机器学习算法基础-模型的选择
模型的选择
- 机器学习的分类
-
- 监督学习
-
- 分类问题
- 回归问题
- 标注
- 无监督学习
- 模型检验-交叉验证
-
- k-折交叉验证
机器学习的分类
监督学习
分类: k-近邻算法、决策树、贝叶斯、逻辑回归(LR)、支持向量机(SVM)
回归 :线性回归、岭回归
标注 :隐马尔可夫模型(HMM)
分类问题
分类是监督学习的一个核心问题,在监督学习中,当输出变量取有限个离散值时,预测问题变成为分类问题。这时,输入变量可以是离散的,也可以是连续的。监督学习从数据中学习一个分类模型活分类决策函数,称为分类器。分类器对新的输入进行输出的预测,称为分类。最基础的便是二分类问题,即判断是非,从两个类别中选择一个作为预测结果;除此之外还有多酚类的问题,即在多于两个类别中选择一个。
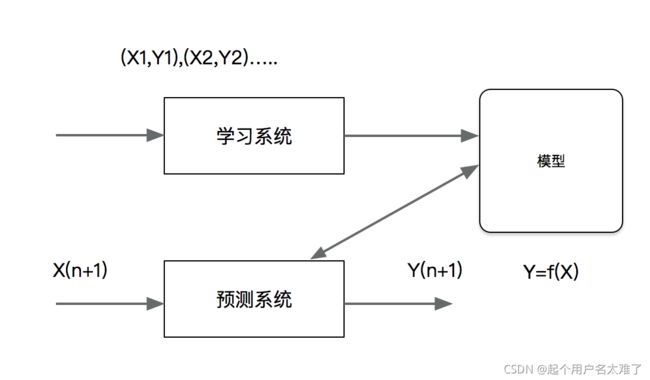
分类问题包括学习和分类两个过程,在学习过程中,根据已知的训练数据集利用有效的学习方法学习一个分类器,在分类过程中,利用学习的分类器对新的输入实例进行分类。图中(X1,Y1),(X2,Y2)…都是训练数据集,学习系统有训练数据学习一个分类器P(Y|X)或Y=f(X);分类系统通过学习到的分类器对于新输入的实例子Xn+1进行分类,即预测术其输出的雷标记Yn+1

分类在于根据其特性将数据“分门别类”,所以在许多领域都有广泛的应用。例如,在银行业务中,可以构建一个客户分类模型,按客户按照贷款风险的大小进行分类;在网络安全领域,可以利用日志数据的分类对非法入侵进行检测;在图像处理中,分类可以用来检测图像中是否有人脸出现;在手写识别中,分类可以用于识别手写的数字;在互联网搜索中,网页的分类可以帮助网页的抓取、索引和排序。
即一个分类应用的例子,文本分类。这里的文本可以是新闻报道、网页、电子邮件、学术论文。类别往往是关于文本内容的。例如政治、体育、经济等;也有关于文本特点的,如正面意见、反面意见;还可以根据应用确定,如垃圾邮件、非垃圾邮件等。文本分类是根据文本的特征将其划分到已有的类中。输入的是文本的特征向量,输出的是文本的类别。通常把文本的单词定义出现取值是1,否则是0;也可以是多值的,,表示单词在文本中出现的频率。直观地,如果“股票”“银行““货币”这些词出现很多,这个文本可能属于经济学,如果“网球””比赛“”运动员“这些词频繁出现,这个文本可能属于体育类
###朴素贝叶斯分类算法
from sklearn.datasets import load_iris,fetch_20newsgroups,load_boston
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
import pandas as pd
news = fetch_20newsgroups(subset='all')
##进行数据分割
x_train,x_test,y_train,y_test = train_test_split(news.data,news.target,test_size=0.25)
##对数据集进行特正常偶去
tf = TfidfVectorizer()
#以训练集当中的词的列表进行每篇文章重要性统计
x_train = tf.fit_transform(x_train)
print(tf.get_feature_names())
x_test = tf.transform(x_test)
mnb = MultinomialNB(alpha = 1.0)
print(x_train.toarray())
mnb.fit(x_train,y_train)
# 对测试验本进行类别预测。结果存储在变量y_predict中
y_predict = mnb.predict(x_test)
##得出准确率
print("准确率为",mlt.score(x_test,y_test))
回归问题
回归是监督学习的另一个重要问题。回归用于预测输入变量和输出变量之间的关系,特别是当初如变量的值发生变化时,输出变量的值随之发生的变化。回归模型正式表示从输入到输出变量之间映射的函数。回归稳日的学习等价与函数拟合:选择一条函数曲线使其更好的拟合已知数据且很好的预测位置数据
回归问题按照输入变量的个数,分为一元回归和多元回归;按照输入变量和输出变量之间关系的类型即模型的类型,分为线性回归和非线性回归。
许多领域的任务都可以形式化为回归问题,比如,回归可以用于商务领域,作为市场趋势预测、产品质量管理、客户满意度调查、偷袭风险分析的工具。
标注
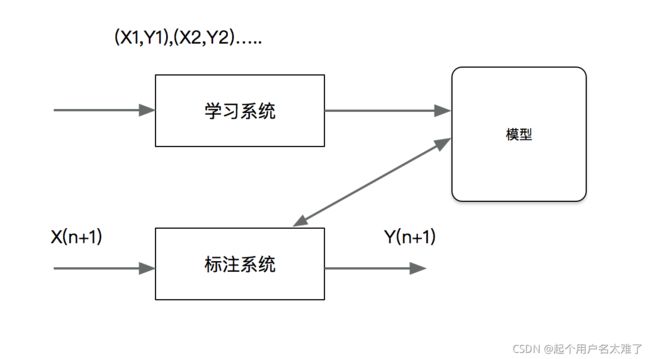
标注也是一个监督学习问题。可以认为标注问题是分类问题的一个推广,标注问题又是更复杂的结构预测问题的简单形式。标注问题的输入是一个观测序列,输出是一个标记序列或状态序列。标注问题在信息抽取、自然语言处理等领域广泛应用,是这些领域的基本问题。例如,自然语言处理的词性标注就是一个典型的标注,即对一个单词序列预测其相应的词性标记序
无监督学习
聚类 :k-means
k-近邻算法采用测量不同特征值之间的距离来进行分类:
优点:精度高、对异常值不敏感、无数据输入假定
缺点:计算复杂度高、空间复杂度高
使用数据范围:数值型和标称型
模型检验-交叉验证
一般在进行模型的测试时,我们会将数据分为训练集和测试集。在给定的样本空间中,拿出大部分样本作为训练集来训练模型,剩余的小部分样本使用刚建立的模型进行预测。
k-折交叉验证
K折交叉验证,初始采样分割成K个子样本,一个单独的子样本被保留作为验证模型的数据,其他K-1个样本用来训练。交叉验证重复K次,每个子样本验证一次,平均K次的结果或者使用其它结合方式,最终得到一个单一估测。这个方法的优势在于,同时重复运用随机产生的子样本进行训练和验证,每次的结果验证一次,10折交叉验证是最常用的。
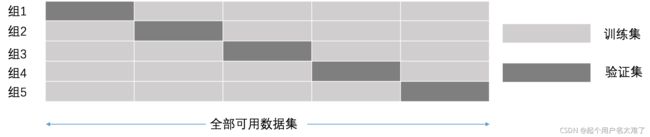
例如5折交叉验证,全部可用数据集分成五个集合,每次迭代都选其中的1个集合数据作为验证集,另外4个集合作为训练集,经过5组的迭代过程。交叉验证的好处在于,可以保证所有数据都有被训练和验证的机会,也尽最大可能让优化的模型性能表现的更加可信。以下是交叉验证,网格搜索和 k-近邻算法用于facebook用户签到数据集(https://ttvand.github.io/Winning-approach-of-the-Facebook-V-Kaggle-competition/)分类的代码实例
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
import pandas as pd
##k近邻预测用户签到位置
##读取数据
path = '/data/facebook-v-predicting-check-ins/train.csv/train.csv'
f = open(path)
data = pd.read_csv(path, sep=',',engine = 'python',iterator=True)
loop = True
chunkSize = 1000
chunks = []
index=0
while loop:
try:
#print(index)
chunk = data.get_chunk(chunkSize)
chunks.append(chunk)
index+=1
except StopIteration:
loop = False
print("Iteration is stopped.")
print('开始合并')
data = pd.concat(chunks, ignore_index= True)
data = data.query("x>1.0&x<1.25&y>2.5&y<2.75")
time_value = pd.to_datetime(data['time'],unit='s')
time_value = pd.DatetimeIndex(time_value)
data['day'] = time_value.day
data['hour'] = time_value.hour
data["week"] = time_value.weekday
place_count = data.groupby("place_id").count()
tf = place_count[place_count.row_id>3].reset_index()
data = data[data['place_id'].isin(tf['place_id'])]
##取出数据中的目标值
y = data['place_id']
#取出特征值
x = data.drop(['place_id','row_id'],axis=1)
#数据的分割
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.25)
#标准化
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
##进行交叉验证和网格搜索
knn = KNeighborsClassifier()
param = {"n_neighbors":[3,5,10]}
gc = GridSearchCV(knn,param_grid=param,cv=2)
gc.fit(x_train,y_train)
#预测准确率
print("准确率:",gc.score(x_test,y_test))
print("交叉验证上最好的结果:",gc.best_score_)
print("最好的模型:",gc.best_estimator_)
print("每个超参数每次交叉验证的结果:",gc.cv_results_)