 简单定义即可修改网络结构:支持采用原生bert最后一层 或 最后多层进行融合,也可自行设计;支持修改bert+不同网络结构(BILSTM、IDCNN、)进行encoding,也可自行尝试新的结构。
2. 严格按照构建验证集方式,记录实验结果:支持模型训练过程中保存每个epoch下验证集对应的准确率、召回率、F1值,用于挑选最 优模型 支持设置交叉验证,同步记录实验结果。
3. 训练样本目标构造方式上,采用IOBS方式,如想修改设计思路,可自行修改,其他代码复用。
4. 如果没有其他设计思路,可以利用该整合版本代码跑不同的实验结果,进行模型融合。
5. 调参,lr | batch_size | dropout | bert最后一层,还是最后多层 | bert+cnn?抑或 bert+rnn?
6. 提高recall,从目前线上来看,召回偏低,对于解码部分比较严格,会丢失一部分预测结果, 可想办法尽可能控制准确率提高召回。如果没有好的思路,可采用模型融合的方式进行召回补充。
7. 构造训练样本方式上,由于训练样本很多偏长(大于512),可以尝试CNN卷积划窗的形式。以某个特殊符号进行切分,设定窗口大小。
8. 模型融合(很重要的上分点)| PS:多实验,多记录过程,实时保存最好的模型文件,最后 进行模型融合。
模型的ensemble是提升最终效果的有力方法,针对本次任务,概率融合的方案。
前面已经说过,加不加先验特征的线上效果都差不多,但是结果文件差异性比较大,为此,可以将两个模型的结果取并集,而在取并集之前,则通过模型平均的方法提高单一模型的准确性。具体来说,先不加先验特征,然后将所有数据随机打乱并且分成8份,做8折的交叉验证,从而得到8个不加先验特征的模型;然后加上先验特征重做一次,得到另外8个加上先验特征的模型。
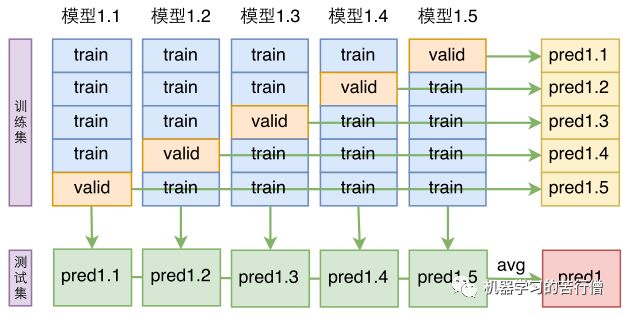
得到这16个模型后,将不加先验特征的8个模型进行平均融合(如下图,即将输出的概率进行平均,然后再解码出三元组),再将加了先验特征的8个模型进行平均融合,这样一共得到两份结果文件,由于进行了平均融合,可以认为这两份结果文件的精度都有了保证,最后,将这两份结果文件取并集。
9. 半监督迁移学习【 网上找公开的医学相关数据,最好数据分布差异小 】
目前找了一个类似的药品说明书,数据路径如下:
https://github.com/myboyliu/chinese_drug_ner/blob/master/data/drug_info.csv
10. 还有就是一个神奇的事情,一个比较好的seed,可以考虑使用grid search,来找一个好的种子数,对提分也有功效
11.知识蒸馏
由于训练集存在一些缺漏和不规范的(当然大部分是好的),因此采用类似知识蒸馏的方式来重新整理训练集,改善训练集质量。
首先,我们使用原始训练集加交叉验证的方式,得到了8个模型,然后用这8个模型对训练集进行预测,得到关于训练集的8份预测结果。每一个个样本的四元组pos_bposb, pos_epose, c>,d表示文档,pos_bposb,和pos_epose分别对应实体提及在文档d中的起止下标,c表示实体提及所属预定义类别,这些四元组同时出现在8份预测结果中但没有出现在训练集的标注中,那么就将这个四元组补充到该样本的标注结果中;如果某个样本的某个四元组在8份预测结果中都没有出现但却被训练集标注了,那么将这个三元组从该样本的标注结果中去掉。
这样一增一减之后,训练集就会完善很多,用这个修正后的训练集重新训练和融合模型。
七.sota 模型介绍
1.概要
FLAT: Chinese NER Using Flat-Lattice Transformer(ACL2020)
代码地址:https://github.com/LeeSureman/Flat-LatticeTransformer
作者提出了一种将Lattice图结构无损转换为扁平的Flat结构的方法,并将LSTM替换为了更先进的Transformer Encoder,该方法不仅弥补了Lattice LSTM无法并行计算(batchsize=1)的缺陷,而且更好地建模了序列的长期依赖关系;
作者提出了一种针对Flat结构的相对位置编码机制,使得字符与词汇得到了更充分更直接的信息交互,在基于词典的中文NER模型中取得了SOTA。
2.动机
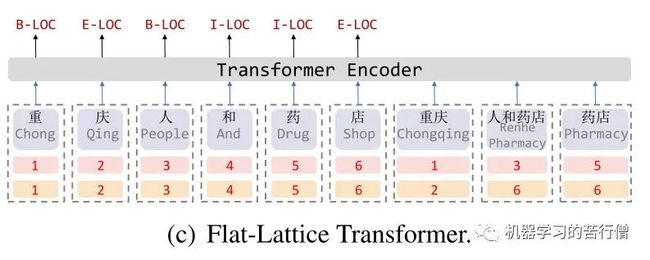
从Transformer的position representation得到启发,作者给每一个token/span(字、词)增加了两个位置编码,分别表示该span在sentence中开始(head)和结束(tail)的位置,对于字来说,head position和tail position是相同的。
3.改进点
有效的位置编码一直是改进Transformer的重要方向,针对本文提出的Flat结构,作者借鉴并优化了Transformer-XL (ACL 2019)中的相对位置编码方法,有效地刻画了span之间的相对位置信息。
Relative Position Encoding of Spans
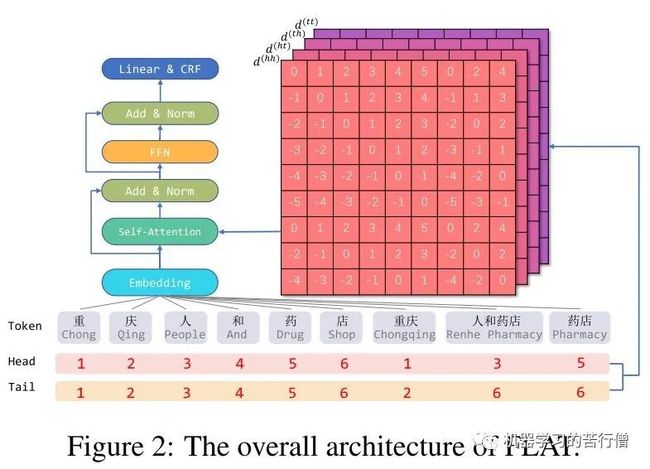
span是字符和词汇的总称,span之间存在三种关系:交叉、包含、分离,然而作者没有直接编码这些位置关系,而是将其表示为一个稠密向量。作者用和表示span的头尾位置坐标,并从四个不同的角度来计算和的距离:
如图2所示,这会得到四个相对距离矩阵:,其中表示的开始位置和的开始位置的距离。然后将这四个距离拼接后作一个非线性变换,得到和的位置编码向量:
其中是Transformer采用的绝对位置编码:
这样,每一个span都可以与任意span进行充分且直接的交互,然后作者采用了Transformer-XL (ACL 2019)中提出的基于相对位置编码的self-attention:
可以直观地将前两项分别看作是两个span之间的内容交互和位置交互,后两项为全局内容和位置bias,在Transformer-XL中是根据绝对位置编码直接计算得出的,而这里的经过了非线性变换的处理。最后,用替换式(1)中的,取出字的编码表示,将其送入CRF层进行解码得到预测的标签序列。
参考资料:
https://github.com/ZhengZixiang/NERPapers
https://zhuanlan.zhihu.com/p/141088583
https://github.com/thunlp/OpenNRE
https://zhuanlan.zhihu.com/p/249181095
https://zhuanlan.zhihu.com/p/150000444