yolo模型部署——tensorRT模型加速+triton服务器模型部署
将最近的工作做个记录,方便日后学习回顾:
1.针对项目需求开发满足任务的模型,拿到任务就要去选相应的算法,由于是工程应用型,必须找填坑多的算法,这样遇到问题可参考的资料多。
2.做好以后,还要将开发的算法进行封装集成,要交付的是一个相对成熟的产品,所以涉及到算法和模型的部署,而不是每个应用场景都需要像开发环境一样去构建开发环境。
3.在本次模型的部署中遇到了各种各样的问题,有些细小问题无法全面记录,本次只按开发流程记录必要步骤。
4.主要涉及环境配置、模型训练、模型编译、模型部署、产品测试。
5.包含tensorRT模型加速、Triton模型推理、ubuntu18.04、GPU1080\2080\3080\3090上的不同处理、cuda、NVIDIA驱动、linux操作系统(不同设备上部署各环境要严格遵守官网建议、否则极易失败……)
目录
- 1.yolo模型训练
- 2.tensorRT模型编译
- 3.triton-inference-server
- 4.模型部署
-
- 4.1环境安装
-
- 4.1.1 适用于gpu1080/2080
- 4.1.2 适用于GPU1080\2080\3080\3090
- 4.2启动triton服务
- 4.3启动封装好的客户端界面
- 5总结
1.yolo模型训练
网上有各种版本的训练教程,自己找一个完成训练即可。我这里所采用的是yolov5,具体训练可参看《yolov5训练自己的数据集(一文搞定训练)》。
2.tensorRT模型编译
由于我们训练的网络模型参数较多,模型较大,且需要部署到其他机器,会导致模型加载及推理的速度降低。为了提高模型的速度,我们利用tensorRT对训练好的模型进行优化。tensorRT是C++库,故需要对现有模型进行转换。github上有各种模型的tensorRT项目:tensorRT.
在build之前,要按照自己的训练参数对应的进行修改,如yolov5.cpp中的cuda版本,class_map……,yololayer.h中的输入图像的长宽等所有和训练有关的参数。此外,还要在编译之前就要完全按照你之后所用到的对应版本triton的配套环境进行配置(前后不匹配的话,就会和我一样遇到好多问题)这里可以回头再进行tensorRT模型的编译(重复失败几次就熟悉了……)。
build过程其实很容易,就看环境那些的不报错就行。主要操作看官网的readme。即:
在yolov5中将训练好的pt模型利用gen_wts.py转换成.wts文件并复制到tensorRT项目下
然后:
mkdir build
cd build
cmake …
make
sudo ./yolov5 -s
通过上面步骤就会在build文件夹下生成yolov.engine 和libmyplugins.so。这两个文件后面有用!
这里是我自己的环境配置(ubuntu18.04):
GPU1080\2080上面:
triton20.8\9
tensorRT7.1.3
NVIDIA driver 450.51
cuda11.0
opencv3.4
GPU3080\3090上面:
triton20.11
tensorRT7.2.1
NVIDIA driver 460.84
cuda11.1
opencv4.0.1
#其中在该环境下编译可能会遇到上图报错,需要将yolov5.cpp文件做修改:所有的CV_FOURCC_MACRO(‘M’, ‘P’, ‘4’, ‘V’)换为cv::VideoWriter::fourcc(‘M’,‘P’,‘4’,‘V’)
关于驱动、cuda的安装可以参看:ubuntu18.04下cuda9.0-cudnn7.6安装与多版本cuda共存及切换。
tensorRT下载链接,各版本对应的环境依赖。
opencv安装(这个适用于部署机器,若是开发进行模型编译时最好利用build得方式安装opencv,这个网上可参考的案例很多,但是在有些情况下不同版本的opencv编译的坑不同,在3080上3.4版本的我就没编译成功,最后换成了4.0.1,直接就成功了,具体操作自行查找):
sudo add-apt-repository ppa:timsc/opencv-3.4
sudo apt-get update
sudo apt install libopencv-dev如果你安装opencv3.4.1中遇到了问题可参考:
ubuntu18.04安装opencv3.4.3遇到问题解决方法 ubuntu18.04
安装OpenCV3.4.1踩坑过程
3.triton-inference-server
Triton 推理服务器,提供针对 CPU 和 GPU 进行优化的云和边缘推理解决方案。Triton 支持 HTTP/REST 和 GRPC 协议,允许远程客户端请求对服务器管理的任何模型进行推理。对于边缘部署,Triton 可用作带有 C API 的共享库,允许将 Triton 的全部功能直接包含在应用程序中。github项目地址:https://github.com/triton-inference-server/server
关于如何triton的介绍及使用可到官方github上仔细研读。其中强调一点就是要必须遵守官方文档中的各版本所依赖的环境,其中若是在ubuntu18.04下使用的话、使用版本20系列,20.08,20.09可在GPU1080\2080上运行,在GPU3080\3090上没成功:
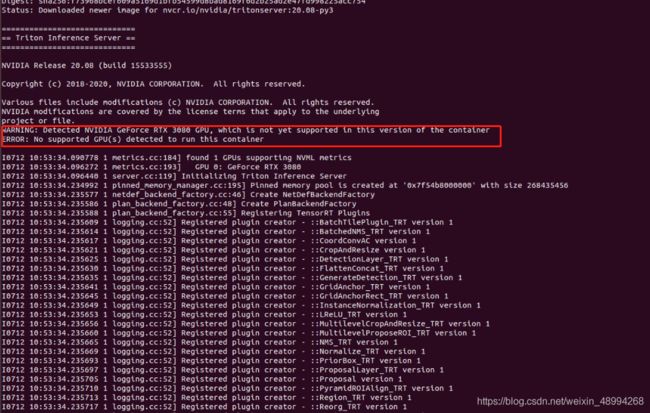
在GPU3080\3090上使用20.11版本。
关于各版本所依赖的环境可见:support-matrix:

重点关注NVIDIA驱动、cuda、tensorRT三者的依赖关系。
具体使用教程参见:Quickstart
需要安装docker,NVIDIA Container Toolkit。
拉取所需要的triton。
#其中 是您要拉取的 Triton 版本。
docker pull nvcr.io/nvidia/tritonserver:<xx.yy>-py3
#例如 docker pull nvcr.io/nvidia/tritonserver:20.08-py3 创建自己的模型库,就是一个存放自己模型的文件夹,其文件存放的示例见docs/examples/model_repository 中。其中config.pbtxt文件是模型的输入输出的一些参数。
启动服务:
docker run --gpus=1 --rm -p8000:8000 -p8001:8001 -p8002:8002 -v/full/path/to/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:<xx.yy>-py3 tritonserver --model-repository=/models也可按照指示获取客户端示例,具体看官方文档。
4.模型部署
将模型在别的机器上进行部署。所部署的机器不需要拥有模型的开发环境,只需配置模型的运行环境即可。
4.1环境安装
4.1.1 适用于gpu1080/2080
cuda11.0-tensorRT7.1.3-opencv3.4-triton20.8 所对应的驱动大于450
这里必须先安装cuda再装tensorRT,且安装方式要一致,我用的是deb安装
对于该环境安装起来比较简单,直接运行脚本sh install_server_env.sh 文件具体内容如下
#!/bin/bash
# install cuda
cd package/ #存放对应deb安装包的文件夹
sudo dpkg -i cuda-repo-ubuntu1804-11-0-local_11.0.3-450.51.06-1_amd64.deb
sudo apt-key add /var/cuda-repo-ubuntu1804-11-0-local/7fa2af80.pub
sudo apt-get update
sudo apt-get install cuda
# install tensorrt
sudo dpkg -i nv-tensorrt-repo-ubuntu1804-cuda11.0-trt7.1.3.4-ga-20200617_1-1_amd64.deb
sudo apt-get update
sudo apt-get install tensorrt
# install opencv
sudo add-apt-repository ppa:timsc/opencv-3.4
sudo apt-get update
sudo apt install libopencv-dev
# install docker
sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
gnupg-agent \
software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io
sudo groupadd docker
sudo gpasswd -a ${USER} docker
sudo systemctl restart docker
sudo cp ./daemon.json /etc/docker/daemon.json
sudo systemctl daemon-reload
sudo systemctl restart docker
# install NVIDIA Container Toolkit
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - \
&& curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update
sudo apt-get install -y nvidia-docker2
sudo systemctl restart docker
# install tritonserver
docker pull nvcr.io/nvidia/tritonserver:20.08-py3
echo "server env installed successfully!"
4.1.2 适用于GPU1080\2080\3080\3090
该环境主要是为了在30系列显卡上进行模型的部署,所需要的环境比较新,所以有很多的坑,下面是我花了好多时间测试出来的能够在30系列上部署成功的方法。由于我开发是在GPU1080上进行的,如果用我自己的环境编译出来的模型就会加载失败:
所以得在30的卡上单独编译适用于30的环境。
测试下来triton20.11支持GPU3080\3090但其依赖cuda11.1
相比上面一种傻瓜式安装,这种安装需要我们一步步逐步安装。
1.升级ubuntu内核 linux kernel change to 5.9+(cuda 11.1 require)
2.卸载原有驱动及cuda,重新安装cuda11.1+cudnn8.0.5
3.安装tensorRT7.2.1
4.升级NVIDIA驱动(这一步必须在安装完cuda11.1和tensorRT后进行,原因是为了满足tensorRT安装的依赖,我们的cuda必须和tensorRT采用相同的deb安装方式安装,而这种方式安装的cuda是自带驱动的)
5.安装opencv4.0.1
6.剩下的与上一种脚本安装基本一样
1. 升级ubuntu内核
参考:Ubuntu 18.04 内核升级
按照作者教程,下载对应的deb包,下载网址https://kernel.ubuntu.com/~kernel-ppa/mainline/,升级至5.9:

sudo dpkg -i *.deb
#重启
reboot2.卸载原有驱动及cuda,重新安装cuda11.1+cudnn8.0.5
sudo apt-get --purge remove nvidia*
sudo apt autoremove
sudo apt-get --purge remove "*cublas*" "cuda*"
sudo apt-get --purge remove "*nvidia*"官网下载cuda11.1deb安装文件:
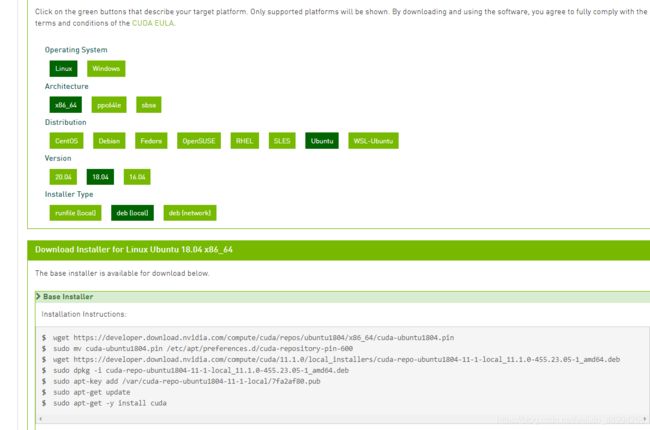
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-ubuntu1804.pin
sudo mv cuda-ubuntu1804.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/11.1.0/local_installers/cuda-repo-ubuntu1804-11-1-local_11.1.0-455.23.05-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu1804-11-1-local_11.1.0-455.23.05-1_amd64.deb
sudo apt-key add /var/cuda-repo-ubuntu1804-11-1-local/7fa2af80.pub
sudo apt-get update
sudo apt-get -y install cuda安装cudnn8.0.5
这里若是cudnn与cuda版本不匹配或者不安装或者安装没有进行链接,都会在tensorRT模型编译的时候报错:
这里建议采用deb安装方式(tar解压并替换文件的方式我试了,没成功)
参考:NVIDIA cuDNN v8 deb方法安装和卸载教程(Linux/Ubuntu)进行安装。
官网下载下面三个文件:
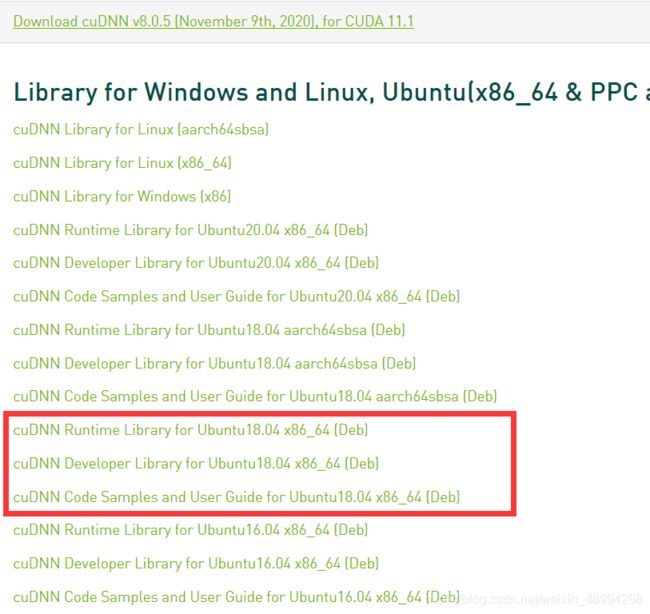
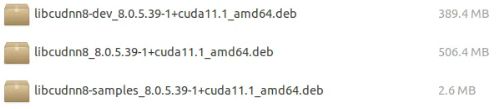
使用如下语句依次安装:
sudo dpkg -i libcudnn8_8.0.5.39-1+cuda11.1_amd64.deb
sudo dpkg -i libcudnn8-dev_8.0.5.39-1+cuda11.1_amd64.deb
sudo dpkg -i libcudnn8-samples_8.0.5.39-1+cuda11.1_amd64.deb查看cudnn版本:
dpkg -l | grep cudnn![]()
3.安装tensorRT7.2.1
wget https://developer.nvidia.com/compute/machine-learning/tensorrt/secure/7.2.1/local_repos/nv-tensorrt-repo-ubuntu1804-cuda11.1-trt7.2.1.6-ga-20201007_1-1_amd64.deb
sudo dpkg -i nv-tensorrt-repo-ubuntu1804-cuda11.1-trt7.2.1.6-ga-20201007_1-1_amd64.deb
sudo apt-get update
sudo apt-get install tensorrt4.升级NVIDIA驱动
参考网上安装驱动教程,需要禁用源,然后下载最新的nvidia驱动文件:
sudo sh NVIDIA-Linux-x86_64-460.84.run5.opencv4.0.1安装
参考:Linux下安装OpenCV4(适用于Ubuntu等)
官网下载安装包,并解压。
在解压的文件夹里新建一个文件夹用来编译OpenCV:
cd opencv-4.0.1
mkdir release
cd release
cmake -DCMAKE_BUILD_TYPE=Release -DOPENCV_GENERATE_PKGCONFIG=ON -DCMAKE_INSTALL_PREFIX=/usr/local ..
make -j7
sudo make install
cd /etc/ld.so.conf.d/
sudo touch opencv4.conf
sudo sh -c 'echo "/usr/local/lib" > opencv4.conf'
sudo ldconfig6.其余环境安装,直接用上一节中的脚本将triton换为20.11安装即可
运行脚本sh install_server_env.sh其具体内容如下:
# install docker
sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
gnupg-agent \
software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io
sudo groupadd docker
sudo gpasswd -a ${USER} docker
sudo systemctl restart docker
sudo cp ./daemon.json /etc/docker/daemon.json
sudo systemctl daemon-reload
sudo systemctl restart docker
# install NVIDIA Container Toolkit
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - \
&& curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update
sudo apt-get install -y nvidia-docker2
sudo systemctl restart docker
# install tritonserver
docker pull nvcr.io/nvidia/tritonserver:20.11-py3
echo "server env installed successfully!"至此就完成了所有环境在GPU3080上的安装,我们要用该环境编译使用于30的模型,故在这之后重新build
tensorRT模型(见第二节),这里说下编译好的模型如何建立triton模型库。编译将生成的yolov5.engin改名为model.plan。另外还有生成的libmyplugins.so文件,按照下面tree放置:
其中config.pbtxt文件:


4.2启动triton服务
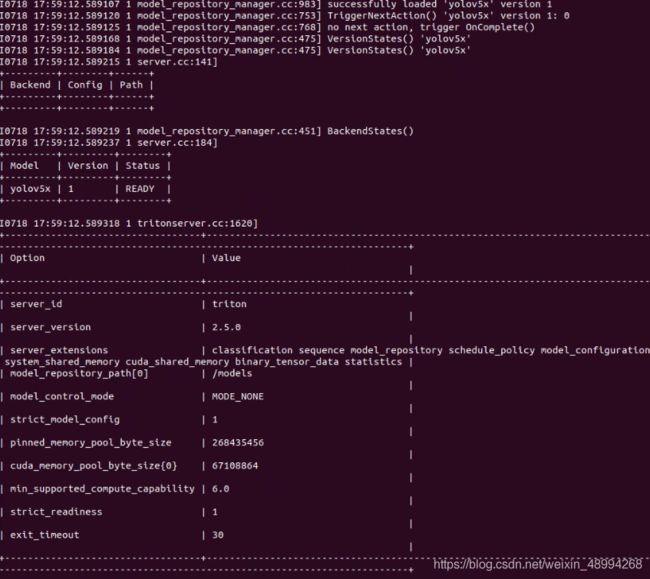
sh run_triton_model.sh启动,文件内容如下(其中在30系列上是tritonserver:20.11。20.08启动一样,改个版本换个模型即可):
#!/bin/bash
docker run --gpus all \
--rm --shm-size=1g \
--ipc=host --ulimit memlock=-1 \
--ulimit stack=67108864 -p8000:8000 -p8001:8001 -p8002:8002 \
-v$(pwd)/triton_deploy/models:/models \
-v$(pwd)/triton_deploy/plugins:/plugins \
--env LD_PRELOAD=/plugins/libmyplugins.so nvcr.io/nvidia/tritonserver:20.11-py3 tritonserver \
--model-repository=/models \
--grpc-infer-allocation-pool-size=16 --log-verbose 1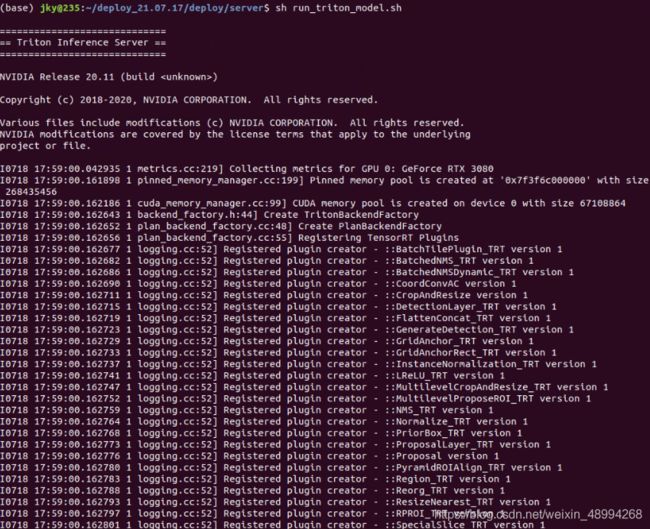

4.3启动封装好的客户端界面

部署后的检测帧率在每秒50帧左右:
5总结
本来在1080\2080直接就部署成功的,但是在部署3080设备时遇到了很多不兼容的问题,经过不断的尝试终于一步步走了下去。真的是每进行一步都有各种大大小小的问题。在解决问题中有的直接就可以找到处理方法,但是有的网上搜不到,只能自己尝试解决,这个过程相当痛苦,前前后后搞了将近一周,熬夜加班,有时候也想放弃。但是回头来看,总结几点吧,官方文档一定要仔细看,多参考别人躺过的坑,还有就是心态不能乱!