句子重写任务近年有哪些值得关注的工作?看这一篇就够了!

©作者 | 叶哲宇
单位 | 携程旅行网-帝国理工学院
研究方向 | 文本生成&机器问答
在多轮对话问答,端到端对话聊天机器人等多个场景下,不完整的句子在现有框架下的处理显得尤为棘手。句子的不完整性可以体现在:1. 指代词(9coreference),使得语句语焉不详指代不清,没法在上下文缺失的情况下就单一句子理解含义;2. 省略词(ellipsi),导致句子成份缺失,上下文背景信息不完善。如何解决这两个问题也引发了学界业界的广泛研究探讨,从而衍生出两个子任务 Coreference Resolution 和 Information Completion。
上述两个子任务可以统称为 Incomplete Utterance Rewriting(IUR),目的是将不完整的话语改写成语义等价但独立于语境的话语。这篇文献综述选取了近年来比较有价值的一些(23 篇)相关工作,做了简要梳理,包括相关公开数据集,模型构造方法等。

EMNLP 2019 [1]
关注于解决 Question Answer 任务中的 Coreference 和 Ellipsi,引入了基于上下文的问题改写任务(Task of question-in-context rewriting),文中又称 de-contextualization。
We introduce the task of question-in-context rewriting: given the context of a conversation’s history, rewrite a context-dependent into a selfcontained question with the same answer.
从 QuAC 数据集中提取了40,527个 questions,构造了 Context Abstraction:Necessary Additional Rewritten Discourse(CANARD)数据集。
从下表中可以到人类对模型表现的对比(BLEU scores),这仍然是一个难度较高且值得去探索的任务。


COLING 2016 [2]
这篇 2016 年的文章指出 Question Answering(QA)system 当中 non-sentential(incomplete)的问题。然而上下文缺失的情况下这些问题很难被问答系统很好的理解,因此需要 QA system 借助历史对话数据来还原这些 non-sentential utterances(NSU),从而可以更好地理解用户的意图。
实验数据集无论在当时还是现在看来都是比较小的,只包含了 7220 段对话, 其中每段对话包含先前的问题(Q1),先前的答案(A1),NSU question(Q2),and 改写后的句子(R1),如下图所示:

模型层面,使用了 RNN-based encoder-decoder 网络结构,并分别设计了 Syntactic Sequence Model 和 Semantic Sequence Model 来学习语言和语义表征信息,并通过一个集成模型选取上述两个模型的输出序列中与待改写问题关键字重合度最高的一个作为结果。
Syntactic Sequence Model :
尽管训练语料很小, 但是字典大小的量级仍然维持在 10k 左右,这在 RNN encoder-decoder 结构下需要大量的参数来维护一个输出向量,这在算力有限的 2016 年仍然是一个挑战。常见的处理方式是,维护一个较小的字典大小,然后把未知词都标识为 UNK。
Syntactic Sequence Model 将语料库中 OOV 的单词替换为带有数字编号的 UNK,这个数字编号是它在对话中的相对位(如下图)。symbols(UNK1, UNK2, UNK3, UNK4)在不同对话当中是共享的,这使得该模型能够在不同的对话中学习语言结构信息。

Semantic Sequence Model :
Syntactic Sequence Model 只关注 OOV 词在序列中的位置,分配一个新的未知符号 UNK,完全抛弃了 OOV 词之间的语义相似性。下面这个两个例子 (a) (b) 中的 UNK 拥有完全相同的位置,但是所期望得到的 R1 其实是大相径庭的。
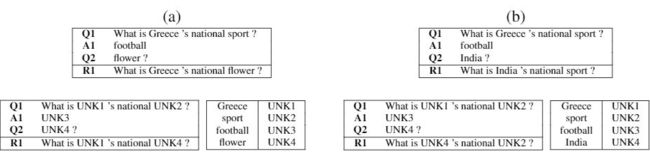
对此,Semantic Sequence Model 的处理方式是,将 UNK 词通过 word2Vec 的结果进行 k-means 聚类,生成 Category Label(CL)。上述 (a) (b) 两个例子中的 UNK 的类别分类如下:


SIGIR 2017 [3]
上文的两位作者,在 SIGIR 2017 也有后续的工作展现。好像很重要,找不到Access。
https://openreview.net/forum?id=Sy41ErWd-B

ACL 2016 [4]
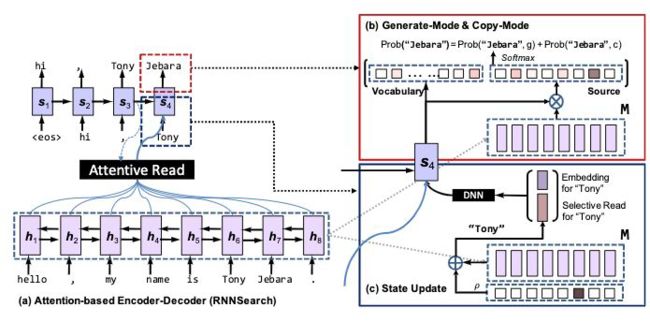
作者来自香港大学和华为诺亚方舟实验室。这篇文章参考了人类在对话当中喜欢重复复述名词实体和较长短语的复读机行为,提出了基于 sequence-to-sequence 的 COPYNET,很好得将传统的生成模式和拷贝模式集成到一起。
在 NLP 中,sequence-to-sequence 这样的经典模型试图将以原始词汇表组成的原始序列映射到一个目标词汇表组成的目标序列中。原始词汇表和目标词汇表可以是相同的,或者有很大一部分是重叠的,就像文本摘要任务;也可以是完全不同的,比如机器翻译场景下。还有许多这样的任务都要求模型能够在目标序列中产生出现在源序列中,但相对于目标词汇表而言 out-of- vocabulary(OOV)的 token。一个简单而直观的想法就是直接从原始序列复制 token,来解决这个 oov 问题。
“copy mechanism”被拟用来模拟人类沟通交流过程中“复述”的行为,是一个选择原始序列中的某个片段,然后将该片段拷贝到目标序列中的过程。
模型构造:
2021 年了,sequence-to-sequence,RNN,Attention Mechanism 这些都老生常谈了,不再赘述了。
CopyNet 的工作方式是在每个 decoding step 中计算目标词汇表中的每个 token 和源序列中的每个 token 的概率。通过这种方式,CopyNet 获得一个目标词汇表以及原始序列构成的 extended vocabulary,允许模型潜在地生成相对目标词汇表 OOV 的 token。在 CopyNet 中,Encoder 采用了一个 Bidi-RNN 模型,输出一个隐藏层 M 作为 short-term memory;Decoder 基于 Canonical RNN-decoder 改造,主要有以下三点不同:
Prediction:存在生成模式和拷贝模式两种不同的词汇解码模式,CopyNet 的预测基于这两个模式的混合概率模型。
State Update:更新 t-th step 的状态时,COPYNET 不仅仅使用用 t-1-th step 预测结果的词向量,而且使用 M 中特定位置的 hidden state。
Reading M:Copynet 选择性地读取 M 的值,获取内容信息以及位置信息有效混合信息。
拓展词汇表 extended vocabulary 可以定义为:
![]()
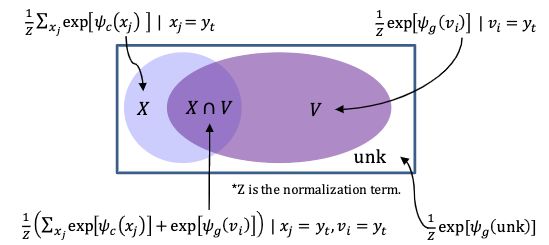
其中目标词汇表 原始序列 ,未知词 [UNK]。该模型将能够在拓展词汇表中自由地选择词汇。具体而言,在解码步骤的 t-th step,token 的概率分布为:
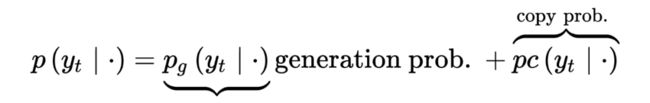
根据上图的四种情况,分别计算 generation probability 和 copy probability :
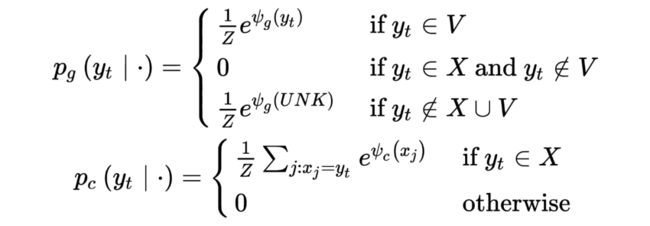
其中:
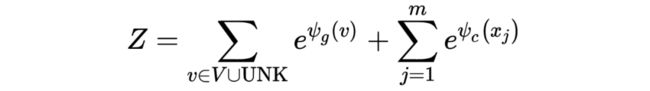
是一个 normalization term, 是 generation 的得分函数, 是 copy 的得分函数。
状态更新
t-1-th step 时刻, 的 hidden state 表示为 ,由 的词向量与状态权重和拼接而成,理解为 attentive read+selective read,weighted sum 函数 定义为:

M 的混合解析
一个词的语义和它在 X 中的位置都将被一个经过适当训练的编码器 RNN 编码到 M 中的隐藏状态中。
在生成模式下,attentive read 占据主导,其主要由受到语义信息和语言模型来驱动,因此阅读 M 上的信息时位置更加跳跃自由;在拷贝模式下,对 M 的 selective read 往往受到位置信息的引导,从而采取非跳跃式僵化移动(rigid move)的做法,往往涵盖连续的多个词,包括未知词。
位置信息的更新方式如下:
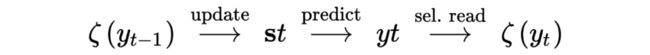

ACL 2017 [5]
论文原作者 Abigail See 的解读:
http://www.abigailsee.com/2017/04/16/taming-rnns-for-better-summarization.html
Two Problems :
基于 RNN + attention 的 abstractive summarization 方法面临两个问题:
没法准确地再现事实细节(复制某个词),特别面对 oov 或者不常见的词。
rare words 的 word embedding 不够强。
一些名词性质的单词尽管拥有较强的 representation,但是其 embedding 倾向于聚集在一起,这可能会在试图还原单词时造成混淆。
经常自我重复。
decoder 过度依赖于其输入,即先前生成的词,而不是在 decoder 中存储长程信息。
How to Fix :
Easier Copying with Pointer-Generator Networks:为了解决 Problem 1(inaccurate copying),提出了 pointer-generator network。这是一个混合网络,可以选择通过 point 从原本复制单词,同时保留从 fixed vocabulary 生成单词的能力。具体模型构造可以概括为计算 attention distribution ,vocabulary distribution ,generation probability :
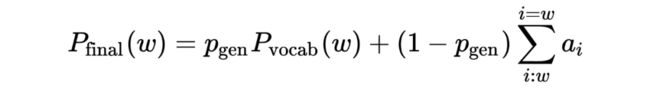
生成单词 w 的概率 = 从词汇表生成的概率 + 复制原文某一个处文本的概率
Eliminating Repetition with Coverage:为了解决 Problem 2(repetitive summaries),提出 coverage 方法使用 attention distribution 记录覆盖率,为重复部分添加惩罚机制。

即,一个原始单词的覆盖率等于它迄今所接收到的 attention scores 的和。

ACL 2019 [6]
这篇来自微信人工智能模式识别中心的文章,利用指针网络引入了一种基于 transformer 的重写体系结构,同时另外一大贡献是收集了一个带有人工注释的新数据集。
数据集构造:
作者从几个主流的中文社交媒体平台上抓取了 200k 个候选的多轮会话数据,从中整理出了 40k 正负比例平衡的高质量语料,其中正例指包含省略或指代,负例中的句子则拥有完整的语义表达,不需要重写。
下面这张表是其中随机 2000 个对话数据中,省略 or 指代出现频率的分析结果。只有不到 30% 的 utterances 既没有指代也没有省略,相当多的 utterances 二者都有,这进一步证实了在多轮对话中处理指代和省略的重要性。

模型构造:
使用了基于 Transformer encoder-decoder 结构的 copy network,试图根据历史对话数据 以及需要被改写的最后一轮 utterances 学到一个 mapping function 从而得到改写后的句子 。跟经典的 Transformer 类似,对于每一个 token ,它的词向量由 word embedding 以及 positional embedding 相加得到,再次基础上本文引入了第三种 embedding ——turn embedding 用以区分不同轮数:
![]()
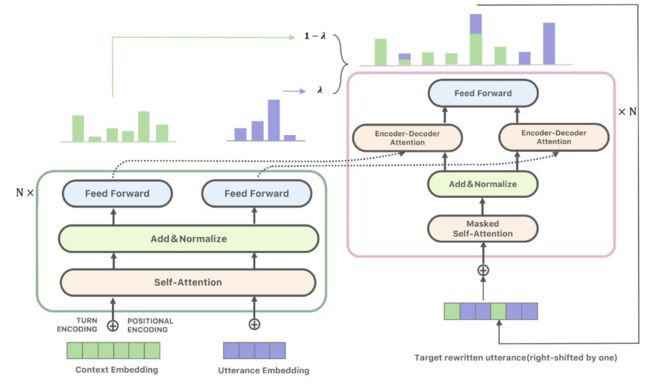
上图显示了模型的整体架构,Encoder 和Decoder 的部分几乎就是 typical 的Transformer,这边不再赘述了。在最后 decoder 的输出层,我们希望模型能在 decoding 阶段的每一步都能学习到是否 copy 来自历史对话数据 H 的字词。这边一个额外的 probability λ 需要在每一步被计算来决定是否从 context 或者原始待改写句子 中复制字词:
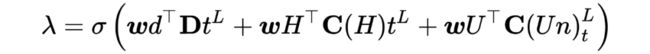
λ = 1, If contains neither coreference nor information omission
λ = 0, when a coreference or omission is detected
通过 maximizing 来训练这个端到端模型:

and 分别是 和 的 attention scores。此时注意机制负责从对话历史 或者 中找到适当的共指信息或缺省信息。
结果分析:
以下四种不同类型的模型比较中,T-Ptr-Gen 生成质量不高,比单独的 Copy network(2)效果更差
(L/T)-Gen: Pure generation-based model. Words are generated from a fixed vocabulary.(worst)
(L/T)-Ptr-Net: Pure pointer-based model. Words can only becopied from the input
(L/T)-Ptr-Gen: Hybrid pointer+generation model. Words can be either copied from the input or generatedfrom a fixed vocabulary.
(L/T)-Ptr-λ: Our proposed model which split the attention by a coefficient λ. (best)

EMNLP 2019 [7]
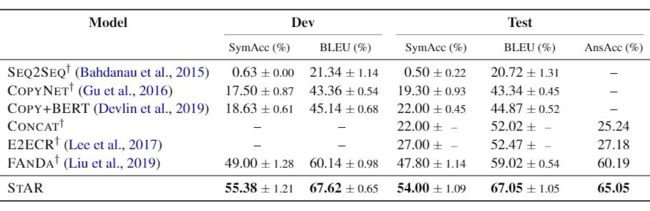
来自腾讯 AI Lab 的工作,文章开源了一个大型多轮对话数据集 Restoration-200K,提出了“pick-and-combine”的方法试图从对话系统中的上下文内容中还原不完整的语句,并对比其和 Syntactic(Kumar and Joshi, 2016),Sequence-to-Sequence model(Seq2Seq)和 Pointer Generative Network(See et al., 2017 [5])的模型表现。
数据集构造:
原始语料从豆瓣小组爬取,数据样本大小为 200k,其中每个样本中包含 6 条语句。
辛苦的五人标注团队花了六个月时间完成了以下两个标注任务:
utterance 是否省略先前话语中所产生的概念或实体,即是否需要改写(与上文的正负样本相同)。
对于正例,人工重写不完整的语句. 重写后的语句被要求尽可能使用原文使用过的字词,来减少改写句子的多样性。再迫不得已的情况下,可以使用预先设定好的一个规模较小的常用单词列表来保证句子的流畅性。后续校验过程发现只有 4.8% 的句子不满足这个要求,且都被剔除于数据集之外了。
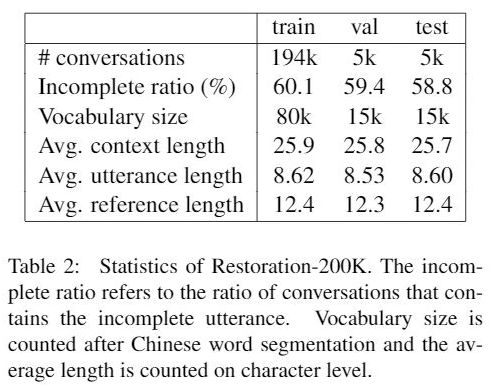
从上表的数据集统计信息中,我们可以注意,这 200k 大小的数据集中有 60% 的句子是不完整的。相比于 Kumar and Joshi, 2016(Avg. utterance lenght=3.52),Restoration-200K 的平均语句长度更长,理论上单句话包含更多的信息。
Pick-and-Combine (PAC) Model :
作者表示,还原后的 utterances 与 Original utterances 的重叠率是 100%,而与 Previous utterances 的重叠率只有 17.7%。因而模型在训练过程中,会倾向于简单地复制原始 utterances 而没法有效地改写该语句。PAC Model 将改写分为了两个步骤:
Pick process:使用 BERT,识别 Previous utterances 中被省略的单词 (序列标注任务)。
Combine stage:根据已识别的省略词恢复原话语, 实验验证下 BERT 效果不佳。将 selected omitted words 附加到 Original utterances 的后方,然后将这两个序列输送到一个 pointer generative network 中。(标注过程中使用到的额外字典在这边应该也需要引入进来,确保 PGN 能够尽可能地还原 restored utterances)。

机器指标和人工指标下,PAC 都表现出了卓越的性能表现。



AAAI 2019 [8]
Slides:
https://siviltaram.github.io/files/fanda-slides.pdf
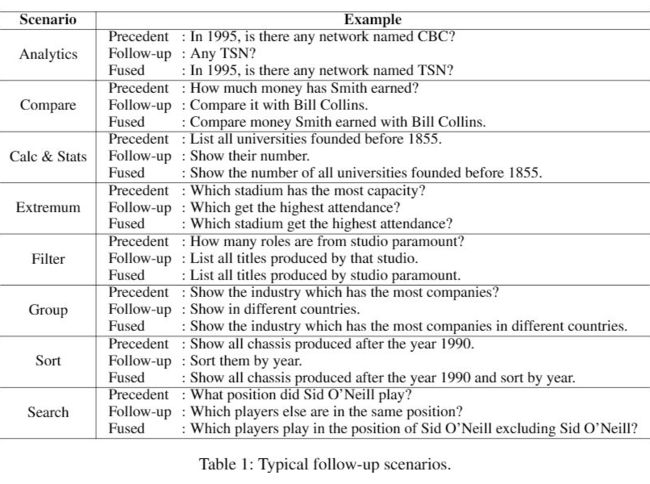
在 Natural Language Interfaces to Databases(NLIDB)场景中,用户可以使用自然语言搜索数据库,而不是使用类似 sql 的查询语言。然而在用户多轮查询的过程中,经常出现极简问,后续查询(Follow-up query)等等例子,这就需要充分解析上下文信息从而理解用户查询的真实意图。Follow-up query 可以定义为上下文无关问题(precedent query)的后续问题,前者我们可以称之为 precedent query,重写后融合上下文语义信息的 query 则被称为 fused query。
从 WikiSQL 中筛选了一个数据集 FollowUp,其中包含了 1000 个问题的三元组跨越 120 个不同的表,以下是一些数据集中的样本示例。另外一大贡献则是提出Follow-up ANalysis for DAtabases(FANDA)方法。
precedent query(x)与 follow-up query(y)往往会有大量冲突的语义结构。FANDA 特此将 symbol-level 和 segment-level 两种结构的信息都纳入考量,前者代表单词,后者代表与 SQL 语句相关的短语。具体而言,FANDA 的结构可以细化为下图所示的三个模块:

Anonymization
这一步骤中,query 当中的 analysis-specific words 会被挖掘出来。Analysis-specific words 是 SQL语句的具体参数,可以分为下图八种。可以在 FANDA 的结构图中看到,这八种 analysis-specific words 会被替换为对应的 Symbol。而剩下是组成句式的修饰词(rhetorical words)。

Generation
这种挖掘字词语义却忽略了上下文信息的行为,跟 Kumar and Joshi(2016)中的 Semantic Sequence Model 有点像。为了弥补这种上下文语义信息的缺失, segment structure 被用来捕捉这些修饰词,通常基于 SQL 参数和简单常识 (Table 3)。在 Generation 中,Symbols 被组合产生所有可能的 segment sequences(考虑到 ellipsis 的存在,图一有 12 种可能),然后通过一个 ranking model 来选择得分最高的 segment sequence。

Fusion
Fusion 模块可拆分为两步走战略:
第一步:找到 x 与 y 之间,sql 成份冲突的部分(相同或不兼容的语义)。
第二步:我们用一个 segment 替换另一个 segment 来融合两个 segments,以解决上述冲突。
第二步中的“替换”操作可以具体为 Refine 和 Append:
Refine: “How much money has Smith earned? How about Bill Collins?”
Append: “How much money has Smith earned? Compare with Bill Collins.”
Ranking model
区分两种 Intents:Refine & Append,并参照 NER 的方法,对 Seg 进行 IOB 标注, BiDi-LSTM+CRF 进行 ranking,取得分最高的表达作为最后意图。
对于 sql 语句的标注,这是一件毕竟费时费力的事情,本文使用了少量 fused query 的 ground truth 进行弱监督学习。

EMNLP 2019 [9]
Slides:
https://siviltaram.github.io/files/split-slides.pdf
code:
https://github.com/microsoft/EMNLP2019-Split-And-Recombine
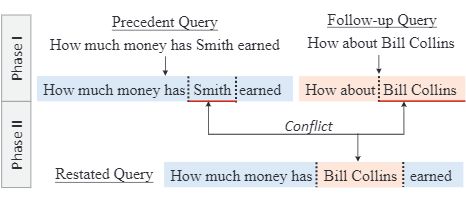
来自与上文工作的同一批作者,inspired by 自己之后又把自己超了。提出了 SpliT-And-Recombine(STAR)模型,正如其名字所暗示的,STAR 先将 precedent query(x)与 follow-up query(y)拆分为多个 span,然后再重新组合到一起生成 restated query(又换了一个名字), 如下图所示:

要 maximize 的目标为:

其中 为 split(x, y)的所有可能。由于缺少用于 splitting 和 recombination 的注释,很难直接执行监督学习,再这边强化学习大法又来了:

其中 是所有 restated query 的候选空间, 代表由比较 和标注 产生的 reward。
Phase I : Split
把 span 分割任务再再再当成序列标注任务(Split or Retain)。使用 BiDAF(Seo et al., 2017)获取 之间的语义交互。Embedding 由 character,word and sentence 拼接而来: 。
Phase II : Recombine
直接我们只需将 precedent query 中的 span 替换为 follow query 中冲突的 span,以生成 restated query。
我们直接略过强化学习的部分直接看结果:

NAACL 2018 Short [10]
Code:
https://github.com/kentonl/e2e-coref/
解决高阶指代消解问题,主要是 globally inconsistent 的问题:

Baseline : Bidirectional LSTMs

最后得到 antecedent distribution 。

Higher-order approach
高维信息其实体现在多轮对话中,简单地使用 LSTM 连接两个 mention 会导致长程信息的消失。这篇文章提出了一个推理方法,充分考虑前文的信息。具体而言是多轮的迭代(iterations),假设 N 轮,通过 attention 机制将前一轮的表征信息 加入进来,来计算 i,j 两个位置互相是 mention 的概率:

其中 还是 baseline 当中用到的得分方程。每一轮的 span representation 的更新方式如下:
![]()
其中

Coarse-to-fine antecedent pruning 上述推理过程比较耗时,需要加入一些剪枝技巧。引入一个 alternate bilinear 的得分函数 , 相较于 计算量要小得多。这样我们可以将 改写为:
![]()
通过三个步骤,分别得到
的 top M
的 top K
的 top 1

EMNLP 2019 Short [11]
一篇将 BERT 应用到 Coreference Resolution 的工作,恰如其名。分别将上文中c2f-c2fcore(Lee et al., 2018)中的 LSTM 替换为 BERT,Elmo 对比了模型表现。e2e-coref 为不使用分布式语义的模型版本。
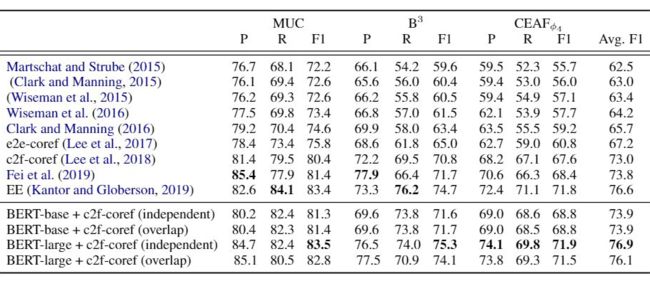
因为 max segment len 的存在,对于超过 max segment len 的文档,采用以下两种变体作为处理方案:
Independent:超过 max segment len 就截断
Overlap:超过 max segment len 的文档,通过滑动窗口的形式生成多个片段。再通过 f 拼接起来:
![]()

EMNLP 2020 [12]
将 incomplete utterance rewriting 转化为一个语义分割任务(Semantic Segmentation),构造一个 word-level edit matrix 包含三种不同的编辑类型:None,Substitute and Insert。提出了 Rewritten U-shaped Network(RUN)来构造这个 ,并进行随后的字词替换插入操作。
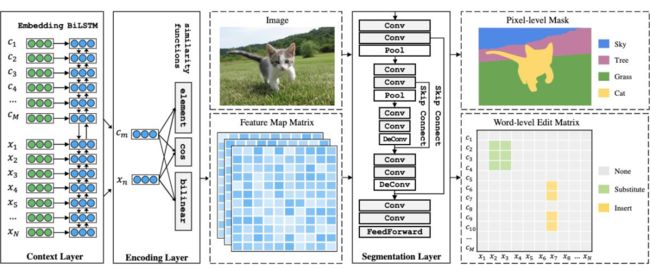
正如上图模型架构所描绘的,模型(RUN)主要由以下三个组件构成:
Context layer : GloVe + BiLSTM (c and x are jointly encoded)
Encoding layer (concentrate on local rather than global information) : concatenating 1. element-wise similarity (Ele Sim.) 2. cosine similarity (Cos Sim.) and 3. learned bi-linear similarity (Bi-Linear Sim.) -> D-dimensional feature vector
Segmentation layer (To capture global information) : Conv + pool + skip connect + ffn ->
上述架构同样可以使用基于预训练模型(e.g. BERT, etc)获取分布式表征信息, RUN + BERT 表现出相较 RUN 更有说服力的实验结果。
生成前需要进行一步 standardization确保所有的 Y 都是长方形,based on Hoshen–Kopelman,并添加 Connection Words 保证句子流畅度。

在 REWRITER 数据集(Su et al., 2019)上的结果:


EMNLP 2019 [13]
提出了 Context rewriting network(CRN),CRN 基于 Bidi-GRU + attention的 encoder-decoder 模型架构实现,在 decoding 阶段使用 CopNet 架构从原文中复制文本。在没有真实标注的条件下,CRN model 先在 Pseudo Data 进行预训练,在生成阶段也关心 Response 与改写语句的交互关系,进而提高回复的准确率。
模型构造
在 Decoder 当中,每一个 step 接受融合后的多元信息 context ,last utterance 以及上一步的 hidden state 作为输入,从而权衡是否需要直接从 context 中拷贝字词到 pseudo rewritten candidate 。
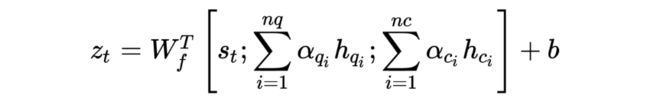
其中 ,都是注意 力权重,根据以下公式计算可得:

最后可以用 copy mechanism 来预测下一个目标词汇,根据这个条件概率公式:
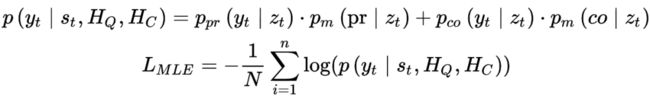
是回复中的 t-th 词,和 分别是 predict-mode 和 copy-mode 的候选词概率分布, 和 分别是其得分函数。并且由一个额外的 来控制选择这两个模式的概率。
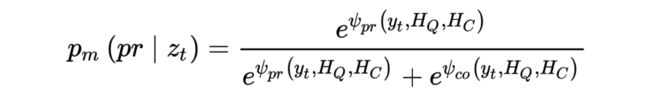
Pre-training with Pseudo Data :
因为数据集中并没有改写句的标注,因此作者从对话历史中抽取关键词来构造模拟数据。
Key Words Extraction:为了寻找共同信息量大的 words,作者使用了 pointwise mutual information(PMI)来抽取文本中的关键词。

是 context word, 是 response word。为了选择对回复来说最重要的词,作者也计算了 , 是 last utterance 的词,最终的 PMI 分数为:

然后选择 PMI 分数最高的 20% 词插入 last utterance
Pseudo Data Generation:在生成阶段,每一个关键字前后 2 个位置的临近词都被考虑作为插入词。在如何选择插入位置这个问题上,语言模型多层 RNN 被选择作为解决方案,同时保留得分最高的三个生成句。这三个生成句被输送到一个 encoder-decoder 的生成模型 以及一个回复选择模型 当中:

是候选回复, 是 CRN 生成的候选 query,以及 pseudo rewritten candidate 。
Fine-Tuning with Reinforcement Learning :
通过上述方式得到的 pseudo data 不可避免的包含一定程度的错误和干扰,为了使得回复更加流畅,引入强化学习来加强 CRN 模型。对于生成后的改写语句候选句 ,计算
回复生成的奖励:
![]()
回复选择的奖励:
![]()
配合经典的 policy gradient 算法,计算 RL objective 的损失函数
![]()
最后把 MLE loss 和 RL loss 的和作为最后的训练目标:
![]()

ACL 2020 [14]
香侬科技官方知乎文章:
https://zhuanlan.zhihu.com/p/126544790
Overall:
把指代消解问题转换为一个 query-based Span 预测问题,like Extractive QA Task — Query:一个基于相应代词周围上下文生成的问题,Answer:一个 Clusters 包含所有相同指代含义的 Coreferences。
这个 span prediction 策略在 mention proposal stage 具有很强的灵活性,可以检索出遗漏的 mention;避免 mention 遗漏造成错误传递。
用 query 明确地去 encoding the mention 和它的 context,这样通过 MRC 训练框架以及 attention 机制能够将上下文的影响传播到每一个输入词中,从而深入透彻地理解 coreferent mention 的 context。
大量现有的 MRC 数据集(SQuAD etc)可用于数据增强,以提高模型的泛化能力。
模型构造:
该模型由一个指称提取模块(Mention Proposal)和一个指称链接模块(Mention Linking)组成,
Mention Proposal:使用 FFNN 从原始文本中提取出所有可能的指代词 Mention,获得 的指称得分:
![]()
在得到所有文段的得分之后,只取前 个作为候选指称,N 为文档长度, 为超参数。
Mention Linking:将指称聚类为共指词 — 对候选指称中的任意一个指称 ,指称链接模块任意一个其他候选指称 ,计算它们是共指的得分。把 作为上下文, 所在的句子作为 query , 的所有 coreferent mentions 作为 Answers ,得到三元组 {context, query, answer}。考虑到一个 mention 会有多个匹配的 coreferent mentions,SpanBERT 被用来获取 contextual representations 从而给 中的每个 生成 BIO tagging:
![]()
把 token score 拓展到 span score 可以得到 对 的共指得分
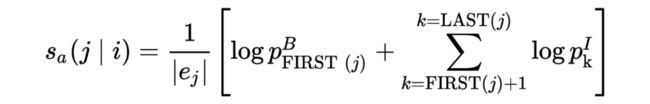
根据其对称的双向关系,可以得到 和 的共指得分
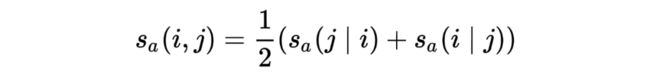
和 的共指词得分可以由以下等式获得
![]()
即,他们是共指的前提是:1)他们分别是 mention;2) 他们互相是 coreferent mentions。

NAACL 2019 [15]
来自 AI Amazon Alexa AI 的工作, 主要是想解决多轮对话下的对话状态跟踪(dialogue state tracking)以及指代消解问题(referring resolution tasks)。同样地,把任务重构为解决基于对话内容自感知的语句重写任务(dialogue context-aware user query reformulation task),下图是一个 Amazon Alexa 的实际例子,CQR Engine 可以将用户的输入“Buy his latest book”转化为“But Yuval Harari's latest book.”。
在文中,pointer-generator network(PGN, See et al., 2017 [5])同样被使用到,并且使用了 multi-task learning 来训练这个 PGN,可以做到在训练中不需要额外的人工标注数据。

计算 PGN 中的 generation probability 和 copy probability 以及一个模式选择概率 ,最后得到输出分布:
![]()
在训练数据中,维护了一个 rewrites-corpus 其中 i,t,j 分别表示:第 i 个对话数据,某个对话中的第 t 轮,j 表示正确改写中的第 j 个改写(多个 golden reference)。训练目标则是优化如下 log-likelihood:
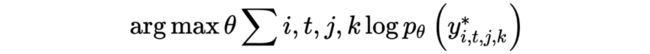

上面这个例子中我们可以看到, 包含两个 golden reference。尽管他们语序以及所包含的字词都不相同,但是 Entity S1 和 U3 都出现其中。这意味着,对于对话重写任务,从输入对话框复制的实体子集应该保持不变,而不管 decoder state 的动态。
也就是说,对于 task-oriented 型语句重写任务语句改写场景下,关键实体信息不应该有缺失。为此,加入 SLU(Spoken Language Understanding)模块识别出来的 domain 和 intent 信息,e.g. BOOKQUERY 和 SYSTEM INFORMINTENT。此外还需要一步去词化(delexicalize)操作:即用该实体类型或名称替换掉具体的实体 value e.g. “Sapiens” -> “book”。

Multi Task Learning(MTL)中,可以引入一个额外的 Entity-Copy Auxiliary Objective 用来判断 Input 中的 Entity 是否在 golden rewrites 中。理论上这个额外的训练目标会优化 encoder 产生的表征信息,使其更关注于是否 copy 这个 entity。最后的 PGN 的目标函数如下:
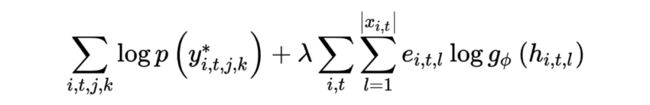
其中 是一个超参数, 为


EMNLP 2019 [16]
Code:
https://github.com/terryqj0107/GECOR
Oral:
https://vimeo.com/424412465
Web:
https://multinlp.github.io/GECOR/
提出了 Generative Ellipsis and CO-reference Resolution model(GECOR),主要思想是在生成模式和复制模型之间切换来生成一个语义完善的话语。又搞了一个数据集 CamRest676,CamRest676 数据集包含 676 个对话,有 2744 个用户话语。这 2744 个用户话语中有 1,174 ellipsis 和 1,209 Co-reference 被标注出来。参考 Su et al., 2019 的数据分割方案,CamRest676 包含 1,331 个包含 ellipsis 或 co-reference 的正例,以及不需要改写的负例 1413 个。
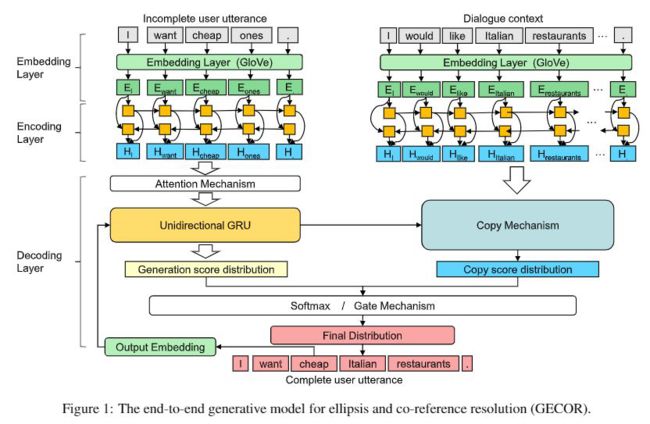
GECOR 不考虑 ellipsis 或 co-reference 的语法特性,它们可以是字词,短语甚至短句。同时这种改写方式不需要提供一组要解析的候选指代,以往的研究,such as Lee et al., 2018 往往需要在存在多个 ellipsis 或 co-reference 的情况下遍历文本,计算复杂度较高。
embedding layer 采用 Glove,Utterance and Context Encoder 负责分别对待改写句子和对话内容进行编码。在 Decoder 中,需要分别计算与 Gu et al., 2016 [4] 类似的 generation probability 和 copy probability :
generation probability :
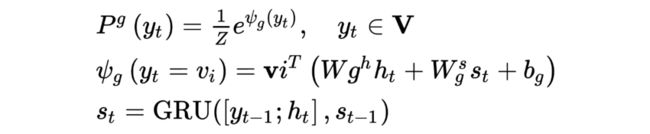
其中 为 entire vocabulary, 为前一步 decoder state, 是前一步生成的 word embedding, 是归一项。
copy probability :
对于 dialogue context 中的每一个词,是否将其拷贝的概率 如下:

是 context encoder 对于 的输出结果。
充分考虑上述两个概率,可以得到在 extended vocabulary = 上的选词概率分布公式为:
![]()
上述 copy 机制(Gu et al., 2016 [4])可以替换为基于 See et al.,(2017) [5] 修改而来的 gated copy mechanism,即引入一个 :
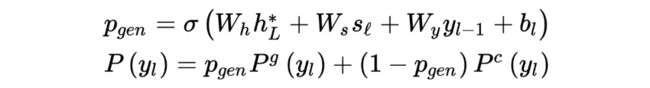
将 GECOR 集成到一个 end-to-end 的 task-oriented 对话系统 TSCP [17] 当中。可以从下图中看到,这个 end-to-end 架构,一共包含 2 个 encoder(分别对 user utterance 和上下文进行编码),3 个 decoders:一个 decoder 用于预测对话状态,第二个 decoder 用于生成完整的用户话语,第三个 decoder 用于生成系统响应。

目前只关注 GECOR 的结果,暂时不看 TSCP 的:
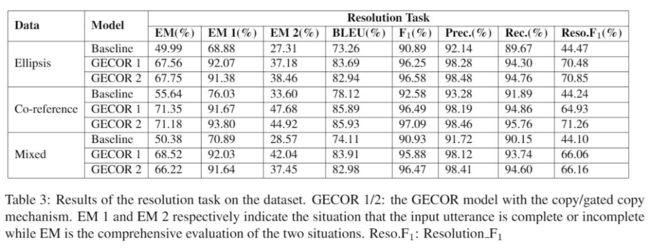
baseline model 来自 Zheng et al.(2018)的 seq2seq neural network model。

AAAI 2020 [18]
官方博客:
https://xiyuanzh.github.io/projects/AAAI2020.html
Code and Data:
https://gitlab.com/ucdavisnlp/filling-conversation-ellipsis
省略(ellipsis)现象在日常对话当中十分常见,ellipsis 的存在也增加了对话角色预测(Dialog Act Prediction),语义角色标注(Semantic Role Labeling)等下游任务的难度。通常会采用自动补全的方法来填充 ellipsis,但是自动补全的话语可能会重复或错过一些单词,甚至可能产生无意义的句子。本文提出了一种混合模型 Hybrid-ELlipsis-CoMPlete(Hybrid-EL-CMP),充分考量带有 original utterance with ellipsis 以及自动补全的 utterance,以提高语言理解能力。
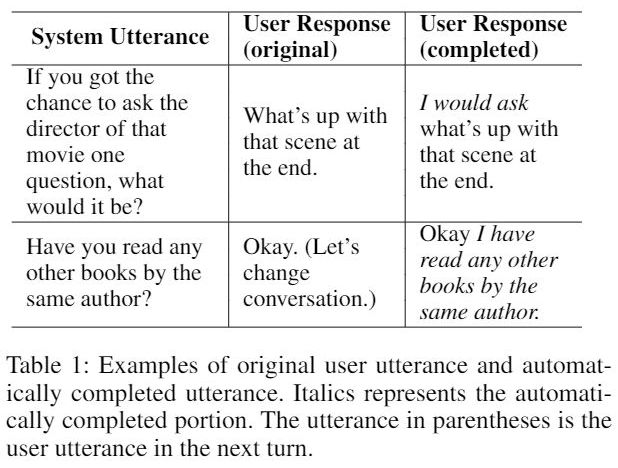
让我们来看一下上表中的第二个例子。用户在说完“Okay”之后停顿了一下说“Let’s change conversation”,实际上他的真实意图是想结束对话。而自动补全的 User response 会让系统误以为用户表示同意。
本文提出的 Hybrid-EL-CMP 正是要解决 automatically completed utterance 所产生的错误,以便于在下游的 Dialog Act Prediction不 误导用户意图,以及 Semantic Role Labeling 中能正确标识语句成份。
上述两个下游任务,也是本文的 evaluation tasks。Hybrid-EL-CMP 作为一种辅助校验模型,可以为下游任务提供更好的语言表达能力,但我们目前更关心如何自动补全不完整的话语。

ACL 2020 [19]
腾讯 AI 又来了,真的高产。

EMNLP 2020 [20]
腾讯 AI 三杀了。这篇文章指出,上述前序工作的 decoder 主要使用 global attention 从而关注对话语境中的所有单词。由于没有预先引入先验焦点(prior focus),上述 atention 机制的注意力可能会对一些无关紧要的字词吸引。
很自然地可以想到——使用 Semantic Role Labeling(SRL)识别句子的谓词-实参(Predicate-Argument)结构,从而捕获 who did what to whom 这样的语义信息作为先验辅助 decoder。下图这个例子很好地体现了语义成分在 Utterenace 中起到的作用,“粤语”和“普通话”被识别为两个不同的实参,可以在 SRL 的指导下获得更多的关注。

腾讯 AI 的标注团队从 Duconv(Wu et al., 2019)数据集上,标注了 3000 个 dialogue sessions,包含 33,673 个谓词,27,198 个话语,选用了一个额外的 BERT-based SRL model(Shi and Lin, 2019)作为 SRL parser 用来完成这个谓词-实参结构的识别任务,并且在 CoNLL 2012(117,089 examples)进行初步预训练。

Input Representation 还是 BERT 经典三件套 Toekn Embedding。Segment Type Embeddings 和 Position Embeddings, 用以区分 Speakers。Input 由 PA structures,dialog context,and rewritten utterance 三者拼接而成,其中 PA structures 由本质上的以谓词为根,语义实参为叶子的根转为换的线性三元组,并以随机顺序拼接。
这样以随机顺序 i 拼接的机制可能会对 sequence encoder 带来一定的干扰信息。这边引入附加在 PA sequence 上的 bidirectional attention mask 机制来辅助,即不同 PA 三元组中的 token 不能相互 attend。同时 PA 三元组的 position embedding 使用各个三元组的独立位置信息。
在 REWRITE(Su et al., 2019)数据集上进行实验对比一下结果,BERT 指代 RoBERTa Chinese。复现结果与 Su et al.,(2019)不太一致。
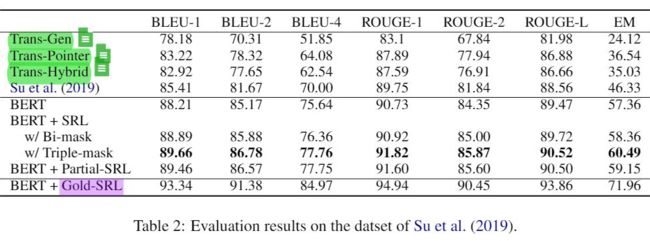
Ablation Study :
SRL:来自经由 CoNLL 2012 训练的 SRL parser, 75.66 precision, 74.47 recall, and 75.06 F1。
Bi-mask:PA Triples 中的 token 可以互相关注。
Triple-mask:只允许在同一个 Triple 的 Token 互相关注,不同的 Triples 中的 token 彼此是不可见的 -> 独立地编码每个谓词-参数三元组,这可以防止不必要的三元内部注意,从而更好地模拟 SRL 结构。
Partial-SRL:SRL Model 只作用于待改写句。
Gold-SRL:使用 SRL 的 golden label 作为输入,说明 SRL model 的质量高度影响 rewriter。
在 Restoration-200K(Pan et al., 2019 [7])数据集上实验结果如下,还不如Pan et al.,(2019)[7] 提出的 PAC Model。
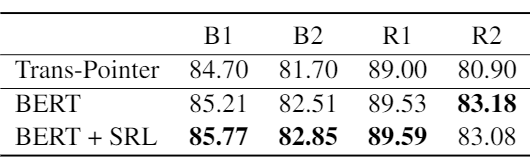
we find that the SRL information mainly improves the performance on the dialogues that require information completion. One omitted information is considered as properly completed if the rewritten utterance recovers the omitted words. We find the SRL parser naturally offers important guidance into the selection of omitted words.

EACL 2021 [21]
文章把省略补充问题和指代消解问题转化为 QA 问题,如下 query 可以转化为的三元组:
context: the entire document
question: the sentence in which the ellipsis/mention is present
answer: the antecedent/entity
对于指代消解问题,如果一个句子包含 n 个 mentions,就转为成为 n 个 questions 其中 resolution 用包裹。
P.S. Ellipsis 被分为 Sluice Ellipsis 和 Verb Phrase Ellipsis,分别有不同的公开数据集。

QA Architectures
选取三种不同的 encoder module:
DrQA (Chen et al., 2017), LSTM
QANet (Yu et al., 2018), CNN
BERT (Devlin et al., 2018), pre-trained Transformer
简单看下结果:
很奇怪这篇文章没有跟 coreference task 的一些工作进行同向比较,他们这样解释:
In this p, we analyse the best performing coreference models and discuss why they cannot be compared with other works in literature.

WSDM 2021 [22]
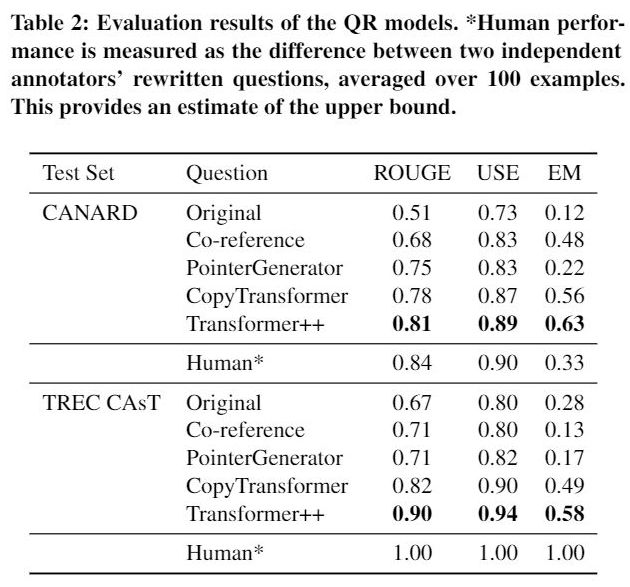
本文展示了如何使用 QR 组件扩展现有的 SOTA QA 模型,并演示了所提出的方法提高了 QA 任务在 End-to-end 会话下的性能。通过 QR 组件重写话语,减少了 follow-up questions 的模糊性的,使它们可以被现有的 QA 模型作为对话上下文之外的独立问题来处理。
提出了基于 Transformer++ 作为 Question Rewriting Model,并将其嵌入于两种不同的 QA 任务类型中,关注会话场景下 QR 任务中在不同类型 QA 模型中的应用能力。
retrieval QA:即在给定的文章中,根据已有<问题,答案>匹配关系集合寻找答案。
extractive QA:即在一篇文章中为一个给定的自然语言问题找到答案。
主要贡献在于在 TREC CAsT 2019 passage retrieval dataset 以及 CANARD 数据集上进行相关实验,对比了相关 baseline:

ArXiv 2020 [23]
这篇来自 Xu et al.,(2020)[20] 同一个团队的文章指出,从对话内容中拷贝缺失内容来重写语句的方式受限于不同 Domain。文本生成需要往往需要对每个字计算output probability,这就使得搜索空间随着字典大小和上下文对话长度的增加而扩大。此外,暴露偏差(exposure bias, Wiseman 和 Rush, 2016)会进一步加剧测试用例与训练集不相似的问题,导致输出与输入表达不同的语义含义。
文本提出了一种新颖的 sequence-tagging-based model 来解决这一健壮性问题,使得搜索空间大大减少。同时为了解决缺乏流畅性这一文本生成的标注模型的通病,作者在一个 REINFORCE framework 下注入来自 BLEU 或 GPT-2 的损失信号。
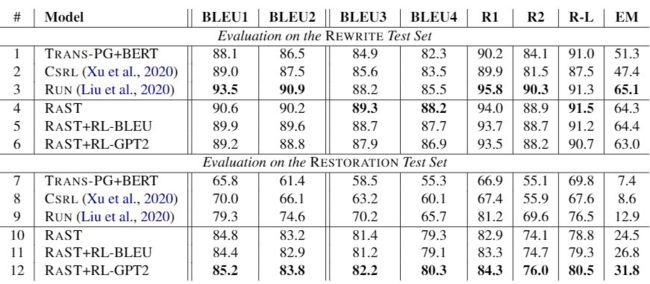
R~A~ST : Rewriting as Sequence Tagging :
先前的工作往往对于 ellipsis 和 co-reference 采取不同的策略,往往是 Insert, Repalce。R~A~ST 将 Insert 和 Repalce 这两个操作用一个先 deletion 后 Insetion 的操作代替,标注数据由 longest common sub-sequence(LCS)算法生成,剔除 REWRITE(Su et al., 2019)和 RESTORATION-200K(Pan et al., 2019)[7] 中不满足要求的。

Deletion :the word is deleted(i.e. 1)or not(i.e. 0);
Insertion: [start, end]: 对话内容中的位置信息,If no phrase is inserted,the span is [-1, -1]。
Insertion 中的 span prediction 当作 MRC 处理。
Enhancing Fluency with Additional Supervision :
REINFORCE 的强化学习目标:
![]()
其中 和 分别来自生成和采样的 candidate sentences, 是 reward function 来自 sentence-level BLEU 或者 GPT-2 model,可以得到最后的损失函数:
![]()
结果分析:

ArXiv 2020 [24]
在该模型中, 语句重写被定义为一个序列生成问题,并通过辅助的词类标签(word category label)预测任务引入词类信息。
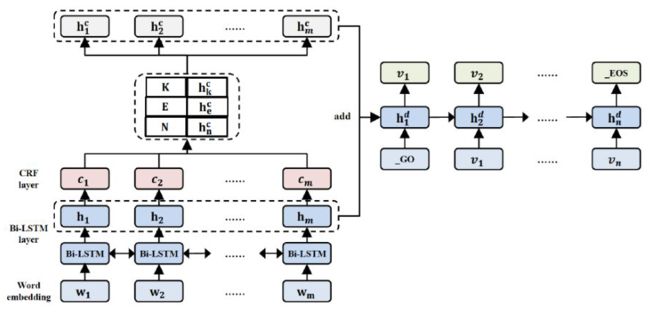
其中 是目标生成词的预测概率, 是词类标签的预测概率。
参考文献
[1] [EMNLP 2019] Can You Unpack That? Learning to Rewrite Questions-in-Context (Elgohary et al., 2019) https://aclanthology.org/D19-1605/
[2] [COLING 2016] Non-sentential Question Resolution using Sequence to Sequence Learning (Kumar and Joshi, 2016) https://aclanthology.org/C16-1190/
[3] [SIGIR 2017] Incomplete Follow-up Question Resolution using Retrieval based Sequence to Sequence Learning (Kumar and Joshi, 2017) https://dl.acm.org/doi/10.1145/3077136.3080801
[4] abc[ACL 2016] Incorporating Copying Mechanism in Sequence-to-Sequence Learning (Gu et al., 2016) https://arxiv.org/abs/1603.06393
[5] abcd[ACL 2017] Get To The Point: Summarization with Pointer-Generator Networks (See et al., 2017) https://arxiv.org/abs/1704.04368
[6] [ACL 2019] Improving Multi-turn Dialogue Modelling with Utterance ReWriter (Su et al., 2019) https://aclanthology.org/P19-1003/
[7] abcd[EMNLP 2019] Improving Open-Domain Dialogue Systems via Multi-Turn Incomplete Utterance Restoration (Pan et al., 2019) https://aclanthology.org/D19-1191/
[8] [AAAI 2019] FANDA: A Novel Approach to Perform Follow-Up Query Analysis (Liu et al., 2019a) https://arxiv.org/abs/1901.08259
[9] [EMNLP 2019] A Split-and-Recombine Approach for Follow-up Query Analysis (Liu et al., 2019b) https://arxiv.org/abs/1909.08905
[10] [NAACL 2018 Short] Higher-order coreference resolution with coarse-tofine inference (Lee et al., 2018) https://aclanthology.org/N18-2108/
[11] [EMNLP 2019 Short] BERT for Coreference Resolution: Baselines and Analysis (Joshi et al., 2019) https://aclanthology.org/D19-1588/
[12] [EMNLP 2020] Incomplete Utterance Rewriting as Semantic Segmentation (Liu et al., 2020) https://aclanthology.org/2020.emnlp-main.227/
[13] [EMNLP 2019] Unsupervised Context Rewriting for Open Domain Conversation (Zhou et al., 2019) https://arxiv.org/abs/1910.08282
[14] [ACL 2020] CorefQA: Coreference Resolution as Query-based Span Prediction (Wu et al., 2020) https://aclanthology.org/2020.acl-main.622/
[15] [NAACL 2019] Scaling Multi-Domain Dialogue State Tracking via Query Reformulation (Rastogi et al., 2019) https://aclanthology.org/N19-2013/
[16] [EMNLP 2019] GECOR: An End-to-End Generative Ellipsis and Co-reference Resolution Model for Task-Oriented Dialogue (Quan et al., 2020) https://arxiv.org/abs/1909.12086
[17] [ACL 2018] Sequicity: Simplifying Task-oriented Dialogue Systems with Single Sequence-to-Sequence Architectures https://aclanthology.org/P18-1133/
[18] [AAAI 2020] Filling Conversation Ellipsis for Better Social Dialog Understanding (Zhang et al., 2020) https://arxiv.org/abs/1911.10776
[19] [ACL 2020] Generate, Delete and Rewrite: A Three-Stage Framework for Improving Persona Consistency of Dialogue Generation (Song et al., 2020) https://aclanthology.org/2020.acl-main.516/
[20] ab[EMNLP 2020] Semantic role labeling guided multi-turn dialogue rewriter (Xu et al., 2020) https://arxiv.org/abs/2010.01417
[21] [EACL 2021] Ellipsis Resolution as Question Answering: An Evaluation (Aralikatte et al., 2021) https://aclanthology.org/2021.eacl-main.68/
[22] [WSDM 2021] Question Rewriting for Conversational Question Answering (Vakulenko et al., 2021) https://arxiv.org/abs/2004.14652
[23] [ArXiv 2020] Robust Dialogue Utterance Rewriting as Sequence Tagging (Hao et al., 2020) https://arxiv.org/abs/2012.14535
[24] [ArXiv 2020] MLR: A Two-stage Conversational Query Rewriting Model with Multi-task Learning (Song et al., 2020) https://arxiv.org/abs/2004.05812
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
???? 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
???? 投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
